
38 Photos and videos




Pinned Tweet

30 Sep 2025
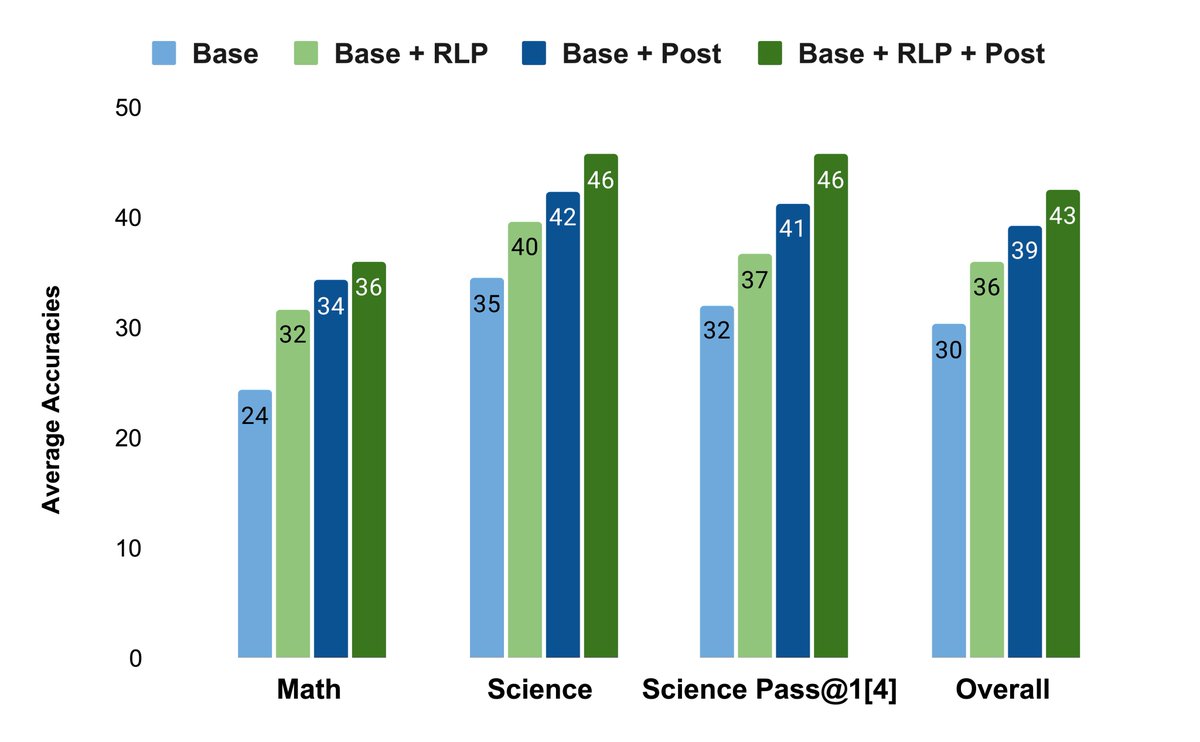
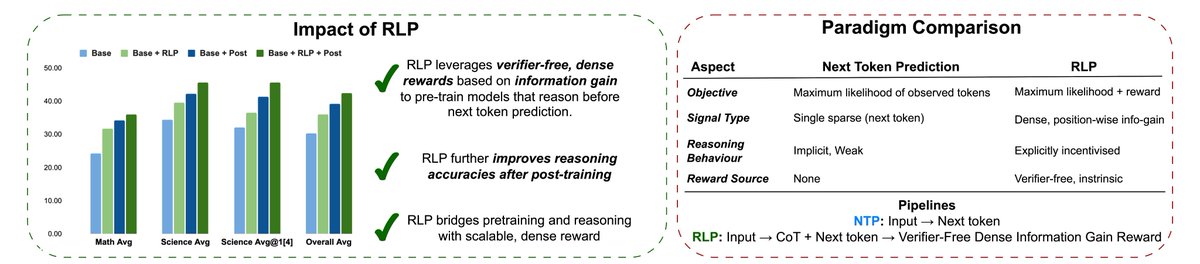
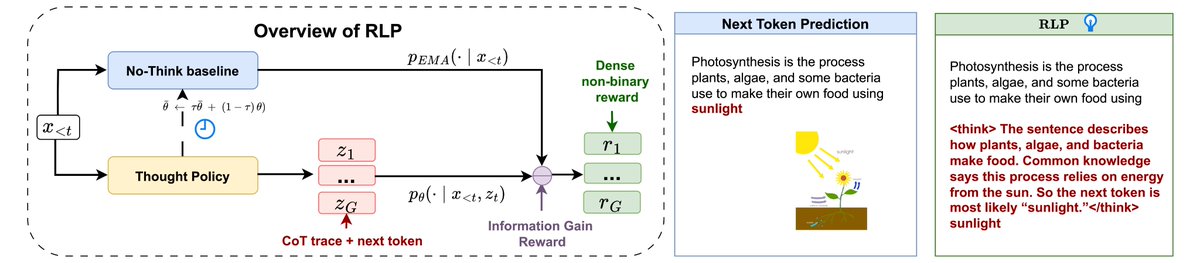
Most LLMs learn to think only after pretraining—via SFT or RL. But what if they could learn to think during it? 🤔
Introducing RLP: Reinforcement Learning Pre-training—a verifier-free objective that teaches models to “think before predicting.”
🔥 Result: Massive reasoning boosts & gains that COMPOUND after post-training!
📝 Blog: research.nvidia.com/labs/adl…
🔗Paper: github.com/NVlabs/RLP/blob/m…
🧵↓
8
40
255
20,314
Syeda Nahida Akter retweeted

