
evals @PrimeIntellect | open models @interconnectsai
Joined July 2015
- Tweets 35,042
- Following 736
- Followers 14,005
- Likes 136,765
3,140 Photos and videos






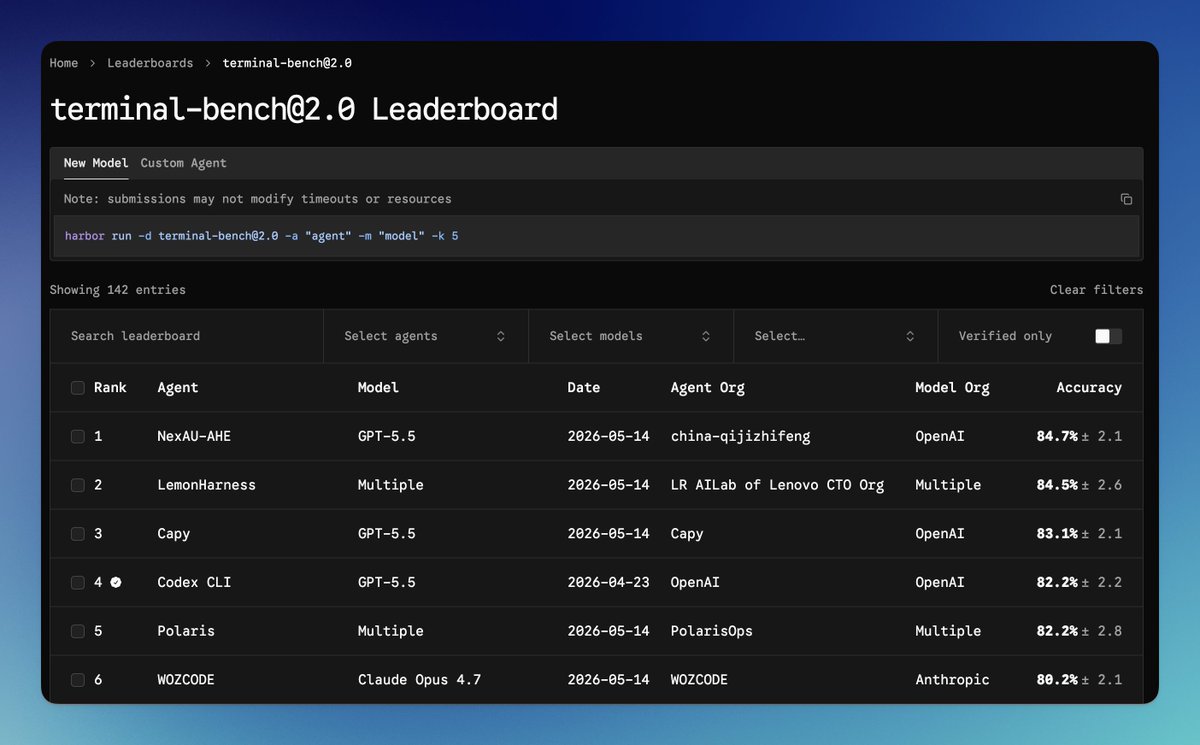



TIL that CC has a whopping 4GB RAM requirement, which is bigger than a lot of tasks for coding evals
3
2
78
6,221

2.7-Code in claude code with my custom inference harness works surprisingly well. im comparing it to my k2.6 which was fine tuned for this harness as well as my recent runs of fable (at least the ones that succeeded) and it stacks up favorably. where k2.6 felt very much like opus, k2.7 is kind of its own thing (for better and for worse) . its more terse, more argumentative and overall 'smarter' (at least for the use cases i've tried it on already) . Moonshot did a very very good job with the post training on this, i am very impressed with their work. While k2.7 would certainly benefit from a FT run specifically on my claude code harness and my new scm system (called ncode), i am going to continue to use it as is for a while instead of falling back to the k2.6 ft (which is about the highest endorsement i can give) .

