
Joined July 2025
- Tweets 215
- Following 212
- Followers 14
- Likes 3,170
50 Photos and videos











Pinned Tweet

Jun 2
Introducing Bloc: A package manager and runtime orchestrator for reproducible local AI. Share optimized model recipes and run them anywhere with a single command :
bloc deploy arnav080/step-3-7-flash-nvfp4
free and open-s.
bloc-theta.vercel.app
1
5
328
Jun 6
this is with Q4_K_XL the previous setup but now the ttft was way better and almost the same as Q4_K_M, same for the t/s
i need to learn more about running these llms and get better at benchmarking
im better at building product so checkout @runbloc; i need help fixing bugs :)
2
9
Jun 6
Gemma 4 12B (M1 16GB) benchmark update:
ran using @runbloc
config:
bloc-theta.vercel.app/recipe…
- Q4_K_XL → Q4_K_M
- Speculative decoding (2B draft model)
- 8 → 4 CPU threads
- 16K → 8K context memory tuning
>> TTFT: ~120s → ~65s

1
3
39
Jun 6
interestingly generation speed (tokens/sec) remained almost unchanged, running the test again on the previous config to verify
3
3

Bloc v0.6.5 [finally stable] is officially live! just shipped a massive core engine rebuild, unifying llama.cpp, vLLM, and SGLang under one seamless interface.
security upgrades and performance boosts
try it now: bloc-theta.vercel.app [free & open-s]
1
1
7
Jun 5
tried running the new gemma 12b model on my macbook m1 16gb, using
@runbloc
config used:
bloc-theta.vercel.app/recipe…
system ram usage is around 7gb's leaving around 9gb for the model; my 5 year old mac aint built for ts, the ttft is around 2mins; but still very cool
1
3
57
Jun 5
if theres any better setups that i shouldve went with pls lmk, ill try running a more aggressive quantization next
8
Jun 5
if theres any better setups that i shouldve went with pls lmk, ill try running a more aggressive quantization next
5
Jun 5
adding a benchmark mode into bloc. whats an ideal benchmarking test for local models?
7
Jun 4
a lot of vide coding today, but this new upgrade to the engine should make it a lot more stable and robust. cleaned up the bad implementations from earlier and technical debt.
getting the update live, a couple more stress tests, in the meanwhile checkout @runbloc
20
Jun 4
fixing the ai slop on bloc now, the code is too fragile rn. bringing a big update soon to make it a lot more stable
9
Jun 4
thank you unsloth! GGUF is here, share those recepies on @runbloc
Jun 3

Thank you Google Deepmind for constantly releasing open models! 🌟
We made Dynamic GGUFs so you can run Gemma 4 12B more efficiently: huggingface.co/unsloth/gemma…
30
Jun 3
the ui is super smooth and amazing [idk why the videos lagging a bit / jitters] go try it out for yourselves it free!!
bloc-theta.vercel.app/instal…
[the only reason im running a 0.5 model is bec im broke and thats all my m1 macbook can run (only got 6ish gb of ram free]

