
wolfbench.ai // @WolframRvnwlf's new evaluation framework for models and agents: because one score is not enough! // brought to you by @CoreWeave/@wandb
- Tweets 33
- Following 15
- Followers 314
- Likes 126

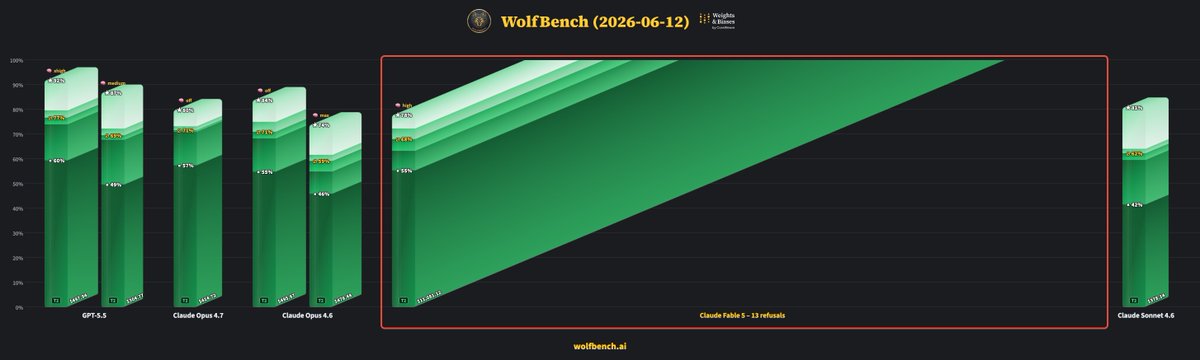
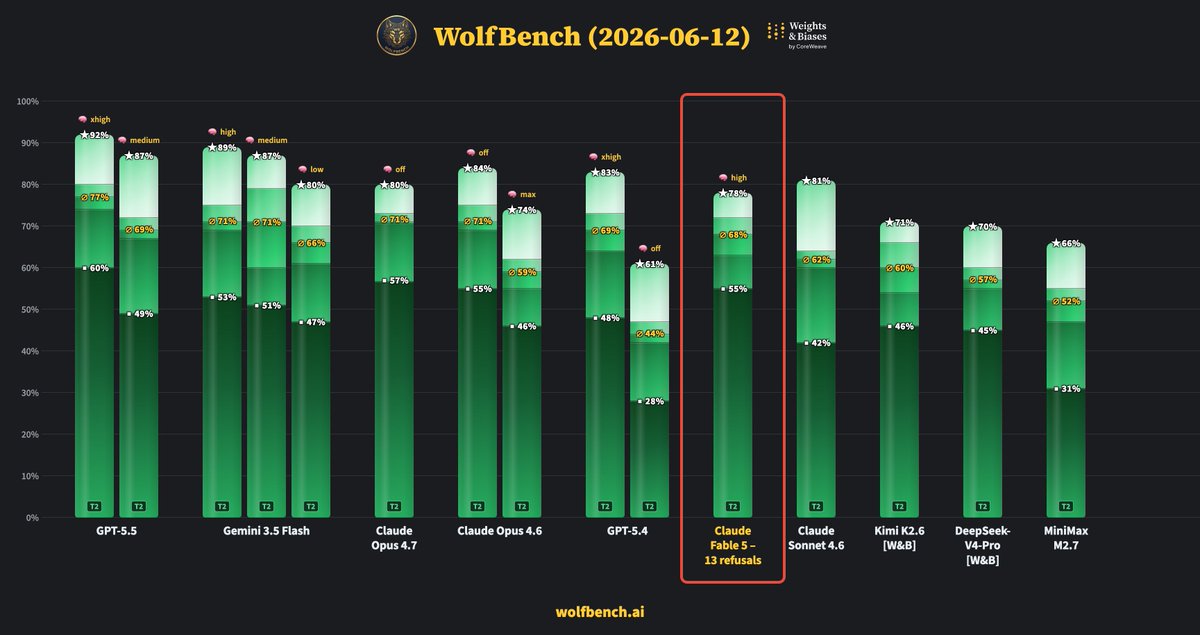



ALT Bar chart comparing AI models' performances, highlighting Claude Fable 5's 13 refusals with lower scores than others on WolfBench.