Ever wished we had fewer X-training hyphenates? Pre, mid, post etc. Why not just Training?
Trying to bridge the divides (and get all our friends into one team again), we intro *Introspective X Training*, an offline RL inspired method that scales effectively across any LLM stage by annotating your data with a thinking reward generated language critique!
Up to 2.8x FLOP efficiency 5-10 point score gains (esp with math and code) at any stage from scratch to 24T tokens on 8b (active) sized models!! We burned much compute ablating so you wouldn't have to
Moral of the story is‼️don't throw out any data via filtering, just feedback condition it‼️
You can spend FLOPs up front on inference to *classify* data quality and then train so that tokens aren't all treated equally based on the feedback starting early in training itself. Right now they're really only separated out much later during mid/post training
This improves overall compute efficiency and gives us benchmark perf not possible with just baseline methods!
Paper here: arxiv.org/abs/2605.20285
Thanks to @BrandoCui and @GXiming for leading this w/ @__SyedaAkter @davidjesusacu @hyunw_kim @jaehunjung_com Yuxiao Qu @shrimai_ @YejinChoinka
2
20
113
26,011
Excited to present Nemotron-CrossThink @eaclmeeting 🇲🇦🚀
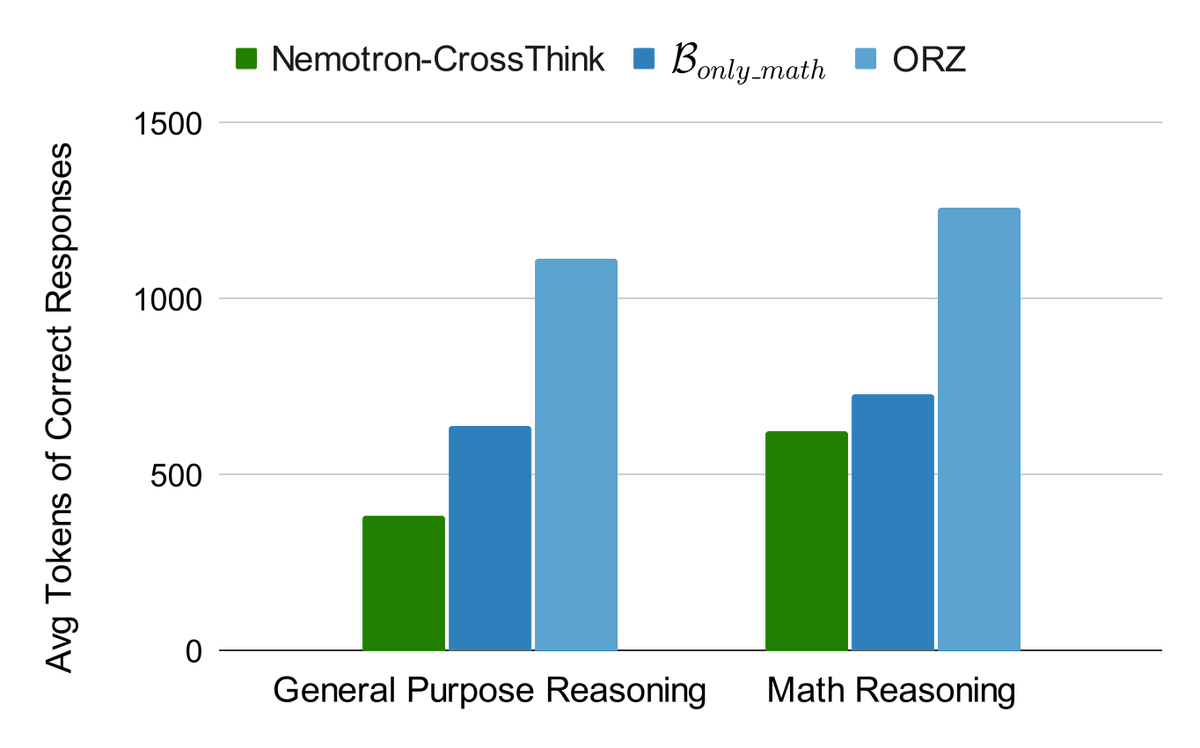
We extend RL beyond math while achieving accurate answers with significantly fewer tokens!
📍 Salle Le Riad 🗓 26 March | ⏰ 9:00–10:30 AM (Moroccan Time)
Session: Reasoning and Self-Learning in LLMs
1 May 2025