2
44
Jun 3
ever seen such an active dev who listens to the community? (i am the community i alone am the community)
5
Jun 3
does anyone know a good way to render pixel-art characters like this directly inside a terminal app?
15
Jun 3
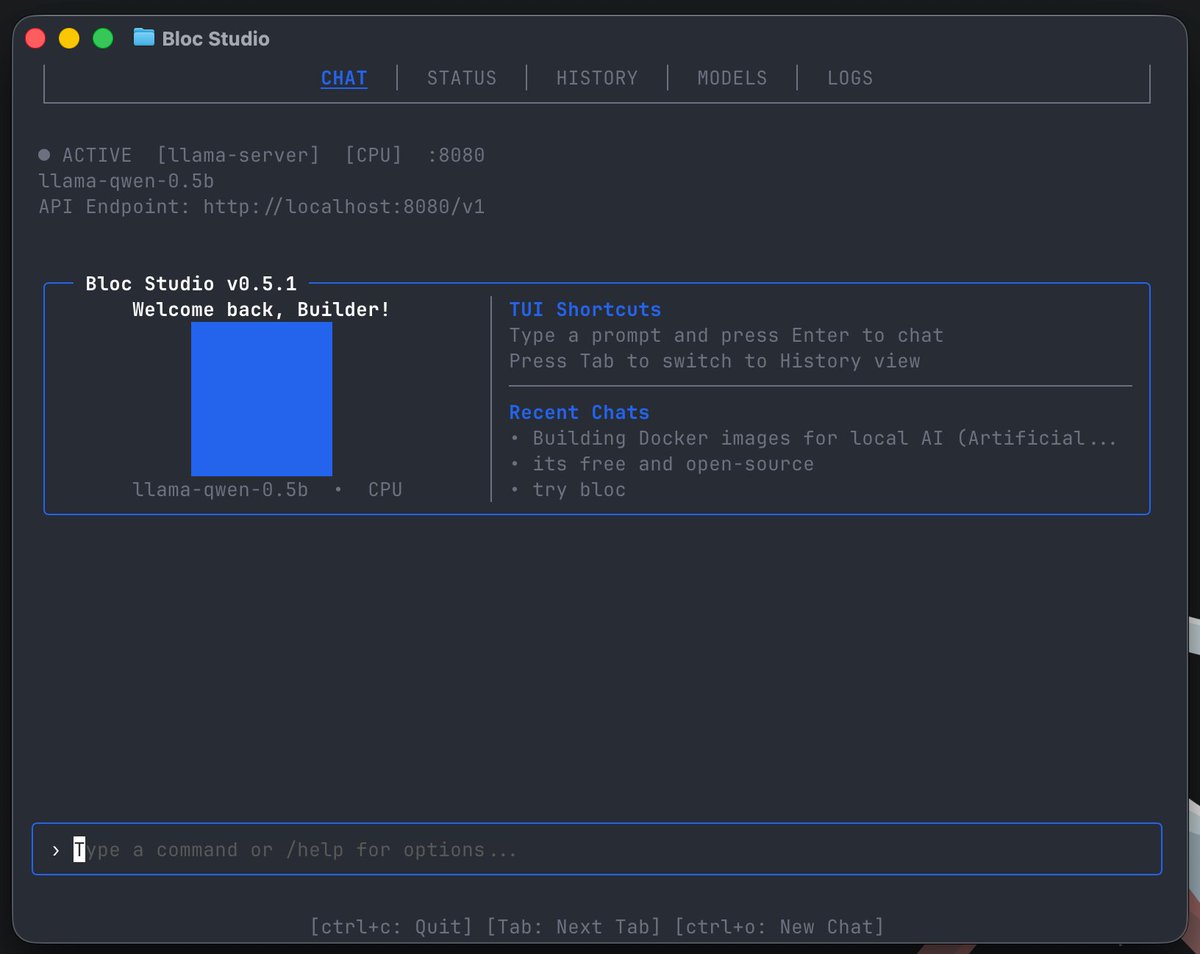
ngl, that looks pretty slick (by that i mean resembles claude code)
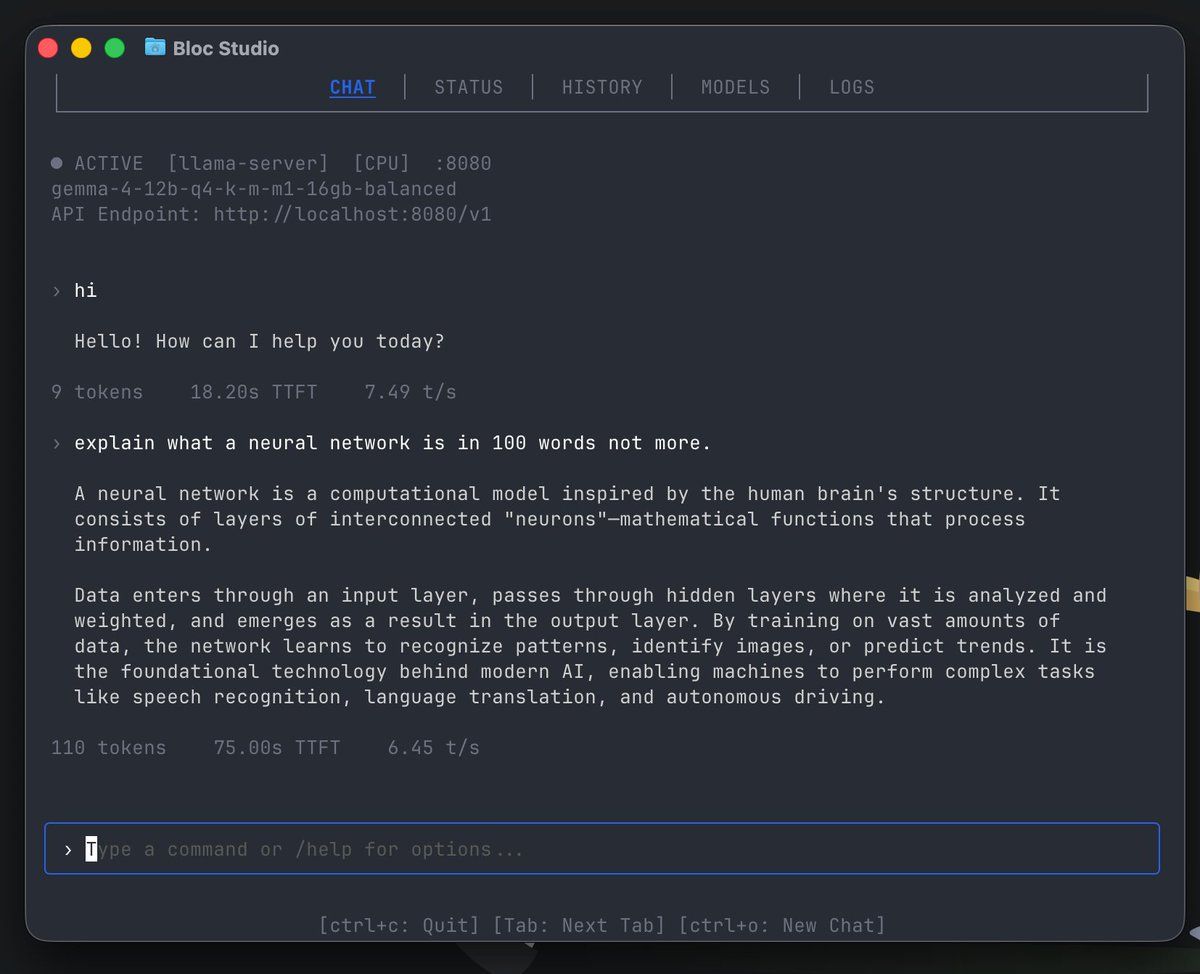
we now have Bloc Studio - a terminal workspace for interacting with your Bloc-hosted models.
Built-in UI for Llama.cpp, vLLM and SGLang engines.
