
Train and run models locally! 🦥 github.com/unslothai/unsloth
Joined November 2023
- Tweets 680
- Following 464
- Followers 68,705
- Likes 9,958
238 Photos and videos












Pinned Tweet

Mar 17
Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500 models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side export to GGUF
GitHub: github.com/unslothai/unsloth
Blog and Guide: unsloth.ai/docs/new/studio
Available now on Hugging Face, NVIDIA, Docker and Colab.
234
881
5,379
1,670,270
Unsloth AI retweeted

Jun 12
Local AI in action! MiniMax M3 unning locally on a single M3 Ultra 512GB in Unsloth Studio! 🔥
Here UD-Q5_K_XL decoding at 32.5 toks/s!
20
13
235
26,094
Jun 12
MiniMax M3 can now be run locally!🔥
MiniMax-M3 is a new 428B (23B active) open model with 1M context that performs on par with Gemini 3.1 Pro.
Run Dynamic 2-bit GGUF on 138GB RAM/VRAM or 3-bit on 165GB.
GGUF: huggingface.co/unsloth/MiniM…
Guide: unsloth.ai/docs/models/minim…
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
58
86
695
139,812
Jun 12
DiffusionGemma can now run at 2000 tokens/sec! ⚡
We made local DiffusionGemma inference 1.8× faster.
Run it on 18GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/models/diffu…
Jun 10

