
Joined December 2010
- Tweets 1,447
- Following 1,053
- Followers 4,155
- Likes 10,132
59 Photos and videos






Pinned Tweet

May 11
✨We are showing some experiments with interaction models @ThinkyMachines: models that could see and hear continuously while processing tasks in the background and generating responses in real-time.
Interaction models offer a glimpse into a future where people collaborate with AI the same way we do with other people. Read our announcement post to explore the capabilities this model unlocks.
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
1
4
40
9,902

🤔Can LLMs reason by sampling continuous thoughts — not just tokens?
Introducing NF-CoT: Latent Reasoning with Normalizing Flows. It samples continuous chain-of-thoughts directly in the stream of LLM with exact likelihood -- powered by STARFlow.
🌐Page: nf-cot.vercel.app
8
32
129
46,786
Victoria X Lin retweeted

An insanely technically challenging project has come to a glorious end! I can't emphasize the amount of hard work behind this effort which I hope will influence the trajectory of 3D perception
Jun 5

Big congrats to our SAM 3D team for receiving a Best Paper Honorable Mention at #CVPR26! This prestigious recognition underscores their incredible work pushing the boundaries of computer vision.
Read the paper here: arxiv.org/abs/2511.16624
1
15
159
15,493
Jun 3
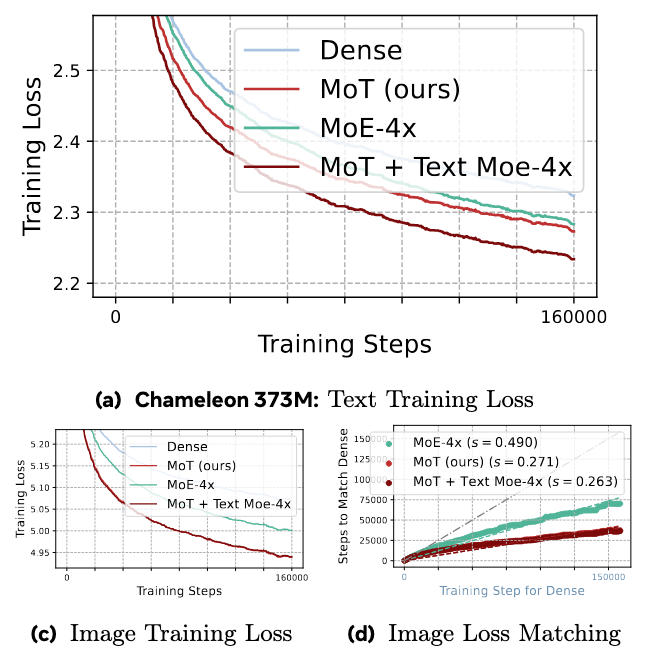
