
neuroscience, computational models | Computational Brain Imaging Group | Huge fan of Metroidvania and Edward Hopper.
Joined May 2020
- Tweets 160
- Following 172
- Followers 219
- Likes 495
8 Photos and videos




Pinned Tweet

May 21
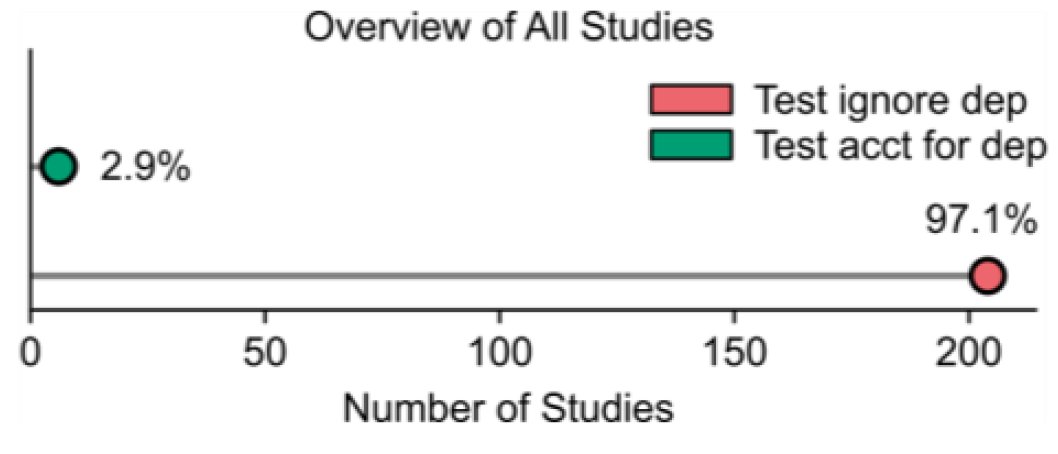
For years, we've known that running a standard t-test on cross-validation folds violates sample independence. We wanted to see how widespread this issue actually is.
The result? 97% of the studies used an invalid statistical test. 🧵👇
May 21

In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
1
5
12
3,462
Shaoshi Zhang retweeted
First time attending @OHBM @OHBM_Trainees !!
A bit different topic (proteomics🧬 for dementia) on OHBM, published in @NatureMedicine doi.org/10.1038/s41591-026-0…
Poster Number: #0573
Time: June 15, 13:45-14:45 & June 16, 12:30-13:30

8
17
2,141

Many thanks to all co-authors, collaborators, and reviewers for helping improve this work. Looking forward to discussing these findings at OHBM!
Paper is now out in @NatureComms
doi.org/10.1038/s41467-026-7…
If you are at @OHBM @OHBM_Trainees , come check out our poster about Simpson’s paradox in neurodevelopment.
Poster number 998
Monday, June 15 | 14:45-15:45
Tuesday, June 16 | 13:30-14:30
4
7
644
Shaoshi Zhang retweeted
Paper is now out in @NatureComms
doi.org/10.1038/s41467-026-7…
If you are at @OHBM @OHBM_Trainees , come check out our poster about Simpson’s paradox in neurodevelopment.
Poster number 998
Monday, June 15 | 14:45-15:45
Tuesday, June 16 | 13:30-14:30

