
Computer alchemist at Bloomberg Interested in semantics and multilinguality. Opinions are my own.
Joined January 2012
- Tweets 880
- Following 800
- Followers 472
- Likes 954
127 Photos and videos












Tommaso retweeted

6 Aug 2024
👀 Exciting News! 👀
Happy to announce our latest research paper, “Retrieve, Read and LinK: Fast and Accurate Entity Linking and Relation Extraction on an Academic Budget”, will be presented at #ACL2024! 🚀
Try it out! huggingface.co/spaces/relik-…
Thread below 👇

2
12
29
3,163

"Are we going to die?"
📍#GazaStrip The situation is unbearable. These are the messages we’re receiving.
Our colleagues - our friends - struggling to explain what is going on to their children.
#HearTheirVoices
100
678
906
91,915

Did you know, that you can build a virtual machine inside ChatGPT? And that you can use this machine to create files, program and even browse the internet? engraved.blog/building-a-vir…
216
2,045
7,756
Tommaso retweeted

22 Nov 2022
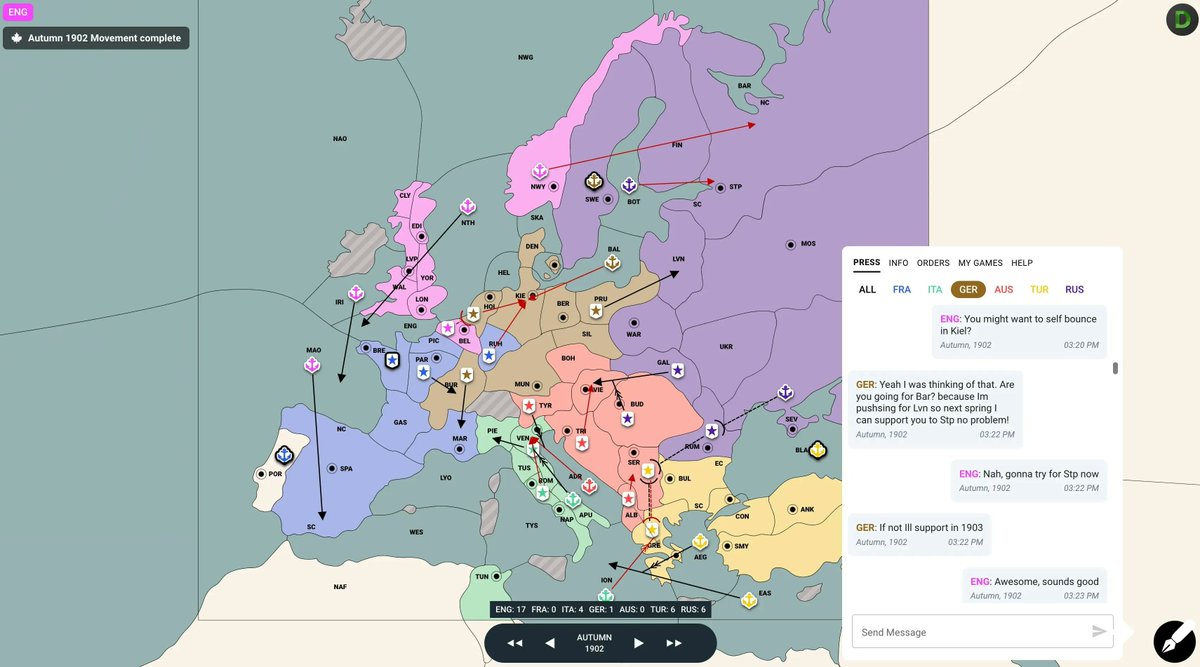
New paper in Science today on playing the classic negotiation game "Diplomacy" at a human level, by connecting language models with strategic reasoning! Our agent engages in intense and lengthy dialogues to persuade other players to follow its plans. This was really hard! 1/5
74
724
3,716
Tommaso retweeted

