
84 Photos and videos









Pinned Tweet

21 Mar 2025
🪂Understanding R1-Zero-Like Training: A Critical Perspective
* DeepSeek-V3-Base already exhibits "Aha moment" before RL-tuning??
* The ever-increasing output length in RL-tuning might be due to a BIAS in GRPO??
* Getting GRPO Done Right, we achieve a 7B AIME sota!
🧵
📜Full details: github.com/sail-sg/understan…
🛠️Code: github.com/sail-sg/understan…

29
186
1,369
330,759
Zichen Liu retweeted

Jun 9
Our latest deliveries:
👨💻 UniRL, an RL infra for unified multimodal models
➕ Two new RL algorithms:
• FlowDPPO for diffusion and flow-matching models
• DRPO for LLMs and VLMs
Check out our repo: github.com/Tencent-Hunyuan/U…
Jun 9

🚀Introducing UniRL, an RL infra for unified multimodal models. Together with two new RL algorithms: DRPO and Flow-DPPO.
One RL loop across diffusion/flow matching models, LLMs/VLMs, and unified multimodal models👇
Code: github.com/Tencent-Hunyuan/U…
(yes — U(you)-ni-(need) RL 😉)

4
27
146
16,807
Zichen Liu retweeted

Jun 9
We propose DRPO: a soft version of DPPO🔥
Since PPO, clipping/mask-based trust regions have long outperformed smooth divergence regularization like KL, even though the latter one feels more principled. 👺
We found two missing pieces:👇
1️⃣ Weight the regularizer by |advantage|
- Otherwise, the trust region geometry changes dynamically and optimization becomes unstable.
2️⃣ Use the right divergence
- What matters is not just “regularization”, but the trust-region geometry induced by the gradient. DPPO-style geometry works much better than PPO-style geometry in LLM.
These insights lead to DRPO, which delivers the most robust and best overall performance across algorithms, even outperforming original mask-based DPPO. 🚀
This project is an amazing collaboration with @ExplainMiracles, @NickZhou523786, Wee Sun Lee, Liefeng Bo, @TianyuPang1 . Do follow them if you are interested in this work!
📄 Paper: arxiv.org/pdf/2606.09821
💻 Code: github.com/Tencent-Hunyuan/U…


