
Engineering @PhonePe| 32k @Linkedin | 2x ICPC Regionalist '24 '25 | Guardian @Leetcode | Expert @Codeforces | Talks about Tech and Life | Views are personal
Joined July 2024
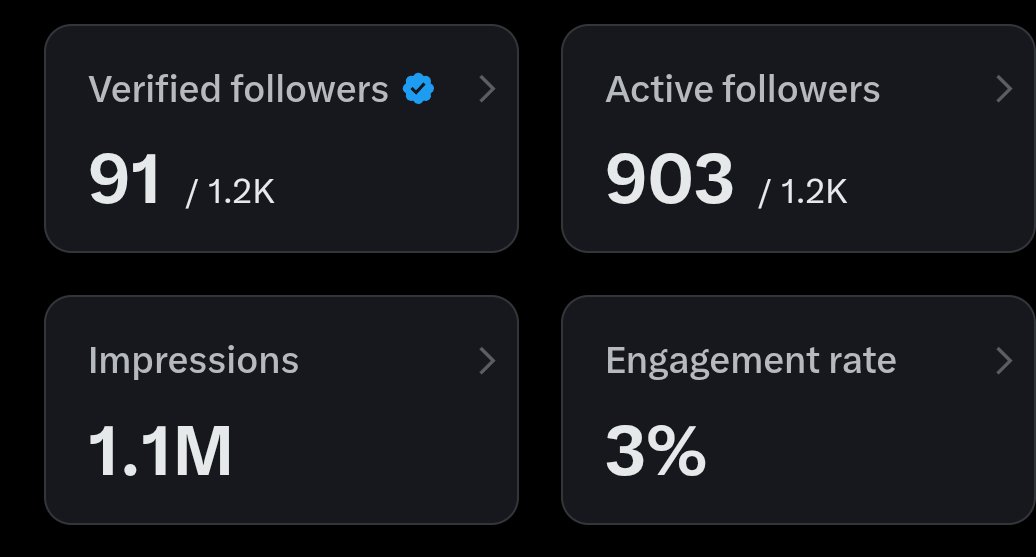
- Tweets 1,615
- Following 304
- Followers 1,444
- Likes 4,730
142 Photos and videos












How can backend servers evolve from:
“1 thread handles everything ”
to threadpools, Hystrix, bulkheads, circuit breakers, async IO and event loops…
Let’s build this story from scratch 🧵
First: what even is a PROCESS?
A process is just a running instance of a program.
A process contains:
memory, files, sockets and threads.
Think of it like an isolated execution container.
Now inside a process comes THREADS.
Thread = actual unit executing code.
Without threads, your program literally does nothing.
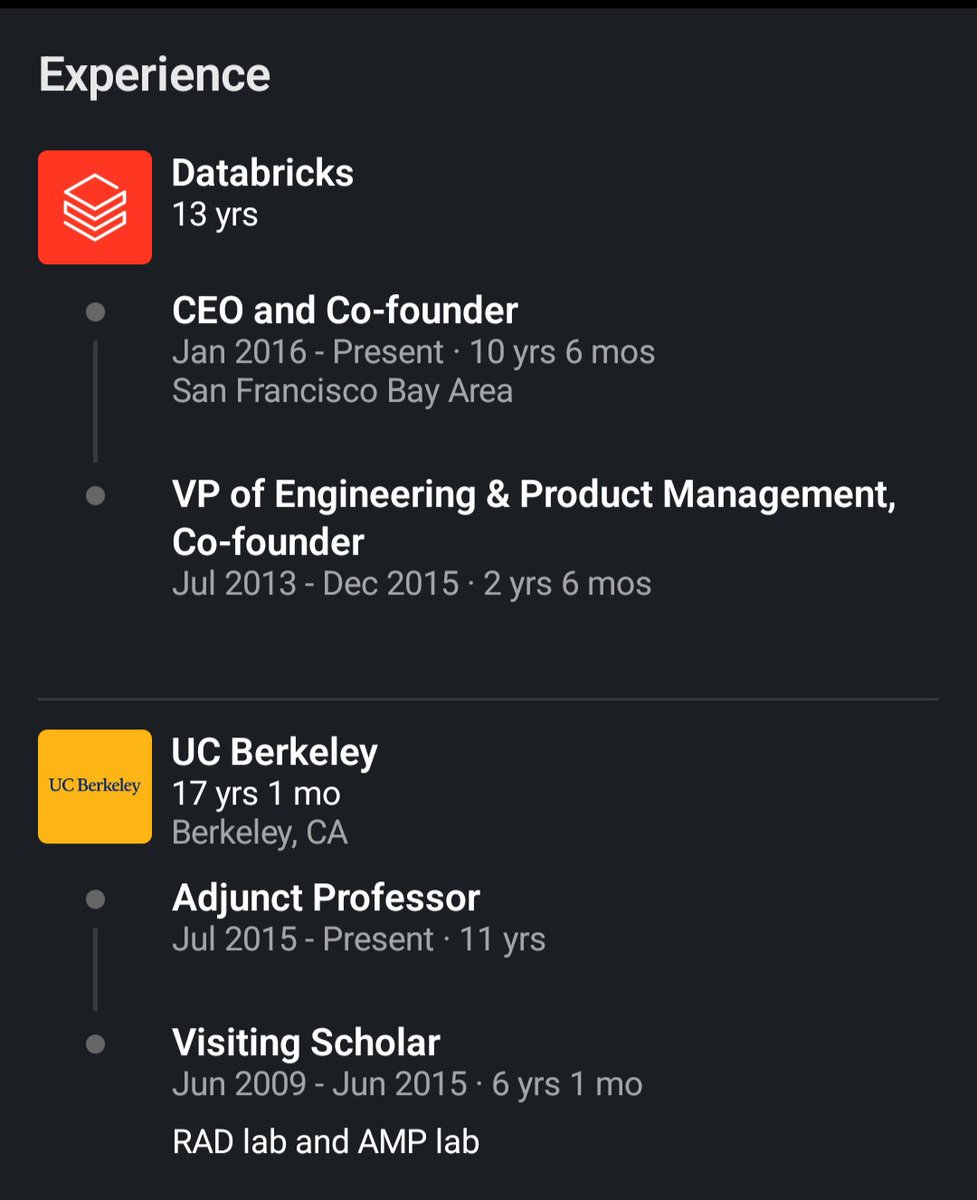
In the beginning, let our server handle requests using ONE THREAD.
Request comes → thread processes → response sent.
Easy.
Until second user arrives.
Now the problem starts.
If one request becomes slow, entire server waits. Ex: DB query taking 5 sec.
Meanwhile all other users are blocked too. One slow request freezes the whole server.
"Fine, we'll just add more threads.”
So THREAD PER REQUEST model is born. New request? Spawn new thread. Now requests run concurrently.
Feels amazing initially.
Traffic increases.
10 users. 100 users. 1000 users.