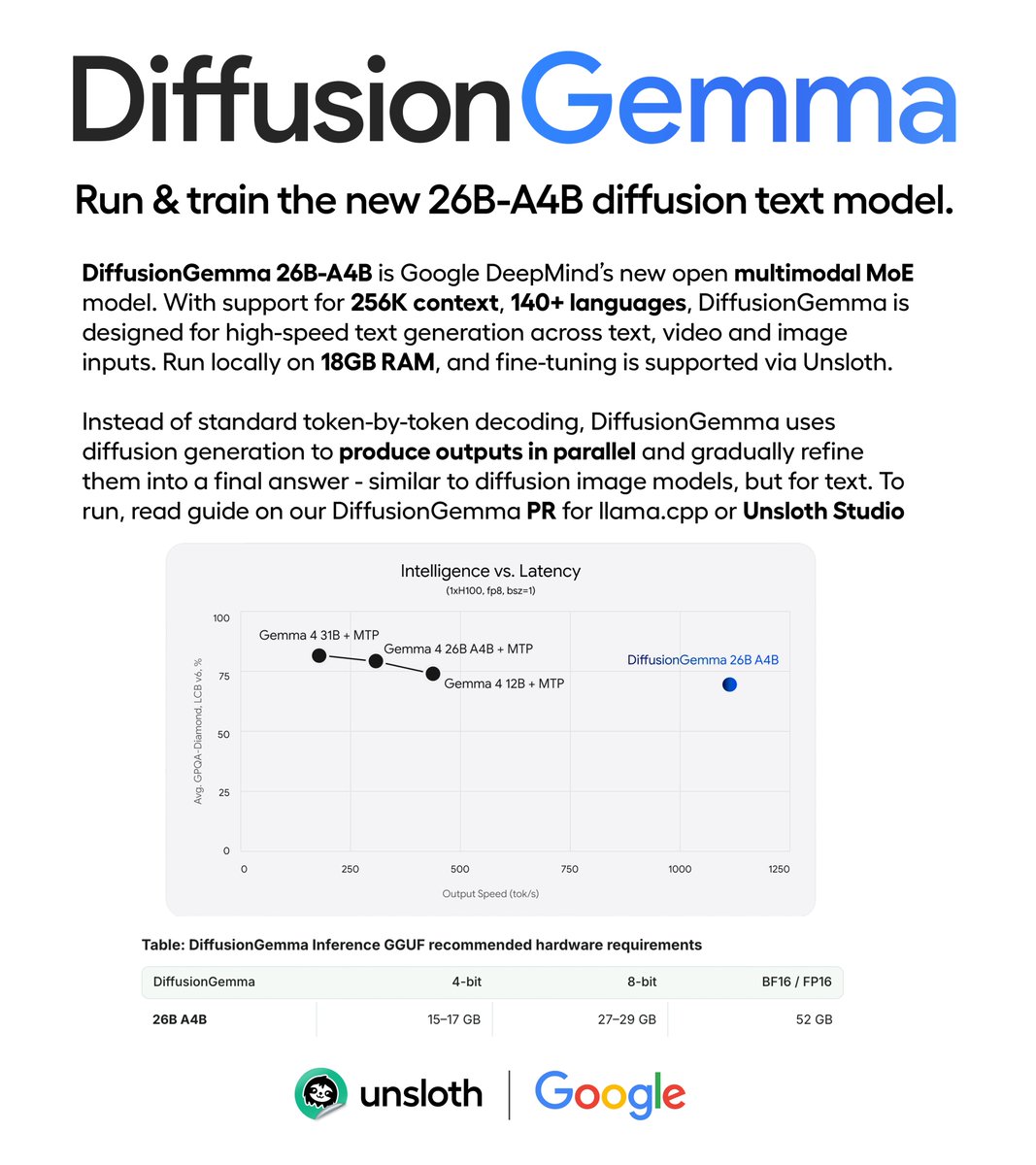
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
62
176
1,686
153,468
Jun 11
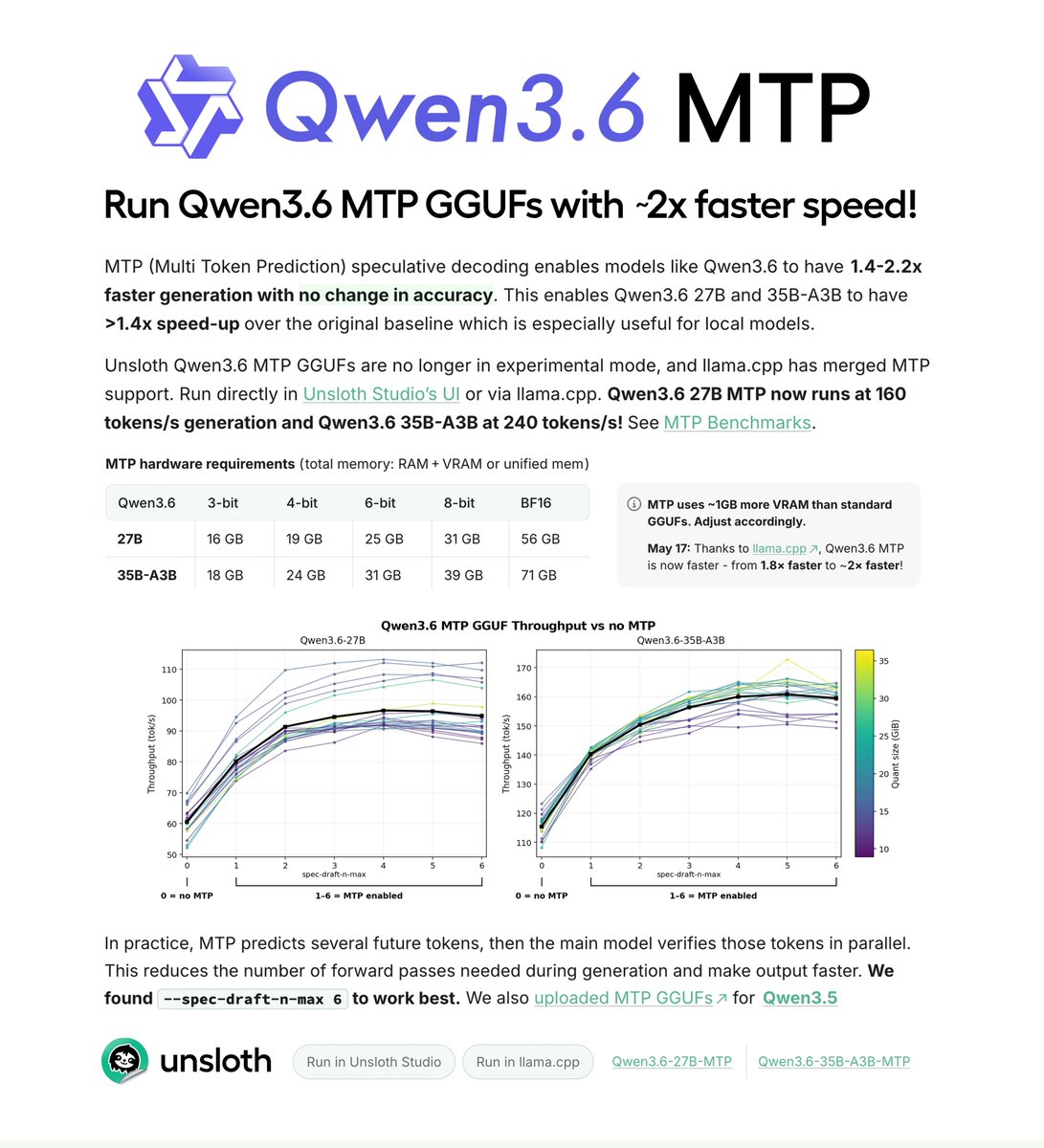
Gemma 4 now runs 2x faster with MTP GGUFs! Run locally on just 6GB RAM. ⚡️
MTP enables Google Gemma 4 run ~1.4–2.2× faster with no accuracy loss.
Gemma 4 12B MTP can run at 162 t/s vs. 52 t/s without MTP. 31B reaches 101 t/s.
GGUFs Guide: unsloth.ai/docs/models/mtp
60
253
2,145
209,474
Jun 10
Google releases DiffusionGemma.✨
The new 26B-A4B diffusion text model runs locally on 18GB RAM.
It supports high-speed text generation, thinking, image, video and 256K context.
Run and train via Unsloth Studio.
GGUF: huggingface.co/unsloth/diffu…
Guide: unsloth.ai/docs/models/diffu…
