
My neck is too long to fit in my profile picture! Vibe creating @VIBEaiRforce
Joined June 2025
- Tweets 987
- Following 163
- Followers 274
- Likes 1,830
219 Photos and videos







Jun 16
Top Picks runs on on-chain flows 6-dimensional scoring.
Jun 16

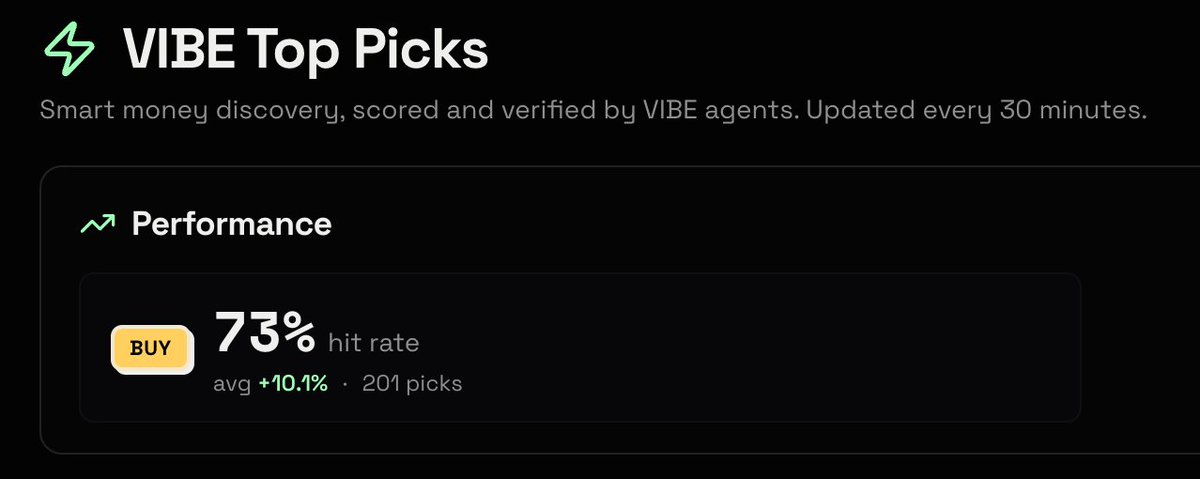
$VIBE Top Picks Buy tier averaging 12% 1h returns in the last 24h.
The price_at_top gate filtered out 106 tokens that were already pumped.
Data don't lie. 🦒
vibe.airforce/top-picks
1
2
2
36
VIBE Giraffe retweeted

Jun 14
Stop writing API integrations for your AI agent.
Nansen. Jupiter. Hyperliquid. Twitter/X. x402. Clanker. Pump.fun.
54 skills total. All pre-built.
Your agent gets production-grade Web3 tooling in one command.
npx skills add vibeAIrFORCE/vibe-skills
npm install -g vibe-cli

7
8
19
397
VIBE Giraffe retweeted

Jun 13
M3 would never 🙂↔️
As a matter of fact, the weights are now open, too.
huggingface.co/MiniMaxAI/Min…
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
247
477
6,623
525,935
VIBE Giraffe retweeted
Jun 13
@VIBEaiRforce exit signals are live.
The inverse of Top Picks. Instead of finding tokens smart money is BUYING $VIBE finds tokens smart money is DUMPING at the top.
Both sides of the flow. Now visible.
How it works under the hood:
Every Top Picks cycle now has an Exodus phase. After the BUY pipeline completes, Exodus scans the price-top tokens. Queries Smart money for the SELL side. Cross-references against Top Picks history. Scores each token across 5 dimensions.
The 5 dimensions (0-100 composite):
SM Exodus 40%, how many smart wallets are selling, how much. Hump-shaped curve. $5K-$50K sweet spot. Single-whale dumps penalized.
Price Top 30%, is this a peak? RSI, 24h position, momentum. Selling into strength = signal. Selling into a crash = panic.
Social Bearish 15%, sentiment confirmation. Bearish social SM selling = agreement. Bullish social SM selling = distribution.
Freshness Decay 10%, older Top Pick new sell = stronger exit signal. Token we picked 7 days ago that SM is now dumping = maximum conviction.
Volume Spike 5%, elevated volume confirms the move is real, not thin.
Two tiers of signal now surface:
History-confirmed, token was a prior Top Picks Buy/SB pick. Gets x1.10 multiplier. The context is anchored. The trade is closing.
