
math/cs @uwaterloo | prev: ml @quora, @amazon
Joined June 2020
- Tweets 113
- Following 753
- Followers 1,461
- Likes 6,573
7 Photos and videos





Pinned Tweet

16 Sep 2025
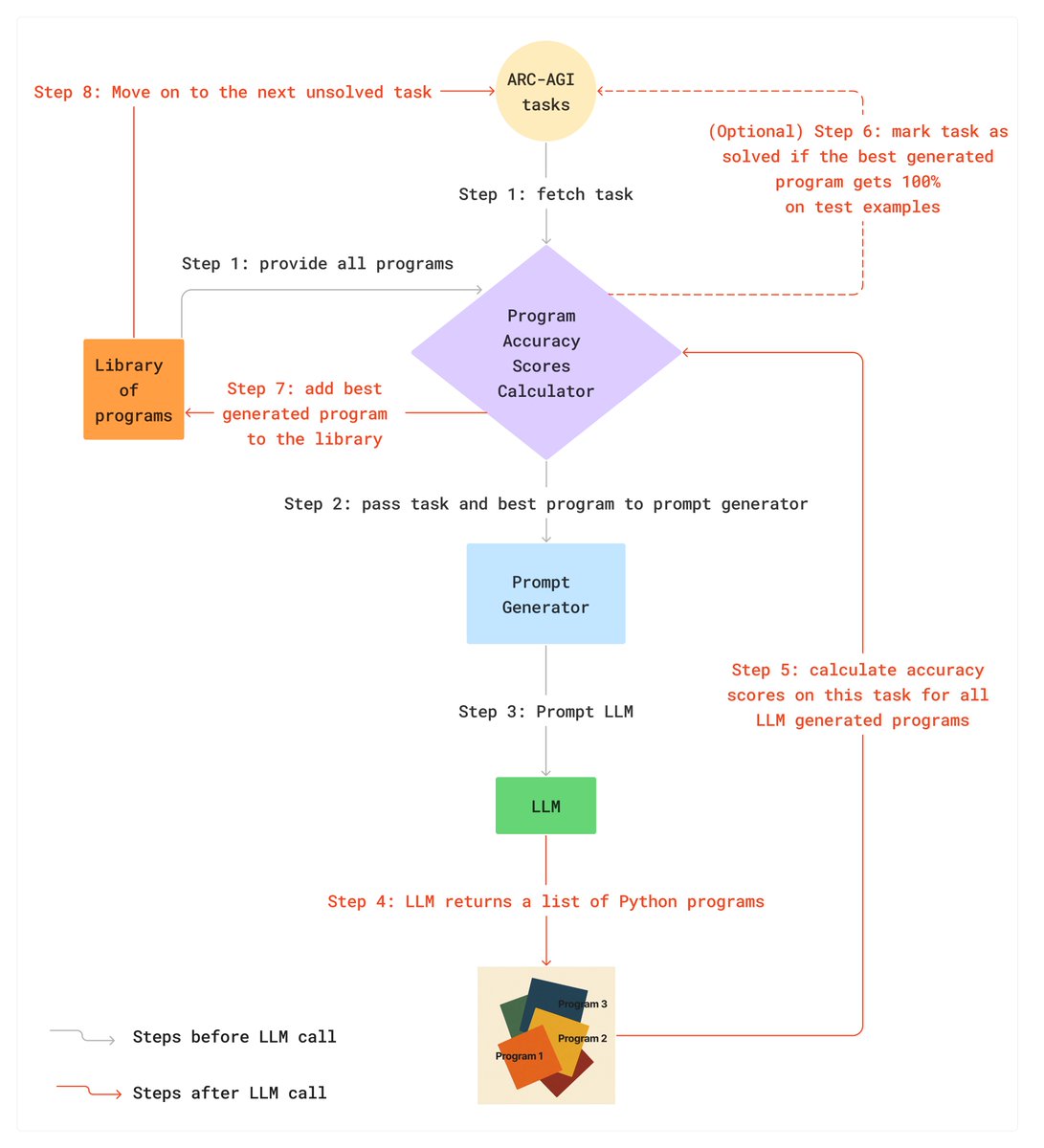
Here's how I (almost) got the high scores in ARC-AGI-1 and 2 (the honor goes to @jeremyberman) while keeping the cost low. To put things into perspective: o3-preview scored 75.7% on ARC-AGI-1 last year while spending $200/task on low setting. My approach scores 77.1% while spending $2.56!

