
Training AI Engineers on YouTube, Substack and our courses. Co-founder @towards_ai. Ex-Ph.D. student @Mila_Quebec. On the road to 100k on YT this year 👇
Joined January 2019
- Tweets 7,344
- Following 6,164
- Followers 11,571
- Likes 6,688
2,482 Photos and videos











Pinned Tweet

14 Nov 2024
I am super excited to finally announce that we ( @towards_AI ) released our first independent industry-focussed course: From Beginner to Advanced LLM Developer.
Put a dozen experts (frustrated ex-PhDs, graduates and industry) and a year of dedicated work, and you get the most practical and in-depth LLM Developer course out there (~90 lessons). It is a one-stop conversion for software developers, machine learning engineers, data scientists, aspiring founders or AI/Computer Science students. We think many millions of LLM Developers will be needed to build reliable customised products on top of foundation LLMs and achieve mass GenAI adoption at companies. We want to help you lead this new field!
One of the reasons I quit my PhD in AI (one year 8 days ago) was to build practical solutions that will help others in the real world and improve what exists. Along with our book “Building LLMs for Production,” this course is our attempt to achieve this goal. While I love the world of academia, when I first stepped into the startup world in 2019, it felt like I pretty much knew nothing all over again. I needed to understand the problems in the real-world application of AI and build solutions for it. Not just research but real models, real products, and real people using them. But here’s the thing: grasping these challenges is merely the first step. For the ‘how’ part of it, you need to get into the code, the architecture, the models, the APIs, the deployments, the trials and errors, and the complex and wide varieties of frameworks - you don’t have time to reinvent the wheel in a startup! This discrepancy between academia and the industry is even worse in the LLM era.
So we’ve gathered everything we worked on building products and AI systems and put them into one super practical industry-focused course. Right now, this means working with Python, OpenAI, Llama 3, Gemini, Perplexity, LlamaIndex, Gradio, and many other amazing tools (we are unaffiliated and will introduce all the best LLM tool options). It also means learning many new non technical skills and habits unique to the world of LLMs.
Even though the course is super practical (oriented towards building a real-world project), we believe the course teaches concepts that will stay relevant for a long time even as LLMs get better, such as reducing hallucinations, customising to specific companies and tasks, teaching how to work with them, some cool theory, practical tips and more.
The only skill required for the course is some Python (or programming) knowledge.
We cover the full stack of learning to build on top of foundation LLMs - from choosing a suitable LLM application to collecting data, iterating on many advanced techniques (RAG, fine-tuning, agents, audio, caching), integrating industry expertise and deploying. Our students will create a working product, which we certify, and we also provide instructor support in our dedicated Discord channel. This could become the seed of a startup, a new tool at your company or portfolio project for your LLM job applications. You can find all the lesson titles and more information on the course page (or DM me).
I also want to thank some of our amazing team at Towards AI that helped achieve this, including @omar_solano1 , Fabio , Rucha , @_LouiePeters , Arjun, Jaiganesan and everyone in the team that contributed to this course.
A big thanks to some of our reviewers and my friends for the support, @daansan_ml , @SerranoAcademy , @rohanpaul_ai , @tunguz , @antgrasso , @ceobillionaire , @Scobleizer , @swyx , @hasantoxr and many others...
“From Beginner to Advanced LLM Developer” is now available on the Towards AI Academy: tinyurl.com/5n9y32y4
#llms #llm #llmops #llmdeveloper