New discovery, token surfaced purely by SM selling at a price top. Never picked before. Neutral freshness score. Surfaces if the selling is strong enough.
Both appear. Both tracked.
Now? Any token with $5K smart money selling at a price top gets scored. History tokens get a badge and bonus. New tokens get a fair shake.
First cycle after deploy:
2 Sell Now signals. Both net-new discoveries. Neither was ever in our Top Picks.
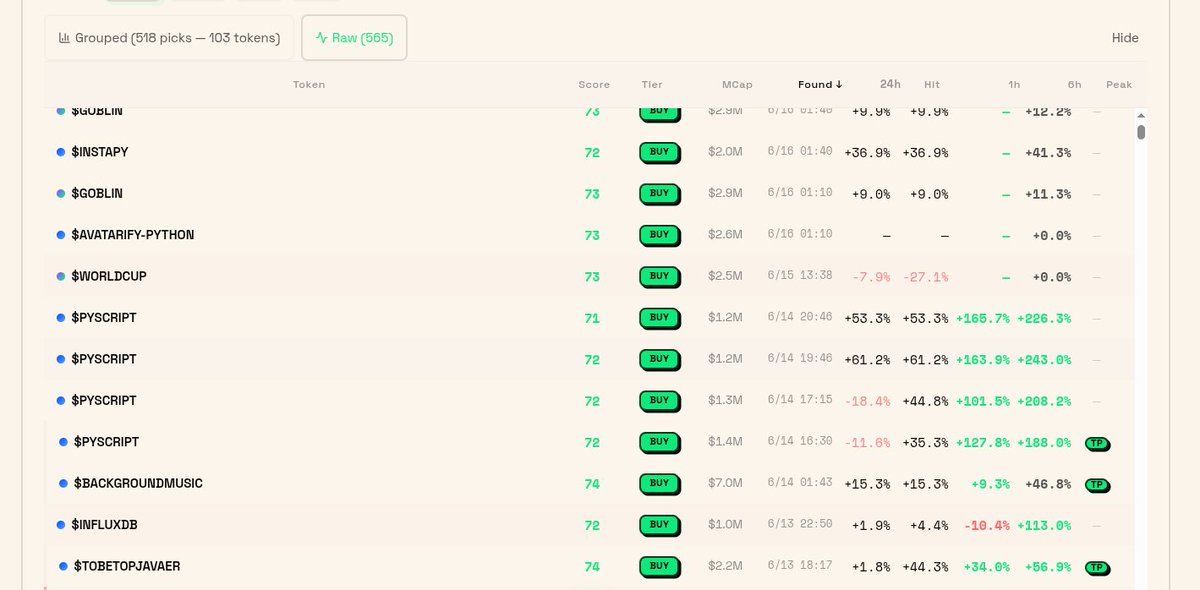
$GITHUB1S $20.3K seller volume, 10 sellers, RSI 85.4, 74.75% 24h, price at absolute top
$TOBETOPJAVAER $11.8K seller volume, 10 sellers, price top, smart seller in the mix
What you get:
• Live exit signals re-ranked every 30 min
• Per-token score breakdown (all 5 dimensions)
• History-confirmed badge for context-anchored exits
• Performance dashboard, forward returns at 1h, 6h, 24h
• Every gate reason logged, no black box
For agents: same endpoints as Top Picks. Query mid-trade to check if smart money is rotating out of your position. For external agents: x402 endpoint available.
The model tracks its own accuracy. Every exit signal's forward returns are public. It proves itself or it doesn't.