New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
27
91
882
135,900

Grok 5 starts training in a few weeks
New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
2,765
3,226
30,489
7,275,385
Eric Pang retweeted

16 Sep 2025
I'm back at the top of ARC-AGI with my new program. I use @grok 4 and multi-agent collaboration with evolutionary test-time compute
New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
72
93
1,254
518,263
16 Sep 2025
Here's how I (almost) got the high scores in ARC-AGI-1 and 2 (the honor goes to @jeremyberman) while keeping the cost low. To put things into perspective: o3-preview scored 75.7% on ARC-AGI-1 last year while spending $200/task on low setting. My approach scores 77.1% while spending $2.56!
New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
27
91
882
135,900
Eric Pang retweeted

16 Sep 2025
We just released 2 open source SOTA submission to ARC-AGI (both v1 and v2)
Submissions by @jeremyberman and @_eric_pang_ are the best we've seen. Both:
- Open source
- Use Grok 4
- Use program synthesis
I asked why they used Grok 4, both said, "It was the best model I used in testing."
These types of submissions are the reason we run ARC Prize. Impacful research which pushes the boundary out in the open.
All the links for their code are in the ARC Prize thread
New SOTA on ARC-AGI
- V1: 79.6%, $8.42/task
- V2: 29.4%, $30.40/task
Custom submissions by @jeremyberman and @_eric_pang_ are now the best known solutions to ARC-AGI
Both:
* Are open source
* Use Grok 4
* Implement program-synthesis outer loops with test-time adaptation
83
98
844
7,724,017
Eric Pang retweeted