3
27
152
10,790
Zichen Liu retweeted

May 28
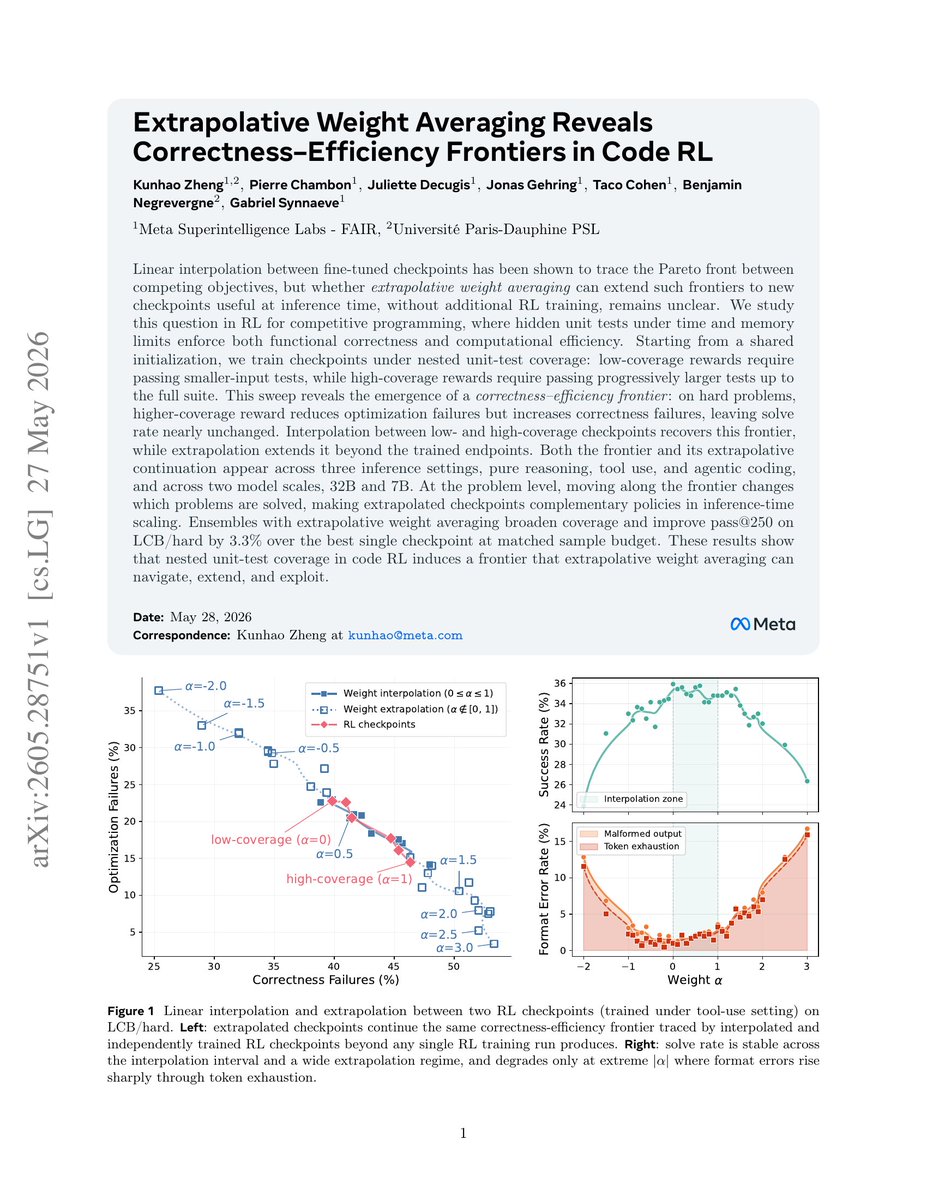
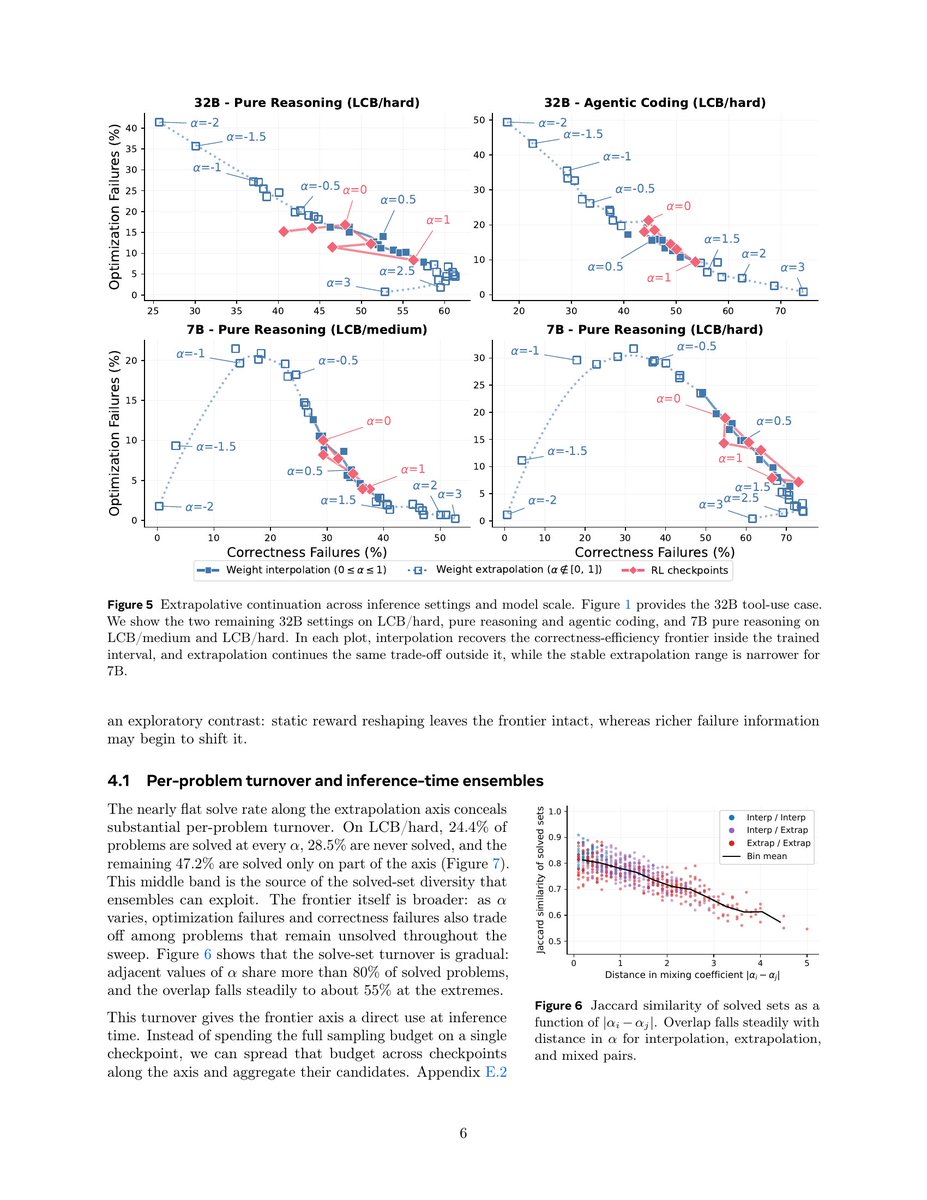
🧵 For 2 RL checkpoints trained differently, you can just weight extrapolate them and it works!
Bonus: these extrapolated checkpoints are complementary policies
-> Get exploration and diversity for free
-> Better inference scaling when ensembling
Paper: arxiv.org/abs/2605.28751
May 28