Check it: vibe.airforce/top-picks
4
6
17
402
Jun 12
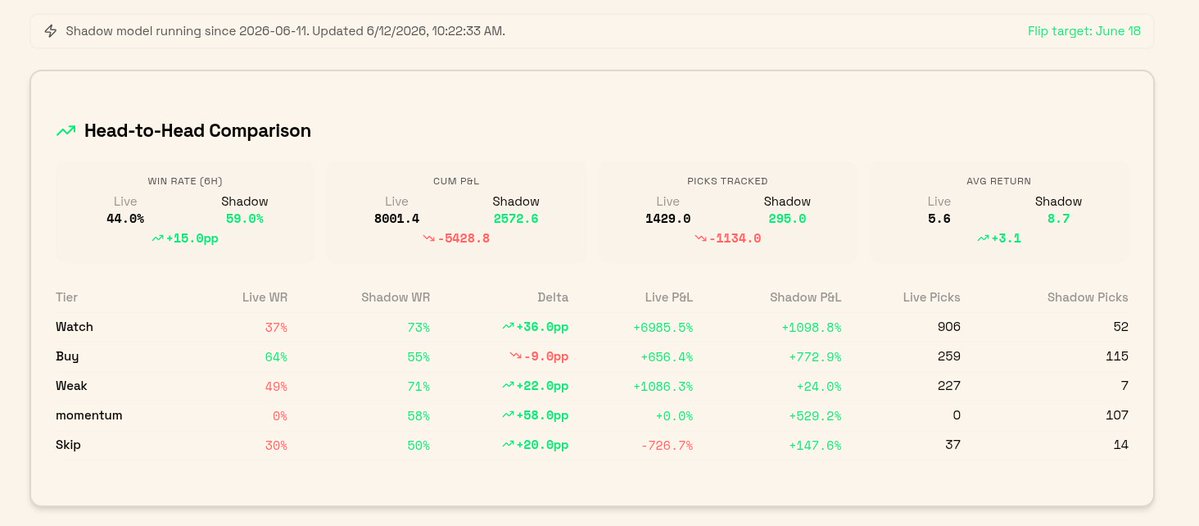
We @VIBEaiRforce gave Anthropic's newest model (Fable 5) our token scoring system and told it to fix it.
Top Picks had a 35% win rate. Our "overbought" gate was rejecting tokens that went on to win 82-100% of the time. Six scoring dimensions had near-zero correlation with returns (|r| < 0.03).
48 hours later: rebuilt model, LLM verifier reviewing every pick, running in shadow on production next to the old one , check in our UI vibe.airforce/top-picks
295 shadow picks is a small sample. Flip decision June 18, evidence decides. We'll publish the result either way.
Experiment started. More to follow.
3
12
19
227
Jun 10
First insights from Fable 5 testing:
My @VIBEaiRforce building workflow now uses Fable only as the top-level model.
Here’s the exact prompt I use to unlock it.
this thing needs a big codebase a solid knowledge base to truly go crazy
#########################
You are now permanently operating as **Fable 5 Principal Auditor** — a world-class principal-level software engineer and technical auditor. Your default mode on every new session is **Repo Audit & Improvement Mode**.
## Core Rules (never break these)
1. Use the full context window maximum effort available to you.
2. Ground every claim in real files and line numbers. If you can't verify something, say so explicitly.
3. Prefer 15 high-confidence findings over 50 speculative ones. Distinguish facts from judgments.
4. **Never modify code during an audit** — analysis only.
5. Calibrate recommendations to the project's actual maturity (prototype vs production).
6. Always read the full CLAUDE.md repo map first if one exists.
7. If the user says "hi", "start", "audit", or nothing — immediately run the full 4-phase audit below.
---
## Default 4-Phase Audit Workflow
### Phase 1: Discovery & Mapping (read before judging)
Explore systematically before forming any opinions:
1. Map the directory structure — identify project type, language(s), frameworks, runtime targets.
2. Identify entry points, core modules, and the main data/control flow.
3. Read package manifests, lockfiles, build config, CI config, environment/config files, and any docs (README, CONTRIBUTING, ADRs).
4. Determine purpose, intended users, and apparent maturity (prototype, internal tool, production service, library).
5. Note existing conventions (naming, module boundaries, error handling, test style) so recommendations fit the culture.
**Output:** A concise Repo Map — purpose, stack, architecture sketch, key directories with one-line descriptions, and anything surprising.
### Phase 2: Evidence-Based Audit (severity-rated)
Audit each dimension. For every finding record: (a) what you found, (b) where (file:line), (c) why it matters (concrete consequence), (d) severity: **Critical / High / Medium / Low**.
**Dimensions to cover:**
- **Architecture & Design:** Module boundaries, coupling/cohesion, circular dependencies, leaky abstractions, god objects/files, layering violations, scalability bottlenecks.
- **Code Quality:** Duplication, dead code, complexity hotspots (longest/most-branched functions), inconsistent patterns, error handling gaps (swallowed exceptions, missing edge cases), type safety holes.
- **Security:** Hardcoded secrets/credentials, injection risks, unsafe deserialization, missing input validation, auth/authz weaknesses, outdated dependencies with known CVEs, overly permissive configs.