ALT Bar chart comparing AI models' performances, highlighting Claude Fable 5's 13 refusals with lower scores than others on WolfBench.
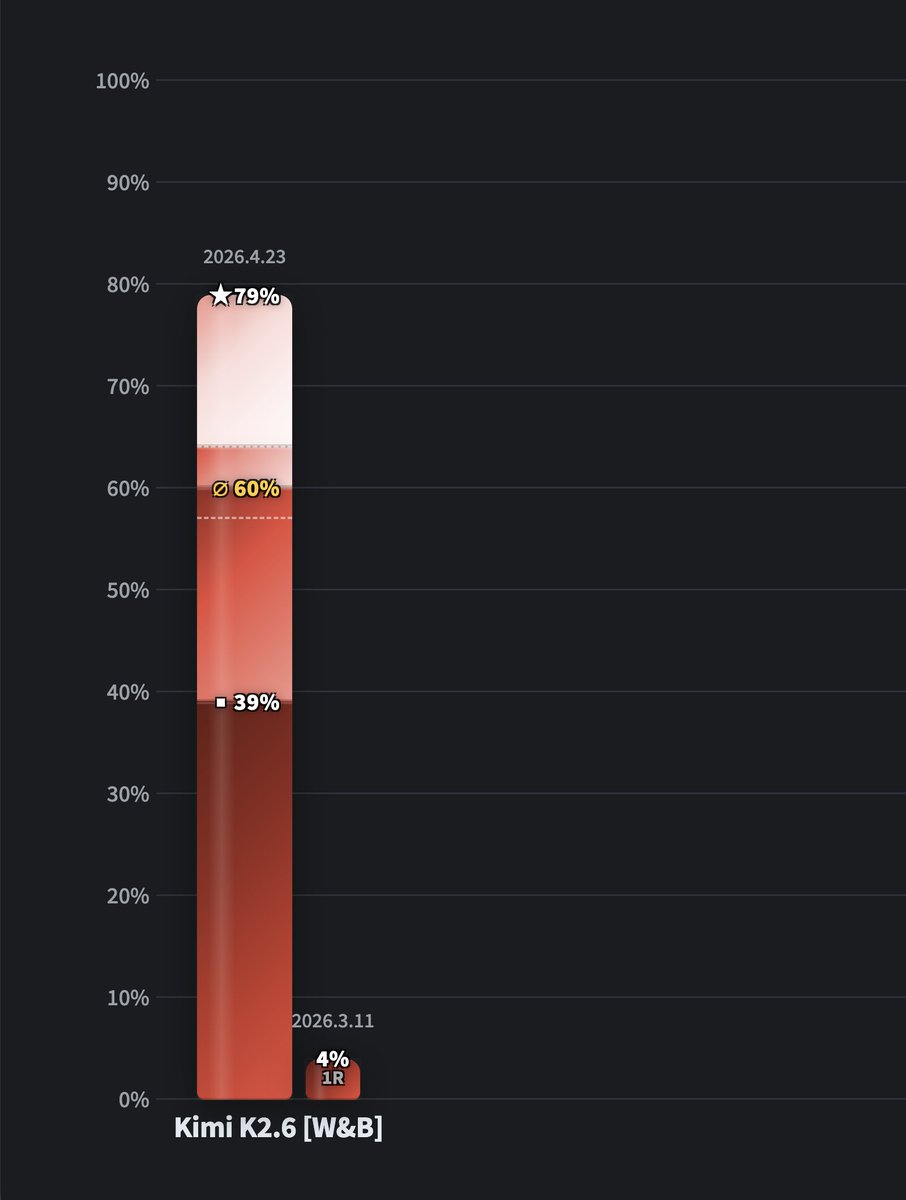
ALT Bar graph showing performance changes of Kimi K2.6, with scores rising from 4% to 60% after OpenClaw version update.
