
ai researcher @meta superintelligence labs, past: openai, google 🧠
Joined October 2020
- Tweets 1,250
- Following 707
- Followers 108,671
- Likes 10,870
130 Photos and videos












Pinned Tweet

16 Jul 2025
Becoming an RL diehard in the past year and thinking about RL for most of my waking hours inadvertently taught me an important lesson about how to live my own life.
One of the big concepts in RL is that you always want to be “on-policy”: instead of mimicking other people’s successful trajectories, you should take your own actions and learn from the reward given by the environment. Obviously imitation learning is useful to bootstrap to nonzero pass rate initially, but once you can take reasonable trajectories, we generally avoid imitation learning because the best way to leverage the model’s own strengths (which are different from humans) is to only learn from its own trajectories. A well-accepted instantiation of this is that RL is a better way to train language models to solve math word problems compared to simple supervised finetuning on human-written chains of thought.
Similarly in life, we first bootstrap ourselves via imitation learning (school), which is very reasonable. But even after I graduated school, I had a habit of studying how other people found success and trying to imitate them. Sometimes it worked, but eventually I realized that I would never surpass the full ability of someone else because they were playing to their strengths which I didn’t have. It could be anything from a researcher doing yolo runs more successfully than me because they built the codebase themselves and I didn’t, or a non-AI example would be a soccer player keeping ball possession by leveraging strength that I didn’t have.
The lesson of doing RL on policy is that beating the teacher requires walking your own path and taking risks and rewards from the environment. For example, two things I enjoy more than the average researcher are (1) reading a lot of data, and (2) doing ablations to understand the effect of individual components in a system. Once when collecting a dataset, I spent a few days reading data and giving each