arxiv.org/abs/2605.28751
Now many studies try to do extrapolation through model merging. arxiv.org/abs/2605.26484
3
30
123
13,582
Zichen Liu retweeted

May 19
Today at Google I/O, we introduced Gemini 3.5 Flash! It has become an integral part of our daily research cycle and works with all the tools we have at Google.
We used a team of agents in Antigravity 2.0 to recreate the original AlphaZero research paper and build a playable version. They coded the reinforcement learning pipeline in JAX/Flax, trained a ResNet model from scratch via self-play on multi-TPU pods, and shipped a full-stack web app so you can play against it, from just 2 prompts. .
Here’s what else makes 3.5 Flash special 🧵
116
74
564
95,050
Apr 10
rl intuition (up-scaled by the correctness of infra) is all you need when cooking with a strong base model such as gemini✨
3
1
71
5,122
Zichen Liu retweeted

Apr 4
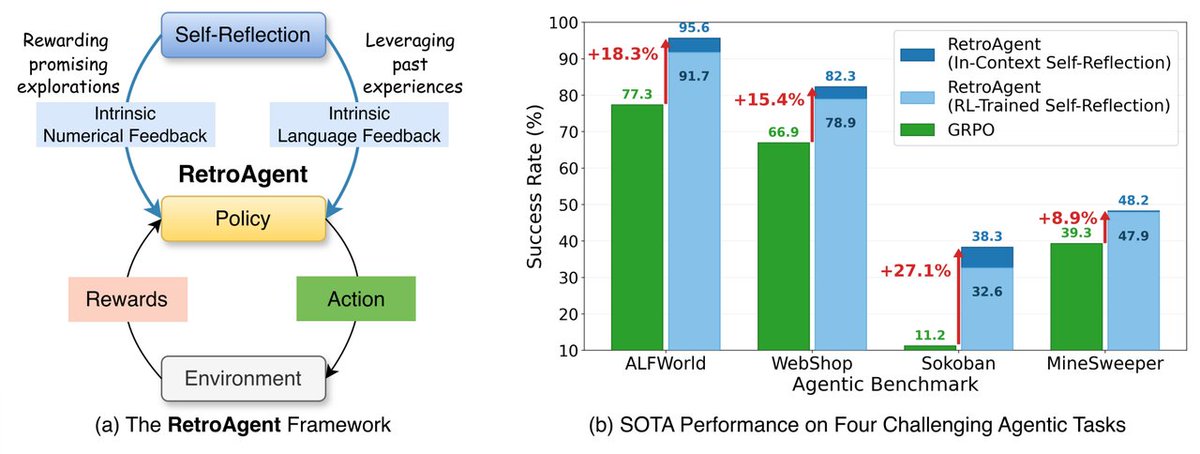
🚀 Excited to share RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback! Instead of training LLM agents just to solve isolated tasks, we designed them to continuously evolve.
By using retrospective dual intrinsic feedback (Numerical for exploration Language for explicit memory) & SimUtil-UCB retrieval, we achieve massive SOTA gains over GRPO baselines:
🔥 18.3% on ALFWorld
🛒 15.4% on WebShop
📦 27.1% on Sokoban
💣 8.9% on MineSweeper
Strong test-time adaptation & OOD generalization included! 🧠👇 📄 Paper: arxiv.org/abs/2603.08561💻 Code: github.com/zhangxy-2019/Retr…
1
1
7
1,187
Zichen Liu retweeted

Mar 17
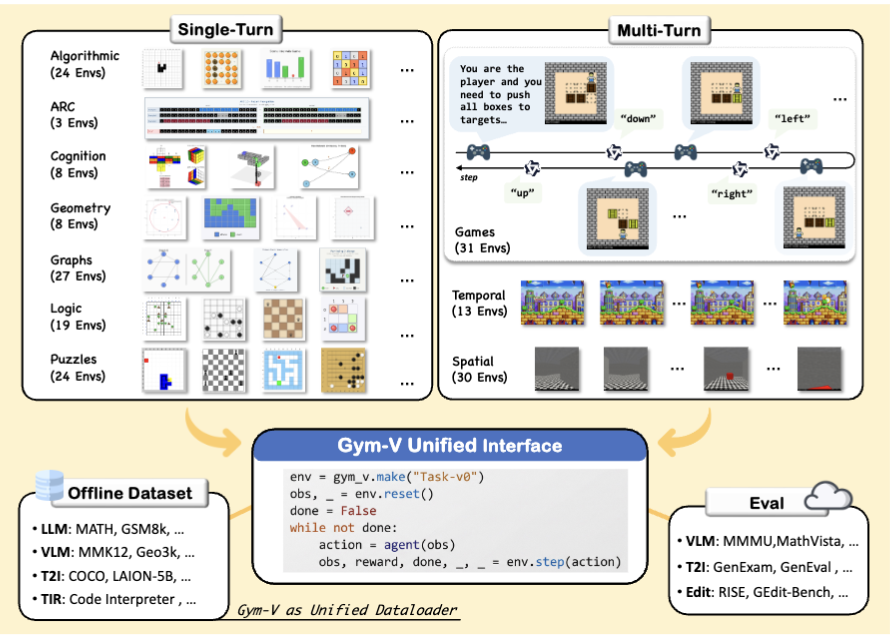
Text agents have their Gym. Vision agents? Not until now.
Introducing Gym-V — a unified gym-style platform for agentic vision research, with 179 procedurally generated environments across 10 domains.
One API to rule them all:
📦 Offline dataset
🤖 Agentic RL training
🔧 Tool-use training
👥 Multi-agent training
📊 VLM & T2I model evaluation
All under the same reset/step interface.
Key findings:
1. Observation scaffolding matters MORE than RL algorithm choice
2. Broad curricula transfer well; narrow training causes negative transfer
3. Multi-turn interaction amplifies everything
📄 Paper: arxiv.org/abs/2603.15432
💻 Code: github.com/ModalMinds/gym-v
Open the thread for a deep dive! 🧵
8
17
109
9,937
Mar 17
🦎🦎 Happy to see two of our works (DrGRPO & DPPO) are highlighted here!
I don’t think changing a few terms is worth a new branding, so we respectfully kept predecessors’ name while highlighting the correction/improvement on top of them.
Hopefully they inspire RL algo designs.
Mar 15

