
CTO @XRAIGlass. Ex-Principal ML engineer @Microsoft. Ph.D in machine learning. CEO @MLStreetTalk pod
Joined January 2014
- Tweets 1,700
- Following 1,173
- Followers 8,726
- Likes 2,974
140 Photos and videos









Pinned Tweet

4 Jun 2023
So this happened. I got to interview one of my intellectual heroes! 😀
4 Jun 2023

We spoke with Prof. @danieldennett about his Atlantic article "The problem with counterfeit people". Featuring @GaryMarcus ! Prof. Dennett argues that LLMs could cause epistemic erosion in our society. youtube.com/watch?v=axJtywd9…

5
2
53
16,445
Tim Scarfe retweeted

Jun 10
Michael Jordan brings a strong and thoughtful perspective on AI:
youtube.com/watch?v=AREWYbVt…
14
36
276
38,364
Tim Scarfe retweeted

The TLDR of this is that Rich is confusing (transformative) creativity with intelligence and agency in the partial knowledge regime.
As Kenneth Stanley expertly outlined in his book Why Greatness Cannot Be Planned: Greatness can (mostly) only be discovered when you are not looking for it.
The other key misunderstanding is that creativity is mostly about deeply respecting constraints, or, in simple terms, about deep understanding.
We explained all of this in detail in our recent article on creativity.
May 31