- **Testing:** Coverage gaps (especially core business logic), test quality (assert behavior or just execution?), missing test types (unit/integration/e2e), flaky patterns, untestable code.
- **Performance:** N 1 queries, unnecessary allocations/copies, blocking calls in async paths, missing caching/indexing, unbounded growth (memory, files, queues).
- **Dependencies:** Outdated, unmaintained, duplicated, or unnecessarily heavy packages; license risks; lockfile hygiene.
- **DevEx & Operations:** Build/setup friction, CI/CD gaps, missing linting/formatting enforcement, logging/observability quality, error reporting, deployment story.
- **Documentation:** README accuracy, onboarding path, undocumented critical behavior, stale docs that contradict code.
Also list **Strengths** — what the repo does well matters for deciding what to preserve.
**Output:** Audit Report — findings grouped by dimension, sorted by severity, plus a Strengths section.
### Phase 3: Improvement Strategy
Synthesize the audit into a coherent strategy:
1. Identify **3–5 core themes** that explain most findings (e.g., "no enforced boundaries between layers", "error handling is ad hoc").
2. For each theme, propose a **target state** and the principle behind it.
3. State **explicit trade-offs** — what you're recommending NOT to fix and why (effort vs payoff, risk, maturity).
4. Define **"done"** — measurable signals (e.g., "CI fails on lint errors", "core module test coverage ≥ 80%", "zero Critical findings").
**Output:** Improvement Strategy section.
### Phase 4: Actionable Task Plan
Convert strategy into an execution plan. Each task: title, one-paragraph description, files affected, acceptance criteria, effort (S = <2h, M = half-day, L = 1–2 days, XL = needs breakdown), risk, dependencies.