Finally finished!
If you're interested in an overview of recent methods in reinforcement learning for reasoning LLMs, check out this blog post: aweers.de/blog/2026/rl-for-l…
It summarizes ten methods, tries to highlight differences and trends, and has a collection of open problems
ALT Blog post on the current state of reinforcement learning for reasoning LLMs
2
4
42
4,108
Mar 11
Huge congrats to Min!

The most exciting breakthroughs in intelligence are yet to come. I’m super excited to start this journey with mes amis to make them happen together.
14
3,691
Zichen Liu retweeted

Mar 9
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

960
2,125
19,522
3,660,050
Zichen Liu retweeted

Mar 4
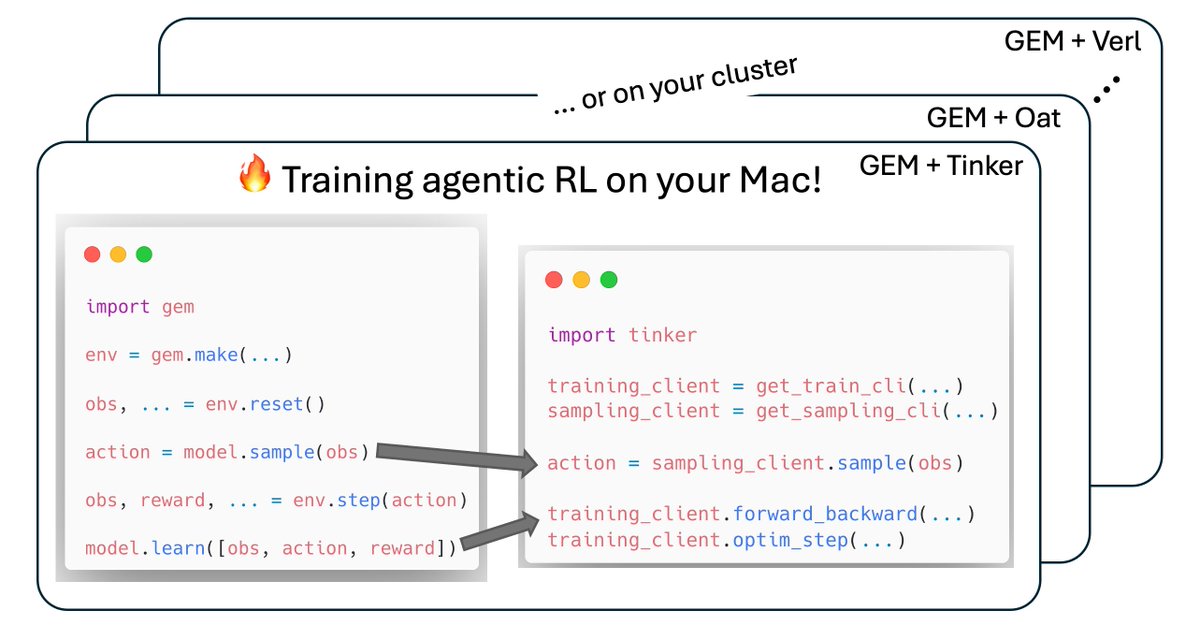
GEM is a standardized environment suite for training agentic LLMs with RL. It handles tool use, multi-environment benchmarking, and plugs directly into Tinker as a training backend — giving researchers a modular way to test RL algorithms on agentic tasks.
x.com/zzlccc/status/19752422…
6 Oct 2025