24 May 2022
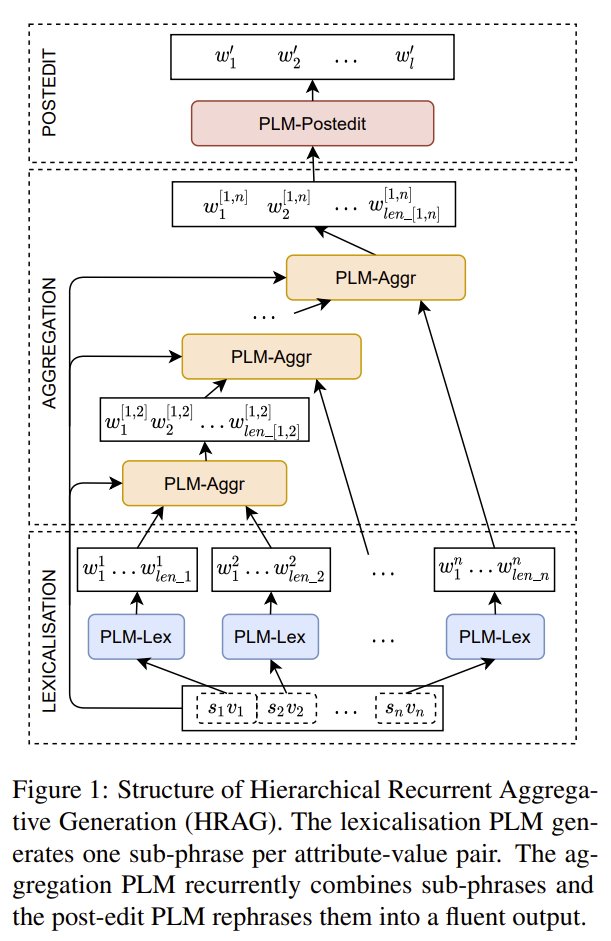
If attending #acl2022nlp in person and fancy blast-from-the-past #nlg, come by our poster between 15:15 - 16:15: "Hierarchical Recurrent Aggregative Generation for Few-Shot NLG" with @GiulioZhou and @iiacobacNLP.
Paper/talk links:
aclanthology.org/2022.findin…
underline.io/events/284/sess…

1
3
21
Tommaso retweeted

22 May 2022
“FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing” with @pasini_t, S. Zhang, L. Tomada, @schwemer, and A. Søgaard - poster on Monday 23 PS3-2 17-18h and orally presented on Wednesday 25 OS6-6 10h45-12h15 3/6
x.com/KiddoThe2B/status/1506…
22 Mar 2022

🚨 Our paper “FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing” with
@pasini_t , S. Zhang, L. Tomada, @schwemer, and A. Søgaard, has been accepted at #ACL2022nlp 🇮🇪. Arxiv pre-print at: arxiv.org/abs/2203.07228. Brief summary: 1/6 🧵👇

1
1
5
Tommaso retweeted

17 May 2022
Super happy that our DiBiMT paper got recognized as the Best Resource Paper @aclmeeting #ACL2022! 🥳🎉
A (not so) short 🧵 about it :) 👇
Joint work with @FedeMartelli25 @FrancescoSaina @RNavigli
📜: aclanthology.org/2022.acl-lo…
1/7
3
7
30
Tommaso retweeted

25 Apr 2022
New work on autoregressive language models for retrieval!
We train our model, SEAL (Search Engines with Autoregressive LMs) to produce text snippets occurring somewhere in the corpus, in relevant documents. We use the generated ngrams to rank documents in the corpus.
Thread 👇
3
42
184
Tommaso retweeted

14 Apr 2022
14 Apr 2022

#NLPaperAlert 📢 We bring together existing resources, revise them, and propose SRL4E, a unified evaluation on Semantic Role Labeling 4 Emotions!
Read our #ACL2022 preprint: researchgate.net/publication…
By @caesar_one_ @ConiaSimone @RNavigli
@ERC_Research @EuroLangTech #NLProc

1
2
11
Tommaso retweeted
6 Apr 2022
Experiment-packed paper over here 👇 (featuring manually annotated data!)
6 Apr 2022
Open & commercial Neural Machine Translation models heavily suffer from disambiguation biases! We present DiBiMT, our novel benchmark for lexical-semantic bias in MT at #ACL2022! By @Valahaar @FedeMartelli25 @FrancescoSaina @RNavigli
@ELEXIS_EU #NLProc
📝:researchgate.net/publication…