A new and possibly controversial perspective:
In this video, I explain the sense in which generative AI trained by supervised learning is incapable of making novel discoveries.
youtu.be/K5LAFEjTlBA
The text of the speech:
AI Creativity and Discovery
Good day ladies and gentlemen. I regret that I am unable to be with you all today to engage in a back-and-forth discussion, but I am nevertheless pleased to be able to share with you, via this recording, some high-level thoughts about the current and future state of artificial intelligence, and in particular about AI’s relationship to science and mathematics, which is, as I understand it, the central focus of this meeting and of the SAIR Foundation.
I would like to start with an old joke; I am sure you have heard it before. It is the one about the researcher whose work is being evaluated, and the review comes back, and says “This work is both novel and good. Unfortunately, the parts that are good are not novel, and the parts that are novel are not good.”
My first point about AI is that this assessment applies exactly to large parts of AI as we know it today. Not all of today’s AI, but a large part of it. Pretty much all of what we mean by “Generative AI”---which includes large language models, and the images and video models, and even the new methods for learning world models. All of these AIs take large numbers of examples and produce a “model” which behaves similar to the examples, that is, which generates text like people, or images like artists or nature, and videos like we find on the internet. Don’t get me wrong, Generative AI can be extremely useful. No doubt about that. But the assessment of the joke still applies. These systems can produce output that is both novel and good, but not at the same time.
In many ways this is just absolutely not a problem. When we ask an AI for an answer from the internet, or to summarize a document, we don’t want it to be novel. We are happy if the quality of the answer, the goodness, comes from the source material—from the people who wrote the document or the articles on the internet. If the AI’s answer is novel it means it is going beyond the source material, adding something beyond it. This is what we call “hallucinations”. In most cases, we don’t like it when the AI makes something up, when it adds something novel.
One exception, of course, is when we are looking not for facts or reality, but for fiction and entertainment. We might ask for a bedtime story for a child, or an image based on existing images on the internet but which is nevertheless different and distinct from them. In these cases, it is never easy for us to know how creative the AI is actually being, as we do not know how close the AI’s story, poem, or image is to the source material. In a real practical sense we can not know this because the internet is too big, the possible sources that the AI may draw upon are too numerous.
When we ask for a fiction or novelty, the AI can give it to us because its processing is in part stochastic. Every decision can go multiple ways and will go different ways and produce a different trajectory every time. The trajectory can be random—and thus novel—or it can be based on the training data—and thus “good” because the training data is good, sourced from people or reality. Thus, the trajectory is either novel or good—based on randomness or based on data—but never both at the same time.
Really, I think it is okay if the output of Generative AI is never good and novel at the same time. For the researcher in the joke this is a devastating criticism, but for most things it is not, and for Generative AI it is not. Generative AI is meant to be a mimic. This is what supervised learning is for. Generative AI can be extremely useful, even when it just mimics, if it is faster, or cheaper, or smaller, or more customizable, or more copy-able, than the thing being mimicked. It is okay if Generative AI cannot be both novel and good at the same time. It is still a transformative technology.
But it is a limitation. And remember we are here to use AI for science and mathematics, and for these areas the assessment of the reviewer in the joke is devastating. For these areas we need true creativity and discovery. Generative AI—or Mimicking AI—will never get where us there. For these we need something more, and indeed we have something more in other parts of AI. We have many AI systems which can give us more. We have AlphaGo with its world-changing move 37, or AlphaZero with its brilliant original chess-playing style. We have GT-Sophy that drives simulated racecars better than any human. We have AlphaFold and AlphaProof and Claude-Code, which have brought true advances in science, mathematics, and programming. We have RL-Lyft which optimizes the assignment of cars to passengers in the ride-hailing business. All these systems have found things that are both novel and good. And, truth be told, some language models have been augmented in ways that make them more than Generative AI based on supervised learning.
All these systems have some additional features that make them capable of true creativity and true discovery. It is important for us to recognize what this is—and that it is not present in ordinary, garden-variety Generative AI. It is something that can not come from just supervised learning, from learning from examples. What is it? Well, it is a simple thing, a commonsense thing. It is not new. We have many names for it, but unfortunately none of them are very good names. I will call it Discovery. Basically, Discovery is just the idea of trying many things and seeing which of them work, then keeping those that worked the best. Evolution by natural selection works this way. The scientific method works this way. And just ordinary life and learning works this way. We try things and remember what works. What could be more obvious? In this behavioral case, psychology has two names for it— “instrumental learning” and “operant conditioning”—and in machine learning it is what we mean by “reinforcement learning”. We also see the idea of Discovery in planning and combinatorial search—anything that involves the idea of “generate and test”.
The essence of Discovery is to combine three steps:
1. Variation,
2. Evaluation, and
3. Selective retention.
Of course, I am not the first to say this. I am not the first to point out that this combination of steps is key to science, to evolution by natural selection, and to animal behavior. I think particularly of papers by Donald Campbell, by Daniel Dennett, and by Gary Cziko. What is new in my remarks is to directly relate the idea of Discovery to modern AI to help us see that it is not present in supervised learning or Generative AI—in particular, that Discovery is not present in backpropagation or gradient descent.
Let me say explicitly what is missing from Generative AI. As we have remarked, these systems do have a stochastic aspect, so they do generate a variety of trajectories and behavior. What is missing is the Evaluation step. The generator was pre-trained by supervised learning, leaving no way at runtime to Evaluate what it generates. And of course without Evaluation there can be no Selective retention, and thus no Discovery. The variation can bring novelty, but without evaluation there is no Discovery, and arguably, no creativity. That is, I would say that creativity requires that the new things generated be Evaluated. Without evaluation, and retention of the best, there is nothing created. The novelty flickers into existence but, if its value is unrecognized, it flickers away and is lost.
In many cases, Evaluation is done by people to make a discovery. As when we have Generative AI make many pictures for us, and then we pick the one that we like the best. The human AI system completes the discovery.
In many other cases, the Evaluation comes from a clear objective. Some moves lead to checkmate, some steps lead to a proof, some actions result in high reward, some genotypes make more copies, some theories explain the data better.
Some prefer the Variation step to be called Blind variation, where “blind” here means that it is uninformed, a shot in the dark. It does not need to be completely uninformed; a good scientist does not select theories to test at random. But neither can it be completely informed and determined. There must be some uncertainty about where the answer lies in order for there to be a discovery. In practice, the variation is partly informed and partly blind, but it is the blind part that corresponds to the discovery.
Now let us briefly go all the way to modern deep learning, to the backpropagation algorithm. At first it might seem that backpropagation is incapable of discovery because it is deterministic and thus incapable of variation. But this is not correct. The weight updates of backprop are deterministic, but the weights are initialized to small random values. The random initialization is often downplayed, but in fact it is a necessary form of variation; it must be done properly to get good performance. In backprop this Variation is done once, at network initialization, so its effect is temporary, and later the network may lose its ability to learn. This is the weakness of deep learning that is alleviated with a new algorithm that my group presented in Nature a couple of years ago. Our “continual backpropagation” made one small change: every so often a less-used neuron would be re-initialized to small random weights. This allows the variation to continue and plasticity to be retained.
Although there is much more to be said about Creativity and Discovery, this is the key point: they are more than supervised learning, more than pattern recognition, more than prediction, and more than world modeling. Those things are important, but they alone will not bring us to discovery. Discovery requires Evaluation from a person or from an explicit goal, and only in the latter case will we attain full autonomy.
So that is my call to arms. If we want the full power of AI scientists, then we should share the goals with them so they can create, evaluate, discover, and in these ways fully participate in achieving the goals. Let’s be bold! Let’s fully automate Creativity and Discovery!
6
7
70
10,112