16 Sep 2025
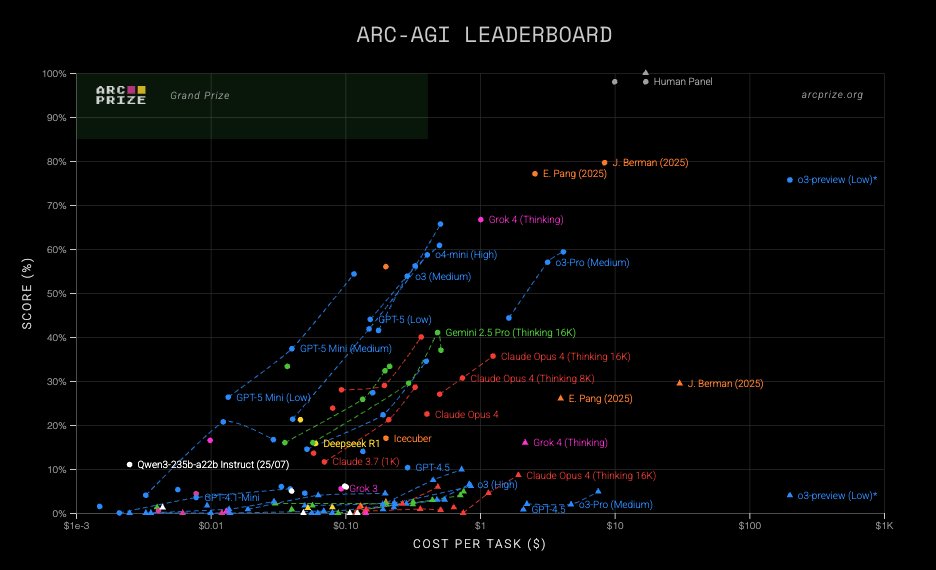
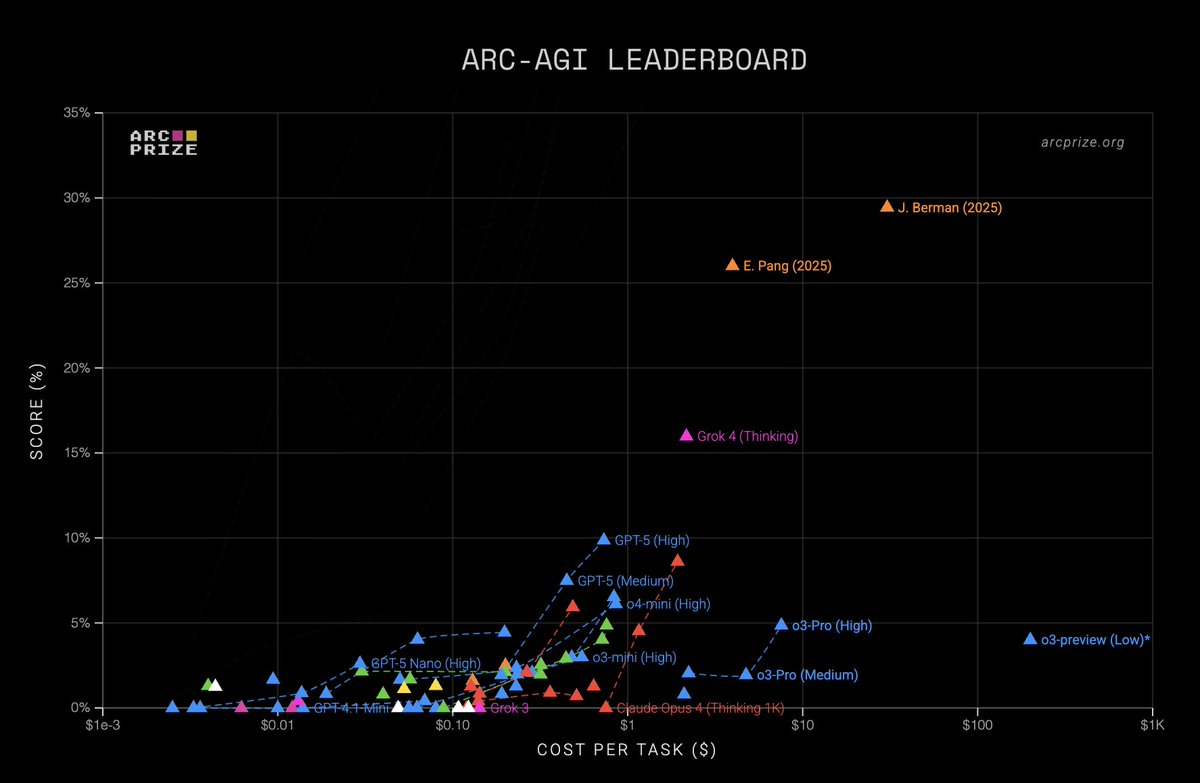
ARC just published new #1 and #2 reproducible SOTA scores on our public leaderboard from @jeremyberman and @_eric_pang_. And their code is now open source! My analysis below -- includes suggestions for application layer AI and future research directions.
New SOTA:
- v1: 79.6%, $8.42/task
- v2: 29.44%, $30.40/task
Jeremy and Eric’s approaches share a lot in common:
1. Both use Grok 4 as a base, chosen as the best off-the-shelf AI reasoning system
2. Both implement program synthesis systems on top of the LLM
3. Both use outer refinement loops and test-time adaptation
4. Both use abstraction library learning
5. Both meaningfully improve accuracy over previous reproducible SOTA
6. Both are relatively efficient (5-20X single-shot cost), practical for deployment
7. Both are reproducible and open source, others can build on them
Their approaches vary in details.
Jeremy upgrades his previous-SOTA [2024] which had an LLM writing python code, for one that writes solutions in English (“natural language programs”).
He notes ARC v2 depends on more complex perception and his English-based solution benefits by using a less-precise substrate for reasoning than code.
He also moved beyond brute-force full program search. Now, English instructions are scored on partial tasks (eg. explain single examples), and high scoring explanations are pooled together.
Eric’s approach combines ideas from evolutionary program synthesis and DreamCoder [2020]. But his approach diverges from DreamCoder in several meaningful ways.
First, instead of a symbolic AST substrate used in DreamCoder, his LLM writes and stores full code programs in text in a library, using an accuracy-based heuristic.
Second, instead of hand-crafted an initial library, his program library starts empty. This is promising as it removes a key bottleneck to applying DreamCoder to new domains.
Based on the last 12 months of public progress on ARC, we are building a good picture of the “right core ideas” for AGI. This is very exciting!
For ARC Prize 2025, I’d love to see a team swap Grok 4 with OSS LLMs and work to fit performance into the Kaggle constraints (targeting human efficiency).
For application areas where accuracy matters most (and latency and some cost can be traded), Jeremy and Eric’s open source outer loops should be considered.
And for further research, I encourage folks to take Jeremy and Eric’s ideas as inspiration and combine them with @lateinteraction DSPy and @LakshyAAAgrawal GEPA.
13
30
265
55,945
14 Sep 2025
The same reason is why ARC-AGI is the most important benchmark in AI. It is the only benchmark that's not saturated after repeated attempts from players big and small.
1
4
558
Eric Pang retweeted

