
Product, engineering and cookies
Joined October 2012
- Tweets 10,619
- Following 960
- Followers 696
- Likes 25,835
692 Photos and videos











You can read more on the README file here
github.com/divyashivaram/age…
187
New training pipeline: verify if data was generated by an American citizen before using them to train an LLM.
Oh wait
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
22
Divya retweeted

Jun 10
I miss Succession so much I choose to pretend every movie with Jeremy Strong is just Kendall’s newest business venture
Jun 10

Jeremy Strong's voice as Mark Zuckerberg in ‘THE SOCIAL NETWORK’ sequel.
“I’m not 2 years out of a dorm room anymore Charlie!”
84
3,238
32,671
1,172,713
Divya retweeted

Jun 11
youtu.be/nkEgT7YvTaM?si=ufpK…
This scene especially 👆
if you've got kids in high school or college, make sure they watch Naruto. It teaches you stuff about teamwork, friendship, kindness and a strong will from it far more than any teacher or class ever could.

Jun 9

which anime changed the way you think ???
1
4
316





We now have an Instagram page. Follow along my to cheer me on this latest obsession 🍪
instagram.com/ikuzo.blr

New project coming up! I’m going to start selling cookies over the weekend in Bangalore. Still testing different textures.
Will share more details once my Instagram page and beta testing form goes live 🍪
Audio on 😋
2
3
565
Divya retweeted

May 31
Dear Vibe Coders:
Orange is the new purple
11
1
18
3,197
Divya retweeted

Jun 2
I launched early access for mooze.ai/
for vibe coders, first-time builders, and founders with no-technical background who want to build a small app that can make money - but get stuck at idea, scope, or execution.
I will personally help you ship your first app
1
2
4
87
Divya retweeted

52
179
1,950
101,025
Divya retweeted

Jun 1
जेबकतरों से सावधान - आज वो CBSE के अंदर बैठे हैं। CBSE की गलती से नंबर ग़लत आए तो आपको क्या मिलता है?
एक bill:
Digital scan copy: ₹100/विषय
Re-totalling: ₹100/paper
Re-evaluation: ₹25/सवाल
अपनी ही answer sheet की सही जाँच के लिए एक बच्चे को ₹2000 तक भरने पड़ सकते हैं।
सोचिए, जब 4 लाख बच्चों ने ऐसे आवेदन डालें हैं तो CBSE कितनी कमाई कर रहा है।
जब scanning फ़ोन से हुई हो, ग़लत मार्किंग तय है। और उसे ठीक करवाने की क़ीमत बच्चा भर रहा है।
गलती CBSE की। सज़ा बच्चे की। कमाई सरकार की।
जब शिक्षा को सेवा नहीं, कारोबार बना दिया जाए तब गलती सुधारी नहीं जाती। बढ़ाई जाती है। और इसकी सबसे बड़ी क़ीमत हमारे बच्चे चुका रहे हैं - अपने समय से, अपने आत्मविश्वास से, और अपने भविष्य से।
977
11,591
32,251
461,512
Divya retweeted

May 31
I hope parents of young kids like these students are watching. I hope they see and comprehend the kind of world they have helped create. They have actively contributed to.
I hope they remember the times they laughed when anyone questioning Modi and his government was called a terrorist, a Pakistani. I hope they remember the times they were silent or participated in the intimidation of someone in their RWA whatsapp group because they were Muslim. I hope they remember the time they dismissed the farmers' protest or the anti CAA/NRC protests as soros sponsored propaganda.
I hope they remember.
And feel shame. And culpability. And responsibility.
May 31