RL boosts LLM reasoning—but why stop at math & code? 🤔
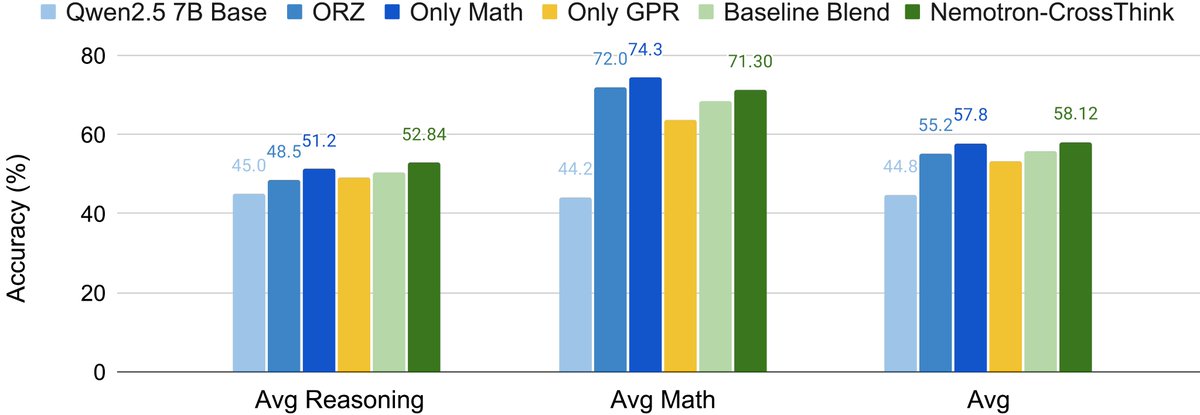
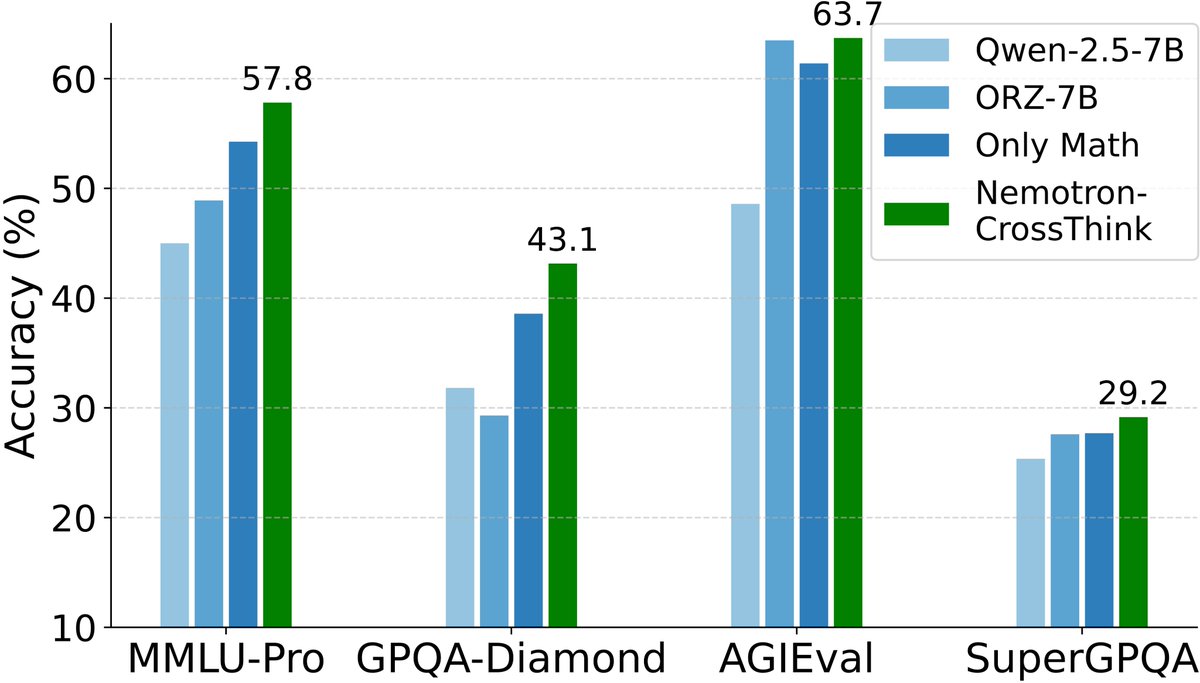
Meet Nemotron-CrossThink—a method to scale RL-based self-learning across law, physics, social science & more.
🔥Resulting in a model that reasons broadly, adapts dynamically, & uses 28% fewer tokens for correct answers!
🧵↓
5
292

Excited to share Nemotron-CrossThink @eaclmeeting 🚀
We move beyond math-only RL by bringing multi-domain reasoning into RL training with scalable, verifiable rewards.
Don't miss the oral presentation tomorrow at 9.00am in Salle Le Riad by @__SyedaAkter
Link: arxiv.org/pdf/2504.13941

1
14
646
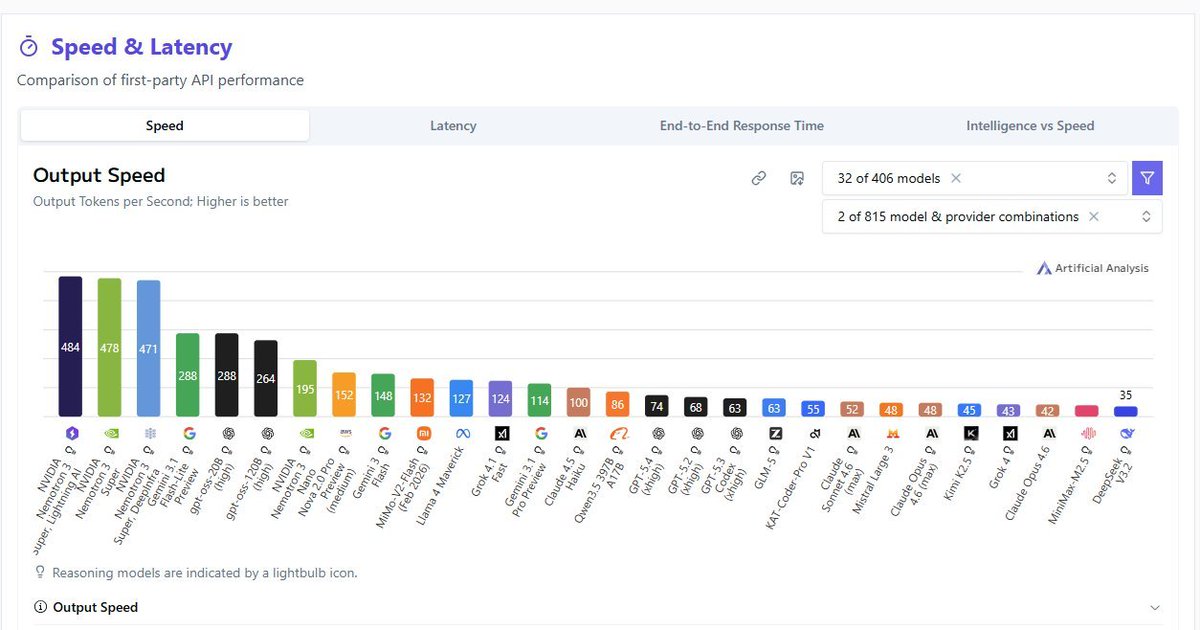
📢 Thrilled to see Nemotron-3 Super out in the world. 🚀
A hybrid MoE model with long-context support and strong reasoning capabilities — designed for scalable agentic AI systems and efficient inference.
🎉 Proud to be part of the team pushing forward open, efficient, and scalable AI systems. @NVIDIAAI @nvidia
2
2
37
1,313
Intelligent and Super Efficient!
Mar 11