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
65
246
1,849
317,651
Jun 5
Google releases Gemma 4 QAT. ✨
You can now run Gemma 4 at 3x less memory with near original performance.
Quantization-Aware Training (QAT) makes it possible to run Gemma 4 26B-A4B on 16GB RAM.
GGUFs: huggingface.co/collections/u…
QAT Guide: unsloth.ai/docs/models/gemma…
Jun 5
We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
93
413
2,899
247,390
Jun 4
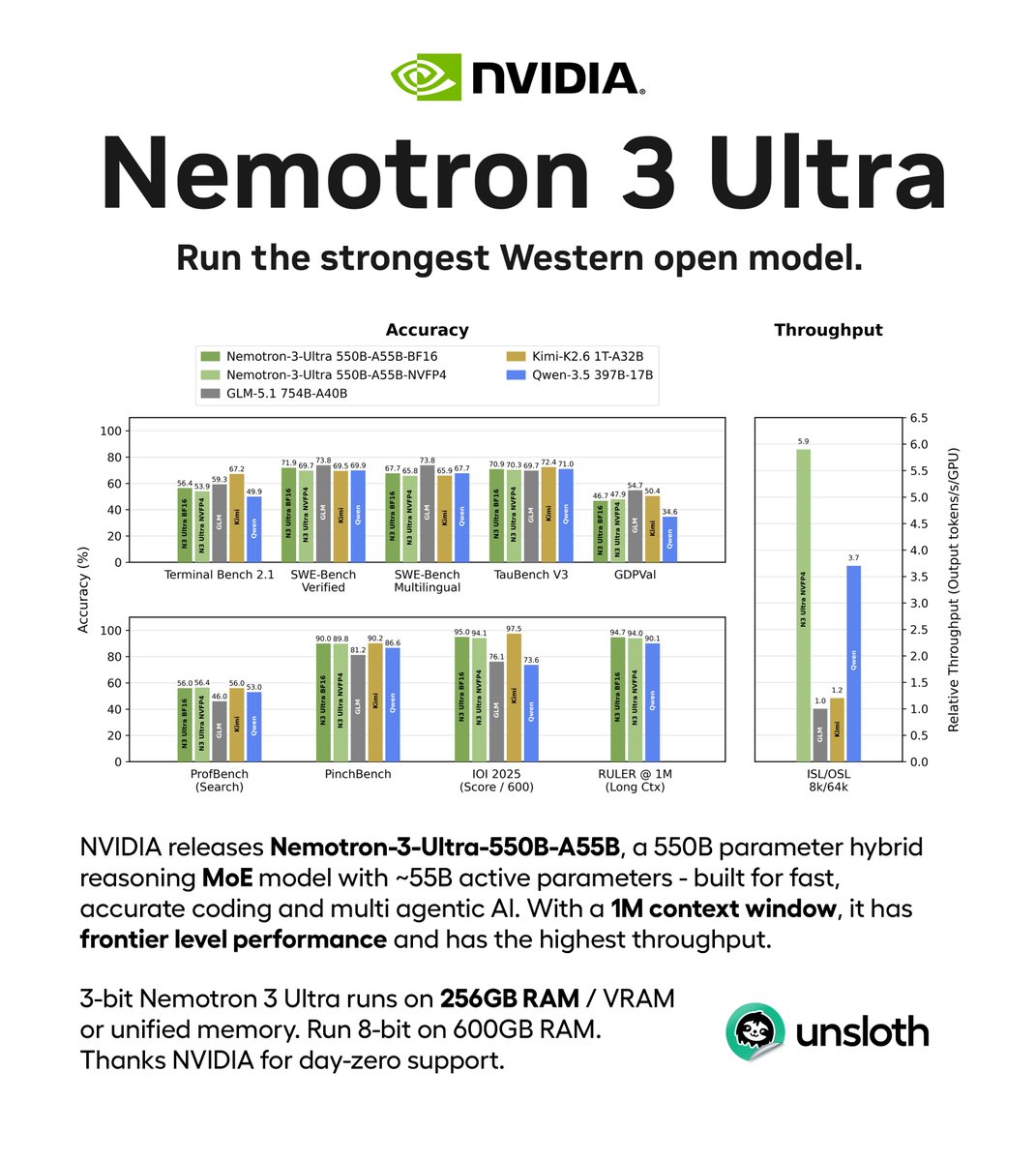
You can now run NVIDIA Nemotron 3 Ultra, a new 550B open model.
Nemotron-3-Ultra-550B-A55B is NVIDIA's largest LLM yet, with 1M context, frontier coding & chat.
Run 2-bit on 200GB RAM, 3-bit on 256GB, 8-bit on 600GB.
GGUF: huggingface.co/unsloth/NVIDI…
Guide: unsloth.ai/docs/models/nemot…

Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
23
44
409
38,859
Jun 4
2-bit Gemma 4 12B GGUF, only 4.66 GB on disk, managed to cite 15 sites from a single prompt.
Try this locally on >6GB RAM via Unsloth Studio.
GitHub: github.com/unslothai/unsloth
Jun 3
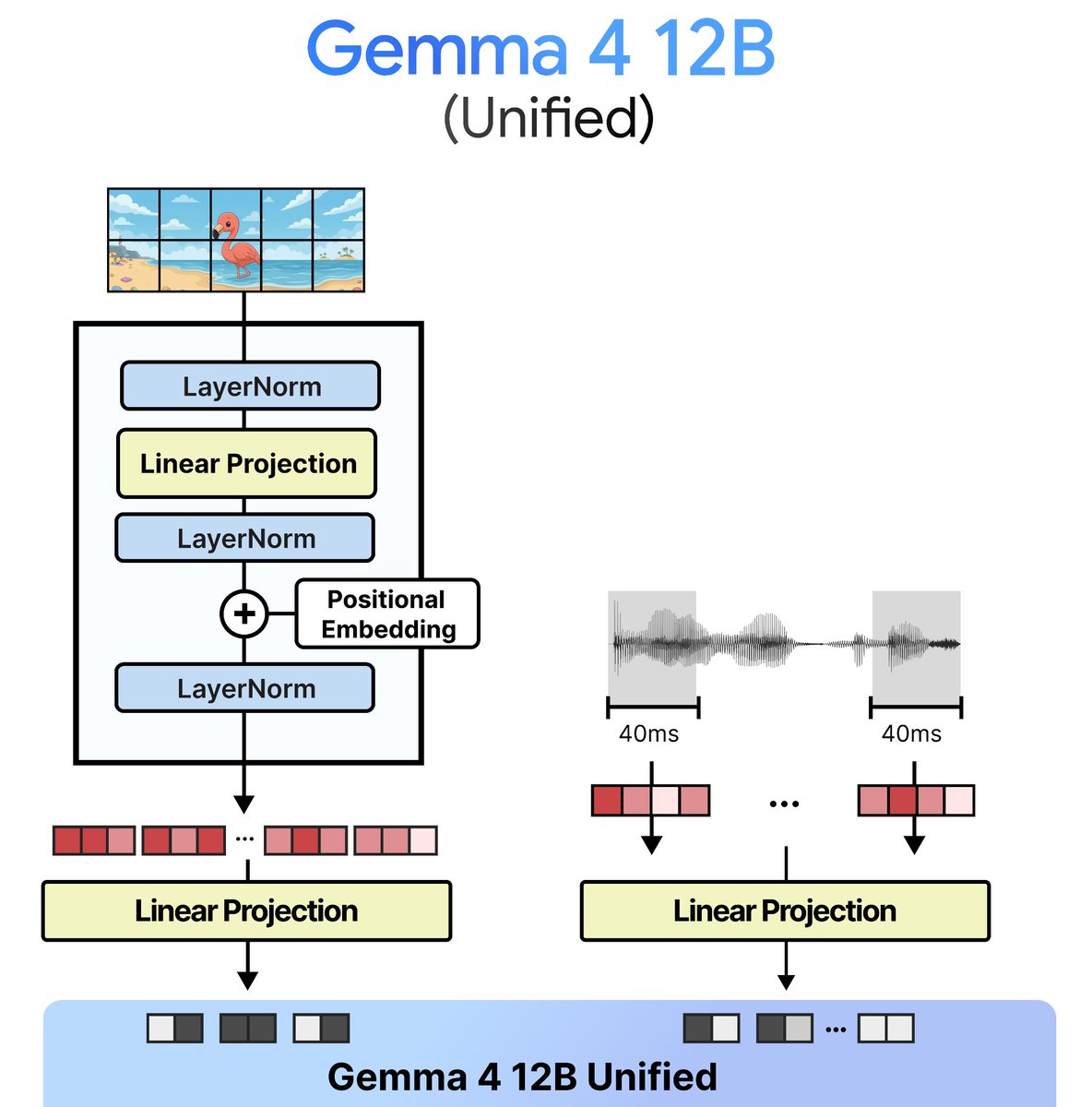
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: huggingface.co/unsloth/gemma…
Guide: unsloth.ai/docs/models/gemma…
45
194
1,628
140,365
Jun 3
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: huggingface.co/unsloth/gemma…
Guide: unsloth.ai/docs/models/gemma…
Jun 3
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