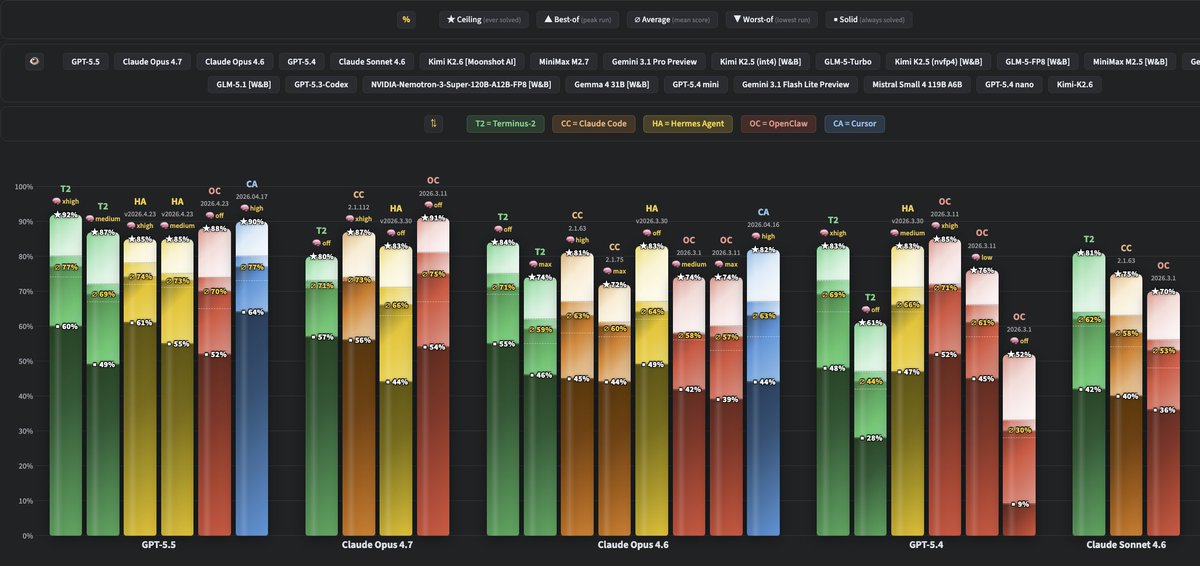
ALT GPT-5.5 takes over WolfBench! It’s now the #1 model, ahead of Claude Opus 4.7 