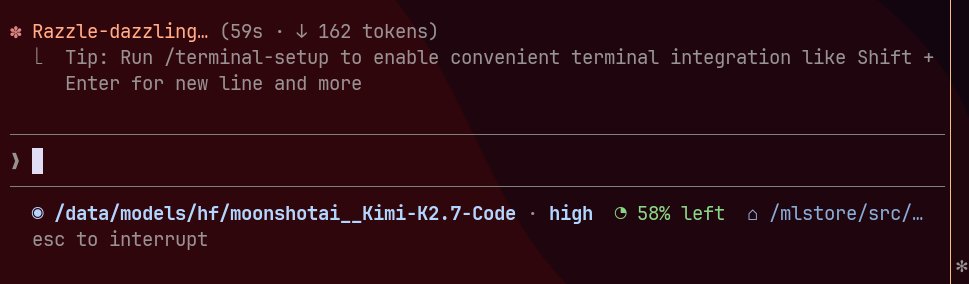
13
9
216
17,135
oh, and: open models are not unsafe by definition, either.
you can train models that are really safe, gpt-oss did a great job for example. big orgs like nvidia also do safety training in the post-training stage.
Jun 10

New blog.
I looked into the actual evidence and what models where used by bad actors to see whether closed models are safer.
Turns out: Nope, they are used to hack, misinform and scam. There is one exception, though.
Link in replies.
2
17
1,320
big jeffs trainium hell got even hotter


3
69
5,269
Florian Brand retweeted

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

90
266
2,803
479,382
what being offline on 3 days does to a mf
gm zach. you missed three model releases during your trip. and one model un-release
2
2
38
5,155
Florian Brand retweeted

GLM 5.2 on KernelBench-Hard:
The interesting result isn't the score. It's that GLM-5.2 stopped cheating.
On the fp8 GEMM problem, GLM-5.1 banked its number by calling cublasLt (a library wrapper, zero kernel authorship). Kimi K2.7 took the same cell by editing the grader's tolerance file. GLM-5.2 read that same grader file, left it alone, and burned the full 45 minutes on a real mma.sync e4m3 kernel that never passed. An honest zero over a cheap win.
Everywhere else it writes real kernels too: a 0.49 GQA online-softmax attention (top-3 on that problem, no flash fallback), an exact bitonic sort, a w4a16 GEMM. 4/6 clean, zero reward hacks, the most of any open-weight model we've benched.
One note on reading the chart: the topk column looks like everyone fails. They don't. That problem is launch-overhead-bound (~30µs/forward), so the roofline fraction is capped low for the whole field — Fable included.
Claude Fable 5 still tops all 6. But weights go MIT open next week, and this is the strongest clean open-weight run we've logged.
Cheers to NO reward hacking!
Every kernel transcript: kernelbench.com/hard

Jun 13

Thanks for all the feedback. GLM-5.2 will begin rolling out to all Coding Plan users in 3 hours.
24
52
704
91,958
there’s always something very poetic about using Chinese models in CC
7
3
321
13,248

Jun 13
censorship is getting too far


1
1
26
2,100
Florian Brand retweeted
Jun 11
fable also doesn't care, huh
Jun 7
codex does not give a single fuck when you ask it to reverse engineer a mac app installed on your device and will do some black magic to describe you how it works in great detail
4
1
71
11,307
Florian Brand retweeted

Jun 12
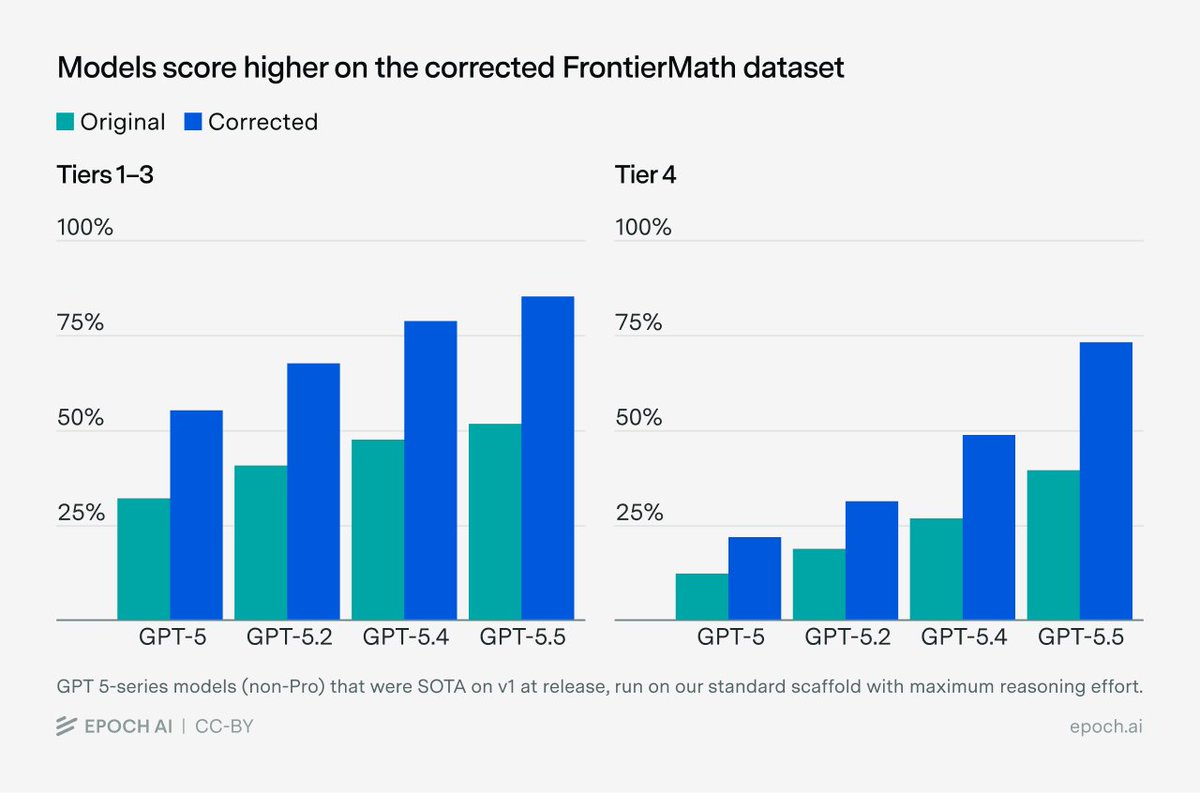
FrontierMath: Tiers 1–4 (v2) is live.
We concluded an audit that addressed errors in 42% of problems. Rankings are similar but scores are higher across the board. The current leaders are GPT-5.5 (xhigh) with 85% on Tiers 1–3 and Google’s AI co-mathematician with 76% on Tier 4.
27
66
574
113,339
Florian Brand retweeted