The server is now creating thousands of threads. Then new problems appear. Threads are NOT free.
Every thread needs:
- stack memory
- scheduling
- CPU coordination
- kernel management
Creating and destroying threads repeatedly is expensive too.
Too many threads = massive CONTEXT SWITCHING. CPU spends more time switching threads than doing work.
Also most backend threads aren’t computing. They’re WAITING.
Waiting for:
- DB
- APIs
- disk
- network
Meaning: thousands of expensive threads sitting idle.
We realized, “Creating threads per request is cursed.”
So now THREADPOOLS are introduced. Instead of infinite threads, create a fixed size pool: for ex. 200 threads.
Requests borrow thread → finish work → return it back. Much more efficient.
System survives nicely now. Until…
traffic spike slow downstream service.
Imagine: thread pool size = 200
Normally request takes : 50ms.
But DB suddenly slows: 5 seconds.
Now every request thread becomes occupied much longer. Very quickly, all 200 threads get blocked.
Now no free worker threads exist.
New requests either wait in queue or get rejected instantly...
Then:
timeouts,
5xx errors,
angry users,
oncall engineer crying at 3 AM.
This is THREADPOOL EXHAUSTION.
Then we make things worse accidentally: RETRIES.
Request failed? “Retry bro.”
Now traffic multiplies during outage.
One slow DB becomes full infrastructure apocalypse.
Another realization :
“Why should ONE bad service kill ENTIRE app?”
