
29 Photos and videos












Recently I dominantly use AI coding agent for all development / brainstorm / research (just drop in every source text and screenshots to the repo). A terminal agent doesn't just code—it treats writing, math, and prose exactly like a software engineering task.
📊 Social Scientist: Coding Agent (20%) v.s. Chatbot (80%)
anthropic.com/research/codin…
🔬 STEM Researcher: Chatbot for strategy, Coding Agent for execution
anthropic.com/research/vibe-…
💻 Computer Science: ~100% Coding Agent?
2
4
632
💡 There are a lot of interesting workflow tips packed in these posts, such as
Cross-Model Critique: Don't let an agent grade its own homework. Pipe its terminal output to another frontier LLM (like GPT) to audit and catch subtle errors.
Workspace Trees: Keep chat threads short. Have the agent maintain a folder of markdown summaries. It's much more accurate than relying on long conversation memory.
Honesty: Add a rule in your CLAUDE.md repo config: "NEVER use phrases like 'this becomes' to skip math or code steps. Show the work or say 'I don't know'."
1
391

GPT-3: Language Models are Few-Shot Learners, by @notTomBrown et al.
“We train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting.”
arxiv.org/abs/2005.14165

11
162
645
Xinya Du retweeted

May 21
Talk: Training Composer
youtube.com/watch?v=uTgqYeVx…
Overview of the methods that we use at Cursor to build our model.
6
85
685
98,063
Xinya Du retweeted

Can we actually TRAIN LLMs for scientific discovery — or only prompt them to brainstorm? 🧬✨
🎉 MOOSE-Star → #ICML2026
Most work on LLMs for hypothesis discovery focuses on inference-time agents or feedback-driven refinement. The core generative process — P(hypothesis | research background), or P(h|b) — has been largely sidestepped: directly training it remains an open problem. We show why: a combinatorial complexity barrier makes naive end-to-end training mathematically intractable.
First scalable recipe for training P(h|b), with clean scaling laws on both training data and test-time compute.
📄 Paper: arxiv.org/abs/2603.03756
💻 GitHub: github.com/ZonglinY/MOOSE-St…
🤗 HF: huggingface.co/collections/Z…
🧵👇

ALT Concept illustration: a deer leaping through a starry universe, representing the search for scientific inspirations across a vast literature space.
3
19
68
225,763
Xinya Du retweeted

Apr 14
New Anthropic Fellows research: developing an Automated Alignment Researcher.
We ran an experiment to learn whether Claude Opus 4.6 could accelerate research on a key alignment problem: using a weak AI model to supervise the training of a stronger one.
anthropic.com/research/autom…
231
278
2,387
450,691
Xinya Du retweeted

Apr 2
Same, I have a similar setup. A mix of Obsidian, Cursor (for md), and vibe-coded web terminals as front-end.
Since I do a podcast, the number/diversity of research interests is very large. But the knowledge-base approach has been working great.
For answers, I often have it generate dynamic html (with js) that allows me to sort/filter data and to tinker with visualizations interactively.
Another useful thing is I have the system generate a temporary focused mini-knowledge-base for a particular topic that I then load into an LLM for voice-mode interaction on a long 7-10 mile run. So it becomes an interactive podcast while I run, where I ask it questions and listen to the answers to learn more.
Anyway, heading out for a run now, thanks for the write-up 👊
192
222
5,723
654,774
Xinya Du retweeted
Apr 2
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
1,037
2,676
17,755
3,901,734
Xinya Du retweeted