16 May 2025
A CONFUCIAN CONFUSION / MAHJONG: TWO FILMS BY EDWARD YANG • Coming to Criterion in August! criterion.com/boxsets/8199-a…
In this pair of sharp, sprawling satires, one of Taiwan’s most celebrated filmmakers captures the anything-can-happen mood of Taipei at the end of the twentieth century.

12
164
1,104
331,196
Eric Pang retweeted

12 May 2025
Introducing Continuous Thought Machines
New Blog: sakana.ai/ctm/
Modern AI is powerful, but it’s still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
Thought takes time, and reasoning is a process. Biological brains inspire us with their complex neural activity, where neural timing is critical to intelligence. We’re exploring how to bring that power to AI. The Continuous Thought Machine (CTM) incorporates neuron-level temporal processing and neural synchronization, moving beyond current AI limitations.
Our approach has two core innovations: (1) neuron-level temporal processing, where each neuron uses unique parameters to process a history of incoming signals for fine-grained temporal dynamics, and (2) neural synchronization, used as a direct latent representation to modulate data and produce outputs, encoding information directly in the timing of neural activity.
Learn more about our approach:
Interactive Report: pub.sakana.ai/ctm/
Full Paper: arxiv.org/abs/2505.05522
GitHub : github.com/SakanaAI/continuo…
36
282
1,299
289,727
11 May 2025
Re: Gödel's incompleteness theorems
27 May 2022

“People get so caught up in the fact that they have limits that they rarely exert the effort required to get close to them.” amzn.to/3eKu26n

1
367
4 May 2025
This is true but Meta doesn't hate it as long as you are still watching reels (and hence the ads)

most of my friends & i have completely stopped posting to insta (even stories).
all we do is exchange memes & reels on messages.
i remember when this happened to fb very vividly. this should be titled zuck’s law.
3
388
27 Mar 2025
Re: the discussion about AI generated art. It's interesting that filmmakers nowadays hate anything AI while the greats in the past were the first to embrace technology and computer generated graphics.
1
1
230
27 Mar 2025
"... as to say well you can't create because now it's a computer rushing numbers through it. The technology is always an element of creativity but it never is the source of the creativity. And so my attitude is to embrace technology as it comes."
1
209