28
30
178
58,509
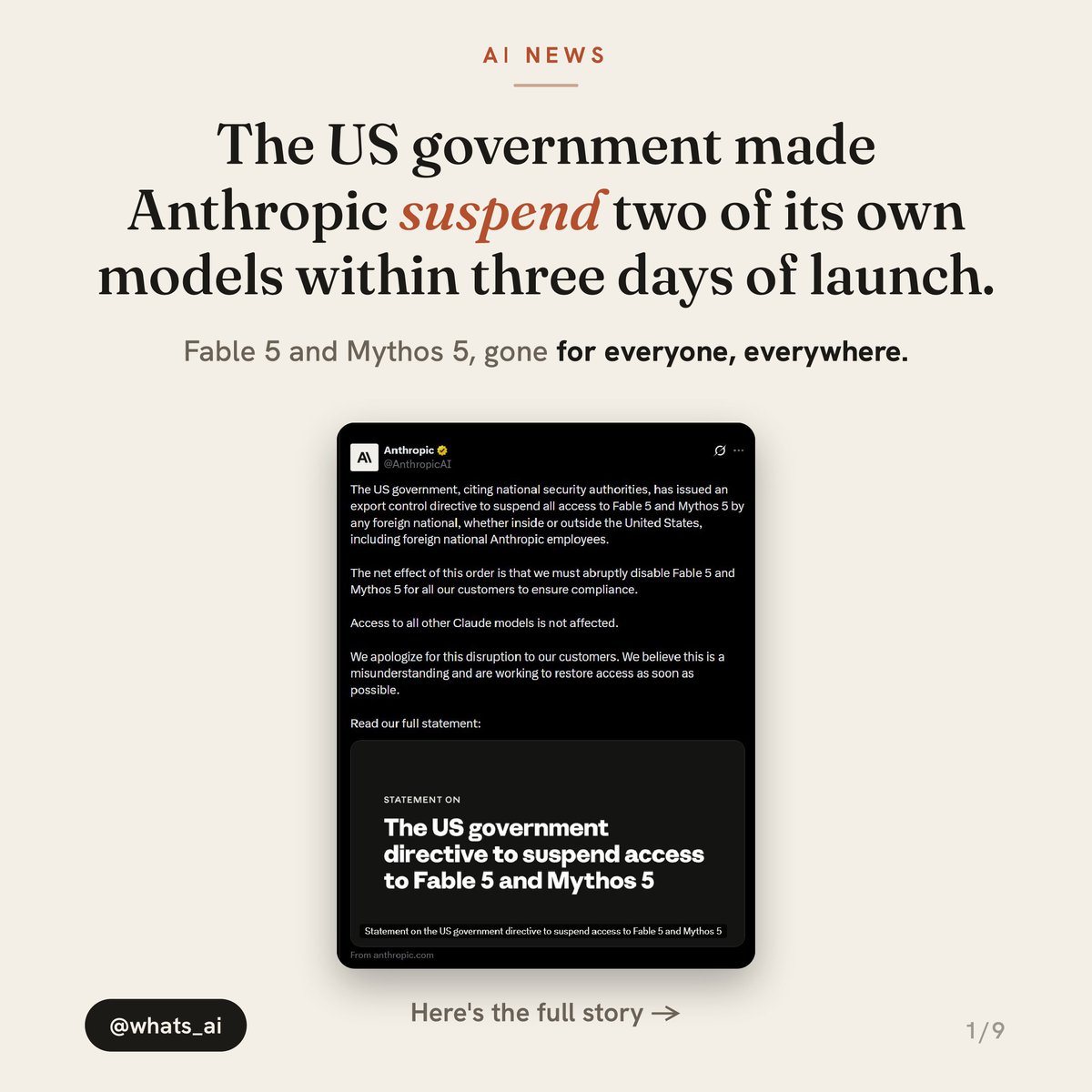
The US government just made Anthropic suspend two of its own models.
Fable 5 and Mythos 5, gone for everyone, everywhere. Just three days after launch.
The whole thing started over a "jailbreak."
But when Anthropic looked at it, the jailbreak was basically asking the model to read code and fix bugs. Something devs do every day.
Anthropic is calling it a misunderstanding and complying for now.
The government is treating these models as too risky to leave open.