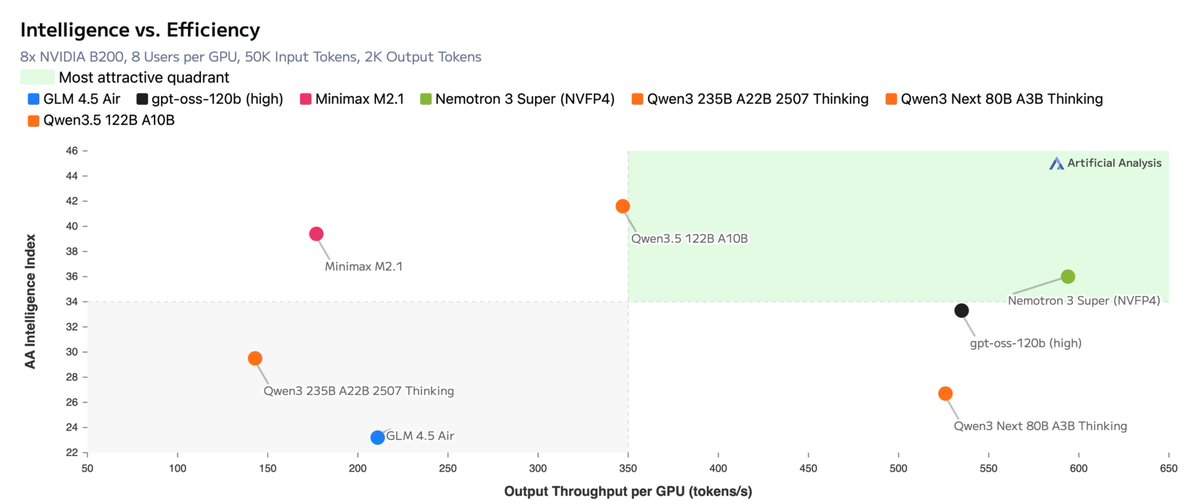
Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell
💚36 on AAIndex v4
💚up to 2.2X faster than GPT-OSS-120B in FP4
💚Open data, open recipe, open weights
Models, Tech report, etc. here:
research.nvidia.com/labs/nem…
And yes, Ultra is coming!
4
361
Thrilled to share that all three of our papers were accepted to @iclr_conf 🎉
1⃣RLP: Reinforcement as a Pretraining Objective
2⃣Front-Loading Reasoning: The Synergy between Pretraining & Post-Training Data
3⃣Nemotron-CC-Math: A 133B-token High-Quality Math Pretraining Dataset
Together, they explore how data, reasoning, and reinforcement during pretraining shape stronger LLMs.
3
10
80
13,344
2/2 at ICLR 2026! 🎊
So happy to share that both of our papers have made it to @iclr_conf!
1️⃣RLP: Reinforcement as a Pretraining Objective
(arxiv.org/abs/2510.01265)
2️⃣Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data (arxiv.org/pdf/2510.03264)
2
3
42
3,681
So grateful to all the collaborators who made these works possible 🙏
1️⃣ RLP: @ahatamiz1, @shrimai_, @jankautz, @MostofaPatwary, @MohammadShoeybi, @ctnzr, @YejinChoinka
2️⃣Front-Loading Reasoning: @shrimai_, Eric Nyberg, @MostofaPatwary, @MohammadShoeybi, @YejinChoinka, @ctnzr
4
166
RLP is ready for ICLR 2026! 🥳 We have added extensive ablations and new experimental results (thanks to the reviewers). Excited to share the final story soon!
Jan 26

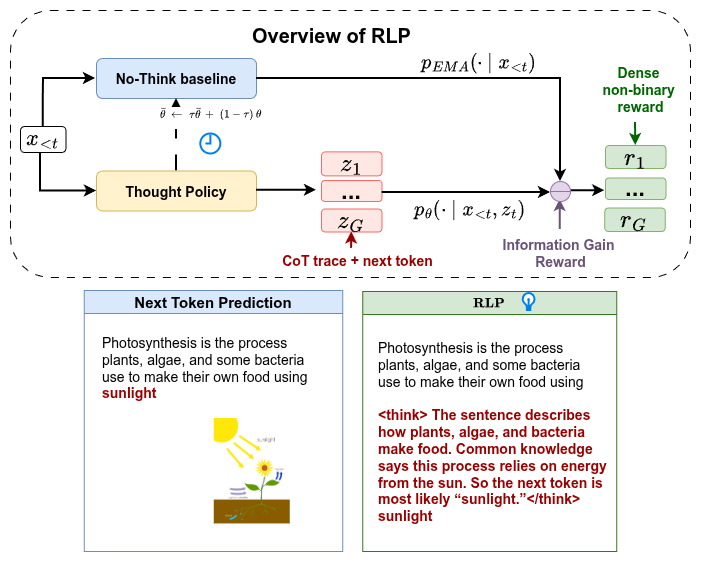
I am happy to announce that RLP has been accepted to ICLR 2026 ! 🎉
RLP re-imagines the foundations of LLM training by bringing reinforcement learning directly into the pretraining stage.
This was a true team effort, and it would not have been possible without the invaluable contributions of our amazing team:
@shrimai_ @__SyedaAkter @jankautz @MostofaPatwary @MohammadShoeybi @ctnzr @YejinChoinka
Paper: arxiv.org/abs/2510.01265
Code: github.com/NVlabs/RLP
7
39
3,971
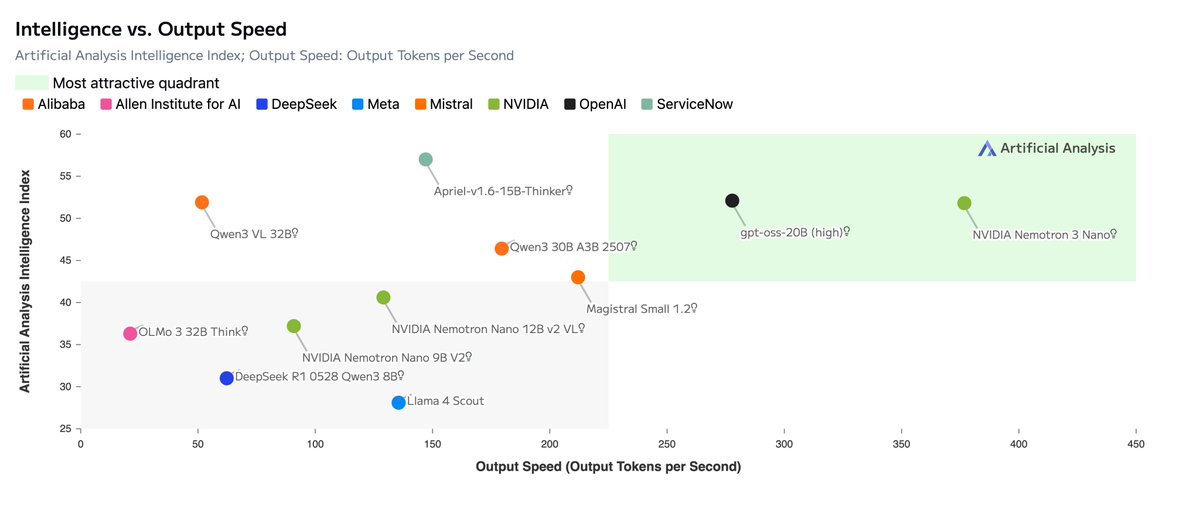
Excited to be part of the launch of @nvidia Nemotron 3 Nano (30B) 🚀 A hybrid MoE reasoning model with 1M context, SWE-Bench-leading performance, and 1.5–3.3× faster inference. Super and Ultra are coming in the next few months. Open, fast, frontier-level 🔥
1
3
33
2,054
Syeda Nahida Akter retweeted