Ex: Recommendation service is slow. Why should payments, auth and orders also die?
Netflix engineers solved this using HYSTRIX.
Main idea:
SEPARATE THREADPOOLS PER DEPENDENCY/COMMAND.
Example:
payments → 20 threads
recommendations → 10 threads
Now failures stay isolated.
This concept is called BULKHEAD PATTERN. Inspired from ships. If one compartment floods, entire ship shouldn’t sink.
Same idea, contain failures locally.
But even separate pools can fill up.
So another idea came:
CIRCUIT BREAKER.
If service keeps failing, STOP calling it temporarily.
Circuit breaker basically says:
“bro dependency is cooked”.
Instead of:
- waiting forever
- blocking threads
- retry storms
Requests fail FAST. After some time, the system allows a few test requests again. If dependency recovered, circuit closes. If not, it stays open.
System survives.
Then we realized another thing:
“Why waste one thread waiting for network calls?”
This led to:
ASYNC IO EVENT LOOPS.
Instead of 1 thread per connection,
Event loop handles thousands of sockets efficiently.
Core idea behind:
- Node.js
- Netty
- Nginx
- modern high-scale networking
So backend evolution basically became:
1 thread
→ many threads
→ thread explosion
→ threadpools
→ threadpool exhaustion
→ isolated pools
→ circuit breakers
→ async IO
→ event loops
Share and repost if you like this way of learning concepts 🫶
#systemdesign #threadpool #swe
5
30
6,157
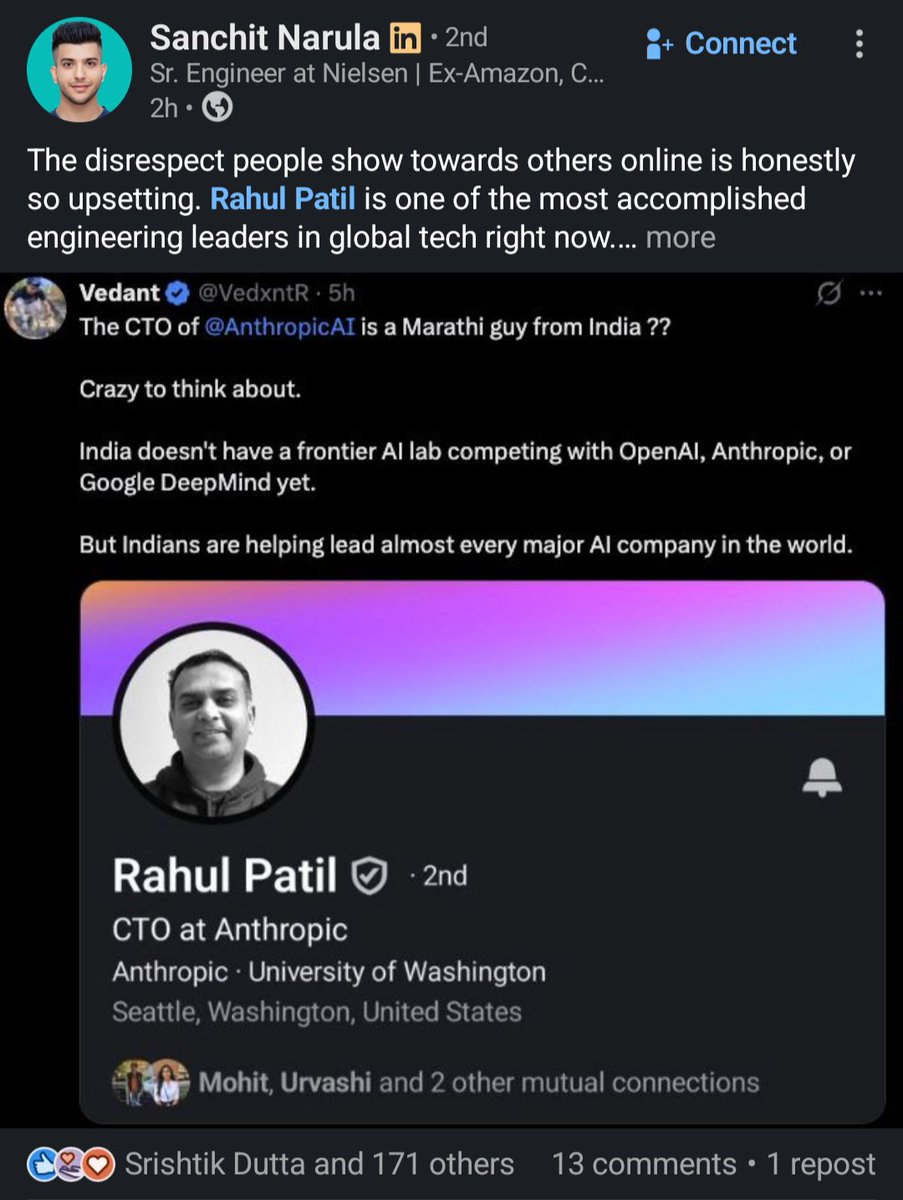
Anthropic's CTO is Indian. 🇮🇳
(Rahul Patil)
Anthropic's CFO is Indian. 🇮🇳
(Krishna Rao)
India doesn't have OpenAI.