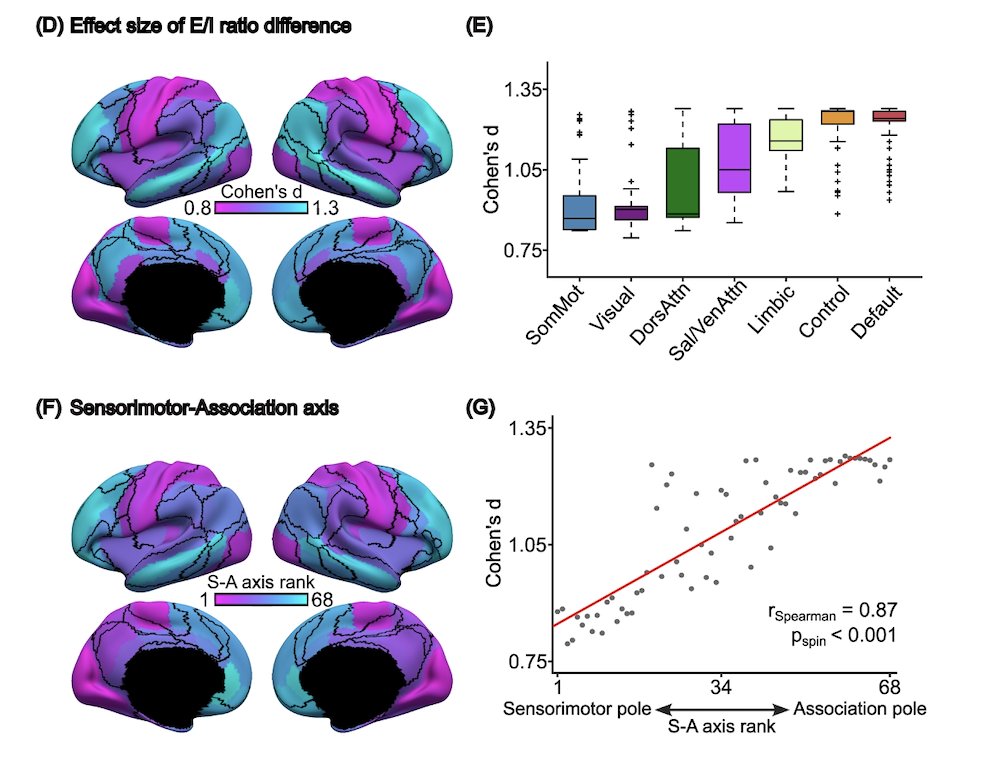
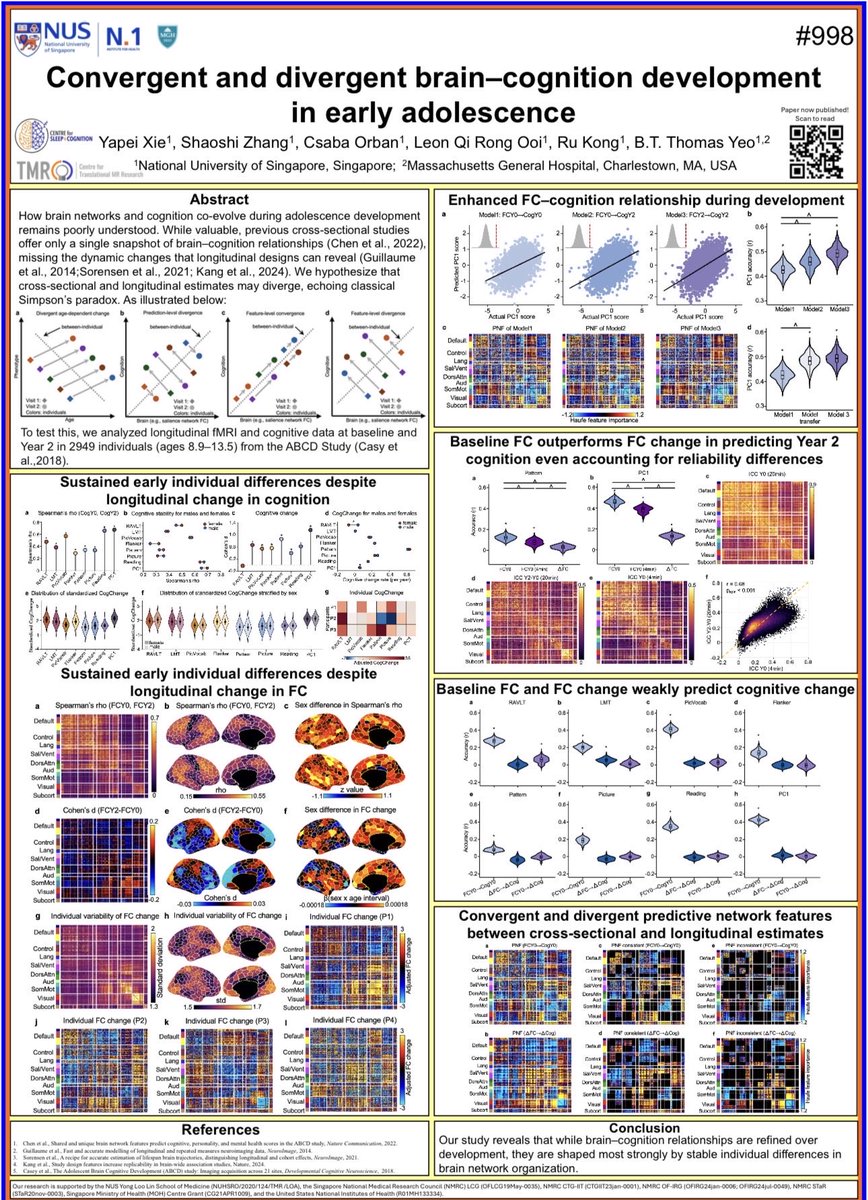
(1/10) How do brain networks and cognition co-evolve as children enter adolescence?
While valuable, cross-sectional studies offer only a single snapshot of brain–cognition relationships, missing the dynamic changes that longitudinal designs can reveal.
We hypothesize that cross-sectional and longitudinal estimates may diverge, echoing classical Simpson’s paradox.
As illustrated below:
To test this, we analyzed longitudinal fMRI and cognitive data at baseline and Year 2 in ~3,000 individuals (ages 8.9–13.5) from the ABCD Study, spanning the transition from childhood to adolescence.
[Read the full paper here: doi.org/10.1101/2025.06.06.6…]