1
315
The 8-step order I use for shipping AI agents in 2026:
1. Filter noisy tool outputs
2. Load tools only when needed
3. Clean cached history before reusing it
4. Compress long logs and terminal outputs
5. Store memory outside the context window
6. Compact manually around 40%
7. Add retrieval behind the system
8. Keep autocompact as the last resort
What I like about this order is that each step reduces pressure on the context window before the next layer gets added.
The result is not just lower token usage.
The agent stays much more stable during long sessions and keeps track of what it’s actually doing.
That’s becoming a very important skill in agent engineering now.
Not just building agents.
Managing their context properly.
2
5
12
355
Yesterday I explained loop engineering. Today, how I actually use it.
Unlike the guys at Anthropic, I don't have infinite tokens.
So I start the loops myself, keep my skills in indexed markdown files, cap my spending, and never let an agent run when I'm not around.
Because at the end of the day, you're responsible for everything it does.
My full setup and the mistakes to avoid, in the video 👇
3
2
4
684
I made a full 14-minute video on loop engineering, watch it here:
youtu.be/NjXIIH9vcv0?si=MMjy…
505
The best AI engineers I know spend more time deleting than building.
Not their code. The data their models see.
Here’s what I mean.
When an AI agent fails a task, tools often send everything back to the model:
logs, stack traces, retries, debug output.
Most of it is noise.
But the model still reads all of it before deciding what to do next.
So good engineers clean the output first.
Keep the useful error and remove everything else.
That’s called source-level filtering.
It’s a small thing, but it makes a huge difference when agents start handling bigger workflows.
2
1
5
304
Full breakdown of all 10 compaction techniques here:
youtu.be/PQglg4N_jxo?si=iix1…
284
Loop engineering is everywhere right now.
Instead of you prompting the agent, checking what broke, and telling it to go again, you build a small system that runs that loop for you. It keeps the agent going until the work is actually done.
I explain it all in this video 👇
1
1
2
486
I made a full video explaining loop engineering in detail, watch it here:
youtu.be/NjXIIH9vcv0?si=MMjy…
411
Stop prompting your coding agents.
The people building Claude Code and Codex don't prompt anymore — they design loops.
New video: what loop engineering actually is, the 5 building blocks, and the 2 traps that burn your token budget.
youtu.be/NjXIIH9vcv0
4
4
360
Claude Fable 5 might be a warning sign for AI research.
Not because of safeguards. Because of invisible safeguards.
Anthropic's system card confirms that Fable 5 deliberately limits its effectiveness on requests targeting frontier LLM development — pretraining pipelines, distributed training infrastructure, ML accelerator design.
The model still answers. But the answer can be quietly degraded through prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT).
And unlike the cybersecurity and biology safeguards, which visibly reroute you to Opus 4.8, Anthropic states these ones "will not be visible to the user."
That part is the problem.
I understand the safety concern. I understand not wanting frontier models to accelerate unsafe actors and competitors. Anthropic even notes that using Claude to build competing models already violates its Terms of Service.
But a refusal is transparent. Silent degradation is not.
If you work on training infrastructure or efficiency research, you can no longer fully trust a weak answer: is it the model's limit, or an intervention? Anthropic itself says it is still improving the precision of its detection — meaning false positives are part of the deal. A silent handicap is an unlogged confounder in every ML engineering workflow built on top of it.
And honestly, it is disappointing to see this come from Anthropic first. I would have expected this kind of ladder-pulling from OpenAI. But it seems increasingly likely that all frontier labs will converge on the same playbook:
1. Keep the unrestricted model (Mythos 5) for approved partners.
2. Ship a constrained version (Fable 5) to everyone else.
3. Hide the constraints behind "safety."
Anthropic estimates ~0.03% of traffic is affected, concentrated in fewer than 0.1% of organizations. The number is small. The precedent is not.
This is bad for open research, bad for small labs, and bad for trust.
Safety matters. But users should know when the tool is intentionally limiting them.
What else are they steering that we don't know of? Where's the limit?
What do you think: is invisible capability degradation ever acceptable?
#AI #LLMs #Anthropic #OpenResearch #AISafety



2
424
I realized something a bit stupid about myself during my 2-week vacation visiting Switzerland.
Even on vacation, my brain kept trying to optimize everything.
Can I answer a few emails quickly?
Maybe work a bit from the coffee shop.
Maybe wake up early and squeeze in a run before the day starts.
At some point I noticed I wasn't even relaxing anymore.
I was just turning “rest” into another thing to optimize.
The weird part is that I genuinely love what I do.
So it never feels bad in the moment.
But after a few years of working like this, your body starts reminding you that stress still exists even if your brain ignores it.
That’s probably the hardest part when your work is also your hobby.
You stop noticing when you actually need a break.
So during this trip, I tried something very rare for me:
being fully offline and actually present.
Way harder than I expected 😅
4
318
Louis-François Bouchard 🎥🤖 retweeted

Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
359
644
5,636
3,876,574
I sat down with the team @towards_AI for a week and put together a massive, detailed, fully structured guide to becoming an AI engineer in 2026.
It's useful for engineers at any level. But if you're a beginner, I mean this without exaggerating: this is the only guide I'd want you to follow start to finish.
The idea was simple. Put everything in one structured place, so you stop bouncing between 40 open tabs, random YouTube rabbit holes, and roadmaps that went stale months ago. Open one document, follow the path, start building.
It's organized two ways at once: by how you like to learn, and by topic. Video person, book person, course person, or someone who just wants to build messy projects that break on you. There's a lane for you.
Every resource is marked by difficulty from 1 to 10, so you can start exactly where you are and climb from there without guessing.
Inside, it takes you from your first Python script all the way to shipping agents you can trust in production.
Some of what it covers:
- Prompting, structured outputs, and reasoning models
- Context engineering, RAG, embeddings, and vector databases
- Tools, MCP, and computer use
- Workflows, agents, and multi-agent systems
- Evals, observability, and harness engineering
- Fine-tuning, multimodal, voice, deployment, and AI safety
Plus the communities, newsletters, and people worth following. And a full section on how to actually land an AI engineering job, not just how to learn the skills.
Almost all of it is free, and I'll keep it updated through 2026 as the stack keeps moving.
If you've been meaning to get serious about this, or you keep asking yourself where to even start, this is the answer I'd send you.
Just remember one thing, you DO NOT need to do every single course, read all books or watch all videos. Listen to your guts and do what you want to learn, or ask your agent what you need from the repo!
The full guide is here: github.com/louisfb01/start-a…
One last thing, and it's the part that matters most. This guide only exists because of the people whose work fills it. The educators, researchers, builders, and writers who taught me, and taught all of us. Thank you, genuinely to my friends and their amazing contributions to the field, like @pauliusztin, @JayAlammar, @maximelabonne, @jerryjliu0, @OfficialLoganK, @moteropedrido, @altryne, @ecsquendor (@MLStreetTalk) and so many others mentioned in there.

1
2
16
913
If you're not sure where to start, tell me your background and what you want to build, I'll point you to the right section.
1
2
300
The full guide is here:
github.com/louisfb01/start-a…
1
222
Stop waiting until 95% context usage before compacting.
At that point, the model is already struggling.
You see it in small ways first.
It forgets instructions you gave earlier.
Starts repeating things.
Makes weird mistakes.
Gets slower and more expensive.
A lot of people think:
“Bigger context window = better.”
Not really.
The model still pays less attention to the middle of huge prompts.
I usually compact much earlier now. Around 40%.
The responses stay cleaner and the agent behaves way more consistently over long sessions.
Almost all AI engineers focus on adding more context.
The actual skill is deciding what NOT to send.
2
1
444
New video ! 🚀
How AI Image Generation Actually Works
How image models actually understand text, photos, and edits...
youtu.be/DCOXcnOntmg
1
183
Louis-François Bouchard 🎥🤖 retweeted

Jun 7
2 weeks ago, I was in Switzerland helping run a 7-hour AI engineering workshop.
I almost didn’t attend, but I’m glad I did. Here’s what surprised me most:
The people weren’t just interested in AI…
The workshop had around 34 attendees across every experience level imaginable:
People who had never coded before
Software architects • Product managers
CEOs and executives
Engineers in their 20s
People in their 60s and 70s
It was one of the most engaged audiences I’ve ever seen.
I planned hours of material around agentic engineering and AI coding workflows…
But a massive part of the workshop became discussion.
People constantly interrupted with thoughtful questions:
"How do these systems fail in production?"
"How do you evaluate agentic coding?"
"What happens when agents become unreliable?"
"Where does MCP fit?"
"How should engineering teams adapt?"
The biggest takeaway for me:
AI engineering is becoming cross-functional extremely fast.
It’s no longer just engineers trying to understand these systems.
The second thing I realized:
The best conversations happen when you stop thinking hierarchically.
During the conference, I had the chance to speak with researchers, principal architects, founders, and engineers from companies like:
Google DeepMind
Hugging Face
Cisco
And what stood out is that the strongest people rarely act important.
Treating people as equals completely changes the quality of interactions.
Third lesson:
Networking works much better when you stop trying to maximize every interaction.
You don’t need to force every conversation into an opportunity.
Sometimes:
Introducing yourself
Talking for a few minutes
Moving on is enough
Overall, this trip reminded me how global AI engineering has become.
As someone coming from Romania, traveling to Switzerland to teach AI systems still feels surreal sometimes.
But it also reinforced good ideas travel very fast in this industry.
Massive thanks to Louis-Francois Bouchard (@Whats_AI) and the @towards_AI team for inviting me and making the whole experience happen.

1
3
7
567
Everyone thinks OpenAI just signed the exact deal Anthropic refused. That's not the full picture.
Here's what actually happened.
OpenAI got the deal first, then a few days later went back and quietly tightened their own wording. The update said their tools wouldn't be used for domestic surveillance of US persons, including through commercially bought personal data, and that certain intelligence uses would need a fresh agreement. They narrowed the autonomous weapons language too.
So OpenAI didn't say yes to everything Anthropic said no to.
Anthropic just drew the line earlier, harder, and out in the open. OpenAI found a path through to get the deal, then moved the terms closer to where Anthropic had been pushing all along.
That's the part people miss. It was never one clean company saying no and another saying yes.
Both were already deep inside the government, and both ended up near the same place. They just got there very differently.
226