15 Dec 2025
Today, @NVIDIA is launching the open Nemotron 3 model family, starting with Nano (30B-3A), which pushes the frontier of accuracy and inference efficiency with a novel hybrid SSM Mixture of Experts architecture. Super and Ultra are coming in the next few months.
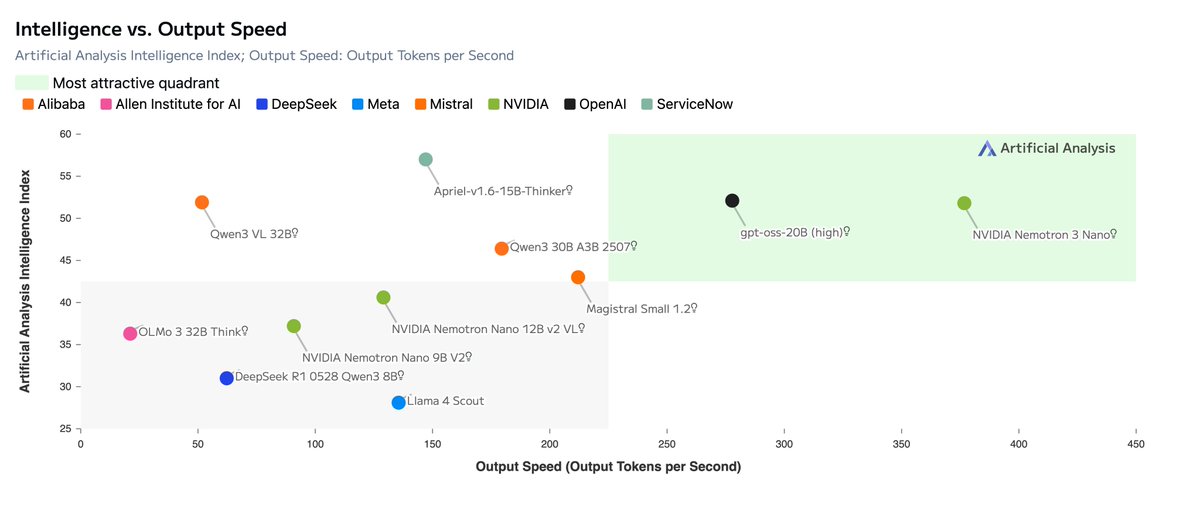
41
221
1,238
505,714
Syeda Nahida Akter retweeted

10 Oct 2025
Lot of insights in @YejinChoinka's talk on RL training. Rip for next token prediction training (NTP) and welcome to Reinforcement Learning Pretraining (RLP). #COLM2025
No place to even stand in the room.

7
22
290
77,479
Syeda Nahida Akter retweeted

10 Oct 2025
By teaching models to reason during foundational training, RLP aims to reduce logical errors and boost reliability for complex reasoning workflows.
venturebeat.com/ai/nvidia-re…
4
8
4,194
Thank you @rohanpaul_ai for highlighting our work!💫
Front-Loading Reasoning shows that inclusion of reasoning data in pretraining is beneficial, does not lead to overfitting after SFT, & has latent effect unlocked by SFT!
Paper: arxiv.org/abs/2510.03264
Blog: research.nvidia.com/labs/adl…
9 Oct 2025