Mar 24
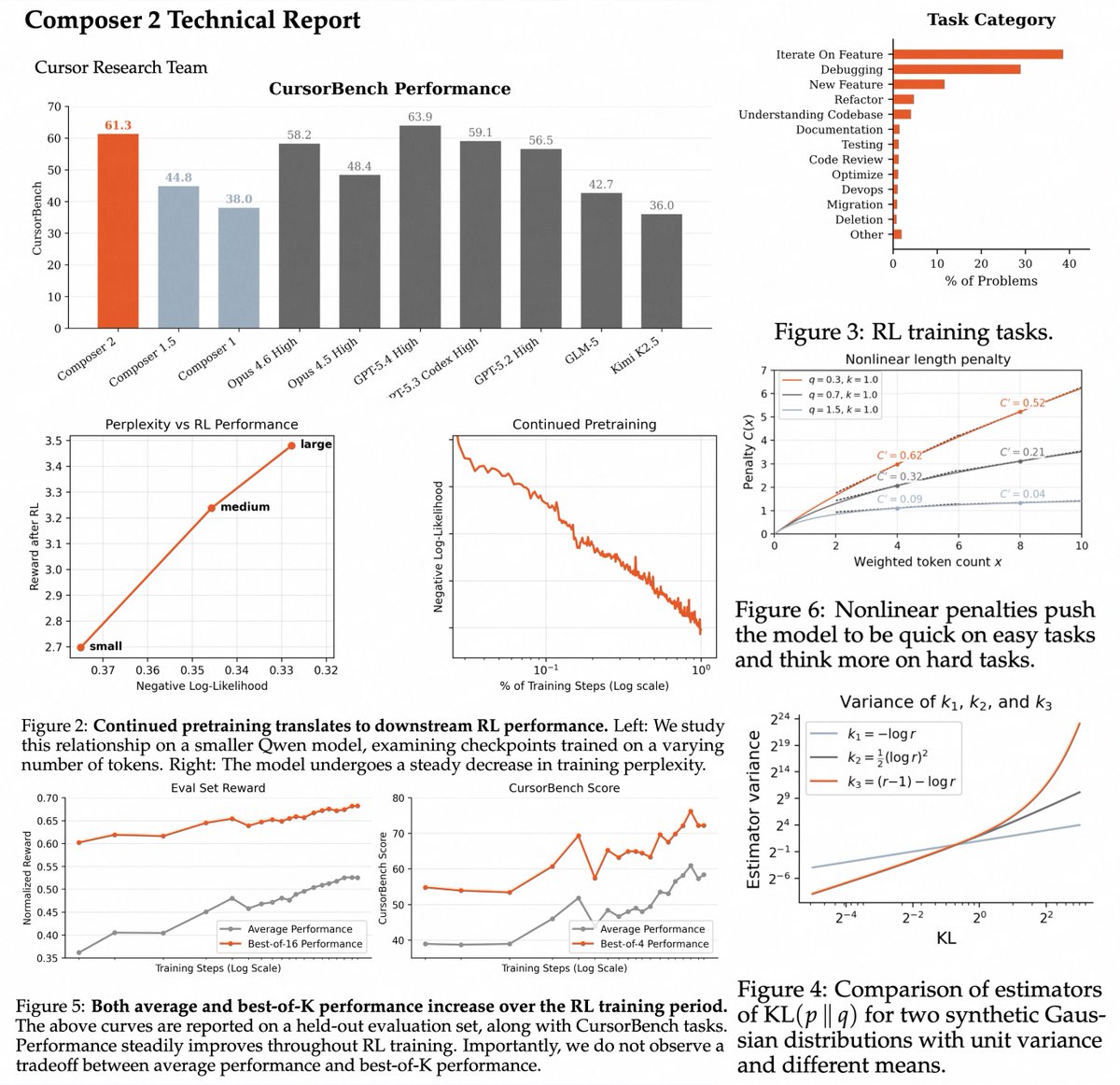
cursor composer 2 tech report is VERY VERY nice
some of the things i found interesting:
> nice "scaling" study of how rl performance is impacted by continual pretraining (more flops => lower ppl => higher RL perf)
> they added mtp head to k2.5 for speculative decoding, they use self distillation objective which is not standard i think for mtp training
> they added length penalty RL to force the model to think more on long tasks and less on easy ones
> they use self summarization (introduced in a previous blog post). cursor mentions the model has a 200k context window but the tech report mentions ctx extension to 256k, so it means they reserve 50k for the compaction/self summarization? it's a bit higher than the 33k token in claude code.
> nice that they report improvement on both best of k and average perf
> very very nice infra section on kernels, parallelism, quantization and muchhh more (i need to read this more in depth!)