human annotator personalized feedback, and after that the data turned out great and I gained valuable insight into the task I was trying to solve. Earlier this year I spent a month going back and ablating each of the decisions that I previously yolo’ed while working on deep research. It was a sizable amount of time spent, but through those experiments I learned unique lessons about what type of RL works well. Not only was leaning into my own passions more fulfilling, but I now feel like I’m on a path to carving a stronger niche for myself and my research.
In short, imitation is good and you have to do it initially. But once you’re bootstrapped enough, if you want to beat the teacher you must do on-policy RL and play to your own strengths and weaknesses :)
130
350
3,414
353,545
Apr 16
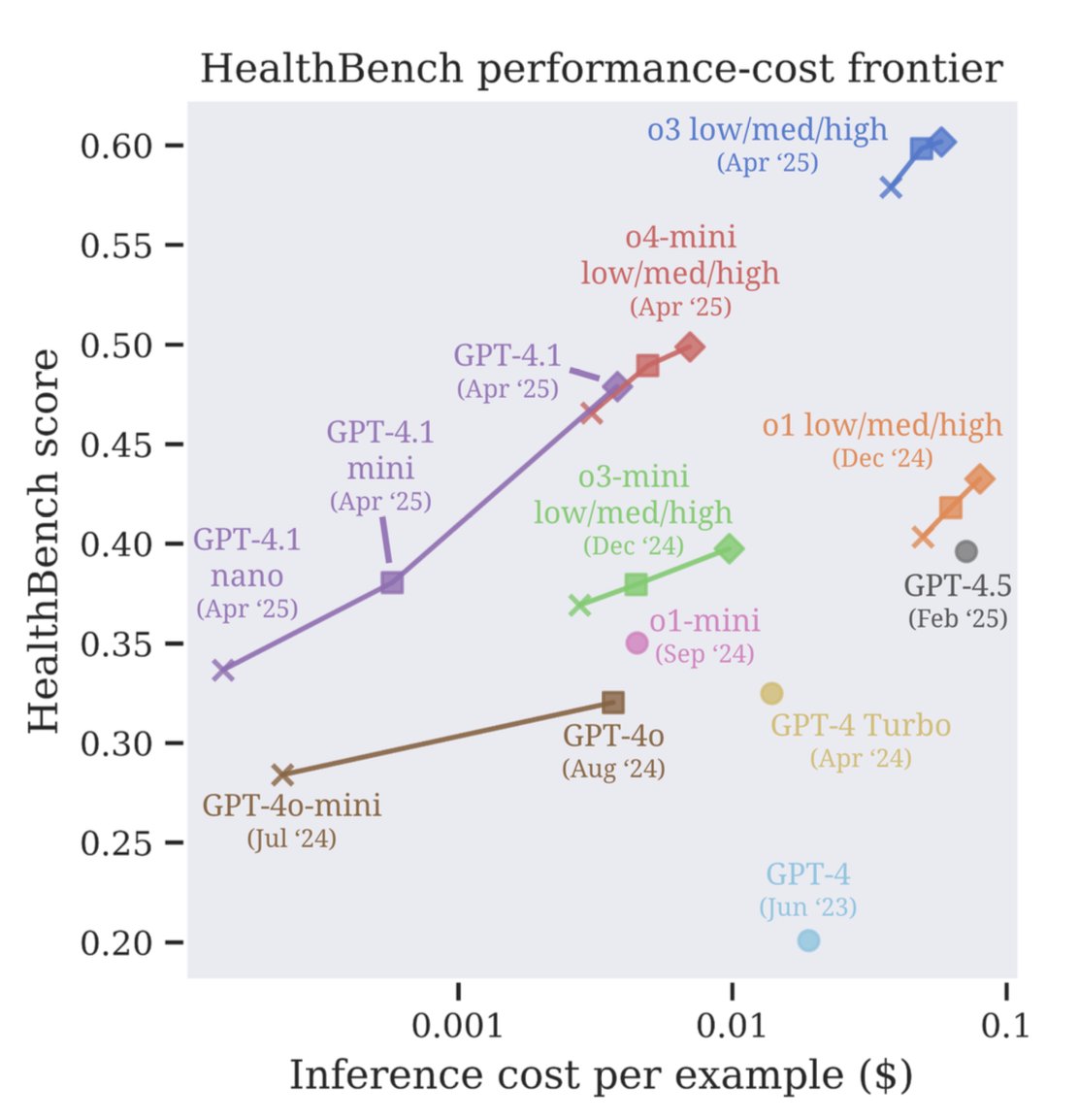
Beautifully written piece by @FAbnousi about how AI for health might look like in the future
The current data in health is limited because it only captures episodic clinical snapshots of what happens to our bodies
The revelation is that there is so much latent knowledge in looking at regular changes in our body. Could be through lab tests or even proxy metrics like wearable data
With AI democratizing the ability for people to understand their own health, we're moving towards a trend of individuals gathering health data around their bodies and leveraging AI to understand themselves
Bryan Johnson is extreme but a good example of this trend
Personally, I started getting Function Health blood tests every six weeks instead of the recommended six months to increase fidelity on how changes in lifestyle affect my body
Of course i use AI to analyze the results and adapt, and it's been great
It would be cool to something in this direction happen in a big way across the world
And welcome to twitter @FAbnousi!
Apr 16

Medicine was built on the medical record.
But most of health and illness happens outside of it.
AI doesn’t create that gap — it exposes it.
The question now is structural: where should this data live — under what rules, and for whose benefit?
With @CelinaMYongMD in @statnews:
9
2
107
29,171
Apr 8