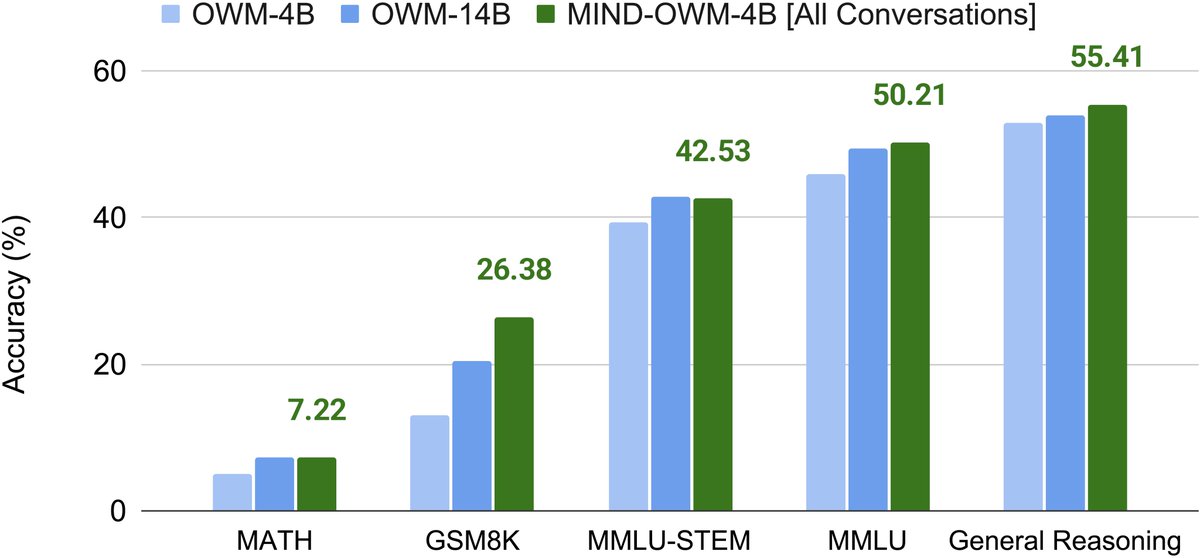
New @nvidia paper shows that teaching reasoning early during pretraining builds abilities that later fine-tuning cannot recover.
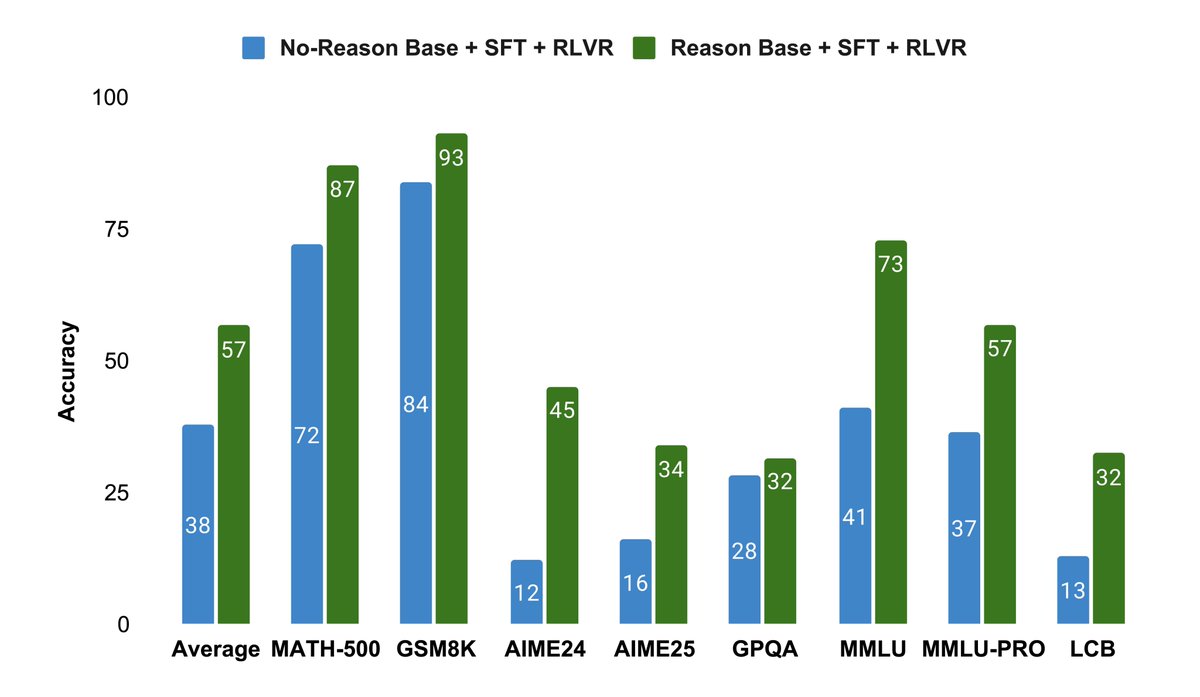
Doing this early gives a 19% average boost on tough tasks after all post-training.
Pretraining is the long first stage where the model learns to predict the next word from lots of text.
Supervised fine-tuning is a later stage where it studies step by step answers from labeled examples.
Reinforcement learning then rewards better answers so the model improves further.
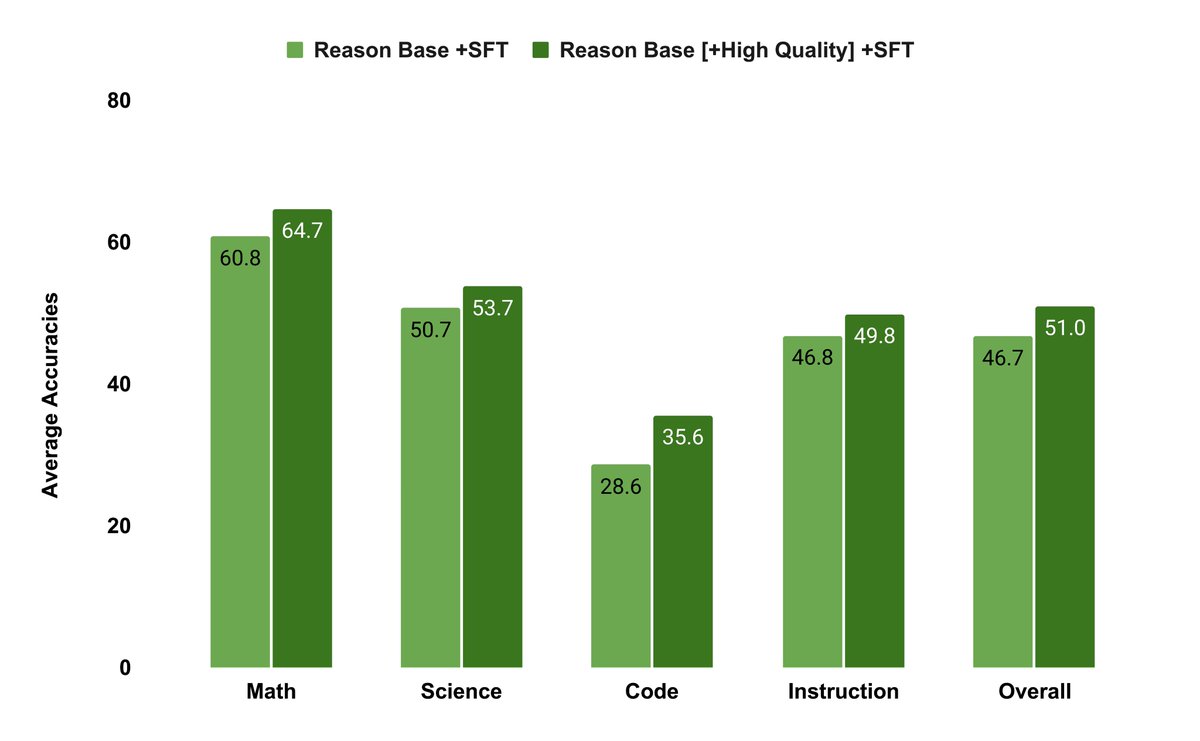
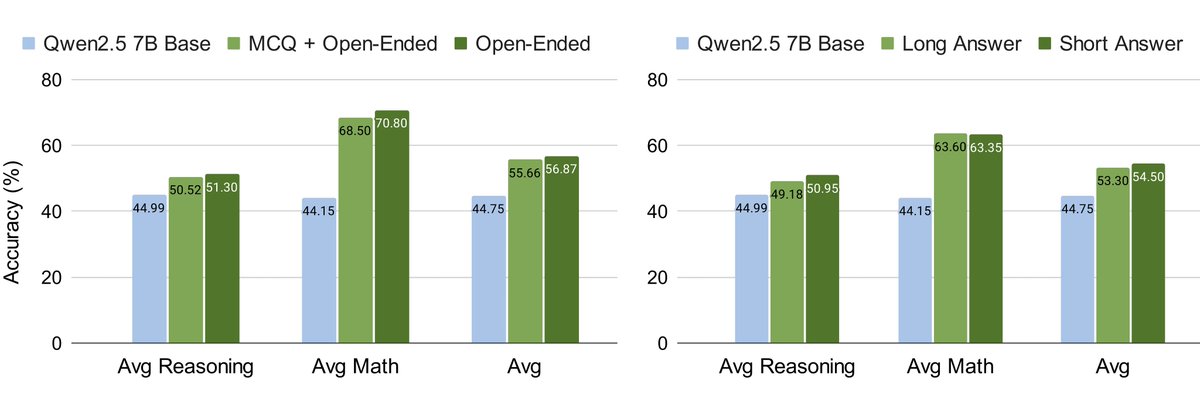
Diversity matters most in pretraining, while high quality matters most in supervised fine-tuning, roughly 11% vs 15% gains.
Even doubling supervised fine-tuning on a base that skipped early reasoning could not catch up.
Adding lots of mixed-quality supervised fine-tuning data even cut math by about 5%.
High quality reasoning added in pretraining looked small at first, then showed up strongly after supervised fine-tuning.
Teams should load diverse reasoning into pretraining, use a small high quality set for supervised fine-tuning, then stabilize with rewards.
----
Paper – arxiv. org/abs/2510.03264
Paper Title: "Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data"

