
433 Photos and videos
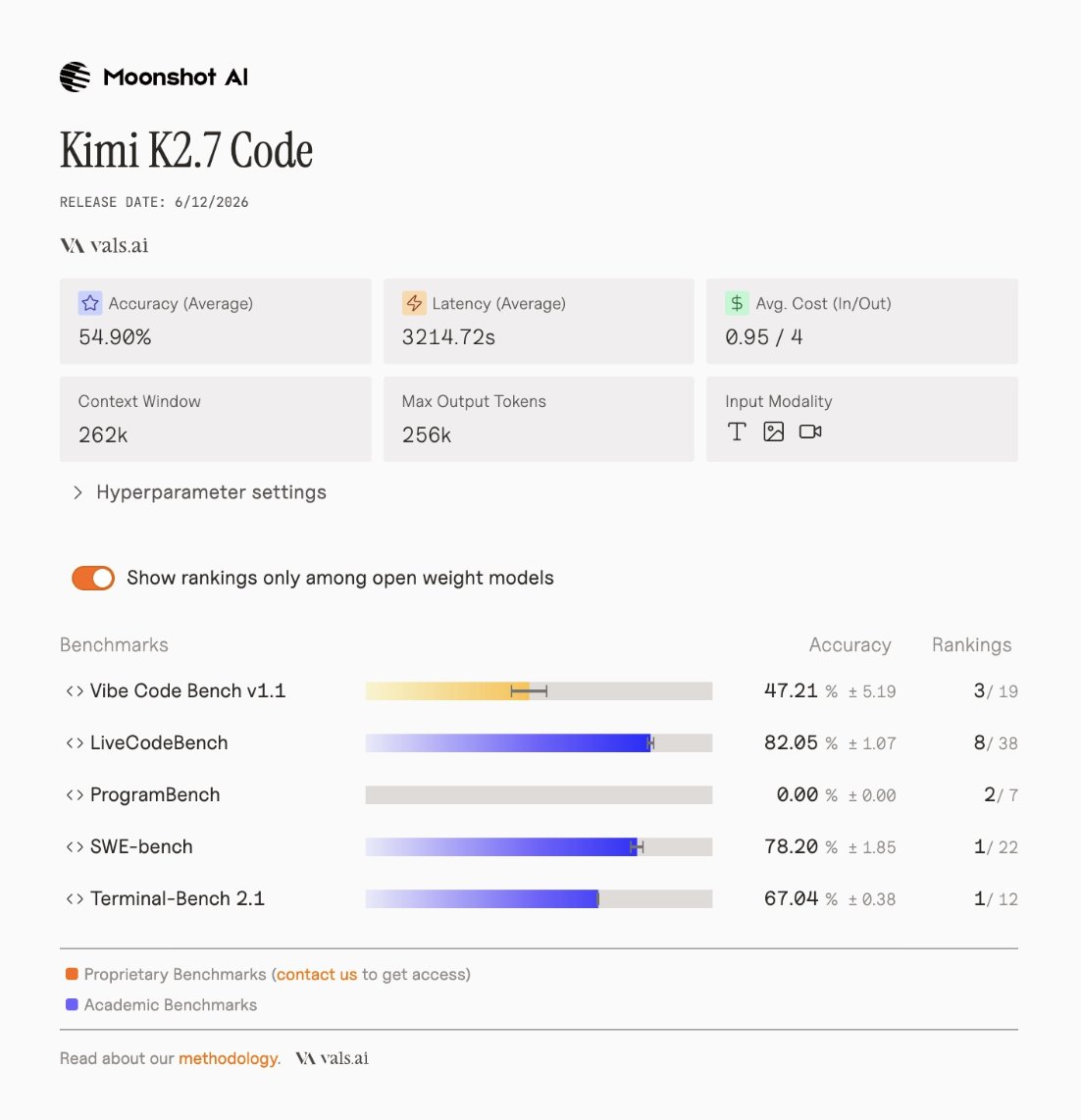

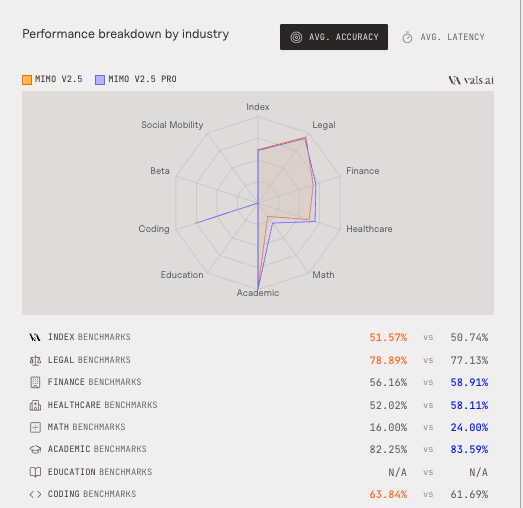








Congrats to the @Xiaomi team on the release. Full benchmark-by-benchmark results vals.ai/models/xiaomi_mimo-v… vals.ai/models/xiaomi_mimo-v…
2
415
Vals AI retweeted

Jun 11
Consistent with Jack Clark Gillian Hadfield's regulatory markets paper 3 years ago. Private orgs are often better at building tech needed to keep up with the market rather than slowing it down. But need the right incentive structure to be public good aligned.