7
30
371
40,102
Xinya Du retweeted

Feb 27
I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at :)
I tried a few setups: 8 independent solo researchers, 1 chief scientist giving work to 8 junior researchers, etc. Each research program is a git branch, each scientist forks it into a feature branch, git worktrees for isolation, simple files for comms, skip Docker/VMs for simplicity atm (I find that instructions are enough to prevent interference). Research org runs in tmux window grids of interactive sessions (like Teams) so that it's pretty to look at, see their individual work, and "take over" if needed, i.e. no -p.
But ok the reason it doesn't work so far is that the agents' ideas are just pretty bad out of the box, even at highest intelligence. They don't think carefully though experiment design, they run a bit non-sensical variations, they don't create strong baselines and ablate things properly, they don't carefully control for runtime or flops. (just as an example, an agent yesterday "discovered" that increasing the hidden size of the network improves the validation loss, which is a totally spurious result given that a bigger network will have a lower validation loss in the infinite data regime, but then it also trains for a lot longer, it's not clear why I had to come in to point that out). They are very good at implementing any given well-scoped and described idea but they don't creatively generate them.
But the goal is that you are now programming an organization (e.g. a "research org") and its individual agents, so the "source code" is the collection of prompts, skills, tools, etc. and processes that make it up. E.g. a daily standup in the morning is now part of the "org code". And optimizing nanochat pretraining is just one of the many tasks (almost like an eval). Then - given an arbitrary task, how quickly does your research org generate progress on it?
Feb 27

How come the NanoGPT speedrun challenge is not fully AI automated research by now?
562
797
8,715
1,635,101
Xinya Du retweeted
Feb 11
On DeepWiki and increasing malleability of software.
This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use:
Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A:
deepwiki.com/karpathy/nanoch…
Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it.
But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried:
"Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained"
Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat
github.com/karpathy/nanochat…
Anyway TLDR I find this combo of DeepWiki MCP GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (x.com/karpathy/status/194161…)
There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?
5 Jul 2025

How to build a thriving open source community by writing code like bacteria do 🦠. Bacterial code (genomes) are:
- small (each line of code costs energy)
- modular (organized into groups of swappable operons)
- self-contained (easily "copy paste-able" via horizontal gene transfer)
If chunks of code are small, modular, self-contained and trivial to copy-and-paste, the community can thrive via horizontal gene transfer. For any function (gene) or class (operon) that you write: can you imagine someone going "yoink" without knowing the rest of your code or having to import anything new, to gain a benefit? Could your code be a trending GitHub gist?
This coding style guide has allowed bacteria to colonize every ecological nook from cold to hot to acidic or alkaline in the depths of the Earth and the vacuum of space, along with an insane diversity of carbon anabolism, energy metabolism, etc. It excels at rapid prototyping but... it can't build complex life. By comparison, the eukaryotic genome is a significantly larger, more complex, organized and coupled monorepo. Significantly less inventive but necessary for complex life - for building entire organs and coordinating their activity. With our advantage of intelligent design, it should possible to take advantage of both. Build a eukaryotic monorepo backbone if you have to, but maximize bacterial DNA.
299
764
7,245
1,114,470
Xinya Du retweeted

Feb 10
Thanks to good people at @AnthropicAI we now have an official MCP for Excalidraw!
Take it for a spin on @claudeai (search for Excalidraw in Connectors, or use in Claude Code and elsewhere).
More to come. ✌
Feb 10

We are moving quickly. Thanks to Anton and the folks at @excalidraw , this is now the official Excalidraw MCP server. From weekend project to official server in less than a week.
190
534
6,320
797,468
Jan 26
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual autocomplete coding and 20% agents in November to 80% agent coding and 20% edits touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
573
Xinya Du retweeted