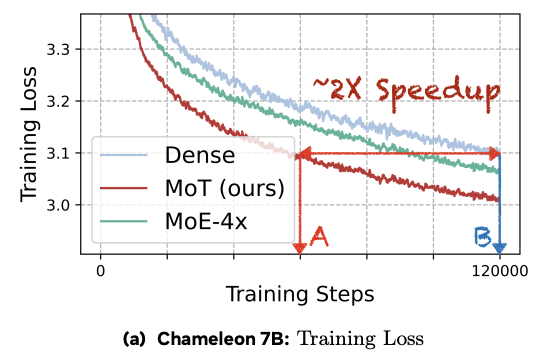
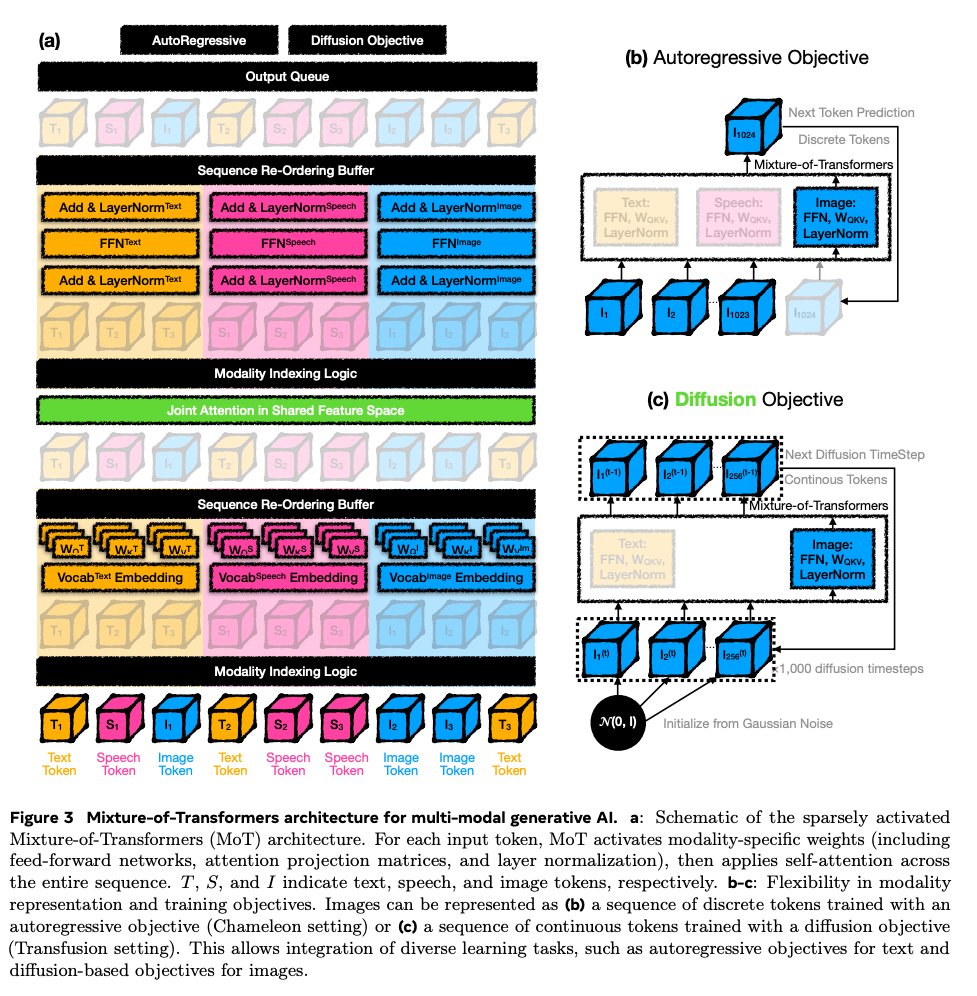
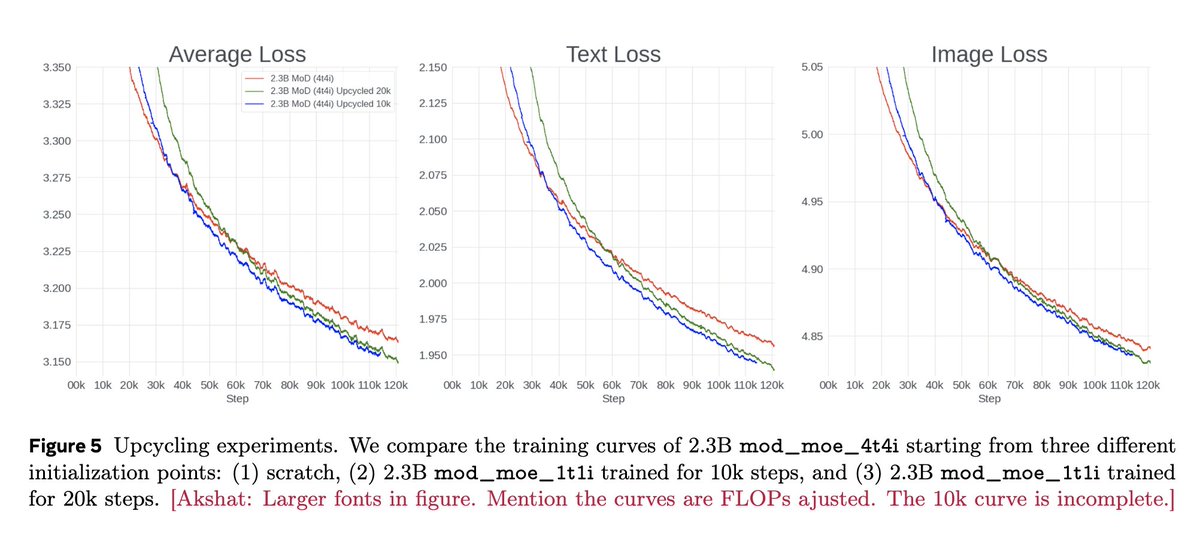
Excited to see 🌟 Mixture-of-Transformers (MoT) ideas continue to scale in native multimodal systems. nvidia.com/en-gb/glossary/mi…
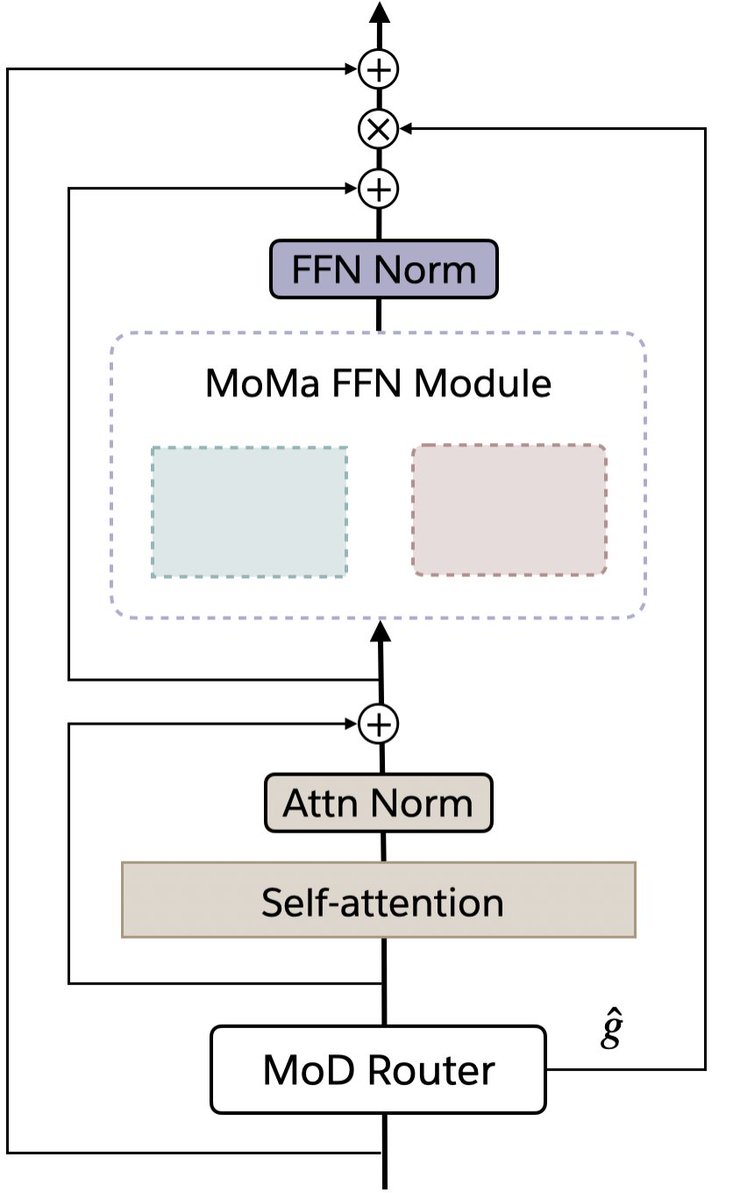
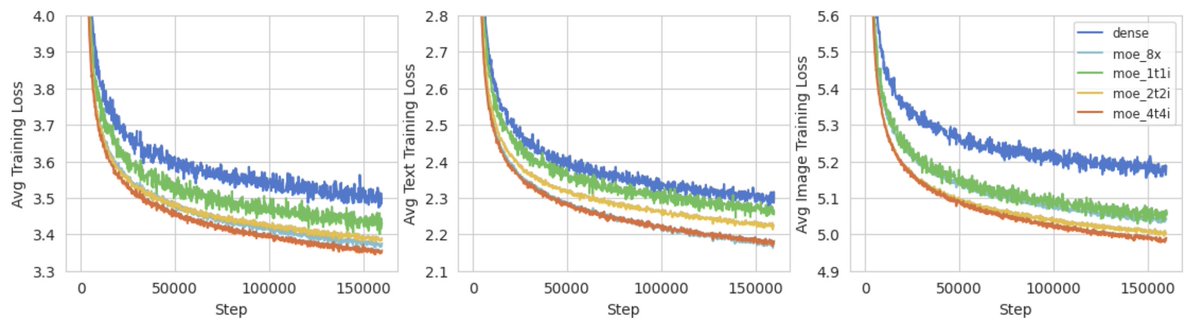
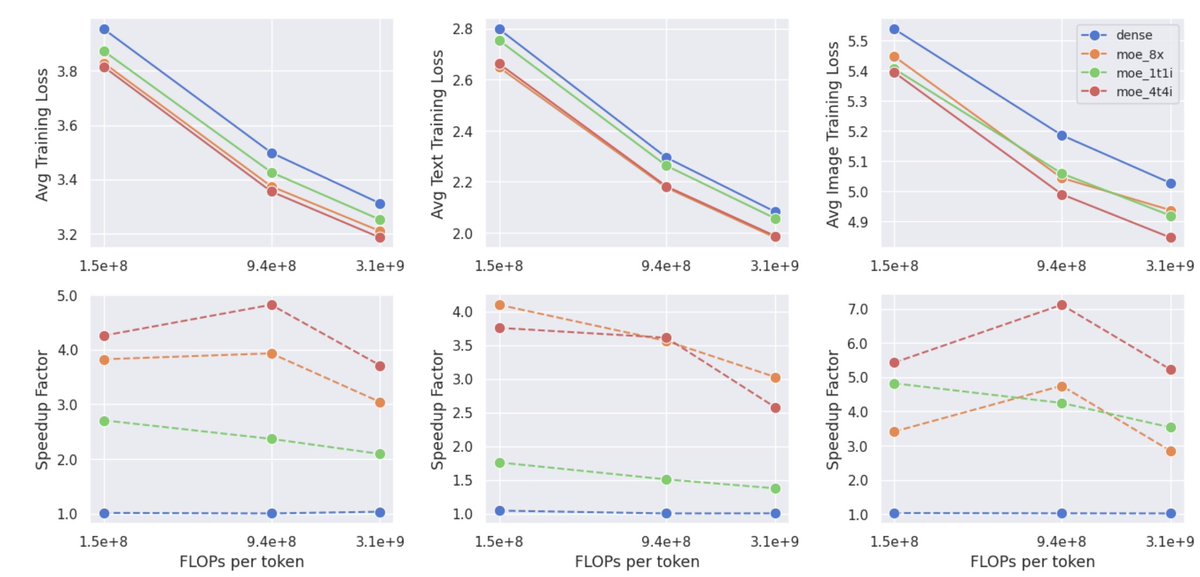
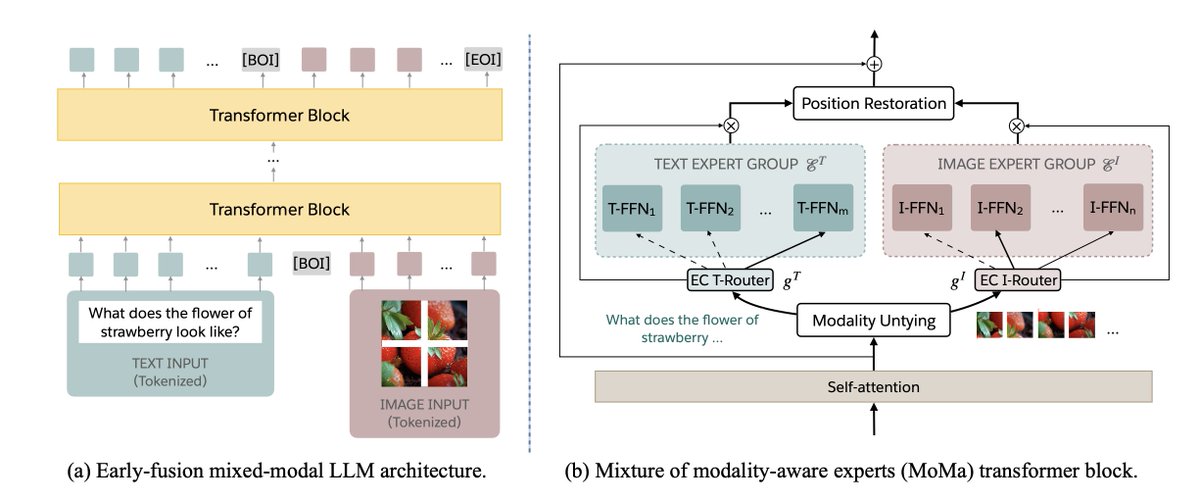
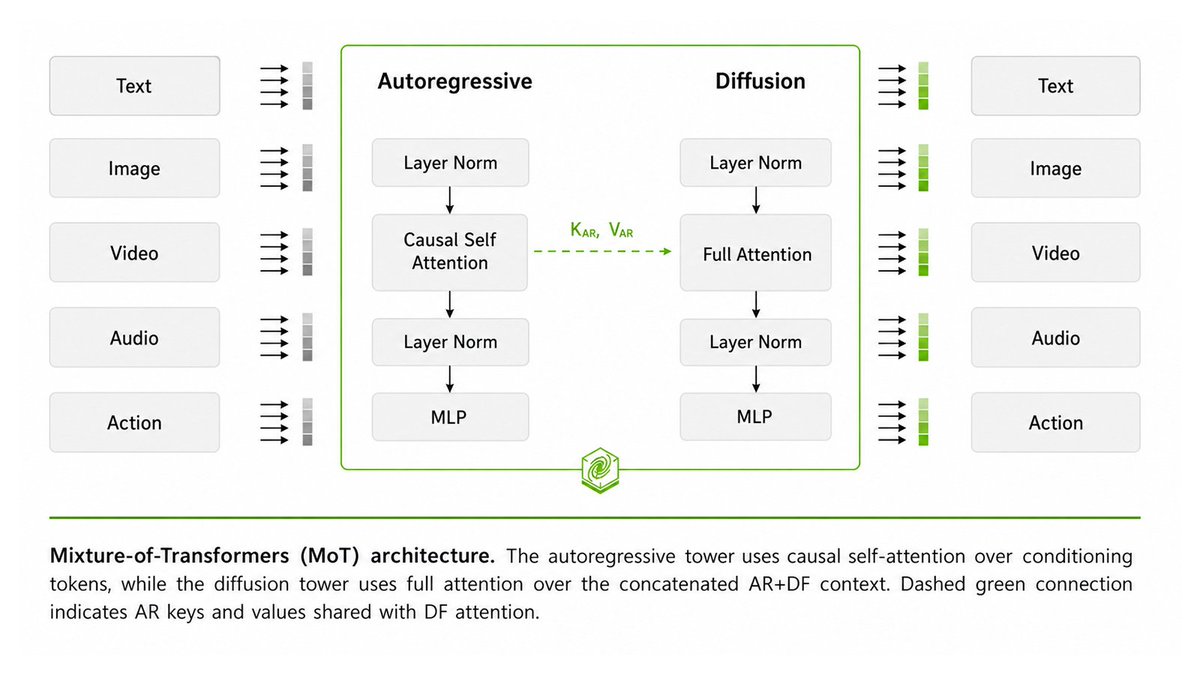
In our MoT work, we explored modality-specialized transformer parameters as a path toward building more efficient multimodal foundation models with stronger scaling properties. Cosmos 3 is an impressive instantiation of this design space in physical AI — combining reasoning, world generation, and action within a unified architecture.
Congrats to @NVIDIAAI and the broader team on this exciting open-source release!
w/ @liang_weixin @liliyu_lili Liang Luo and the team