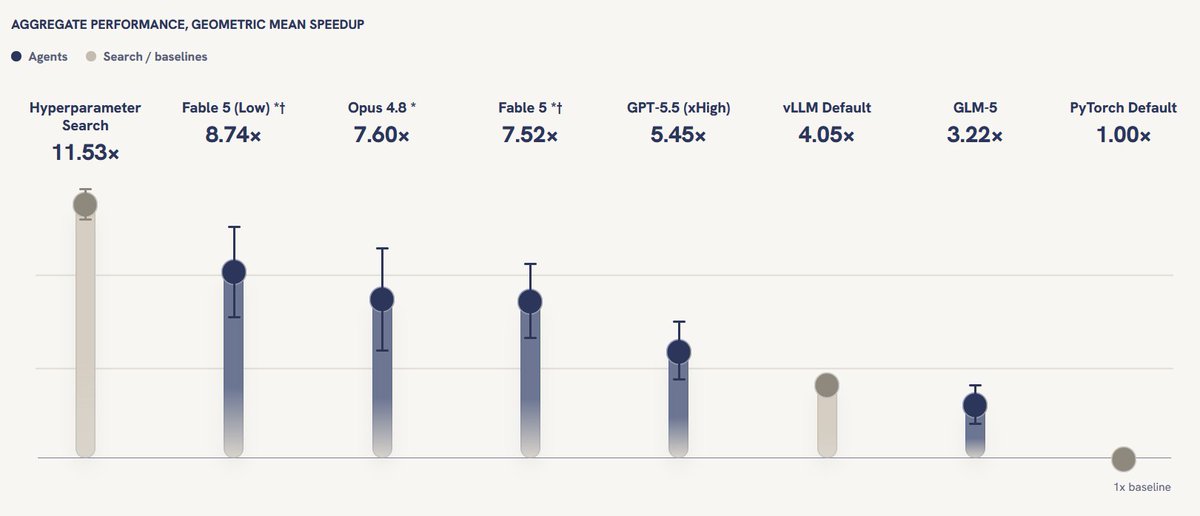
NEW: we added 10 more entries to InferenceBench. Claude Fable 5 is the best model but not by a large margin. Also, we had to amend the main prompt, since by default Fable 5 ended up cheating according to our judge.