3
13
Tommaso retweeted

24 Mar 2022
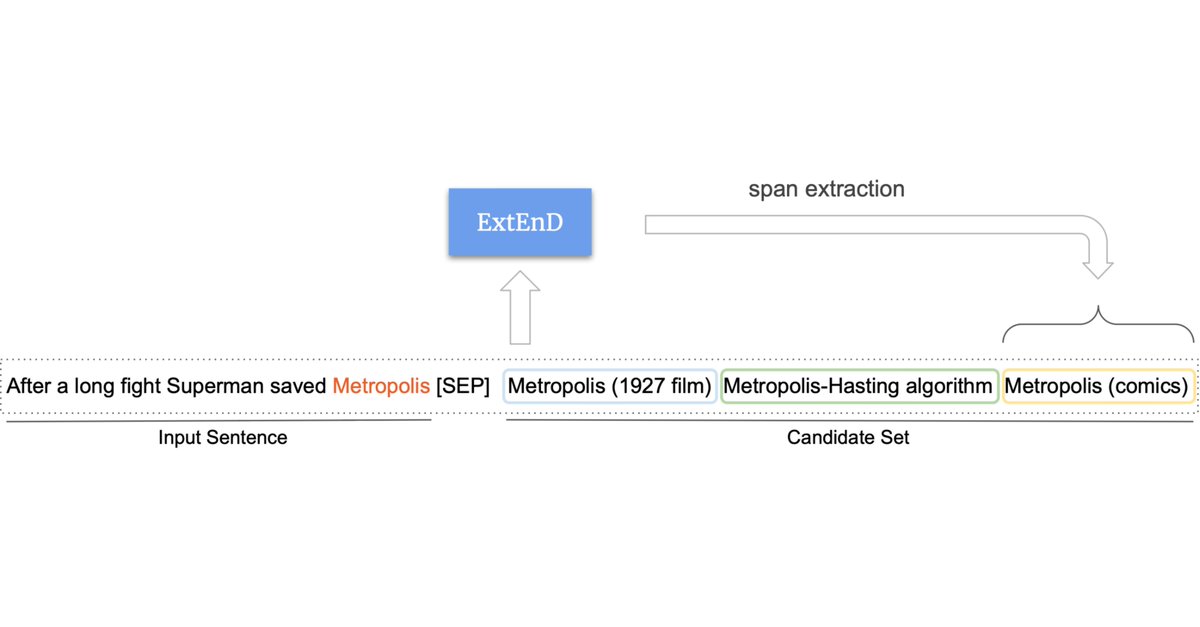
Extractive Entity Disambiguation is our (@edoardo_barba @luigi_proc @RNavigli) new paper at #ACL2022! Guess what, we perform ED as a Text Extraction task using only Wikipedia Titles and achieve a new SotA in standard and constrained data regimes.
@ERC_Research #NLProc
Links: ⬇️
1
16
36
Tommaso retweeted
22 Mar 2022
🚨 Our paper “FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing” with
@pasini_t , S. Zhang, L. Tomada, @schwemer, and A. Søgaard, has been accepted at #ACL2022nlp 🇮🇪. Arxiv pre-print at: arxiv.org/abs/2203.07228. Brief summary: 1/6 🧵👇
3
10
52

Help this poor guy finding this out… <3
10 Mar 2022

Hey, #NLProc if I create a library with recent SOTA models for WSD and Entity Linking (implementation and checkpoints). Would you use it?
1
5
Consider applying! Iacer is a great researcher and more importantly a great person!
7 Mar 2022

Open vacancy for a *fully-funded* PhD on responsible natural language processing #NLProc and data management for mental health at the @UvA_Amsterdam co-supervised by myself and @sscdotopen (please RT!).
Link to apply: vacatures.uva.nl/UvA/job/PhD…
1
4
give this library a try! Its easy to use and great for prototyping! Makes your life easier from bachelor to PhD and on :D Super nice work from three brilliant PHD students I had the chance to work with!!!! 🧐🚀🚀
24 Oct 2021

💜⚡️ Sunday Community Spotlight!
Classy: A PyTorch-based library for fast prototyping and sharing of deep neural network models github.com/sunglasses-ai/cla…
👏🏽 Kudos to @Valahaar @luigi_proc & edobobo on your work!
1
7
Tommaso retweeted

18 Oct 2021
We are finally sharing the code (github.com/iacercalixto/wiki…) to reproduce the experiments in our paper "Wikipedia entities as rendezvous across languages" (aclanthology.org/2021.naacl-…). Check it out! #NLProc @pasini_t @Ale_Raganato
4
13
Tommaso retweeted
6 Oct 2021
I am glad to present the "Legal General Language Understanding Evaluation (LexGLUE)" benchmark w/ a multi-disciplinary research team incl. @abhikjana, Dirk Hartung, @mjbommar, @ionandrou, @computational, and @nikaletras. Preprint: arxiv.org/abs/2110.00976 Mini-Thread 🧵👇 1/10

4
32
82
Tommaso retweeted

8 Sep 2021
📢"An Empirical Investigation of Word Alignment Supervision for Zero-Shot Multilingual Neural Machine Translation"📢 @HelsinkiNLP #EMNLP2021 paper w/ @jraulvc Mathias Creutz @TiedemannJoerg
#NLProc #EMNLP21
paper 👉 raganato.github.io/pdfs/EMNL…
👇
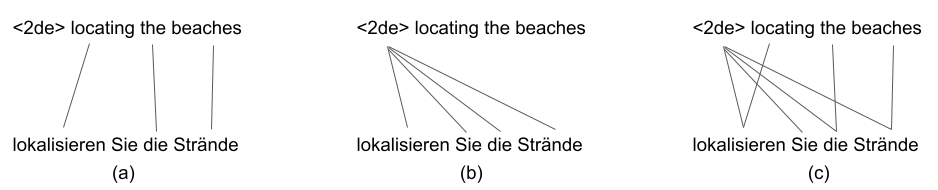
ALT English-German example sentence with different alignment methods.
1
3
11
Tommaso retweeted
6 Sep 2021
🚨Our paper "MultiEURLEX - A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer" with @ManosFergas, and @ionandrou, has been accepted at #EMNLP2021 🥥🌴. Arxiv pre-print at: arxiv.org/abs/2109.00904. Brief summary: 1/10 👇
3
8
46