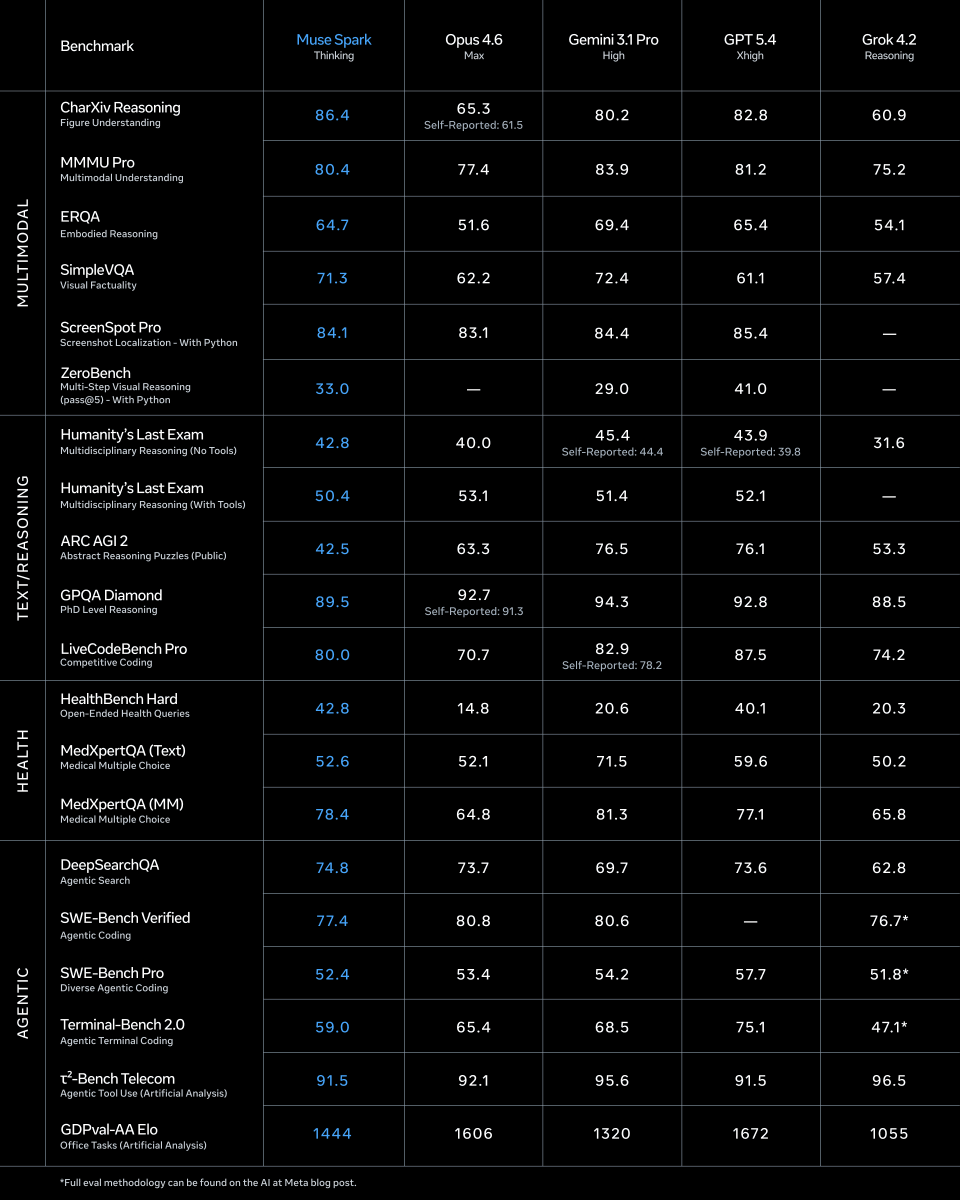
Fun nine months! My first week i remember we had a long dinner in the cafeteria daydreaming about the cool research directions to pursue, then going to back to our desks to write a basic script to inference llama. Now we have a pretty complete stack and our first model is out 🥑
Apr 8

1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
39
26
696
95,807
30 Sep 2025
Bullish, in the coming decades majority of compute will be spent on ai for science
30 Sep 2025

Today, @ekindogus and I are excited to introduce @periodiclabs.
Our goal is to create an AI scientist.
Science works by conjecturing how the world might be, running experiments, and learning from the results.
Intelligence is necessary, but not sufficient. New knowledge is created when ideas are found to be consistent with reality. And so, at Periodic, we are building AI scientists and the autonomous laboratories for them to operate.
Until now, scientific AI advances have come from models trained on the internet. But despite its vastness — it’s still finite (estimates are ~10T text tokens where one English word may be 1-2 tokens). And in recent years the best frontier AI models have fully exhausted it.
Researchers seek better use of this data, but as any scientist knows: though re-reading a textbook may give new insights, they eventually need to try their idea to see if it holds.
Autonomous labs are central to our strategy. They provide huge amounts of high-quality data (each experiment can produce GBs of data!) that exists nowhere else. They generate valuable negative results which are seldom published. But most importantly, they give our AI scientists the tools to act.
We’re starting in the physical sciences.
Technological progress is limited by our ability to design the physical world.
We’re starting here because experiments have high signal-to-noise and are (relatively) fast, physical simulations effectively model many systems, but more broadly, physics is a verifiable environment. AI has progressed fastest in domains with data and verifiable results - for example, in math and code. Here, nature is the RL environment.