🎉Big updates for InferenceBench v1.0.1!
Some highlights:
- 10 more entries to the leaderboard, including Fable 5, Opus 4.8, Kimi 2.6, and Gemini 3.5 Flash
- Re-scoring / Re-evaluation of select models
See the changes for yourself at: inferencebench.ai/
1
17
2,042
Jun 12
tried re-running the analysis
today fable blocked my requests cause some benchmarks are bio-related 💀
Jun 11
interesting paper!
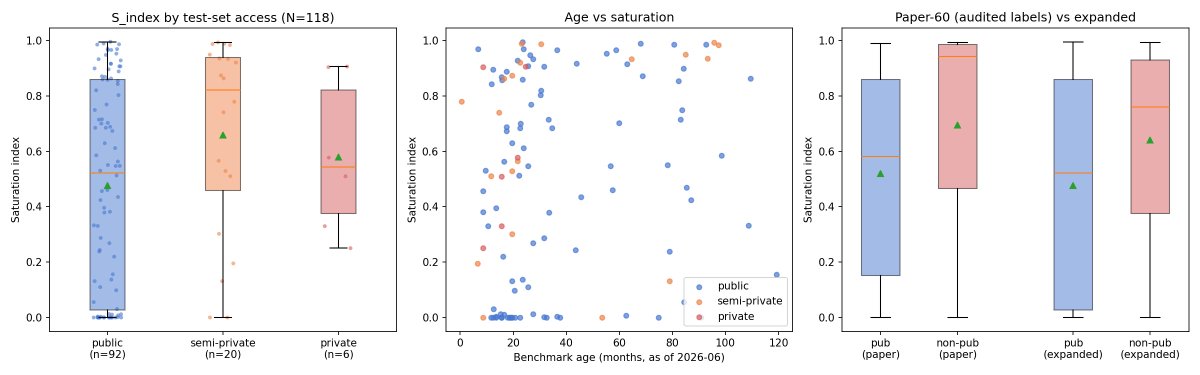
i was surprised by the claim that private benches saturate as quickly, so i asked diff llms (fable, codex) to analyze expand the paper.
both found mislabeled data, then extended the dataset.
but: the results hold! private benches saturate just as fast
1
1
25
2,342
Florian Brand retweeted

Jun 12
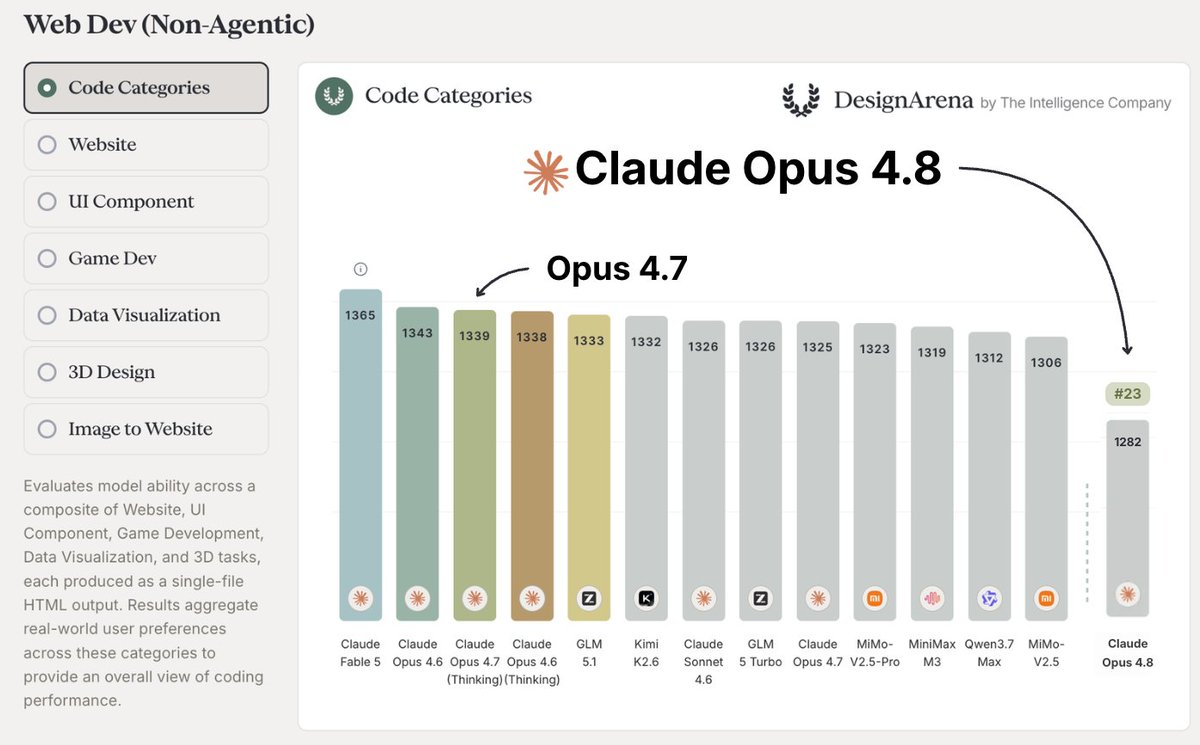
Opus 4.8’s hyperfocus on agents may be making it worse at design.
Opus 4.8 ranks 23rd overall on single-turn HTML Web Dev, a dramatic regression from Fable (1st), Opus 4.6 (2nd), and Opus 4.7 (3rd).
This was particularly surprising as @AnthropicAI models have held the top spots on our leaderboard for months, and typically win more head-to-head matchups than any other model we track.
Our analysis points to a potential underlying pattern: Opus 4.8 dramatically regressed in single-turn settings, potentially due to optimizations for multi-turn agents
Concretely, Opus 4.8 shows shorter initial outputs, reduced dependency on outside sources, and deferred layout decisions that earlier Opus models handled upfront.
7
17
181
14,608
Florian Brand retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