3 Dec 2025
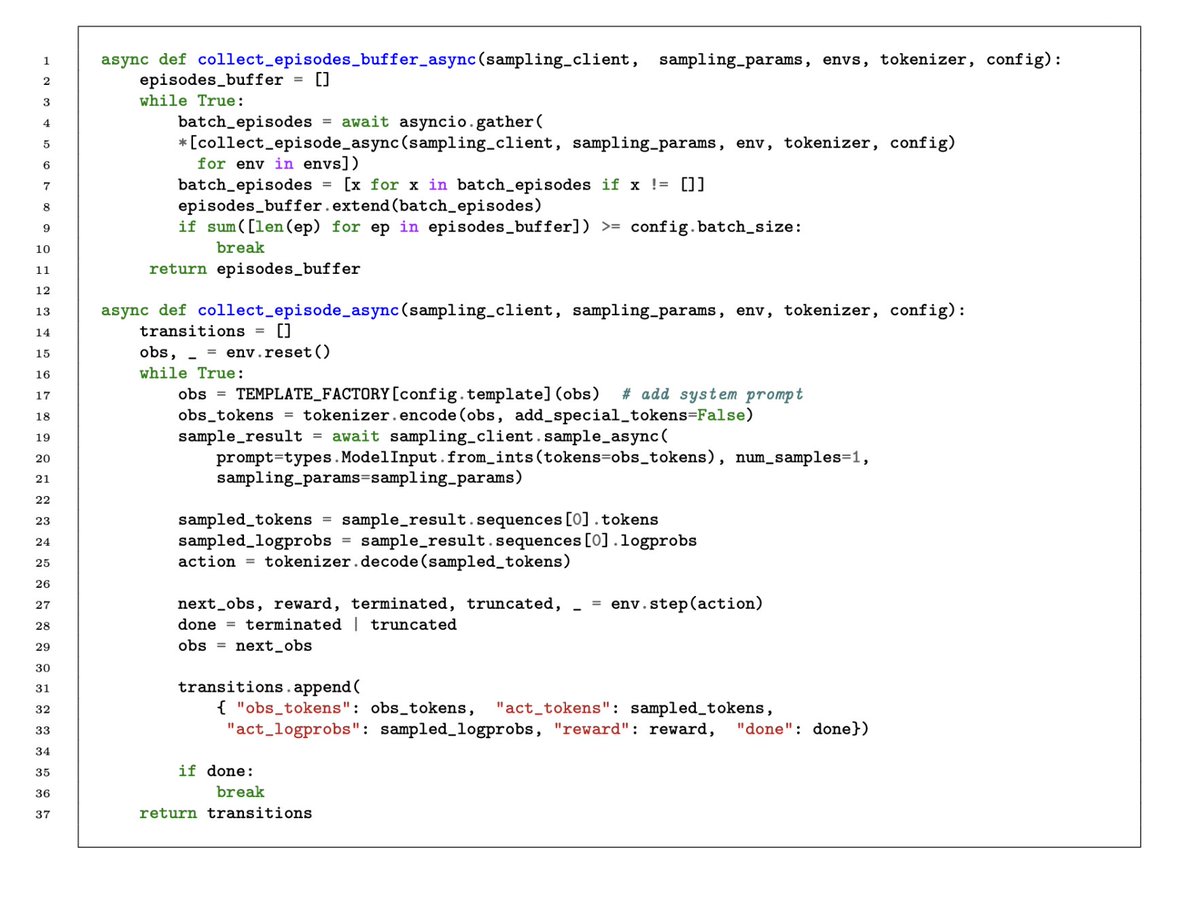
I am pleased to announce another update to my RL tutorial (arxiv.org/abs/2412.05265). This time I have added code for RLFT for multi-turn LLM agents, using the awesome Tinker library from @thinkymachines, and the simple ReBN training loop from GEM by @zzlccc et al. With ~100 lines of simple python running on your laptop, you can train an agent based on Qwen3-4B-Instruct to play "guess the number" in 20 minutes.

14
148
1,134
88,109
Xinya Du retweeted

29 Oct 2025
Today we’re announcing research and teaching grants for Tinker: credits for scholars and students to fine-tune and experiment with open-weight LLMs.
Read more and apply at: thinkingmachines.ai/blog/tin…
19
126
1,003
504,193
Xinya Du retweeted

17 Oct 2025
The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
535
2,905
18,583
10,746,907