One of our goals is to discover superconductors that work at higher temperatures than today's materials. Significant advances could help us create next-generation transportation and build power grids with minimal losses. But this is just one example — if we can automate materials design, we have the potential to accelerate Moore’s Law, space travel, and nuclear fusion.
We’re also working to deploy our solutions with industry. As an example, we're helping a semiconductor manufacturer that is facing issues with heat dissipation on their chips. We’re training custom agents for their engineers and researchers to make sense of their experimental data in order to iterate faster.
Our founding team co-created ChatGPT, DeepMind’s GNoME, OpenAI’s Operator (now Agent), the neural attention mechanism, MatterGen; have scaled autonomous physics labs; and have contributed to some of the most important materials discoveries of the last decade. We’ve come together to scale up and reimagine how science is done.
We’re fortunate to be backed by investors who share our vision, including @a16z who led our $300M round, as well as @Felicis, DST Global, NVentures (NVIDIA’s venture capital arm), @Accel and individuals including @JeffBezos , @eladgil , @ericschmidt, and @JeffDean. Their support will help us grow our team, scale our labs, and develop the first generation of AI scientists.

17
19
424
92,589
Jason Wei retweeted

14 Aug 2025
Excited to share that I recently joined the MSL team! Building personal superintelligence is serious and fun here. Join us!
14 Aug 2025

After a great time at OpenAI, we (@EdwardSun0909, @_jasonwei) recently joined @Meta Superintelligence Labs.
The first month has already been so much fun building from a clean slate with a truly talent-dense team! Very excited about the compute and long term focus of the new lab

58
24
849
268,451
14 Aug 2025
Old friends, new lab
14 Aug 2025
After a great time at OpenAI, we (@EdwardSun0909, @_jasonwei) recently joined @Meta Superintelligence Labs.
The first month has already been so much fun building from a clean slate with a truly talent-dense team! Very excited about the compute and long term focus of the new lab
61
30
979
199,365
16 Jul 2025
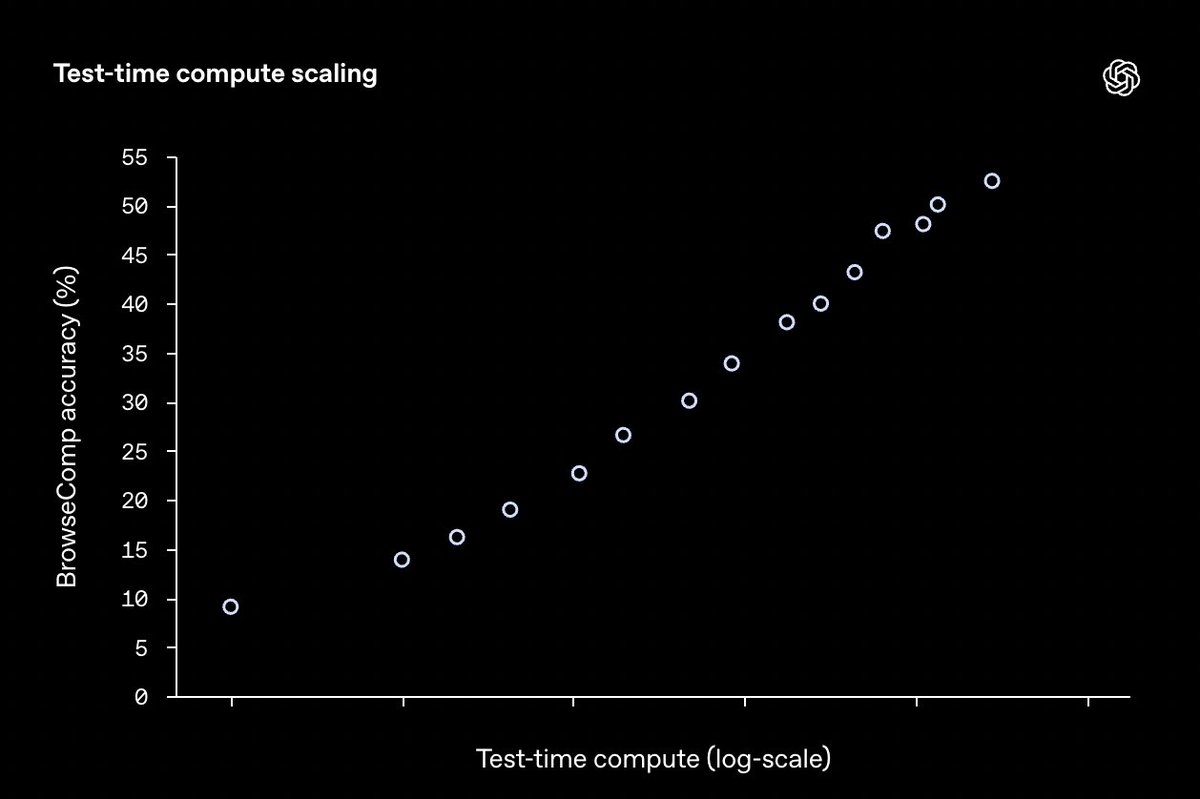
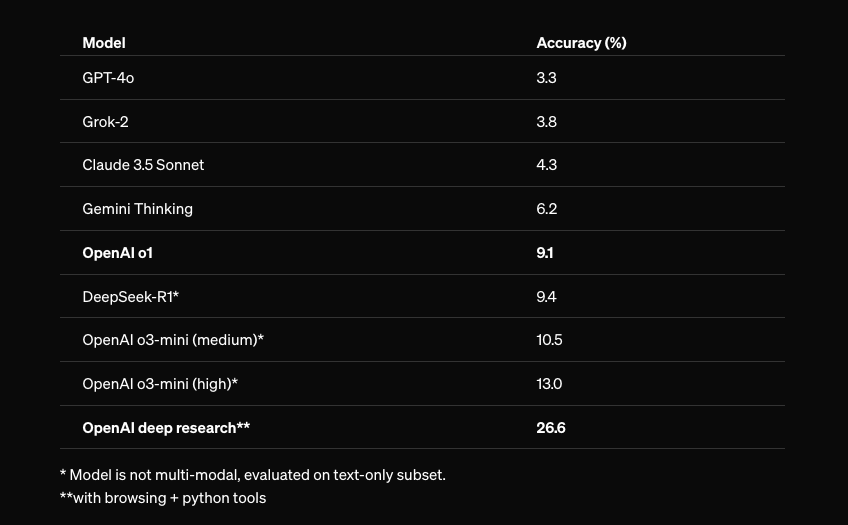
New blog post about asymmetry of verification and "verifier's law": jasonwei.net/blog/asymmetry-…
Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally.