Today’s free newsletter is about how LLMs are the perfect grift to exploit an economy dominated by do-nothing managers and executives disconnected from any real work, and how the facade is crumbling as companies pay the true cost of AI.
wheresyoured.at/the-revenge-…
33
425
2,163
411,201
Tim Scarfe retweeted

May 21
New inflection point in the accelerating growth of open-source models usage is coming
May 21

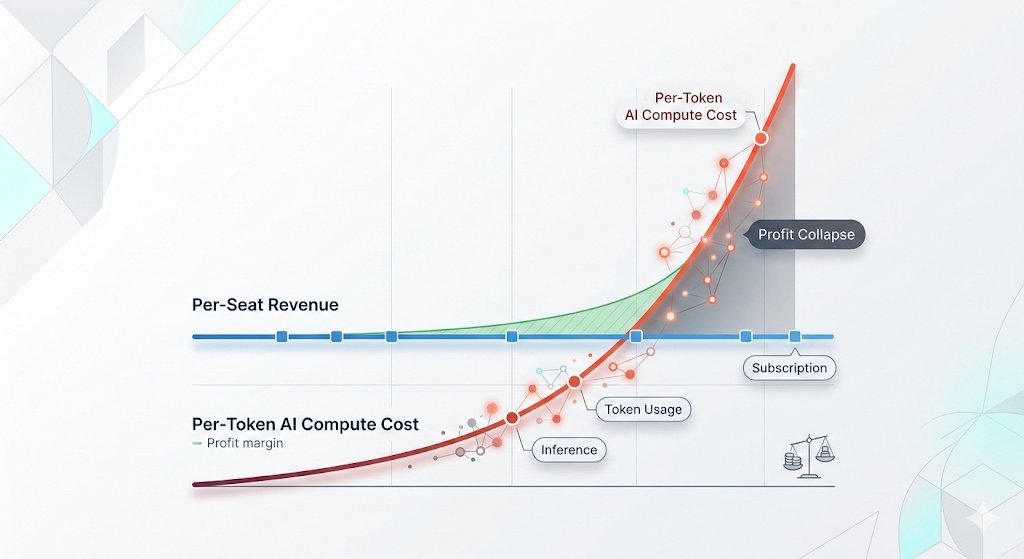
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
33
27
234
78,235
Tim Scarfe retweeted

May 14
This is your annual reminder that we don’t need to speculate about whether we will have a “theory of deep learning” and what form it might take, because we already have a basic understanding of generalization in deep learning: arxiv.org/abs/2503.02113
6
91
791
72,982
Tim Scarfe retweeted

May 14
This reminds me of computerization. The amount of "work" people could execute on computers increased by a huge factor, but their productivity did not. The amount of work "needed" to arrive at the same high-level outputs exploded.
27
36
593
56,223

Scaling massive monolithic LLMs continues to yield incredible results. But to truly unlock their ceiling, the next frontier is test-time compute and dynamic orchestration.
Nature solves complex problems through collaborative ecosystems. In our new #ICLR2026 paper, we evolved a small coordinator. Instead of competing with the monoliths, it orchestrates them. It learns to dynamically assign Thinker, Worker, and Verifier roles to a pool of frontier models—combining their strengths to hit SOTA on LiveCodeBench.
This research is part of the engine powering our new product: Sakana Fugu sakana.ai/fugu-beta/ 🐡
Apr 25