GEM❤️Tinker
GEM, an environment suite with a unified interface, works perfectly with Tinker, the API by @thinkymachines that handles the heavy lifting of distributed training.
In our latest release of GEM, we
1. supported Tinker and 5 more RL training frameworks
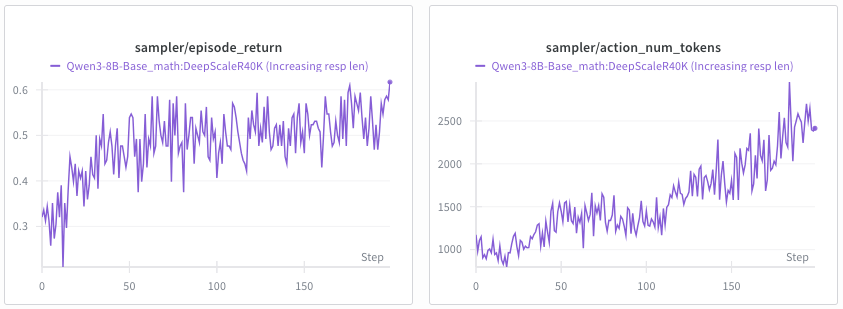
2. reproduced deepseek-r1 length increasing with LoRA
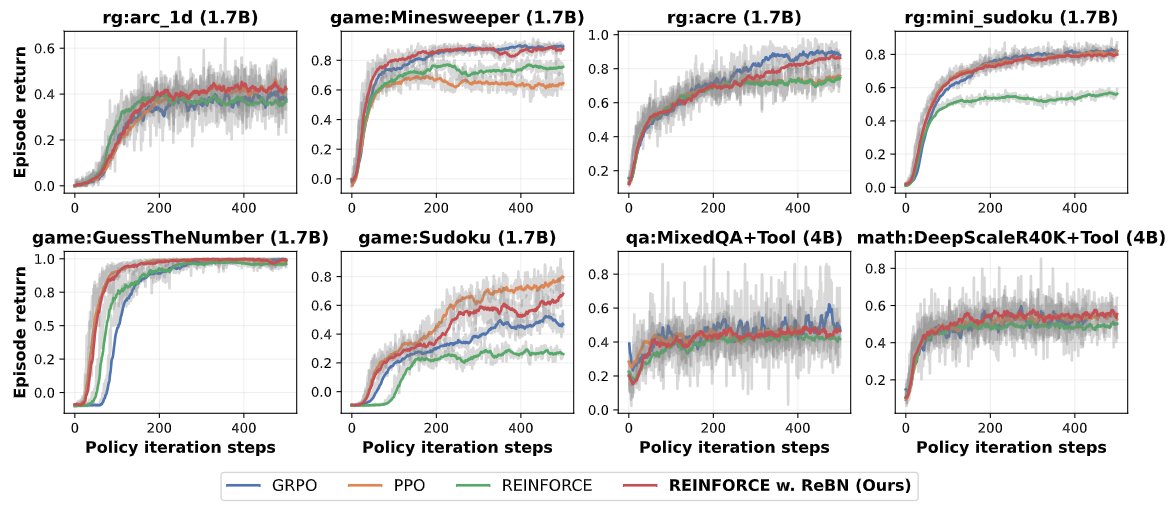
3. benchmarked PPO, GRPO, REINFORCE and showed their tradeoffs
4. added Terminal, MCP, visual and multi-agent environments
…
Open the thread for a deep dive!
9
42
4,460
Zichen Liu retweeted
Mar 3
Gemini 3.1 Flash-Lite is available now! It takes an unbelievable amount of complex engineering to make AI feel instantaneous, enabling exciting new frontiers for experimentation!
19
41
281
188,973
Mar 2
Welcome @NiJinjie !