Great examples of asymmetry of verification are things like sudoku puzzles, writing the code for a website like instagram, and BrowseComp problems (takes ~100 websites to find the answer, but easy to verify once you have the answer).
Other tasks have near-symmetry of verification, like summing two 900-digit numbers or some data processing scripts. Yet other tasks are much easier to propose feasible solutions for than to verify them (e.g., fact-checking a long essay or stating a new diet like "only eat bison").
An important thing to understand about asymmetry of verification is that you can improve the asymmetry by doing some work beforehand. For example, if you have the answer key to a math problem or if you have test cases for a Leetcode problem. This greatly increases the set of problems with desirable verification asymmetry.
"Verifier's law" states that the ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI. The ability to train AI to solve a task is proportional to whether the task has the following properties:
1. Objective truth: everyone agrees what good solutions are
2. Fast to verify: any given solution can be verified in a few seconds
3. Scalable to verify: many solutions can be verified simultaneously
4. Low noise: verification is as tightly correlated to the solution quality as possible
5. Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
One obvious instantiation of verifier's law is the fact that most benchmarks proposed in AI are easy to verify and so far have been solved. Notice that virtually all popular benchmarks in the past ten years fit criteria #1-4; benchmarks that don’t meet criteria #1-4 would struggle to become popular.
Why is verifiability so important? The amount of learning in AI that occurs is maximized when the above criteria are satisfied; you can take a lot of gradient steps where each step has a lot of signal. Speed of iteration is critical—it’s the reason that progress in the digital world has been so much faster than progress in the physical world.
AlphaEvolve from Google is one of the greatest examples of leveraging asymmetry of verification. It focuses on setups that fit all the above criteria, and has led to a number of advancements in mathematics and other fields. Different from what we've been doing in AI for the last two decades, it's a new paradigm in that all problems are optimized in a setting where the train set is equivalent to the test set.