Jun 10

Today I'm publishing a new essay, Policy on the AI Exponential. AI is progressing extremely fast—much faster than the policy process was built to handle. The essay lays out where I think the technology is now, and the action needed to close the gap: darioamodei.com/post/policy-…
1
4
17
3,221
Vals AI retweeted

Jun 10
Update: They listened!! Great transparency and quick reaction, kudos :)

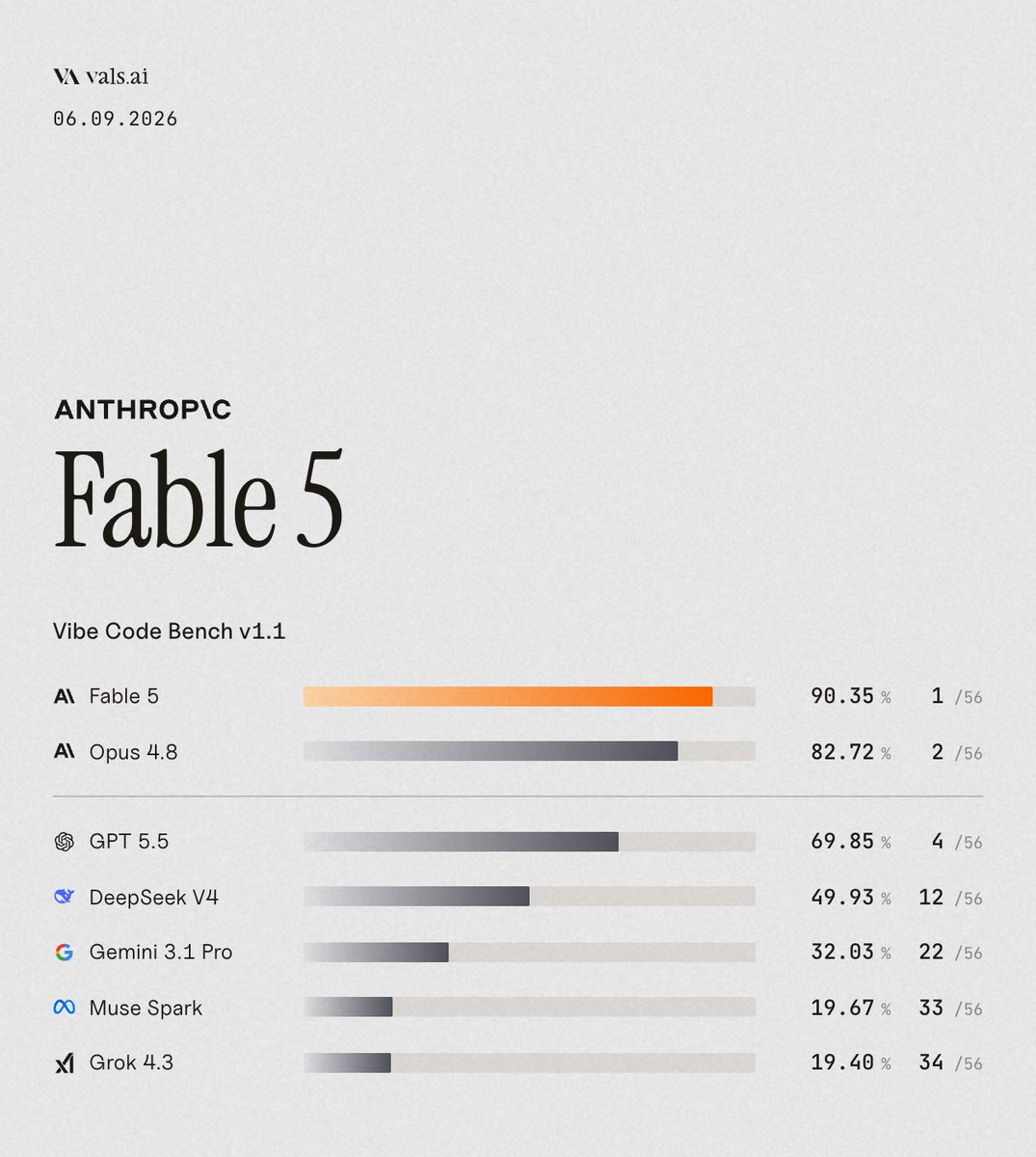
We have added the ability to view Fable 5 scores with Opus 4.8 fallbacks disabled to the Vals AI website (refusals are marked as zero).
The eval community was ill-equipped for this, but transparency is our first priority.
We’re anticipating more models like this, and are developing our official policy going forward.
2
2
38
2,945
Vals AI retweeted
Jun 10
The benchmark challenge is one of the existential risks to AI progress
1
1
13
2,353
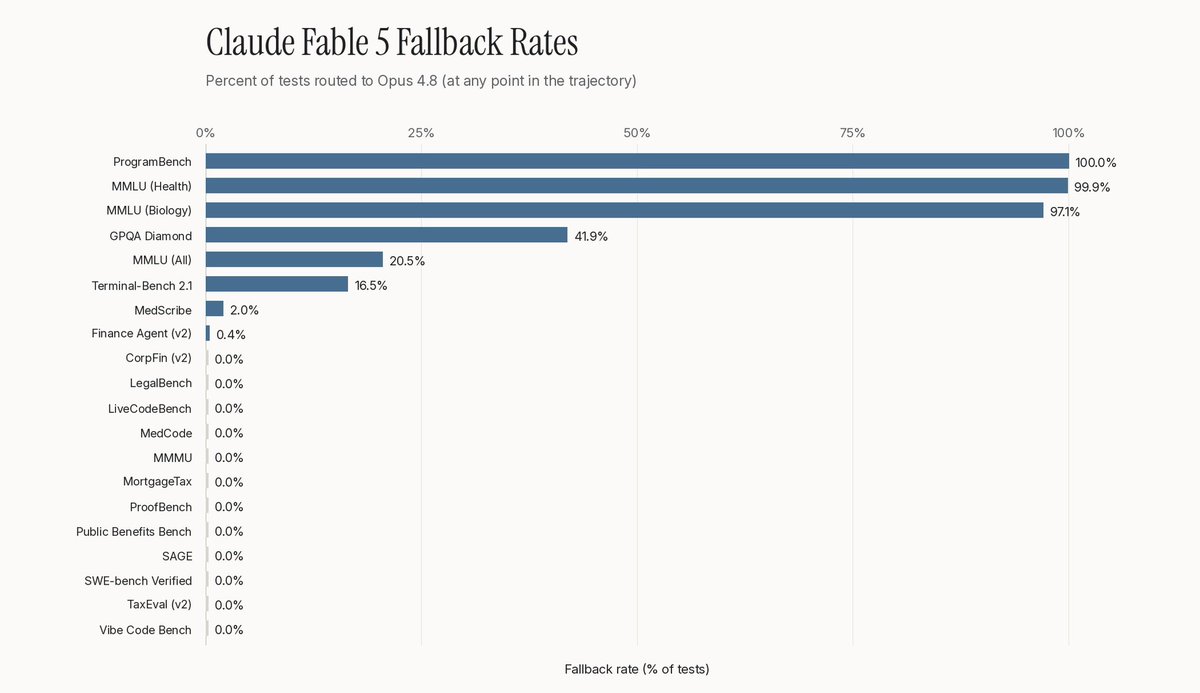
We are also releasing the per-benchmark fallback rates.
The majority of benchmarks had no or very low fallback rates, but as mentioned in our previous post, the safety classifier was highly sensitive to certain benchmarks.
For example, MMLU Biology and Health have nearly a 100% rejection rate. ProgramBench also has a 100% rejection rate, likely due to the phrase “reverse engineer” being present in the system prompt.
2
1
24
2,989
Going forward, evaluations will have to report not only on capability, but also how much of that capability is available to users.
We will soon be sharing updated methodology on tracking and reporting APIs that ship with fallback models or have high rejection rates.
1
1
17
822
We have added the ability to view Fable 5 scores with Opus 4.8 fallbacks disabled to the Vals AI website (refusals are marked as zero).
The eval community was ill-equipped for this, but transparency is our first priority.
We’re anticipating more models like this, and are developing our official policy going forward.
8
15
181
21,205
Vals AI retweeted

Jun 9
What I find fascinating with Claude Fable 5 is it proves once again that large generalist models will outperform vertical ones.
On ProofBench (graduate-level formal math benchmark in Lean, where a proof either compiles or it doesn't) Fable 5 beat Harmonic's Aristotle, 77% vs 71%.
Aristotle is a system built specifically for formal math run on its own internal harness, so the generalist beat the specialist on the specialist's home turf.
It's the Richard Sutton's "The Bitter Lesson". His whole argument is that across 70 years of machine intelligence research, the methods that win are the general ones that scale with compute. Not the ones where we hand-encode human expertise. Building our own knowledge into the system feels good and helps short term gains but long term it always gets overtaken by bigger model.
You can look at Chess, Go, speech, vision, same story every time. First the specialized model wins, then the general one takes over.
and btw this is the whole premise of AGI. You don't build one model for math, one for code, one for law. you build a single general model that scales with compute and it learns to do everything

38
63
612
65,724