Life update: I’ve joined @GoogleDeepMind as a research scientist to work on ✨gemini scaling and RL, under the leadership of Yi Tay (@YiTayML) and Quoc Le (@quocleix).
I feel extremely fortunate to be on the critical path towards AGI and can't wait to help push the frontier of gemini capabilities! 🚀

1
31
4,458

Congrats and welcome @NiJinjie to the center of AGI (🇸🇬 branch). Taking highly technical and capable researchers like this and giving them a chance to be at the frontier to make tons of impact for Gemini has been one of the most rewarding things of founding & building GDM in SG.
Life update: I’ve joined @GoogleDeepMind as a research scientist to work on ✨gemini scaling and RL, under the leadership of Yi Tay (@YiTayML) and Quoc Le (@quocleix).
I feel extremely fortunate to be on the critical path towards AGI and can't wait to help push the frontier of gemini capabilities! 🚀
5
9
121
18,899
Zichen Liu retweeted

Feb 19
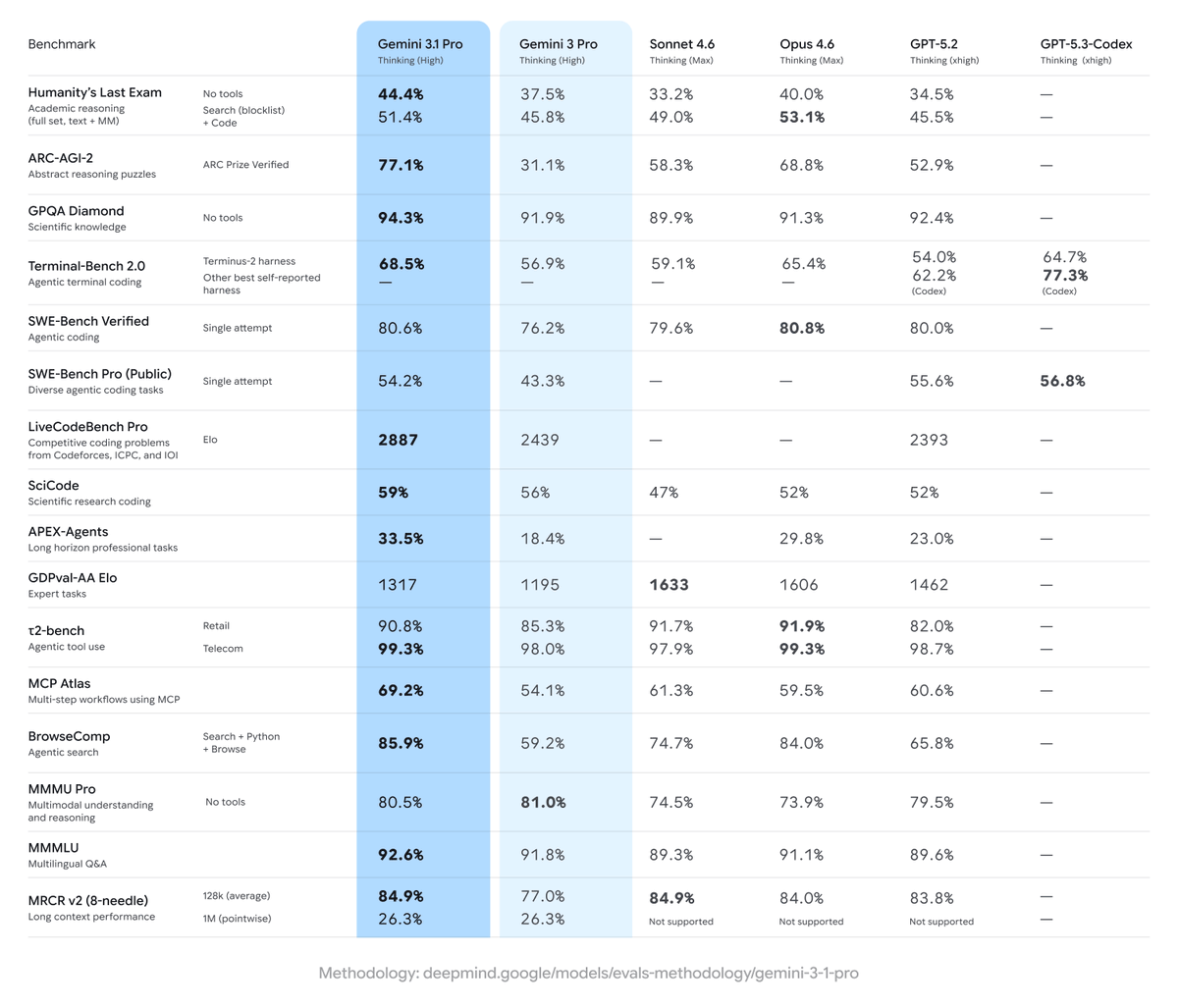
"And, what's next?"
New Gemini 3.1 pro is here
blog.google/innovation-and-a…
Gemini is not only a good model, but better models coming in an unstopable way.
13
8
112
12,658
Zichen Liu retweeted