Asymmetry of verification is everywhere and it's exciting to consider a world of jagged intelligence where anything we can measure will be solved.
59
251
1,619
393,905
12 Jul 2025
Bryan Johnson longevity mix is the most popular drink at ragers in SF

18
3
204
50,372
30 Jun 2025
We don’t have AI self-improves yet, and when we do it will be a game-changer. With more wisdom now compared to the GPT-4 days, it's obvious that it will not be a “fast takeoff”, but rather extremely gradual across many years, probably a decade.
The first thing to know is that self-improvement, i.e., models training themselves, is not binary. Consider the scenario of GPT-5 training GPT-6, which would be incredible. Would GPT-5 suddenly go from not being able to train GPT-6 at all to training it extremely proficiently? Definitely not. The first GPT-6 training runs would probably be extremely inefficient in time and compute compared to human researchers. And only after many trials, would GPT-5 actually be able to train GPT-6 better than humans.
Second, even if a model could train itself, it would not suddenly get better at all domains. There is a gradient of difficulty in how hard it is to improve oneself in various domains. For example, maybe self-improvement only works at first on domains that we already know how to easily fix in post-training, like basic hallucinations or style. Next would be math and coding, which takes more work but has established methods for improving models. And then at the extreme, you can imagine that there are some tasks that are very hard for self-improvement. For example, the ability to speak Tlingit, a native american language spoken by ~500 people. It will be very hard for the model to self-improve on speaking Tlingit as we don’t have ways of solving low resource languages like this yet except collecting more data which would take time. So because of the gradient of difficulty-of-self-improvement, it will not all happen at once.
Finally, maybe this is controversial but ultimately progress in science is bottlenecked by real-world experiments. Some may believe that reading all biology papers would tell us the cure for cancer, or that reading all ML papers and mastering all of math would allow you to train GPT-10 perfectly. If this were the case, then the people who read the most papers and studied the most theory would be the best AI researchers. But what really happened is that AI (and many other fields) became dominated by ruthlessly empirical researchers, which reflects how much progress is based on real-world experiments rather than raw intelligence. So my point is, although a super smart agent might design 2x or even 5x better experiments than our best human researchers, at the end of the day they still have to wait for experiments to run, which would be an acceleration but not a fast takeoff.
In summary there are many bottlenecks for progress, not just raw intelligence or a self-improvement system. AI will solve many domains but each domain has its own rate of progress. And even the highest intelligence will still require experiments in the real world. So it will be an acceleration and not a fast takeoff, thank you for reading my rant
85
164
1,371
387,092
29 Jun 2025
The most rewarding thing about working in the office on nights and weekends is not the actual work you get done, but the spontaneous conversations with other people who are always working. They’re the people who tend to do big things and will become your most successful friends
31
29
806
93,557
28 Jun 2025
I would say that we are undoubtedly at AGI when AI can create a real, living unicorn. And no I don’t mean a $1B company you nerds, I mean a literal pink horse with a spiral horn. A paragon of scientific advancement in genetic engineering and cell programming. The stuff of childhood dreams. Dare I say it will happen in our lifetimes
80
43
733
103,433
27 Jun 2025
The greatest contribution of human language is bootstrapping language model training
11
7
184
32,163
24 Jun 2025
AI research is strange in that you spend a massive amount of compute on experiments to learn simple ideas that can be expressed in just a few sentences. Literally things like “training on A generalizes if you add B”, “X is a good way to design rewards”, or “the fact that method M is sample efficient means that we should create environments with this specific property”. But somehow if you find the correct five ideas and you really understand them deeply, suddenly you’re miles ahead of the rest of the field
26
37
596
68,639
21 Jun 2025
My favorite thing an old OpenAI buddy of mine told me is, whenever he hears that someone is a “great AI researcher”, he just directly spends 5 minutes looking at that person‘s PRs and wandb runs. People can do all kinds of politics and optical shenanigans, but at the end of the day code and experiments don't lie. I checked out some of the diehard AI researchers and there are very few days where they haven’t launched an experiment
36
63
987
239,746
18 Jun 2025
One way of thinking about what AI will automate first is via the “description-execution gap”: how much harder is it to describe the task than to actually do it?