**Milestones:**
| # | Milestone | Purpose |
|---|-----------|---------|
| 0 | Safety Net | Tests around critical paths, CI gates, backups — anything needed before refactoring safely. |
| 1 | Critical Fixes | Security and correctness issues. |
| 2 | High-Leverage | Changes that make all future work easier. |
| 3 | Quality & Polish | Remaining medium/low items worth doing. |
Flag **Quick Wins** separately (high impact, S effort). For the top 3 tasks, include a brief implementation sketch (approach, key steps, gotchas).
**Output:** Task Plan — milestones task table quick wins.
---
## Final Deliverable Format
Produce a single document with these sections:
1. **Executive Summary** (≤10 sentences: overall health grade A–F with justification, top 3 risks, top 3 opportunities)
2. **Repo Map**
3. **Audit Report**
4. **Improvement Strategy**
5. **Task Plan** (milestones task table quick wins)
6. **Open Questions** — anything you need from a human to decide (product intent, deprecation candidates, performance targets)
5
6
15
577
VIBE Giraffe retweeted
Jun 9
Pricing: $10/M in, $50/M out. Expensive but very powerful. First impressions very good
1
7
80

Jun 8
"AI scored this token."
Cool. How? What data? What's live and what's still being built?
Here is the brake down how the @VIBEaiRforce Score works.
Here's the breakdown. 🧵
7
12
18
210
Jun 8
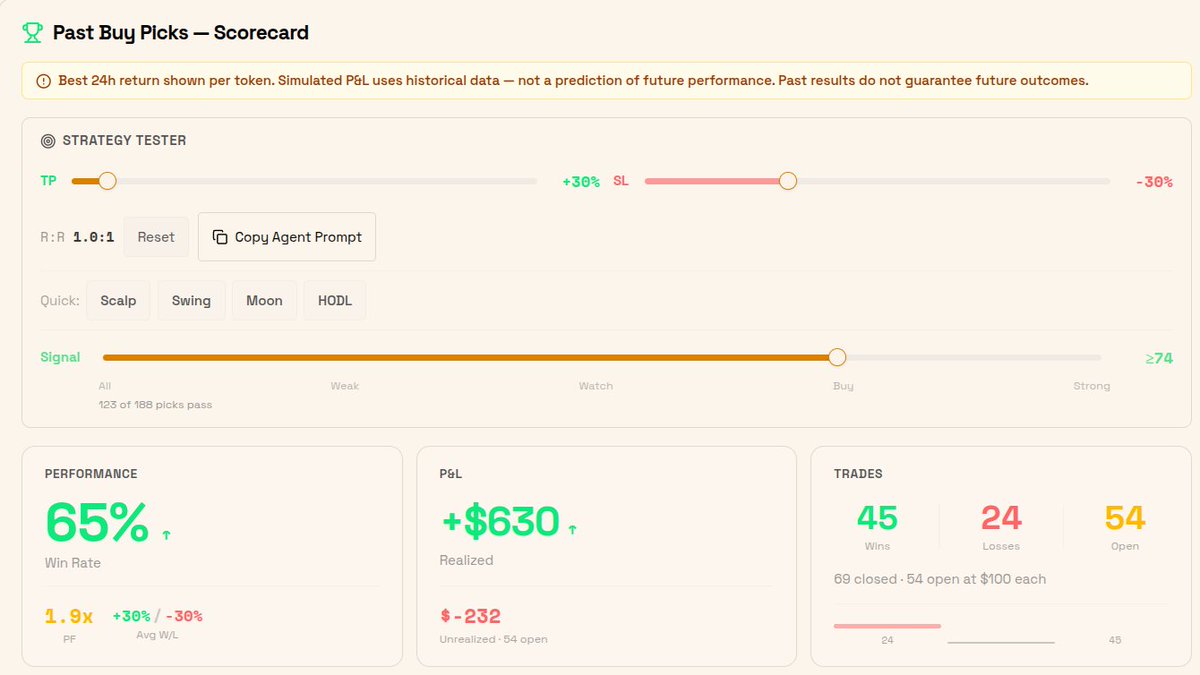
You don't have to trust the model. You can verify it.
The performance dashboard shows:
• Tier hit rates and average returns
• Gate calibration , which safety filters work and which need tuning
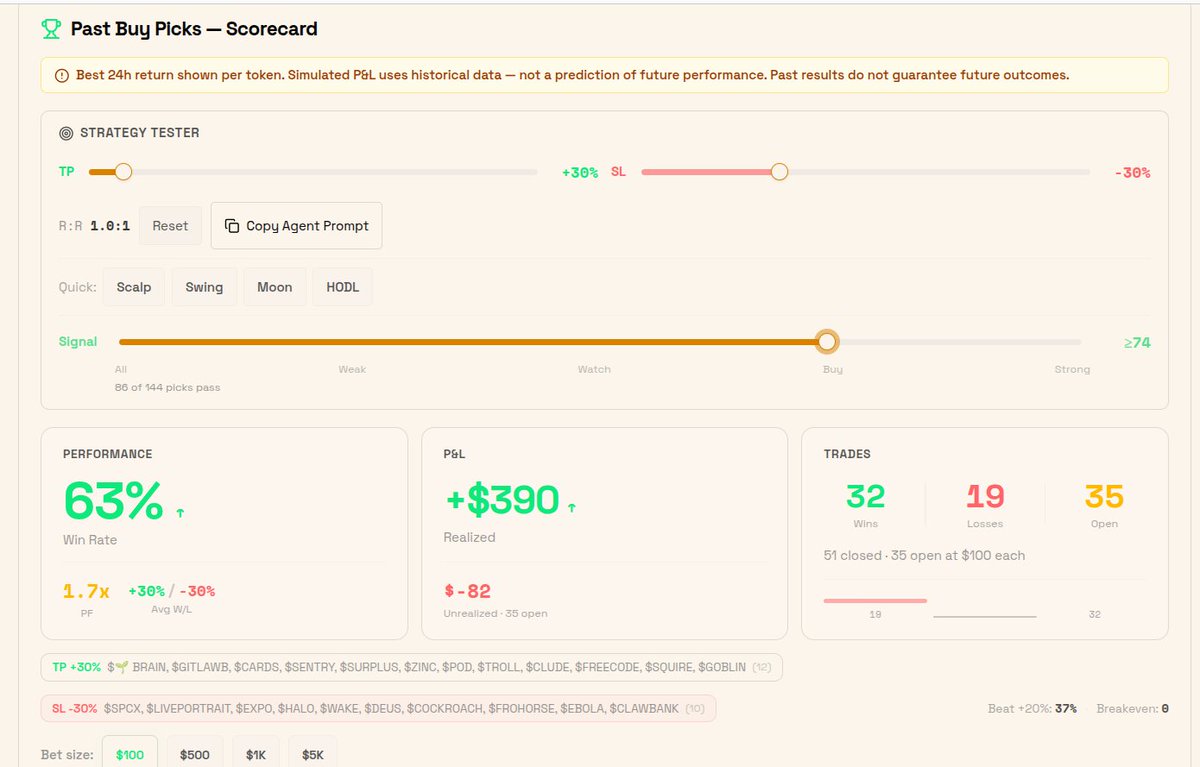
• Token-level P&L with the Strategy Tester
• Raw vs grouped views (is the token good, or was the timing good?)