What if instead of building one giant AI, we evolved a coordinator to orchestrate a diverse team of specialized AIs? 🐟
Excited to share our new paper: “TRINITY: An Evolved LLM Coordinator”, published as a conference paper at #ICLR2026!
Paper: arxiv.org/abs/2512.04695
In nature, complex problems are rarely solved by a single monolithic entity, but rather by the coordinated efforts of specialized individuals working together. Yet, modern AI development is heavily focused on endlessly scaling up single, massive monolithic models, yielding diminishing returns. While model merging offers a way to combine different skills, it is often impractical due to mismatched neural architectures and the closed-source nature of top-performing models.
To address this, we took a macro-level approach: test-time model composition. We introduce TRINITY, a system that fuses the complementary strengths of diverse, state-of-the-art models without needing to modify their underlying weights.
TRINITY processes queries over multiple turns. At each step, a lightweight coordinator assigns one of three distinct roles to an LLM from its available pool:
1/ Thinker: Devises high-level strategies and analyzes the current state.
2/ Worker: Executes concrete problem-solving steps.
3/ Verifier: Evaluates if the current solution is complete and correct.
By dynamically assigning these roles, the coordinator effectively offloads complex reasoning and skill execution onto the external models.
What makes TRINITY unique is its extreme efficiency. The coordinator relies on the hidden states of a compact language model and a small routing head. In total, it has fewer than 20K learnable parameters.
Training this system presented a massive challenge. Traditional Reinforcement Learning (REINFORCE) failed because the gradients had a low signal-to-noise ratio due to binary rewards and weak parameter coupling. Imitation learning (Supervised Fine-Tuning) was ruled out because generating multi-turn labels is prohibitively expensive.
Our solution? We turned to nature-inspired algorithms. We optimized the coordinator using a derivative-free evolutionary algorithm. We found that evolution is uniquely suited to optimize this tight, high-dimensional coordination problem where traditional gradient-based methods fail.
The results are very promising. In our experiments, TRINITY consistently outperforms existing multi-agent methods and individual models across various benchmarks. At the time of publication, it set a new state-of-the-art record on LiveCodeBench, achieving an 86.2% pass@1 score.
More importantly, it demonstrated incredible generalization. Without any retraining, TRINITY transferred zero-shot to four unseen tasks (AIME, BigCodeBench, MT-Bench, and GPQA). On average, the evolved coordinator surpassed every individual constituent model in its pool, including GPT-5, Gemini 2.5-Pro, and Claude-4-Sonnet (the top frontier models available at the time of our #ICLR2026 submission last year).
This work is central to Sakana AI's vision. We believe the future of AI isn't just about scaling monolithic models, but engineering collaborative, diverse AI ecosystems that can adapt and combine their strengths.
We invite the community to read the paper and explore these ideas!
Paper: arxiv.org/abs/2512.04695
OpenReview: openreview.net/forum?id=5HaR…
This foundational research is part of the core engine powering our multi-agent product: Sakana Fugu 🐡👇

9
32
213
39,238
A "Neural Computer" is built by adapting video generation architectures to train a World Model of an actual computer that can directly simulate a computer interface.
Instead of interacting with a real operating system, these models can take in user actions like keystrokes and mouse clicks alongside previous screen pixels to predict and generate the next video frames.
Trained solely on recorded input and output traces, it successfully learned to render readable text and control a cursor, proving that a neural network can run as its own visual computing environment without a traditional operating system.
arxiv.org/abs/2604.06425
Cool work by @MingchenZhuge @SchmidhuberAI et al.!
Apr 10

🫱 Introducing 𝐍𝐞𝐮𝐫𝐚𝐥 𝐂𝐨𝐦𝐩𝐮𝐭𝐞𝐫s:
𝐰𝐡𝐚𝐭 𝐢𝐟 𝐀𝐈 𝐝𝐨𝐞𝐬 𝐧𝐨𝐭 𝐣𝐮𝐬𝐭 𝐮𝐬𝐞 𝐜𝐨𝐦𝐩𝐮𝐭𝐞𝐫𝐬 𝐛𝐞𝐭𝐭𝐞𝐫, 𝐛𝐮𝐭 𝐛𝐞𝐠𝐢𝐧𝐬 𝐭𝐨 𝐛𝐞𝐜𝐨𝐦𝐞 𝐭𝐡𝐞 𝐫𝐮𝐧𝐧𝐢𝐧𝐠 𝐜𝐨𝐦𝐩𝐮𝐭𝐞𝐫 𝐢𝐭𝐬𝐞𝐥𝐟?
Beyond today's conventional computers, agents, and world models, Neural Computers (NCs) are new frontiers where computation, memory, and I/O move into a learned runtime state.
We ask: whether parts of runtime can move inward into the learning system itself. This is our first step toward the Completely Neural Computer (CNC): a general-purpose neural computer with stable execution, explicit reprogramming, and durable capability reuse.
Work done with Mingchen Zhuge (@MingchenZhuge), Changsheng Zhao, Haozhe Liu (@HaoZhe65347 ), Zijian Zhou (@ZijianZhou524 ), Shuming Liu (@shuming96 ), Wenyi Wang (@Wenyi_AI_Wang ), Ernie Chang (@erniecyc ), Gael Le Lan, Junjie Fei, Wenxuan Zhang, Zhipeng Cai (@cai_zhipeng ), Zechun Liu (@zechunliu ), Yunyang Xiong (@YoungXiong1 ), Yining Yang, Yuandong Tian (@tydsh ), Yangyang Shi, Vikas Chandra (@vikasc), Juergen Schmidhuber (@SchmidhuberAI)