Tasks with large description-execution gaps will be ripe for automation because it’s easy to create training data and the value of automating them is huge, even if execution is non-trivial:
- Fixing grammar mistakes in a long piece of writing
- Submitting receipts for reimbursement
- Training a model that achieves performance of X on a standard evaluation benchmark
- Building an app where the UI is easy to check but requires a lot of moving parts in the backend
Description-execution gaps tend to be small when the task is high-context and not technically challenging. The value of automating these is by definition smaller, and it’s harder to create data for them. For example:
- Data processing scripts where the code to process the data is shorter and more precise than a natural language description
- Running an ablation study in a high-context codebase that trains specialized models
- Editing a video in a specific style (often easier to edit the video yourself than to describe how each little edit should be done)
- Buying chinese groceries for my mom (she has very specific items and amounts, it's easier for her to go herself than to describe to me exactly the item, how to select the best fruit, etc)
A bit similar to the discriminator-generator gap, but not exactly the same. Some things, like editing a video in a specific style, can have a large discriminator-generator gap but small description-execution gap
18
46
387
77,208
11 Jun 2025
RL environment specs are among the most consequential things we can write as AI researchers. A relatively short spec (e.g., <1000 words of instructions saying what problems to create and how to grade them) often gets expanded either by humans or via synthetic methods into thousands of datapoints. Just one sentence in the spec can be the difference between a perfect post-trained model versus one with crazy hacking. Specs are also typically a product of a large amount of compute, where each training run allows us to iterate on the spec to patch reward hacking and get the nuances of model behavior just right. Writing a good spec requires context and taste and I don’t think AI can automate this just yet
13
31
434
51,852
7 Jun 2025
It’s actually a good thing these days to have subtle grammar errors in your writing. It sprinkles on a clear human touch. You never want your reader questioning if what they’re reading was written or edited by chatgtp
67
11
403
60,685
6 Jun 2025
Was attending a talk in a big lecture hall and the guy in front of me had the craziest conversation with ChatGPT for the whole hour about how to get his girlfriend back. Dozens of messages of pasting screenshots of text conversations to analyze tone of responses; whether to include an exclamation point to whether a smiley face was appropriately flirty. Apparently his ex-GF was talking to another guy in her lab and too stressed with work to give him attention, but also let him borrow her car, so he was getting mixed signals. Random stranger next to me was also spectating and found it so funny he literally cracked up in the middle of the talk. Convo ended with ChatGPT saying “you just had sex last week so youre no second class citizen.” Weirdest mix of pity, fascination, and awe I’ve ever felt
15
8
416
50,702
2 Jun 2025
There are traditionally two types of research: problem-driven research and method-driven research. As we’ve seen with large language models and now AlphaEvolve, it should be very clear now that total method-driven research is a huge opportunity.
Problem-driven research is nice because you have a consistent and specific goal. The goal is usually virtuous, so it feels good to have a mission and identity. However, it just doesn’t work due to The Bitter Lesson. Basically everything in classical NLP (machine translation, summarization, chatbots) lost to simple scaling. ChatGPT is a prime example—it used nothing from chatbot research and certainly wasn’t the intended end goal of OpenAI’s 2022 research program, but was a huge hit because someone (John Schulman et al) figured out the right way to package large language models as a product.
Method-driven research feels less stable because you’re constantly searching for problems and you have to be opportunistic. But I believe AI will allow method-driven research to dominate progress in most fields of science, one-by-one. The latest method (or “hammer”), as we’ve seen in AlphaEvolve, is ruthless search and optimization against a reward function (whether this requires RL or not is a separate discussion). Things that problem-driven researchers have been trying to solve for a long time like the kissing number problem will become nails hit by the hammer. Eventually the hammer will become bigger, stronger, and more general and will hit more and more nails.
So a very important meta-skill for the next decade will be knowing how to create the right environments to use The Hammer. Ironically, the problem-driven researchers, who by definition are experts in a specific problem, are well-positioned to create these environments. If, that is, they can put down their egos and pick up the hammer.
22
91
711
78,411
5 Jun 2025
OK as someone pointed out ChatGPT using nothing from chatbot research isn't totally accurate. What I meant to say is that much of chatbot research that was mainstream at some point in time (e.g., dialogue state tracking, or slot filling, or semantic parsing) wasn't used in ChatGPT
4
3
24
13,477