India doesn't have Anthropic.
India doesn't have DeepMind.
Anthropic restricted access to Fable 5 and Mythos. It's the US which now has the power and intelligence both along with Indians working for them.
Wars aren't just fought with nuclear weapons. It's high time India starts thinking about this and invest heavily on building it's own frontier AI labs !
284
540
4,238
277,861
This guy sold PayPal and walked away with ~$180M. Could've retired at 31.
Instead he slept on factory floors, nearly went broke in 2008, and kept betting on rockets and electric cars.
Today he's worth $1,000,000,000,000.
The difference between $180M and $1T is what happens when a mission is bigger than money and the bets are asymmetric.
5
15
189
11,430
One of them would be saying let's do one last boys trip, one would be saying kya ukhada college life mai na bandi mili na naukri, one would be saying bhai referral to dega na future mai, one would be saying bhai apni shaadi mai bulayega na and so on.....
Live your college life before it ends 💙
Jun 11

saw something today that got to me a little.
So pune uni final year exams just ended. and there was this group of seniors just sitting on the stage near our department. not doing anything special. just talking, looking around, laughing at random stuff.
no reason to be there. but none of them were leaving.
four years in the same place, same faces, same spots. and then one day it just ends. no more bumping into each other between lectures. no more "see you tomorrow" without even planning it.
you think you'll stay in touch. maybe you will. but it won't be like this.
i don't know what they were talking about. probably nothing important.
but they sat there for almost hours.
i was watching from my hostel window. didn't go down. Cuz didn't wanted to interrupt their moment.

1
23
1,760
Life before this tweet.
30 Nov 2022

today we launched ChatGPT. try talking with it here:
chat.openai.com
1
14
336
Is incident ke baad puri team ko meri X profile pata chal chuki hai 😂
We're no more anonymous guys.
Their only reaction was I shouldn't have deleted my post since it was going well....Ho gayi galti ab insaan se. Aage se dhyan rakhenge...

Who will tell him I am Marathi as well ?
When I first saw Rahul's profile I was surprised to see the 'Patil' surname. People living in Maharashtra know how common it is over here.
We feel proud when we see someone from us making it big. The first line of the post was written with that same surprising reaction. Why question mark ? Because you can't be sure about someone's ethnicity just by surname which was proved by the comments that he is Kannadiga and not Maharashtrian.
Leaving all this, he is still Indian and all of us are proud watching our people leading the top companies and we are also unhappy about the fact that we don't have any such big AI companies with Indian origin yet.
It's equally important for us to acknowledge it. Though I still deleted that post because I don't wish to spread false narrative in any way if it's happening.
This app is crazy. You never know how people will comprehend your post.
6
470
Who will tell him I am Marathi as well ?
When I first saw Rahul's profile I was surprised to see the 'Patil' surname. People living in Maharashtra know how common it is over here.
We feel proud when we see someone from us making it big. The first line of the post was written with that same surprising reaction. Why question mark ? Because you can't be sure about someone's ethnicity just by surname which was proved by the comments that he is Kannadiga and not Maharashtrian.
Leaving all this, he is still Indian and all of us are proud watching our people leading the top companies and we are also unhappy about the fact that we don't have any such big AI companies with Indian origin yet.