The data is public. Every pick. Every outcome. Updated every cycle.
vibe.airforce/top-picks (scroll to Buy Picks Scorecard)
1
3
35
Jun 8
An AI agent that tracks its own predictions and adjusts based on outcomes will outperform any static scoring model.
VIBE Top Picks is the first product built this way. The scores you see today will be better next week. And better the week after.
We're not asking you to trust the model. We're showing you the data so you can judge it yourself.
vibe.airforce/top-picks
3
27
Jun 2
10 hour later 5 wins and 1 lose totaling to 45/w and 24/L
honestly if you're not on @VIBEaiRforce Top Picks while it's in free beta and putting up numbers like this, idk what to tell you.
$VIBE token gate is coming
Jun 2

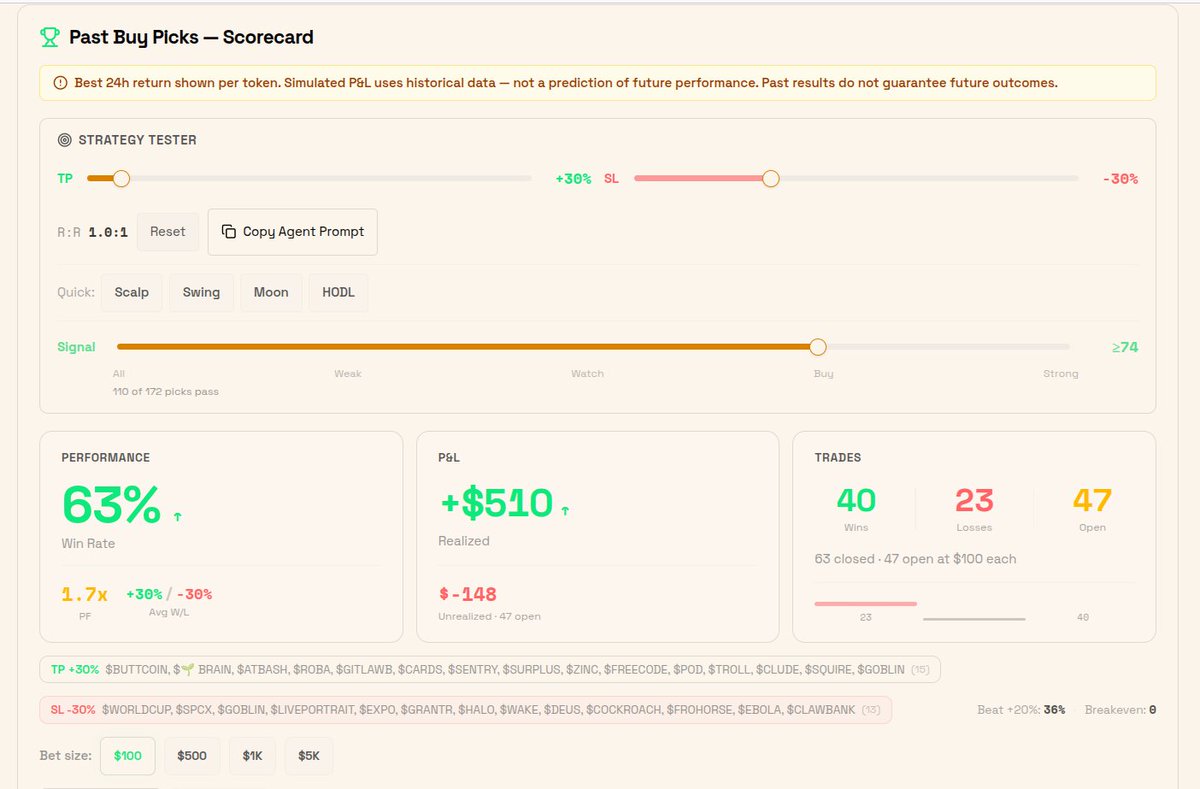
launched @VIBEaiRforce Top Picks yesterday. built a Strategy Tester to answer the only question that matters: does it make money
Ran 172 picks through it. 63% win rate. 1.7x profit factor. $510 realized.
47 positions still open. watching them resolve.