2
9
1,109
9 Oct 2025
Thank you @rohanpaul_ai for sharing our work!
In "Front-Loading Reasoning", we show that injecting reasoning data into pretraining builds models that reach the frontier.
On average, 22% (pretraining) → 91% (SFT) → 49% (RL) relative gains. 🚀
🔗Paper: arxiv.org/pdf/2510.03264
📝 Blog: research.nvidia.com/labs/adl…
9 Oct 2025
New @nvidia paper shows that teaching reasoning early during pretraining builds abilities that later fine-tuning cannot recover.
Doing this early gives a 19% average boost on tough tasks after all post-training.
Pretraining is the long first stage where the model learns to predict the next word from lots of text.
Supervised fine-tuning is a later stage where it studies step by step answers from labeled examples.
Reinforcement learning then rewards better answers so the model improves further.
Diversity matters most in pretraining, while high quality matters most in supervised fine-tuning, roughly 11% vs 15% gains.
Even doubling supervised fine-tuning on a base that skipped early reasoning could not catch up.
Adding lots of mixed-quality supervised fine-tuning data even cut math by about 5%.
High quality reasoning added in pretraining looked small at first, then showed up strongly after supervised fine-tuning.
Teams should load diverse reasoning into pretraining, use a small high quality set for supervised fine-tuning, then stabilize with rewards.
----
Paper – arxiv. org/abs/2510.03264
Paper Title: "Front-Loading Reasoning: The Synergy between Pretraining and Post-Training Data"
13
1,085