and 4.6, GPT-5.4, Sonnet 4.6, Kimi K2.6, Gemini 3.1 Pro, and more.
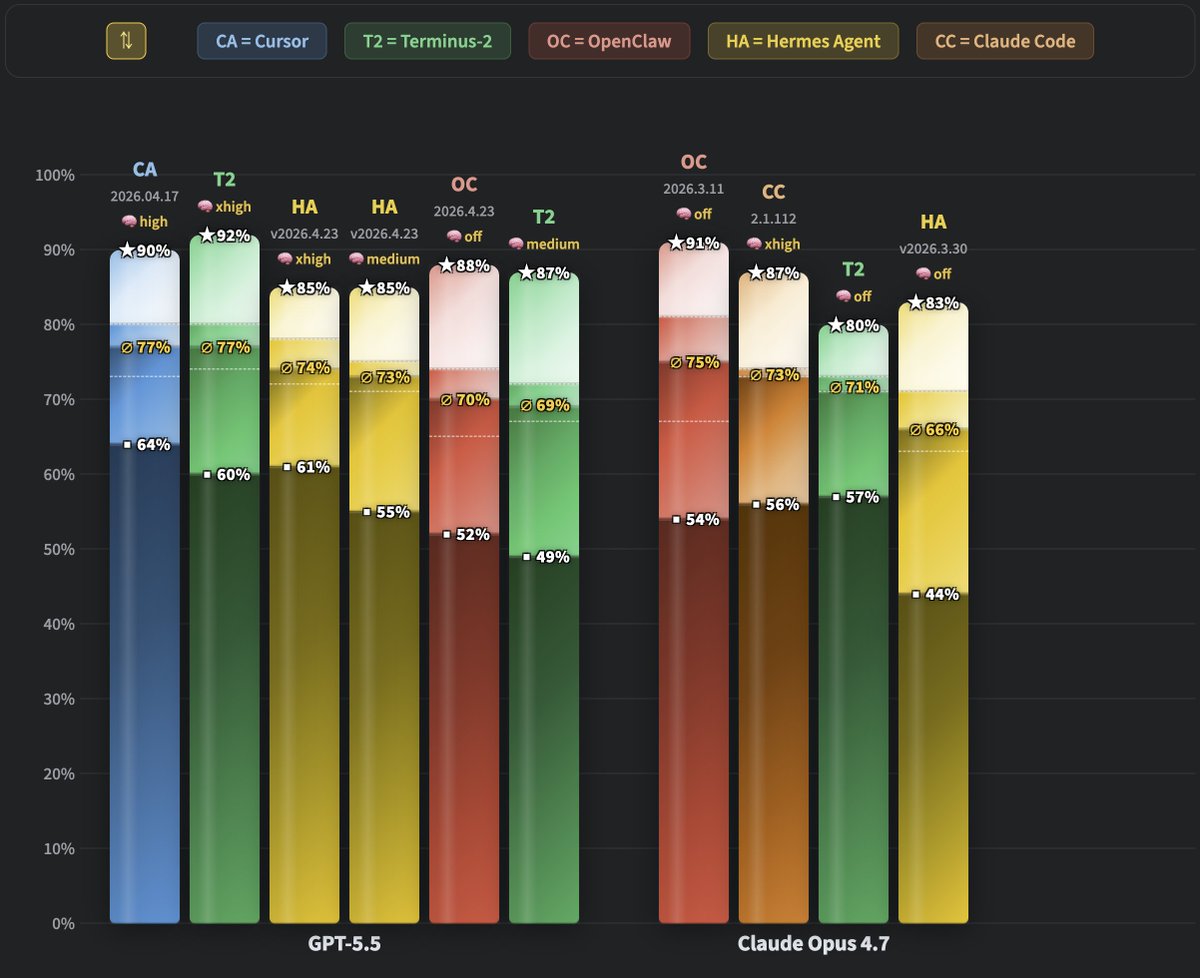