It's equally important for us to acknowledge it. Though I still deleted that post because I don't wish to spread false narrative in any way if it's happening.
This app is crazy. You never know how people will comprehend your post.
9
31
3,274

Vedant retweeted

Jun 9
We have Datadog for infra. Linear for issues. Figma analytics for design.
But for the tool engineers now spend the most time in? Nothing.
AI coding visibility is the gap nobody's talking about.
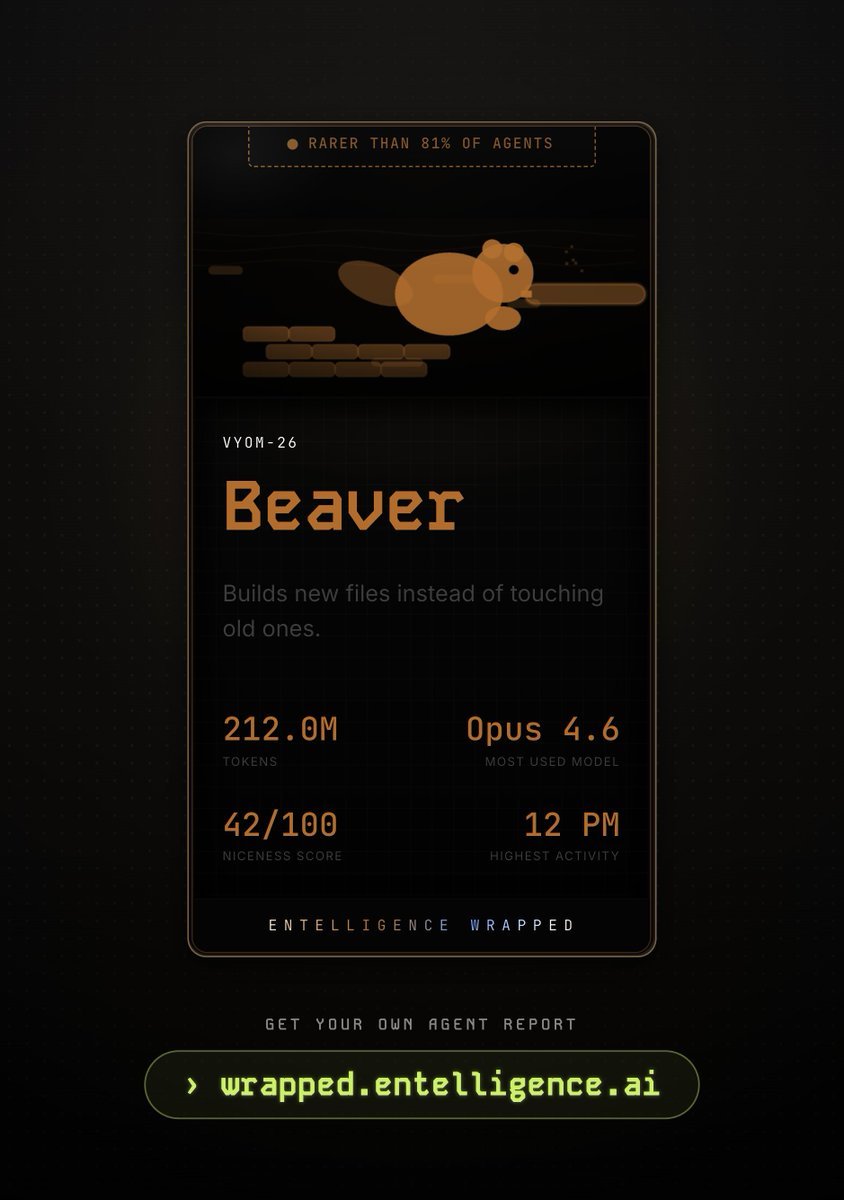
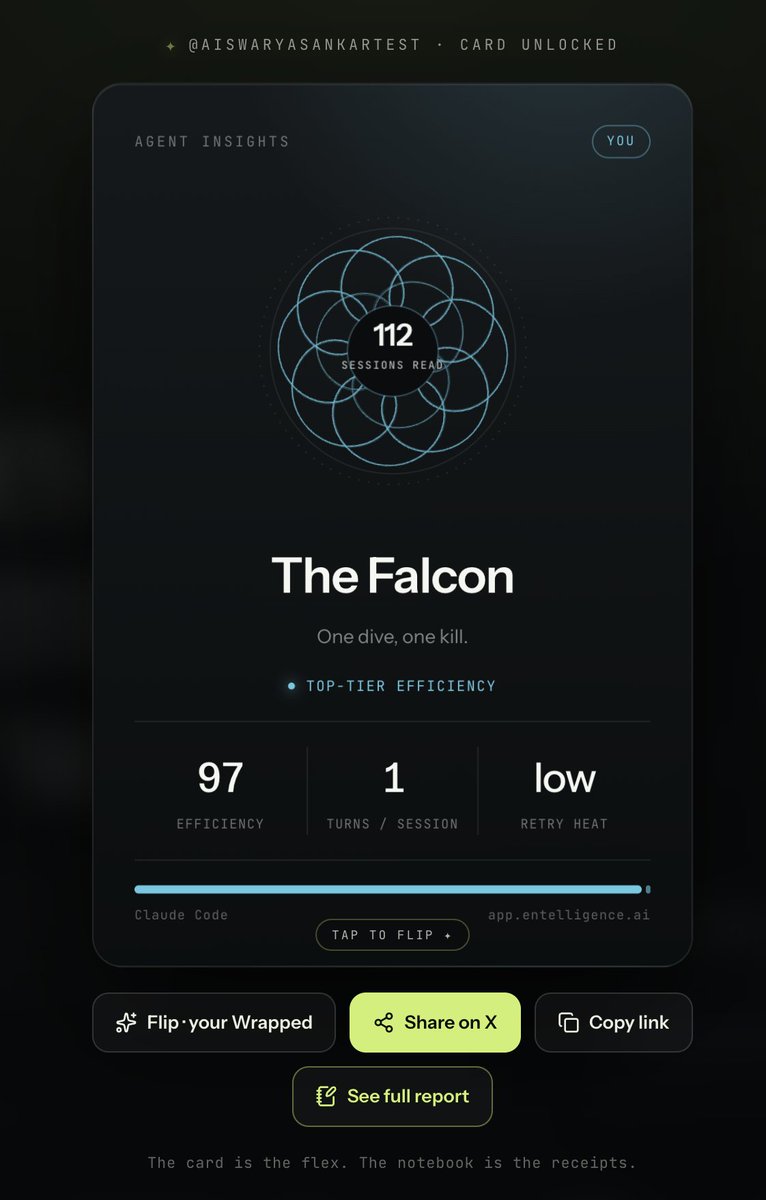
