
prof @Northeastern, media & tech, AIMES Lab, IIID, Social Fact, Governing Babel
Joined February 2009
- Tweets 5,104
- Following 2,969
- Followers 2,634
- Likes 7,030
208 Photos and videos









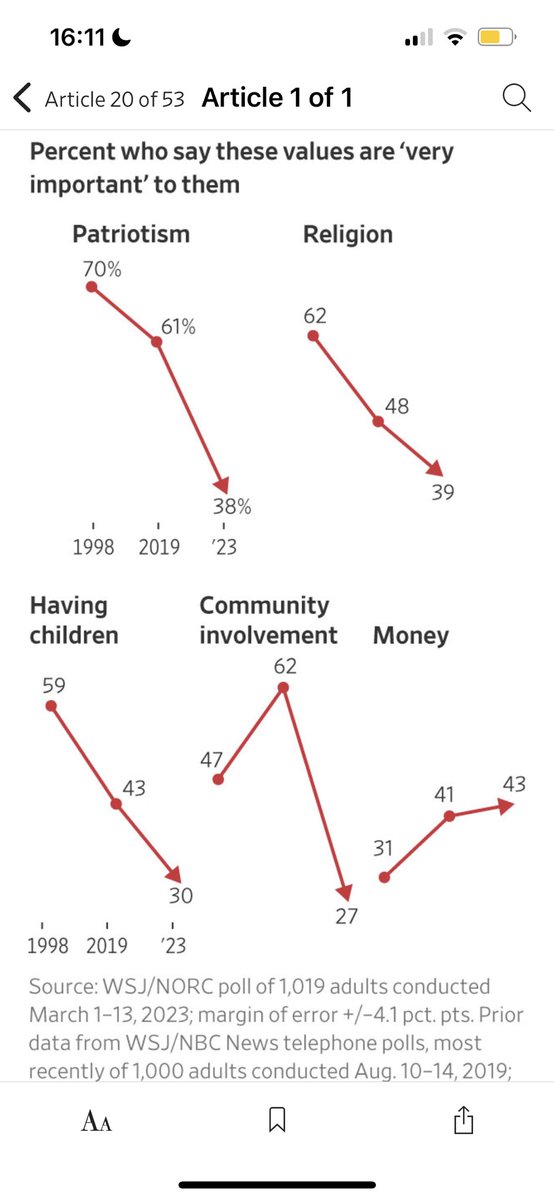





How do we go from AGI to Superintelligence? New report discusses four potential pathways: scaling, AI paradigm shifts, recursive improvement, and ASI emerging from large-scale multi- agent collectives. Importantly, it also looks at possible frictions and bottlenecks along these pathways. Instant classic! arxiv.org/abs/2606.12683

34
167
713
87,308
John Wihbey retweeted

May 6
APSA AI Task Force Report (DRAFT), cochaired by me and @j_a_tucker and including chapters by 60 social scientists, now available... to be published by Cambridge Press later this year
apsanet.org/wp-content/uploa…

2
60
161
12,932
John Wihbey retweeted

May 5
Every firm will need to reconceptualize work as they build agentic systems.
As AI and agents take on more of the execution, the opportunity is to expand human agency and redesign how work gets done.
An in-depth look from the team at what this shift means and key considerations for every business: microsoft.com/en-us/worklab/…
250
372
2,135
253,349
John Wihbey retweeted