Cosmos 3 ties everything together.
Previous releases separated world generation, physical understanding, and controlled scene generation. Cosmos 3’s MoT architecture unifies these capabilities by pairing an autoregressive reasoner tower with a diffusion-based generator tower.
3
2
33
4,255
Victoria X Lin retweeted

May 25
Why did Erdos have so many problems?
134
183
2,768
263,064
Victoria X Lin retweeted

Apr 1
We’re bringing back Stanford’s CS25 Transformers course tomorrow! 🤖
It’s open to everyone (in-person online). Weekly talks (every Thursday) from top AI researchers.
One of Stanford’s most popular AI seminar courses. Don’t miss out!
More info below 👇 (1/7)

10
93
642
59,323
Victoria X Lin retweeted

May 19
We are offering grants of $100,000 Tinker credits to researchers advancing the field of human-AI interactivity. Submit your proposals by June 19th!
thinkingmachines.ai/news/int…
52
199
1,626
618,103
Victoria X Lin retweeted
May 11
People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
464
1,958
15,784
7,748,087
Victoria X Lin retweeted

Working on the interaction models is a lot of fun at TML! I can't imagine doing that in a turn-based world. Building it from scratch makes a lot of things so much easier. I am very excited about the future of natively multi-modal, multi-stream, multi-task models.
4
7
181
23,615
Apr 30
Could @Waymo roll out a “working pod” series where you can comfortably set up your laptop and get work done during the ride?
1
2
1,717
Victoria X Lin retweeted

Apr 24
My solo paper is accepted in ICLR'26 in Brazil. It discovers the training dynamics of grokking behaviors (phase transition memorization -> generalization) in basic settings, and derives provable scaling laws that enables such dynamics to happen.
Unfortunately I won't be able to come to Brazil and present. Here is the poster I made, if people are interested to check: yuandong-tian.com/posters/po…
Will mention that paper in the upcoming invited workshop talks as well. Enjoy~
1 Oct 2025

🚨New work: Provable Scaling Laws of Feature Emergence from Learning Dynamics of Grokking (arxiv.org/abs/2509.21519)
In this work we propose a mathematical framework, named Li2, that explains the dynamics of grokking (i.e., delayed generalization) in 2-layer nonlinear networks. Specifically, it
1️⃣ Tells exactly what features will emerge during training.
2️⃣ Gives provable scaling laws of generalization/memorization, i.e. O(M log M) data samples suffice for generalization behavior of group arithmetic task of order M group.
3️⃣ Provides a more fundamental explanation for the popular empirical hypothesis that "generalization circuits learn slower but is more efficient than memorization circuits".
So how?
6
23
417
65,614

Victoria X Lin retweeted

Apr 17
Not many PhD students know about compute grants, but they can make a huge difference. During my PhD, I got access to Stability AI's HPC cluster through a small proposal and used it for Self-RAG training.
Great practical post by @_emliu!

wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k gpu hrs for roughly 2 weeks of work writing).
nightingal3.github.io/blog/2…
5
32
438
82,800
Victoria X Lin retweeted

Apr 14
Stunning crescent moon rising above Stonehenge this morning 🤩😍🌙 Photo credit Nick Bull 🙏
#moon #crescentmoon #sunrise #april #spring

11
371
2,041
22,987
Victoria X Lin retweeted

Apr 8
Our parallel reasoning project ThreadWeaver is now open-sourced 🎉!
Check out our Data Gen/SFT/RL recipe at github.com/facebookresearch/…
In case you don't know, ThreadWeaver 🧵⚡️ is the first parallel reasoning method to achieve comparable reasoning performance to widely-used sequential long-CoT LLMs, with up to 3x speedup across 6 challenging tasks.

ThreadWeaver
Adaptive Threading for Efficient Parallel Reasoning in Language Models

23
128
56,115
Victoria X Lin retweeted

Mar 10
Grateful to Jensen and @nvidia team for their support. Together, we’re working to deploy at least 1GW of Vera Rubin systems, bringing adaptable collaborative AI to everyone.
thinkingmachines.ai/nvidia-p…

167
279
3,868
560,961
Victoria X Lin retweeted
Mar 10
We are partnering with @nvidia to power our frontier model training and platforms delivering customizable AI.
thinkingmachines.ai/news/nvi…

101
163
2,408
669,206
Mar 8
☕ Society will reward tremendously those who can effortlessly spot mistakes made by autonomous agents.
1
4
28
3,754

This was a wild bug hunt, weeks of effort from @MayankMish98 to track down. The wrong init of Mamba2 in many reimplementations causes the layer to decay its states too quickly, focusing in short context instead. Pretraining is mostly about getting these little things right
Feb 25

We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized).
This bug is related to 2 main issues:
1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-lin…).
2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-lin… will fix this issue upon merging).
The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization.
Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/mamba-t…
Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏
Also thanks to @SonglinYang4 for quickly helping in merging the PR.
2
20
370
32,454
Victoria X Lin retweeted

Jan 31
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
924
5,835
50,786
9,186,532