Feb 19
David Silver's new $4bn company, Ineffable Intelligence, will fulfil the promise of the Era of Experience. youtube.com/watch?v=zzXyPGEt…
ft.com/content/dffe72d0-4064…
24
78
725
61,955
Zichen Liu retweeted

Feb 15
Understanding R1-Zero-Like Training: A Critical Perspective
From Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin, across Sea AI Lab, National University of Singapore, and Singapore Management University.
Problem: R1-Zero-style RL looks magical, but what is actually doing the work?
They take DeepSeek-R1-Zero as the spark, then dissect two core ingredients: the base model and the RL algorithm. The goal is to separate true RL-driven gains from artifacts caused by pretraining quirks, prompt templates, or biased optimization.
Approach: stress-test base models, templates, and RL dynamics
They probe multiple base models (including DeepSeek-V3-Base and Qwen2.5 families) and show templates can be the difference between “answering questions” versus “completing text.” One surprising observation is that Qwen2.5 can look unusually chat-like even without templates, which they argue may reflect pretraining bias.
RL finding: GRPO has a built-in length and difficulty bias
This is the part I enjoyed most because it is pure RL hygiene applied to LLM post-training. They show GRPO’s objective includes response-length normalization and per-question std normalization, which can systematically push incorrect answers to get longer and overweight “too easy/too hard” questions.
Fix: Dr. GRPO removes the bias and improves token efficiency
Their solution is intentionally simple: remove the length and std normalization terms, so the optimization matches the unbiased policy-gradient form more closely. The result is better token efficiency while keeping reasoning performance, and they show this in training dynamics and evaluation comparisons.
Why I recommend it
I recommend this as an RL-for-LLMs “reality check” paper. It made me appreciate RLHF and RLVR even more because it highlights the real job: define the right objective, avoid accidental biases, and measure what changes. It is a reminder that “emergence” can be partly optimizer math, and fixing that is part of doing RL right.

4
24
107
12,298
Zichen Liu retweeted
Feb 10
Sad for losing a fantastic daily collaborator in Sea AI Lab, but happy for Zichen for his new journey.
Thank you for everything, and wish you all the best on your next adventure! 🚀✨
Feb 9
Thrilled to share that I’ve joined @GoogleDeepMind to work on Gemini post-training!
I feel incredibly fortunate to be cooking on this sunny island under @YiTayML's leadership, within @quocleix's broader organization. Looking forward to enjoying RL research and pushing the frontiers of Gemini alongside such a brilliant team!
2
1
20
2,714
Something very special is happening on this island. We're building AGI, the first frontier lab in Asia/SG, and also gathering the best people around in one team. Welcome @zzlccc to join the AGI enjoyers club!
Looking forward to cooking with you!
Feb 9
Thrilled to share that I’ve joined @GoogleDeepMind to work on Gemini post-training!
I feel incredibly fortunate to be cooking on this sunny island under @YiTayML's leadership, within @quocleix's broader organization. Looking forward to enjoying RL research and pushing the frontiers of Gemini alongside such a brilliant team!
8
11
177
28,529