Apr 16
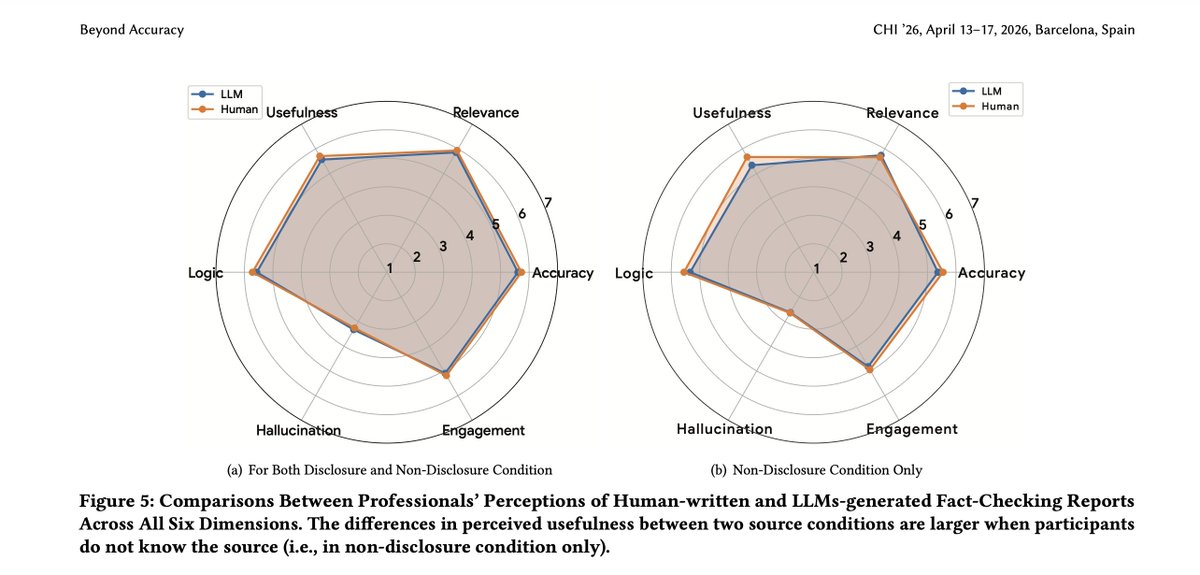
LLMs can match human accuracy in fact-checking, but media experts still find them less useful—especially when they aren't told the source.
Our new #CHI2026 paper, "Beyond Accuracy," explores this critical gap between technical accuracy and practical utility for human experts.
📅 Catch our talk TODAY: Thu, 16 Apr | 9:12 AM - 9:24 AM
🔗 Read the paper here: dl.acm.org/doi/10.1145/37723…
1
2
12
2,803
John Wihbey retweeted

Apr 16
This Report of the Yale Committee on Trust in Higher Education is well-worth reading in full. I hope my colleagues will take these recommendations seriously president.yale.edu/sites/def…



5
27
175
24,329

When AI aggregators update too quickly, there is no positive-measure set of training weights that improves learning access, whereas such weights exist when updating is slow, from @DAcemogluMIT, Tianyi Lin, Asuman Ozdaglar, and James Siderius nber.org/papers/w35036

12
37
7,202
John Wihbey retweeted

Mar 28
Talking to AI shifts political opinions. Sometimes a little left, sometimes a little right. And reduces polarization a bit too!
How *should* AI influence our politics? Well, I have a practical idea about that...
🧵

3
1
17
1,024
John Wihbey retweeted

Mar 20
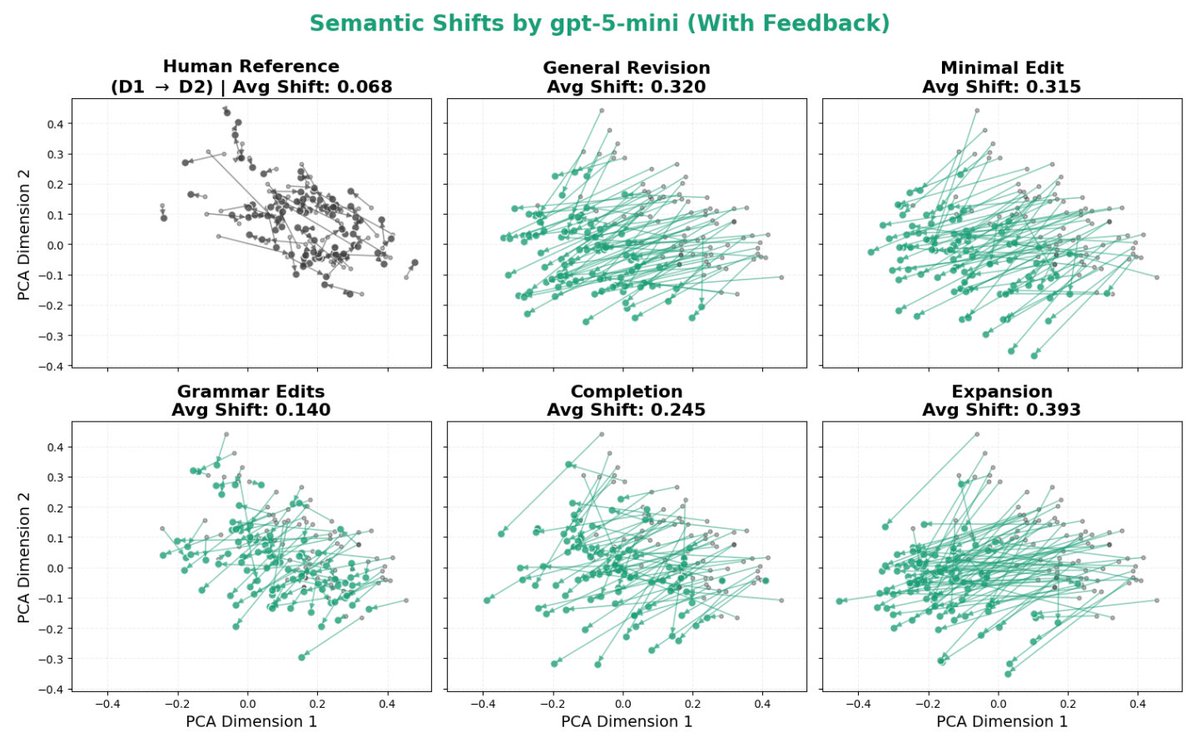
The paper I’ve been most obsessed with lately is finally out: nbcnews.com/tech/tech-news/a…! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.
45
391
1,478
258,975
John Wihbey retweeted