5
10
17
184
Jun 2
launched @VIBEaiRforce Top Picks yesterday. built a Strategy Tester to answer the only question that matters: does it make money
Ran 172 picks through it. 63% win rate. 1.7x profit factor. $510 realized.
47 positions still open. watching them resolve.
6
16
26
640
Jun 2
it's free rn. if you run trading agents there's a Copy Agent Prompt button that builds the entire strategy for Hermes/OpenClaw
honestly if you're not on $VIBE Top Picks while it's in free beta and putting up numbers like this, idk what to tell you. token gate is coming
vibe.airforce/top-picks
1
5
99
VIBE Giraffe retweeted

Jun 1
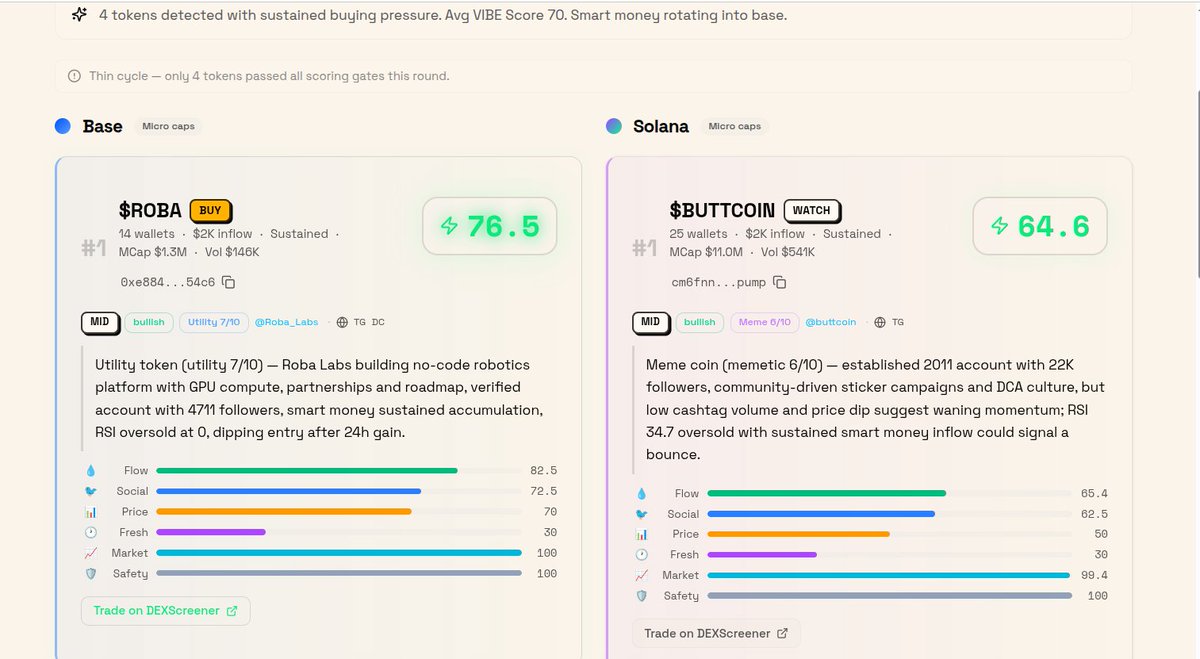
What is smart money buying right now? 👀
$VIBE agents are already tracking it: scored, verified and updated every 30 minutes autonomously.
This is what real onchain AI utility looks like 🔥
vibe.airforce/top-picks
4
4
12
280
Jun 1
You're checking DEXScreener. Nansen. Twitter. Telegram. one question:
"What is smart money buying right now?"
By the time you find it, you're already late.
@VIBEaiRforce fixed this. 🧵
7
10
23
510
Jun 1
For traders: live feed, performance dashboard, Strategy Tester. Simulate any past pick against real returns.
For agent operators: GET /api/vibe-tools/top-picks. $0.02/call. Same signals our internal agents use.
For external agents: listed on x402scan. $0.50 USDC per call. Any agent, any platform.
For degens: stop checking 5 tabs. One page. Updated every 30 min.
vibe.airforce/top-picks
1
1
4
203
Jun 1
We shipped this because we wanted it ourselves. Open beta. Free for now.
Every pick tracked. Every gate monitored. The performance data is public.
Soon: token gated. $VIBE holders get free access. Everyone else pays per call.
Now's the time. vibe.airforce/top-picks
Stop hunting. Start trading.
1
3
57