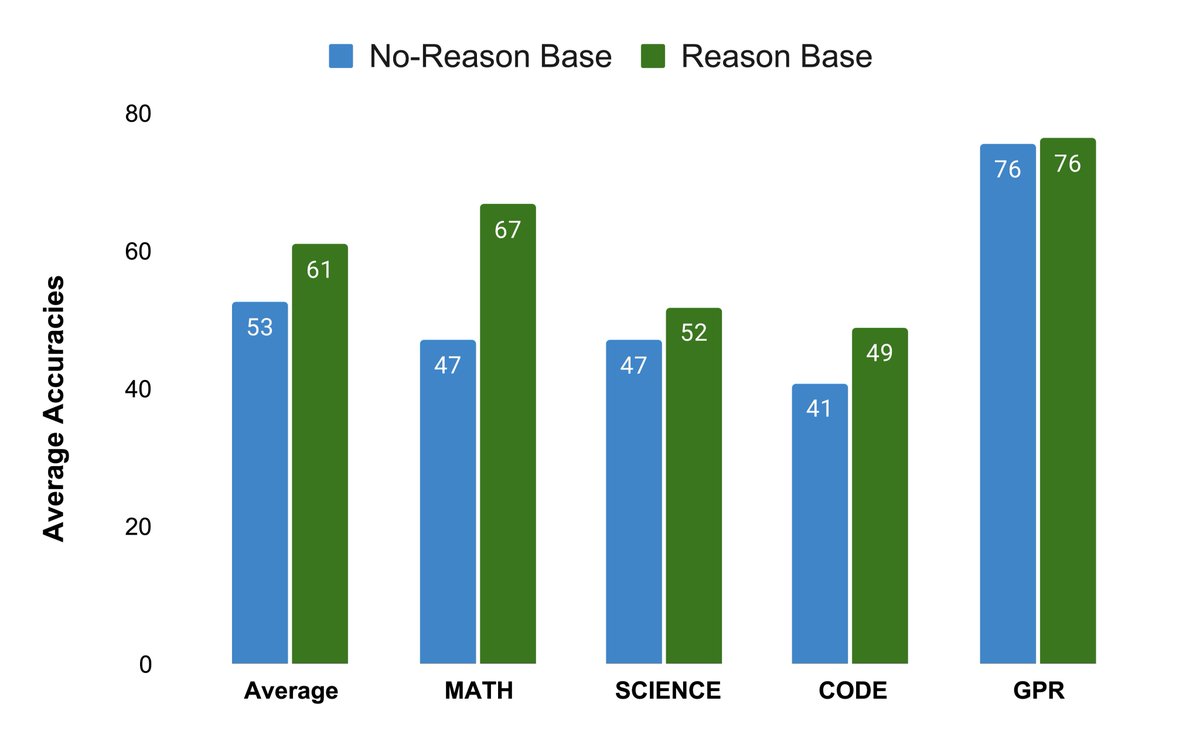
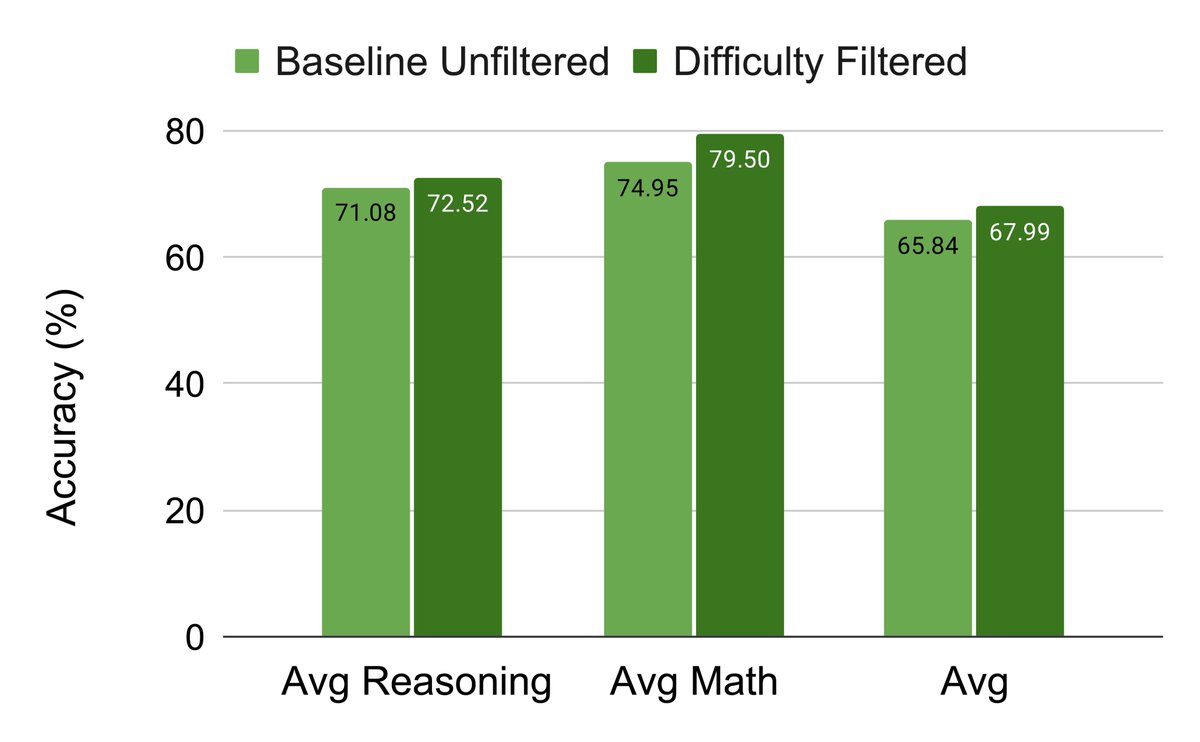
When should LLMs learn to reason—early in pretraining or late in fine-tuning?🤔
Front-Loading Reasoning, shows that injecting reasoning data early creates durable, compounding gains that post-training alone cannot recover
Paper:tinyurl.com/3tzkemtp
Blog:research.nvidia.com/labs/adl…

4
12
47
3,788
2 Oct 2025
When should an LLM learn to reason? 🤔 Early in pretraining or late in fine-tuning?
Our new work, "Front-Loading Reasoning", challenges the "save it for later" approach. We show that injecting reasoning data into pretraining is critical for building models that reach the frontier.
📝 Blog: research.nvidia.com/labs/adl…
🔗Paper: tinyurl.com/3tzkemtp
🧵↓
3
34
143
18,202
2 Oct 2025
Our work provides a principled guide for training reasoning-centric LLMs:
➣ Don't wait: Inject reasoning data into pretraining.
➣ Be strategic: Use DIVERSE data for pretraining, emphasize HIGH-QUALITY data for SFT.
➣ Be careful: Avoid polluting your SFT with low-quality data.
This moves us from "more data" to a smarter, phase-aware approach.
1
2
226
2 Oct 2025
Huge thanks to the amazing team and collaborators: @shrimai_, Eric Nyberg, @MostofaPatwary, @MohammadShoeybi, @YejinChoinka, and @ctnzr!
We'd love to hear your thoughts!
3
218