Mar 13
Dear followers,
I’m happy to share this new academic paper on how even capable AI can lead to deterioration of collective knowledge in society

Studying how generative AI, and in particular agentic AI, shapes human learning incentives and the long-run evolution of society’s information ecosystem, from @DrDaronAcemoglu, Dingwen Kong, and Asuman Ozdaglar nber.org/papers/w34910

93
997
3,942
541,870
John Wihbey retweeted

Mar 4
Yoshua Bengio, Maria Ressa to co-chair UN’s AI panel rappler.com/world/global-aff… via @rapplerdotcom
3
16
87
3,711
John Wihbey retweeted

This week’s Law & Tech Talk examined “AI and Social Media: Global Perils and Governance Possibilities.” Thank you to Prof. John @wihbey for an excellent presentation!



1
1
6
472
John Wihbey retweeted

Jan 21
Wow.
This looks like an amazing project.
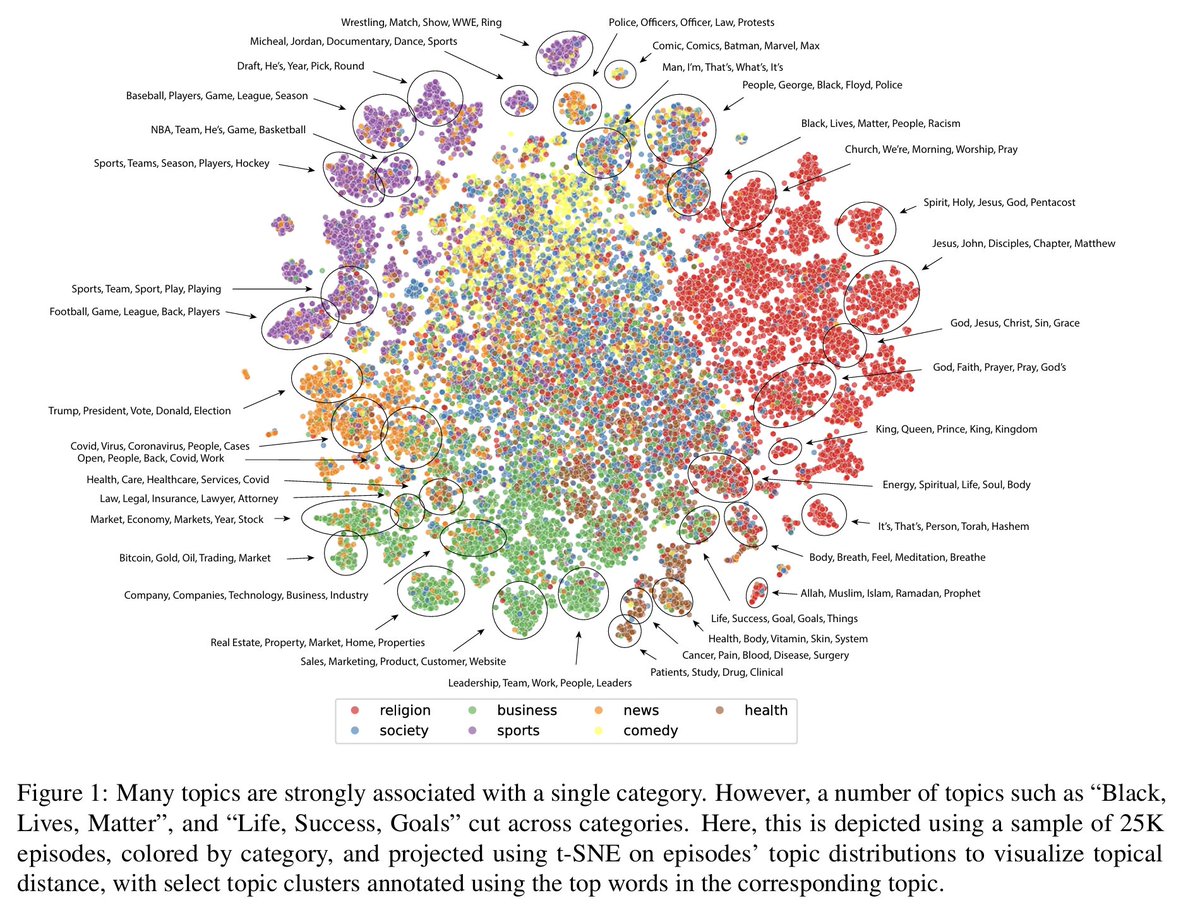
Scholars at UMichigan have recently collected a massive dataset of over 1.1M podcast transcripts that is largely comprehensive of all English language podcasts.
Using this data, they conduct an investigation into the content, structure, and responsiveness of the podcast ecosystem.
Check it out!
61
527
3,228
330,099
John Wihbey retweeted