A revealing chat with my fellow “anti-national Soros agents.”
Vedant and his friends are brilliant, brave young Indians who asked CBSE and the Modi government simple questions - but got insults instead of answers.
They deserve a bright and secure future. We will make sure they get it.
16
441
1,447
24,409
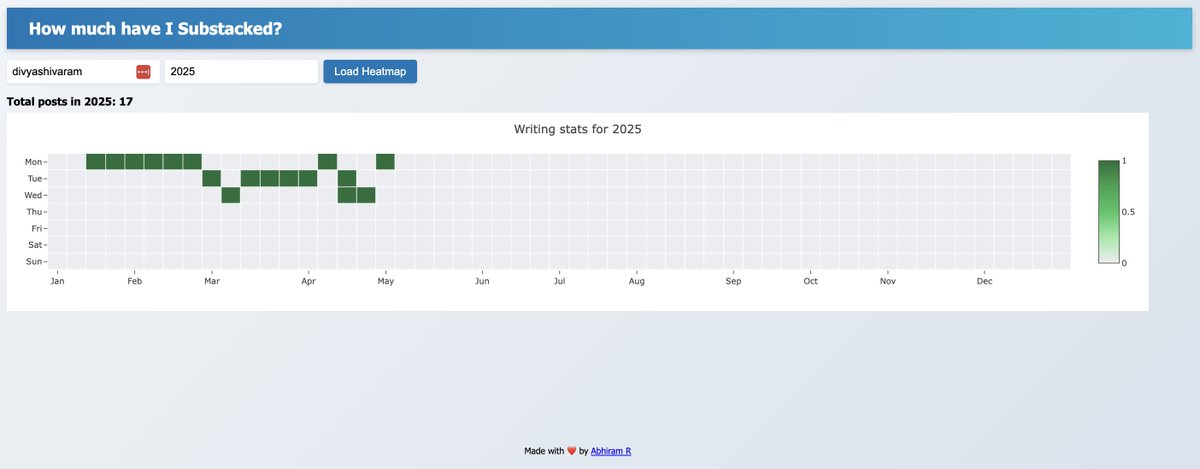
Yes! Just last week I did this for tracking my grocery orders on two platforms. Now I have an auto updating visualisation dashboard on category wise spends.
Apparently I spend ~50% on “non-essentials”
May 25

Reverse engineering APIs through network requests is one of the most fun things you can do with Claude Code to automate tasks..
SO many websites are impossible to navigate "deterministically" via the DOM (or through screenshots).
So, I just point Claude Code to use browser_harness by @browser_use (or vanilla playwright) and ask it to sniff network requests on the pages that I'm trying to get info on.
And, I just keep clicking around on the sections of data that I want. And, then Claude Code is generally able to go through the logs to figure out what is the right structure for these APIs and what kind of auth do they need (most are cookie based). We also determine what kind of rate limits exist based on trial and error.
I'm able to use that to construct jobs that allow me to get that data programmatically. There are many use cases for this besides scraping. I use this for random side projects (like the travel CLI), for monitoring websites (for intel), and for many many other use cases.
Every website will soon need to be headless, and we'll need to figure out mechanisms for how we have our agents pay these websites programmatically as well.
Just as we have llms.txt for data and structure, we'll soon need tools.txt for agents to determine what tools exist that can be leveraged.
38
Divya retweeted

May 21
If Rahul Gandhi did (even in his personal capacity) what Modi did with Meloni, you would have seen worst the septic tank of IT Cell would have to offer.
2
191
1,469
10,546
Divya retweeted

May 16
AI psychosis: cycling between two mental states every single day
↑ after using coding agents: holy shit I'm omnipotent. I can build anything. I've never felt this powerful in my life.
↓ after scrolling twitter: holy shit I'm completely behind. everyone's ahead. the wave is moving and I'm going to get left.
44
28
295
18,960
Divya retweeted

May 15
What sane individual feels comfortable giving this level of access to OpenAI (or any other company for that matter)
Seriously, very curious
43
10
837
67,805
Divya retweeted

May 14
Claude's first day at Dunder Mifflin
443
2,116
31,874
13,439,147
The “former” here is a personal attack. I want to report this tweet.
May 14

Claude Code is Farmville for 40 year old former software engineers
1
35