try it now: bloc-theta.vercel.app
26
Jun 2
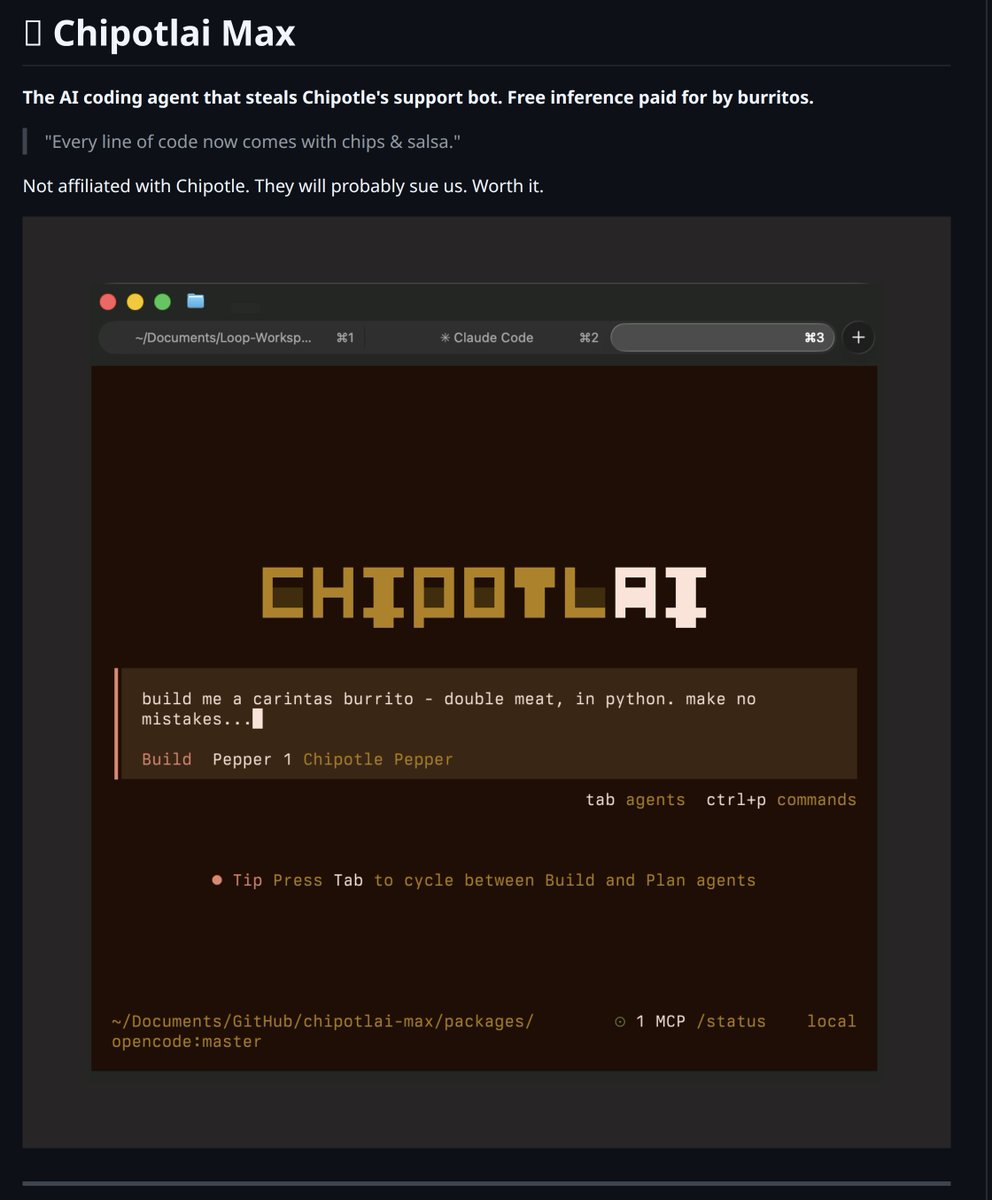
this might be the best tweet ive read in a while

someone made a fork of opencode that routes through the unsecured ai endpoints from chipotle
34
Jun 2
i strongly believe people dont understand how big local ai is going to be in the near future esp for businesses. imagine having to not pay per token, no sending sensitive data to third parties, predictable costs
just owning the models, owning the infrastructure owning the data
17