Do federal funding cuts spell the end for Big Bird and Cookie Monster? @Northeastern experts weigh in below: ⤵️
bit.ly/4qhUnNI
1
1
1
100

13 Nov 2025
Some of my thoughts here on AI, public knowledge, and where we may be headed as a culture: techpolicy.press/in-post-aut… @techpolicypress
92
John Wihbey retweeted

18 Oct 2025
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet x.com/karpathy/status/188254… Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast x.com/karpathy/status/197343… . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. x.com/karpathy/status/194443… . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" x.com/karpathy/status/196080…. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" x.com/karpathy/status/192136… , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": x.com/karpathy/status/193862… , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" x.com/karpathy/status/181403…
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: x.com/karpathy/status/150339… . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) x.com/karpathy/status/197775…
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. x.com/karpathy/status/191558…
Job automation. How the radiologists are doing great x.com/karpathy/status/197122… and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell x.com/karpathy/status/192969… I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
17 Oct 2025

The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
575
1,968
16,791
4,076,255
John Wihbey retweeted

8 Oct 2025
We found a troubling emergent behavior in LLM.
💬When LLMs compete for social media likes, they start making things up
🗳️When they compete for votes, they turn inflammatory/populist
When optimized for audiences, LLMs inadvertently become misaligned—we call this Moloch’s Bargain

845
1,945
9,645
1,340,259
John Wihbey retweeted

2 Oct 2025
Our next CfD Conversation is about artificial intelligence and truth. 💡 On Oct. 15 from 12-1:30 p.m. ET, our panelists will explore how generative AI has become a pivotal force in the proliferation of mis- and disinformation. Register at the link below.
camd.northeastern.edu/events…

1
2
98
26 Sep 2025
Using AI to do message testing/scope public preferences? My lab's new paper provides guidance: "AI Simulations of Audience Attitudes and Policy Preferences: “Silicon Sampling” Guidance for Communications Practitioners" lnkd.in/eKgn3tTE @BurnesCenter @Northeastern
1
82
24 Sep 2025
The First Amendment is one of America’s greatest global contributions and is a key foreign policy lever. Let’s renew it and use it to think through our networked platform challenges. This is my call in Governing Babel (out Oct 7): mitpress.mit.edu/97802620499… @mitpress @Northeastern
1
128
18 Sep 2025
Just had my students asking what the heck the FCC is and how could it do this... Internet generation is like: Someone in gov't can do this kind of thing? I am also astonished, frankly. I have been writing about the FCC as a legacy org, not central. Then this all happened.
2
64