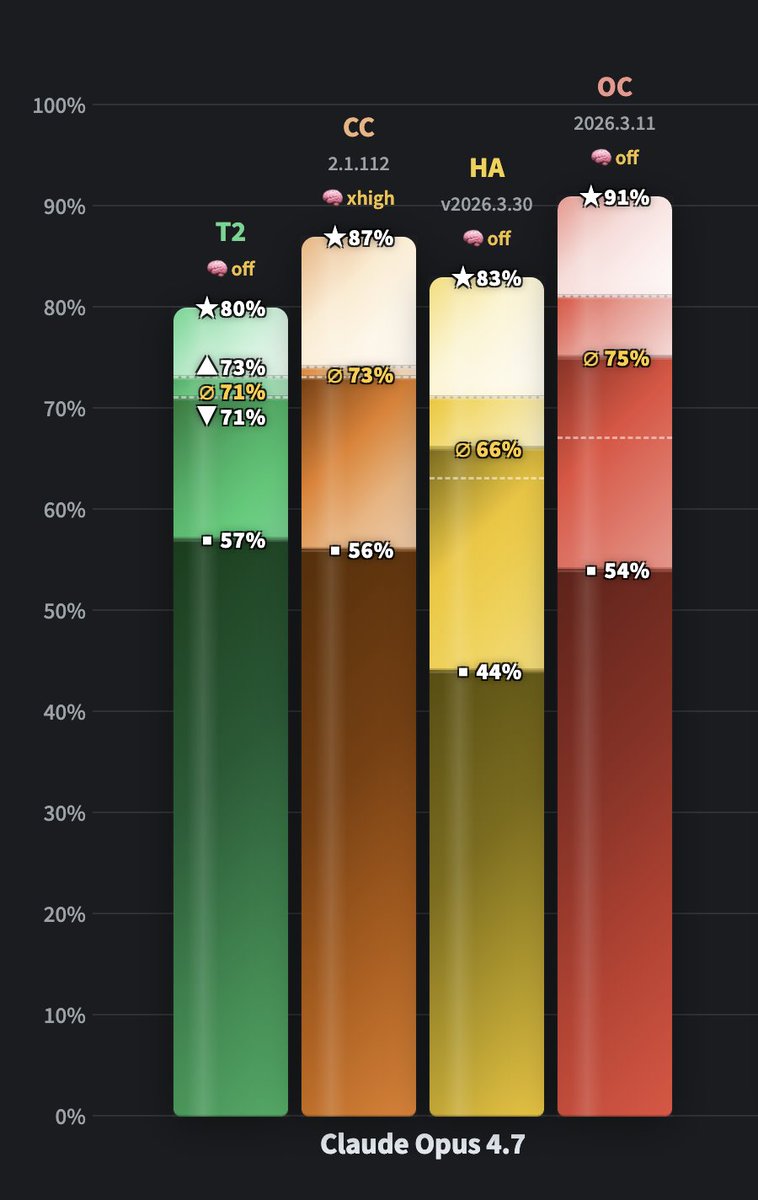
ALT Comparing GPT-5.5 vs. Claude Opus 4.7 on WolfBench
ALT WolfBench.ai