96
380
2,820
348,165
Jun 3
Vision and audio support for Gemma 4 12B GGUF is now added.
Please update to the latest version of Unsloth and llama.cpp. 🙏
2
7
69
6,998
Jun 2
Local models are coming to your laptop soon! 🚀
We're excited to partner with @Microsoft to enable millions of developers run local models on Windows!
Jun 2

Aion 1.0 Plan represents an evolution of what the Windows on-device AI platform is capable of at scale!
Thrilled to partner with @UnslothAI on optimization across our silicon ecosystem.
More #MSBuild news here: msft.it/6017vjGc7
26
50
542
41,050
Unsloth AI retweeted

Jun 2
Aion 1.0 Plan represents an evolution of what the Windows on-device AI platform is capable of at scale!
Thrilled to partner with @UnslothAI on optimization across our silicon ecosystem.
More #MSBuild news here: msft.it/6017vjGc7
9
34
234
76,222
Jun 2
You can now train 120B parameter models locally on a laptop! 🔥
We collabed with NVIDIA and Microsoft to bring LLM training on the 128GB unified memory RTX Spark laptop!

This is the NVIDIA RTX Spark Superchip. A new beginning for personal computers.
Designed for creators, AI developers, and gamers, RTX Spark brings over 30 years of NVIDIA innovation to slim Windows laptops and small, ultra-efficient desktop PCs.

55
106
1,134
89,114
Jun 1
We made a guide on using MCP with local LLMs.
Connect Qwen3.6 and Gemma 4 for controlled access to tools, files, APIs, enabling private automated workflows.
Learn to use OAuth, Exa, Context7, Hugging Face & more.
Guide: unsloth.ai/docs/basics/mcp
GitHub: github.com/unslothai/unsloth
18
147
990
39,070
Unsloth AI retweeted

May 30
🙌 Massive unlock for open and proprietary models, can't wait to try this out!!
May 26
You can now run GPT, Claude & other models in Unsloth.
Connect run APIs in a local UI:
- Code execution, web search, image gen, editing
- Auto prompt caching to save costs
- Provider features like cites, sandboxes
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/integrations…
2
6
54
12,261
Unsloth AI retweeted

May 28
Fine-tuning in 2026 has never been easier
You can make any open-source model 10x more powerful
And thanks to Unsloth Studio, creating custom datasets takes just a few mins,
Here is the full course:
18
68
697
35,690
May 26
You can now run GPT, Claude & other models in Unsloth.
Connect run APIs in a local UI:
- Code execution, web search, image gen, editing
- Auto prompt caching to save costs
- Provider features like cites, sandboxes
GitHub: github.com/unslothai/unsloth
Guide: unsloth.ai/docs/integrations…
17
32
265
31,178