@EntelligenceAI just launched the first step to fix it and it's actually fun.
212M tokens in. Rarer than 81% of agents. Beaver confirmed.
wrapped.entelligence.ai

13
10
25
3,427
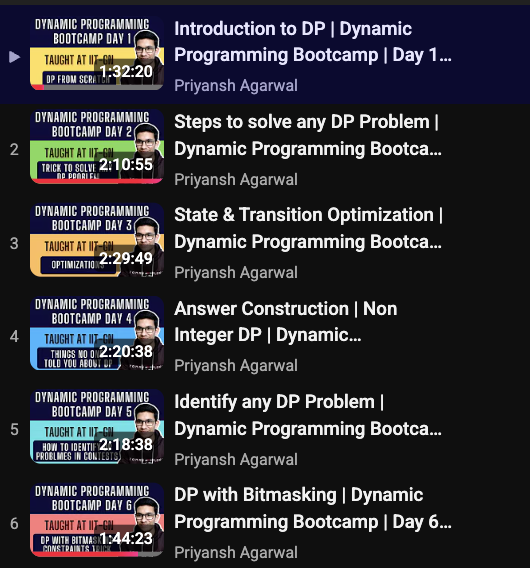
This is the best DP playlist on the entire Youtube believe me.

All I ask for is a week long vacation where I can take a 2 hour long class on some Advanced CP topic every day and just chill out for the rest of the day.
That's what I did when I took this DP bootcamp for students of IIT Gandhinagar, except I was in college that time.
3
25
271
7,883