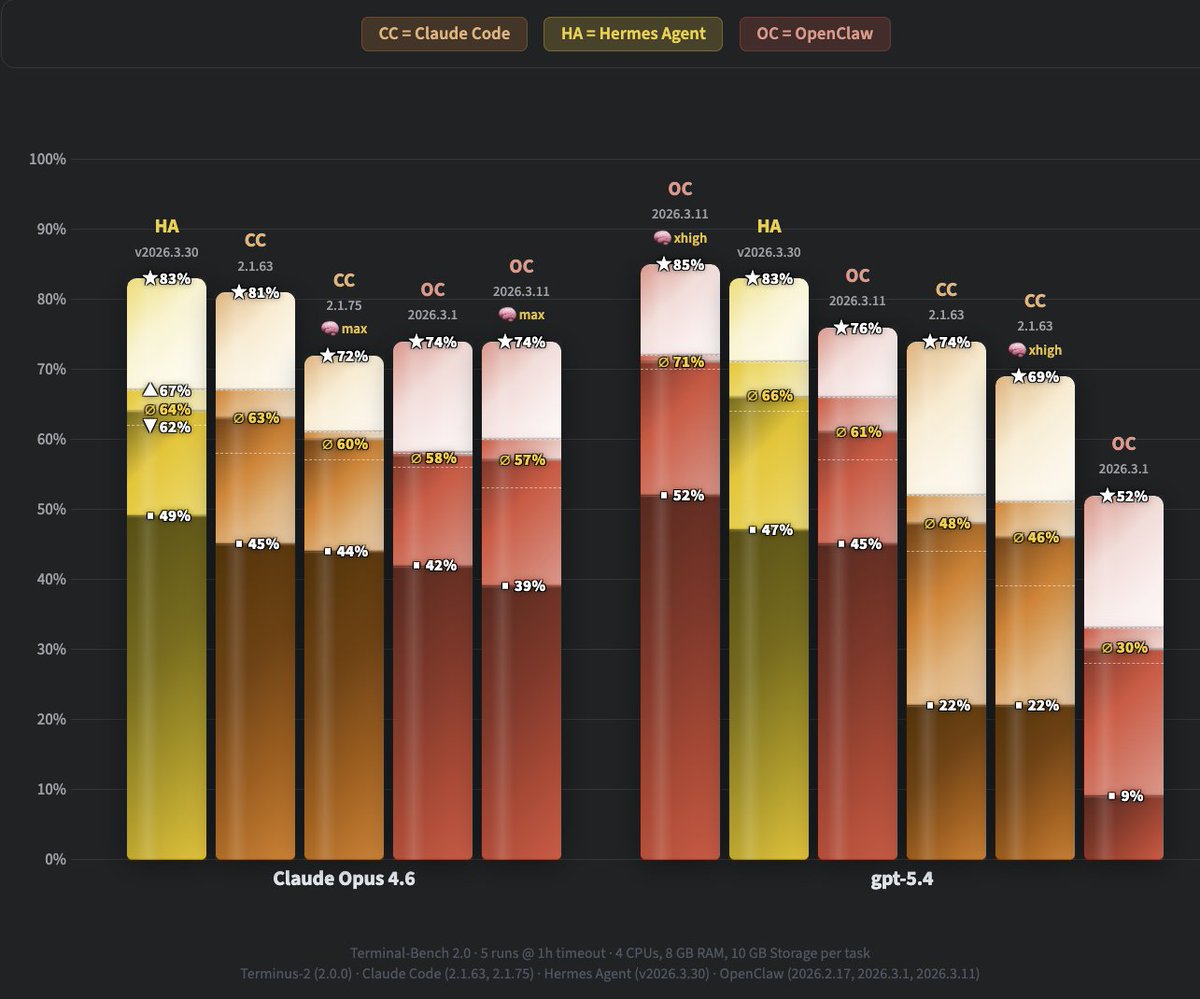
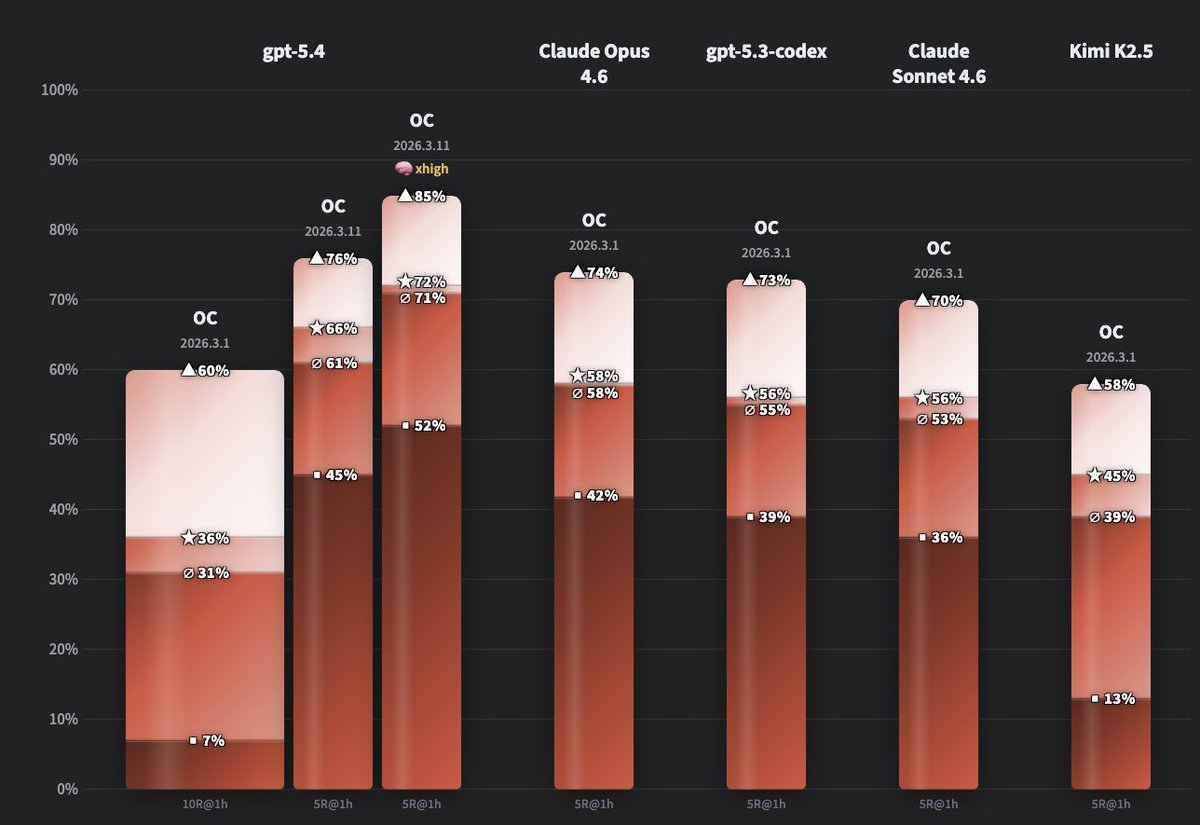
ALT GPT 5.4 takes the top spot on WolfBench with OpenClaw!