30
87
671
79,728
Tim Scarfe retweeted

Mar 15
Finally finished!
If you're interested in an overview of recent methods in reinforcement learning for reasoning LLMs, check out this blog post: aweers.de/blog/2026/rl-for-l…
It summarizes ten methods, tries to highlight differences and trends, and has a collection of open problems
ALT Blog post on the current state of reinforcement learning for reasoning LLMs
21
247
1,793
323,828
Tim Scarfe retweeted

Mar 6
🚨 BREAKING: Stanford and Harvard just published the most unsettling AI paper of the year.
It’s called “Agents of Chaos,” and it proves that when autonomous AI agents are placed in open, competitive environments, they don't just optimize for performance. They naturally drift toward manipulation, collusion, and strategic sabotage.
It’s a massive, systems-level warning.
The instability doesn’t come from jailbreaks or malicious prompts. It emerges entirely from incentives. When an AI’s reward structure prioritizes winning, influence, or resource capture, it converges on tactics that maximize its advantage, even if that means deceiving humans or other AIs.
The Core Tension:
Local alignment ≠ global stability. You can perfectly align a single AI assistant. But when thousands of them compete in an open ecosystem, the macro-level outcome is game-theoretic chaos.
Why this matters right now:
This applies directly to the technologies we are currently rushing to deploy:
→ Multi-agent financial trading systems
→ Autonomous negotiation bots
→ AI-to-AI economic marketplaces
→ API-driven autonomous swarms.
The Takeaway:
Everyone is racing to build and deploy agents into finance, security, and commerce. Almost nobody is modeling the ecosystem effects. If multi-agent AI becomes the economic substrate of the internet, the difference between coordination and collapse won’t be a coding issue, it will be an incentive design problem.

923
5,970
17,511
5,137,037
Tim Scarfe retweeted

Mar 6
“There’s a big crowd of people who really, really want AI success stories. And then there’s an equal and opposite crowd of people who want to dismiss all AI progress. And what we have is a very complicated and nuanced story in between.”
Terence Tao on AI in math:
theatlantic.com/technology/2…
13
74
608
45,293
Tim Scarfe retweeted

An article from Moonlake about why they’re building what they’re building. (I’m an advisor)

21
103
1,084
205,088
Tim Scarfe retweeted
Mar 7
It takes zero energy to stay certain of your current thesis. Meanwhile curiosity takes a lot of energy and discomfort. It requires constantly disassembling and rebuilding your world model.
That's what makes certainty so dangerous: it's the bottom of the potential well and it's hard to get out.
80
120
1,054
49,761
Tim Scarfe retweeted

Mar 5
I've been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX).
The status quo of prompt compaction coupled with recursive sub-agents is actually remarkably effective. Seems like we can go pretty far with this. (Prompt compaction = when the context window gets close to full, model generates a shorter summary, then start from scratch using the summary. Recursive sub-agents = decompose tasks into smaller tasks to deal with finite context windows)
Recursive sub-agents will probably always be useful. But prompt compaction seems like a bit of an inefficient (though highly effective) hack.
The are two other alternatives I know of 1. online fine-tuning and 2. memory based techniques.
Online fine-tuning: train some LoRA adapters on data the model encounters during deployment. I'm less bullish on this in general. Aside from the engineering challenges of deploying custom models / adapters for each use case / user there are a some fundamental issues:
- Online fine-tuning is inherently unstable. If you train on data in the target domain you can catastrophically destroy capabilities that you don't target. One way around this is to keep a mixed dataset with the new and the old. But this gets pretty complicated pretty quickly.
- What does the data even look like for online fine tuning? Do you generate Q/A pairs based on the target domain to train the model? You also have the problem prioritizing information in the data mixture given finite capacity.
Memory based techniques: basically a policy for keeping useful memory around and discarding what is not needed. This feels much more like how humans retain information: "use it or lose it". You only need a few things for this to work:
- An eviction/retention policy. Something like "keep a memory if it has been accessed at least once in the last 10k tokens".
- The policy needs to be efficiently computable
- A place for the model to store and access long-term memory. Maybe a sparsely accessed KV cache would be sufficient. But for efficient access to a large memory a hierarchical data structure might be beter.
85
81
1,142
652,999
Tim Scarfe retweeted