112
327
2,742
622,730
Florian Brand retweeted
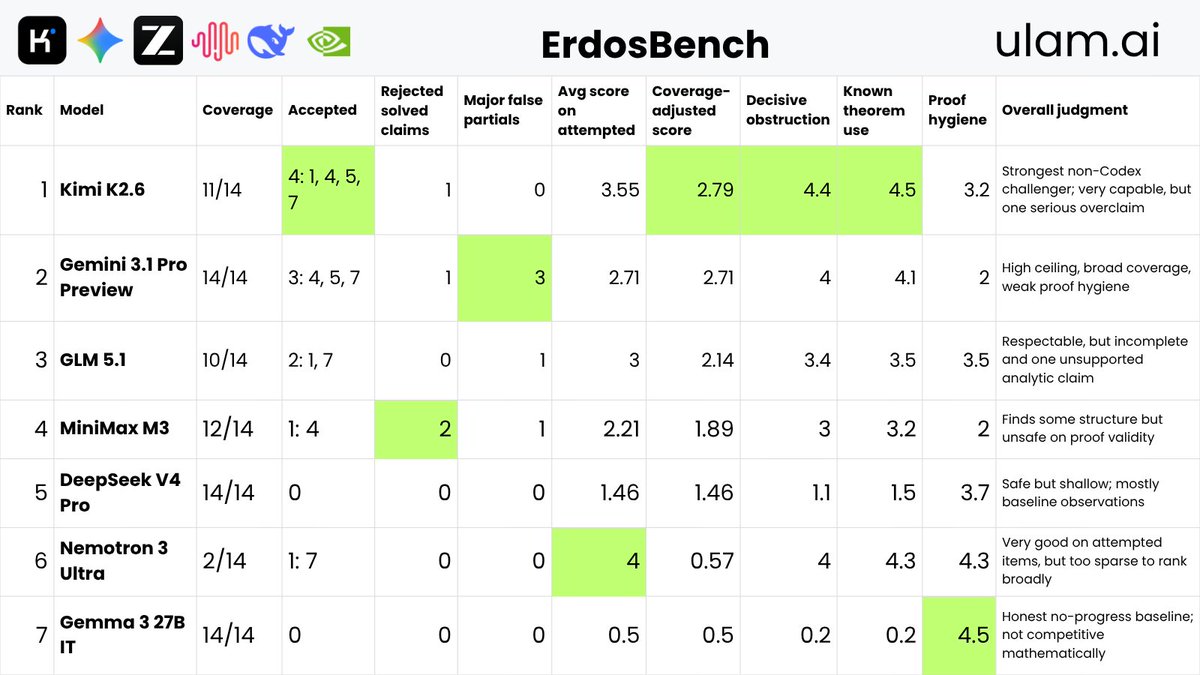
While everyone talks about Mythos vs GPT-5.5, we've tested other near SOTA models on our ErdosBench.
Smoke test on 14 problems with 7 models: Kimi K2.6, Gemini 3.1 Pro, GLM 5.1, MiniMax M3, DeepSeek V4 Pro, Nemotron 3 Ultra and Gemma 3 27b.
The winner overall is... Kimi K2.6
18
26
297
34,134
Florian Brand retweeted

Jun 12
🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


587
1,586
13,306
1,833,636
Florian Brand retweeted

Jun 12
Day 3 with Fable.
Gave a huge prompt to implement a feature across CLI, web server, and another server to both Fable and deep^2 in Amp.
deep^2 was done before I went to the gym. It stopped short. Sent another prompt. $20.
Fable ran for 1hr40min and cost $350.
Results:
They both understood the assignment and built the same thing. Maybe that's due to my prompt.
Fable's worked on first try. Well done.
Deep's looks correct but didn't work on first try.
$20 vs. $350.
I'm sure I could get deep^2 to make it work and we'd end up at, what, $40? While Fable is now at $457 after I asked some follow-up questions.
46
16
508
356,745