1
16
28
4,905
Shaoshi Zhang retweeted
It was great fun giving the talk at the neuroimaging statistics workshop. Happy to share the slides here: dropbox.com/scl/fi/8riomlptb…
Hopefully, the talk is pitched at a level that is understandable to non-statisticians!
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
7
19
2,075
Shaoshi Zhang retweeted
For those going to @OHBM @OHBM_Trainees you can check out our poster on spectral normative modeling!
Poster Number: 1054
Monday, June 15, 14:45-15:45
Tuesday, June 16, 13:30-14:30
Our preprint has also been massively updated: doi.org/10.1101/2025.01.16.2…

6 Feb 2025

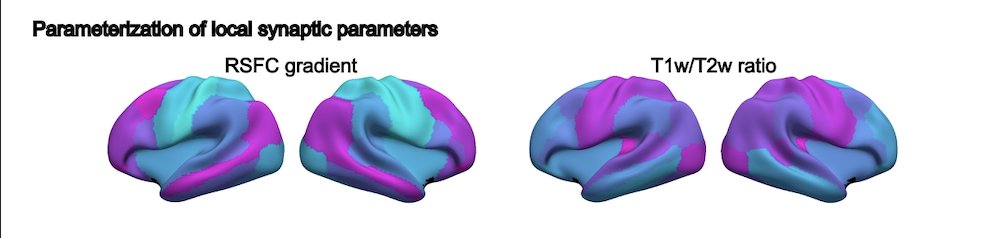