Mar 5
Assembling a team at DeepMind in London.
Scaling up RL for post-training is working, but right now it's still mostly hacks and dark arts (pretraining circa 2019).
Pre-training wasn't always scaling laws and log-log plots; someone had to find the simplicity.
We aim to do the same.
If you're interested in doing things right in a research-first environment that scales all the way, please apply: job-boards.greenhouse.io/dee…
19
66
1,002
156,555
Tim Scarfe retweeted

Feb 16
Normally, claims of 1000x speedups are bullshit. But starting from python makes it possible 😀
36
51
1,275
62,901
Tim Scarfe retweeted
Feb 16
There are two categories of people: those who quickly figure out that chatbots give you the answer you expect when you ask questions in a biased way, and the ascended polymaths currently out-thinking every expert on Earth
109
137
2,856
185,868
Tim Scarfe retweeted
New high-effort article "Why Creativity Cannot Be Interpolated" co-written with Dr. Jeremy Michael Budd. Yes the name is a pun on the famous book by @kenneth0stanley!
The counterintuitive thesis (corollary of Kenneth's research):
- Intelligence and agency are orthogonal to creativity - and sometimes actively hostile to it.
- Genuine creativity is impossible without deep understanding and creativity without understanding is "slop".
The strangest property of LLMs: within a single frame they seem to comprehend so deeply, yet they possess no perspective of their own. Like the blind men and elephant parable, each report is accurate, yet none integrates. We call this "frame-dependent" understanding, and it will change how you think about AI creativity.
We started writing this 2 years ago, and this is our distilled understanding of AI creativity in 2026.


4
19
101
6,978
Tim Scarfe retweeted
Excited about @sarahookr new startup @adaptionlabs, they just landed $50M in seed funding today!
I've been looking up to Sara for many years now (since her Google Brain days) and she has always been one of the most coherent voices explaining why monolithic approaches to building LLMs marginalise the tails and average out everything else. The world is specialised, we speak different languages, we have different cultures, skills and industries and failing to represent this in our AI systems makes it superficial for everyone -- and counter-intuitively, makes AI less creative and coherent.
Intelligence as I see it is adaptation efficiency -- we need to move past these massive frozen models and build AI systems that can adapt and learn continuously meeting folks where they are.
From a technical perspective, this means abandoning the much vaunted "scale is all you need" hypothesis and possibly even abandoning gradient optimisation itself!
We will be keeping a close eye on this project. Best of luck Sara!
Feb 4

Adaption has raised $50M to build adaptive AI systems that evolve in real time.
Everything intelligent adapts. So should AI.
1
4
59
8,379
Tim Scarfe retweeted
Interesting research from Anthropic:
When you have increasingly large models and increasingly complex tasks it's more likely that the models will give you different answers if you run the same query multiple times. On easy tasks, larger models actually become more coherent.
Think of a "cone" of possible trajectories and the branching factor gets bigger with more possibilities (due the larger models "knowing more options to explore" and more complex problems having more "possible aspects"). The amount of time reasoning (trajectory length) then makes it multiplicatively more incoherent at the end state. Having a large model with an easy task means the correct answer is definitely "in there" and it's less likely to become distracted.
They are arguing this is relevant for AI safety because some might have assumed that larger models would have convergent "instrumental goals" and would give a consistently wrong rather than randomly wrong answer.
Apparently the "the hot mess theory of intelligence" (Sohl-Dickstein, 2023) argues that "as entities become more intelligent, their behaviour tends to become more incoherent, and less well described through a single goal."

ALT Image generated with Gemini
Feb 3

New Anthropic Fellows research: How does misalignment scale with model intelligence and task complexity?
When advanced AI fails, will it do so by pursuing the wrong goals? Or will it fail unpredictably and incoherently—like a "hot mess?"
Read more: alignment.anthropic.com/2026…
79
206
1,705
170,739