1/ Excited to share our latest preprint! 🚀 We introduce Spectral Normative Modeling (SNM)—a novel approach leveraging graph spectral methods to advance brain charting towards personalized precision medicine.
🔗medrxiv.org/content/10.1101/….
2
11
36
2,672
Shaoshi Zhang retweeted
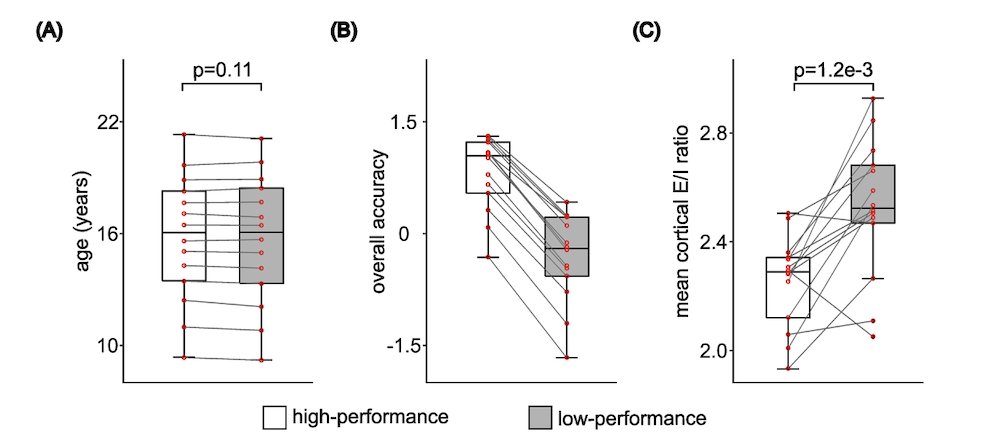
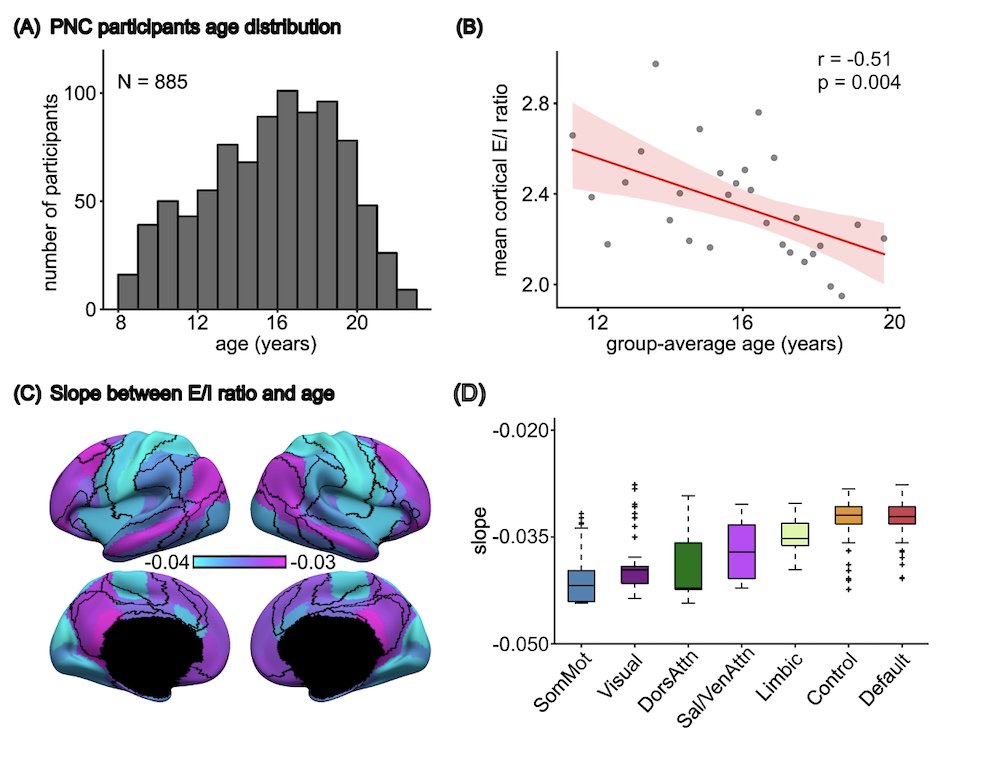
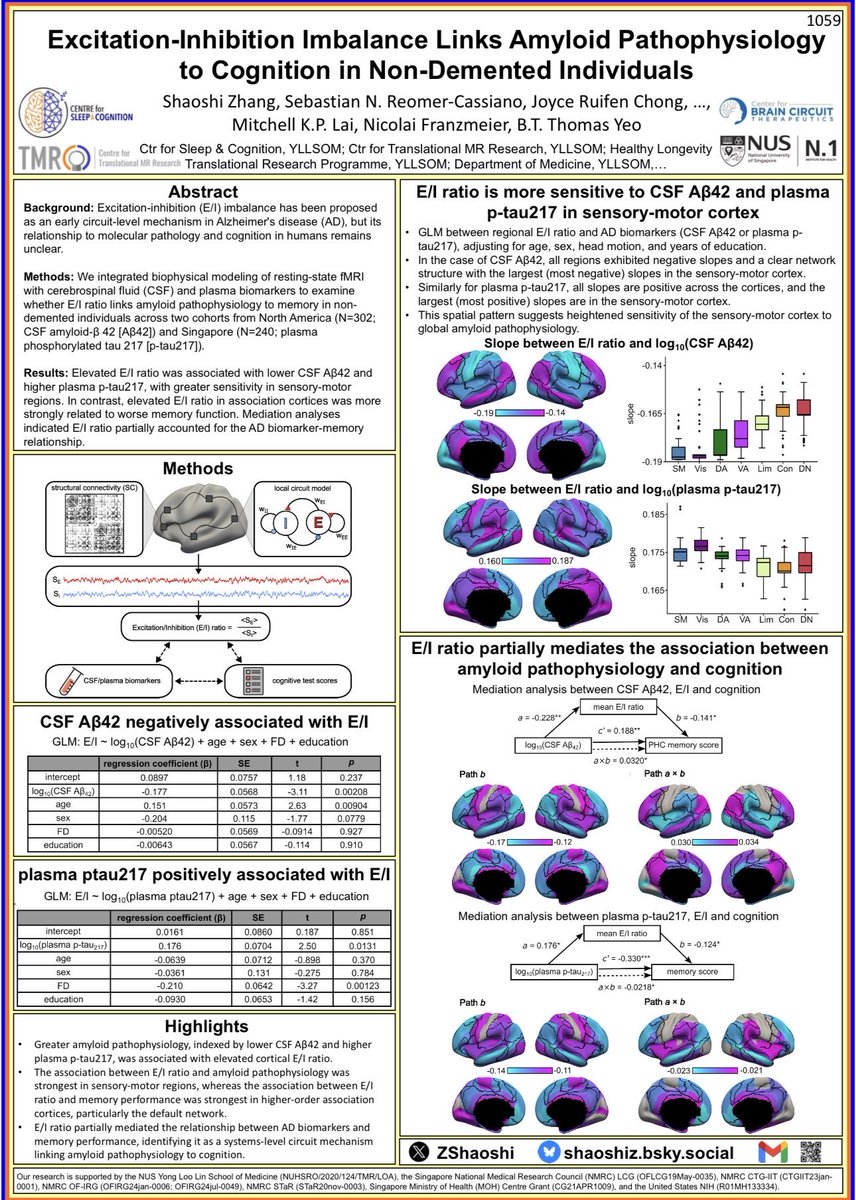
For those attending @OHBM @OHBM_Trainees come check out our poster on E/I imbalance in pre-dementia individuals and the relationships with blood/CSF biomarkers.
Poster 1059
Stand-by time:
Monday, June 15 | 13:45-14:45 & Tuesday, June 16 | 12:30-13:30
9
18
686
Shaoshi Zhang retweeted

Jun 10
I’ve officially resigned as Associate Editor for Frontiers in Systems Neuroscience (part of @FrontNeurosci). It used to be a reputable journal, but became a case study in how forced automation destroys academic integrity. 👇
33
243
1,072
195,538
Shaoshi Zhang retweeted

May 28
The p-tau217 breakthrough blood test replicated again, predicting Alzheimer's disease in a large cohort mean age 61. The cover of the new issue is telling @TheLancet thelancet.com/journals/lance…

19
270
884
88,330
Shaoshi Zhang retweeted

May 22
This looks like a straightforward, highly applicable solution to the long-standing problem of valid inference for K-fold CV performance differences. The trade-off is smaller training sets from the split-half step and having to rerun K-fold CV many times.
May 21
So we propose SHARP, which involves repeated split-half to generate pairs of independent statistics. There are still 3 unknowns — mean, variance, between-repetition correlation — but the independent pairs provide a 3rd information source to estimate all 3 unknowns. 7/N

2
6
33
3,736
Shaoshi Zhang retweeted

New paper in Imaging Neuroscience by Ru Kong, B.T. Thomas Yeo, et al:
Network-based near-scalp personalized brain stimulation targets
doi.org/10.1162/IMAG.a.1222

6
16
1,710
Shaoshi Zhang retweeted

May 22
Here's bonus slides on cross-validation tests, separate from our preprint. Covering:
1. paired (sign-flip) permutation test
2. label-swap permutation test
3. sample-level vs fold-averaged stats
4. a common misapplication of the corrected t-test
5. three bootstrap variants 1/N
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
1
25
46
7,693
Shaoshi Zhang retweeted

May 22
This is fantastic! I'm glad to have something to point people to in reviews beyond Demšar, 2006 (and Benavoli 2017 for the Bayesian perspective).
1
2
5
557
Shaoshi Zhang retweeted

May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
3
15
3,807
Shaoshi Zhang retweeted

May 21
Biomedical AI may be headed for a replication crisis.
(This work below is not about AI-generated reports; it’s about studies of biomedicine that use ML in their methods, and how they are evaluted.)
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
9
4
52
10,889
Shaoshi Zhang retweeted

May 21
Omg I've been commenting about this in manuscript reviews for years. Thank goodness there's actually a paper to cite now!! Thanks @bttyeo !
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
2
3
18
4,758
Shaoshi Zhang retweeted

May 21
Eye opener 👀
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
3
5
887
Shaoshi Zhang retweeted

May 21
Proud to participate in this study! We should keep rigorous in AI-Biomedical research, we also observe some concerning trends in AI biomarker studies…
Congratulations @tianchuzeng Tian Fang and @ZShaoshi
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
1
5
12
1,907
Shaoshi Zhang retweeted

Important work. Worth to take a look if you are doing AI in biomedical research.
May 21
In a meta-analysis of 210 biomedical AI studies that statistically compared models under cross-validation, 97% used invalid statistical tests.
Here's our new preprint doi.org/10.64898/2026.05.17.… led by @tianchuzeng @kkli20111 @ZShaoshi @ten_photos 1/N
5
17
2,190
Shaoshi Zhang retweeted
May 21
Once again, @ten_photos came to the rescue - we prayed to him for a better statistical test for k-shot learning (since the corrected t-test is overly conservative in that scenario), and he answered our prayers with a new test that also covers classical cross-validation.
May 21
So we propose SHARP, which involves repeated split-half to generate pairs of independent statistics. There are still 3 unknowns — mean, variance, between-repetition correlation — but the independent pairs provide a 3rd information source to estimate all 3 unknowns. 7/N
1
10
17
2,823