
PhD student at @BoulderNLP @lecslab. LLMs for rare languages, automata, synthetic data
Joined November 2018
- Tweets 1,676
- Following 325
- Followers 249
- Likes 102,868
84 Photos and videos










Jun 8
In low-resource languages, speculative decoding may actually be hurting performance!
1/n
1
2
108
Jun 8
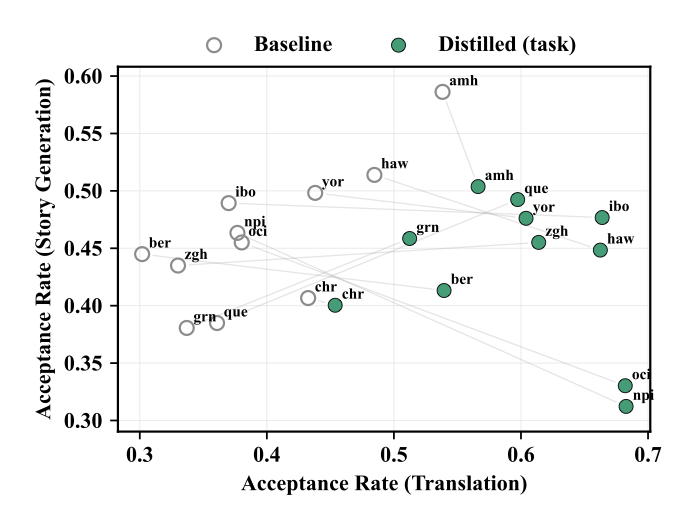
Distillation is a common way to improve acceptance rates, but we find that distillation on one task (translation) tends to generalize poorly to another task (story generation) in the language
3/n
1
1
48
Jun 8
So what should we do instead? It turns out the simple n-gram models might be a better choice, thanks to incredibly fast inference speeds.
Sometimes, simpler is better!
4/n
20
michael retweeted

Jun 8
the God Model is a useful theoretical construct akin to a Worst-Case Adversary or a Busy Beaver Program or an NP Oracle, less compelling as a target to seek than as a foil for designing minimax programs which can be tangibly realized
2
3
59
8,170
May 17
If you don’t think LLMs hallucinate anymore, try asking any remotely niche question about Logic Pro
1
126
michael retweeted

May 5
DPO is substantially more similar to SFT than it is to RL. I will die on this hill.
31
12
404
35,925
Apr 21
1. Workshop lowers publication standards
2. Quality of papers goes down
3. Workshop reputation goes down
4. Next workshop gets less submissions
5. Workshop lowers publication standards
....
2
1
442
Apr 16
Most cringe *so far*
Apr 15

the most cringe thing that has happened to applied ai is the openclaw hype
1
249
Apr 15
Profoundly embarrassing stuff

Introducing ABG CMO.
If your CMO isn’t an ABG, you’re already losing
Try now at abgcmo.com
1
160
michael retweeted

Apr 13
not having to type is really nice, but i think i want to go back to manually writing the code myself and more leveraging LLMs for research and understanding of the codebase
it's just too easy to defer you thinking today and end up in a bad state
Apr 13

from my experience, even the best models (Opus 4.6, 5.4 xhigh / 5.3 codex) cannot write good code today without an amount of work that is equivalent to just doing the work myself
am excited for a world where they can, but in the current state i have very low trust in them
53
39
890
55,674
michael retweeted

Apr 6
Really excited about this work w/ my long-time collaborators at Boulder!
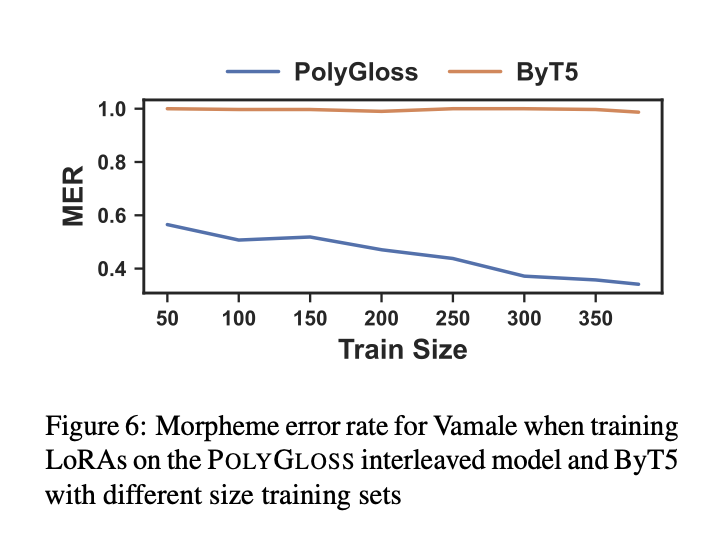
We address limitations in existing morphosyntactic annotation systems for digitally under-resourced languages and show how *jointly* predicting morphological segmentation helps with glossing performance
Apr 6

Excited to announce that the PolyGloss paper has been accepted to @aclmeeting!
Previously, we trained models to help in endangered language documentation workflows by automatically predicting interlinear glosses. But real-world user studies revealed crucial issues...
2
31
2,379
Apr 6
Excited to announce that the PolyGloss paper has been accepted to @aclmeeting!
Previously, we trained models to help in endangered language documentation workflows by automatically predicting interlinear glosses. But real-world user studies revealed crucial issues...
2
6
26
3,664
Apr 6
Check it out here: arxiv.org/pdf/2601.10925
This work is the result of an ongoing collaboration between @lecslab and @LTIatCMU. Many thanks to my collaborators including @lexicutioner @lltjuatja @gneubig, and others!
1
1
110
Apr 6
The models are available right now on HuggingFace! See usage instructions on our GitHub: github.com/lecs-lab/polyglos…
1
104
Apr 6
Excited to announce my work on learning FSTs with RNNs has been accepted to ACL Findings! @aclmeeting
Jan 20
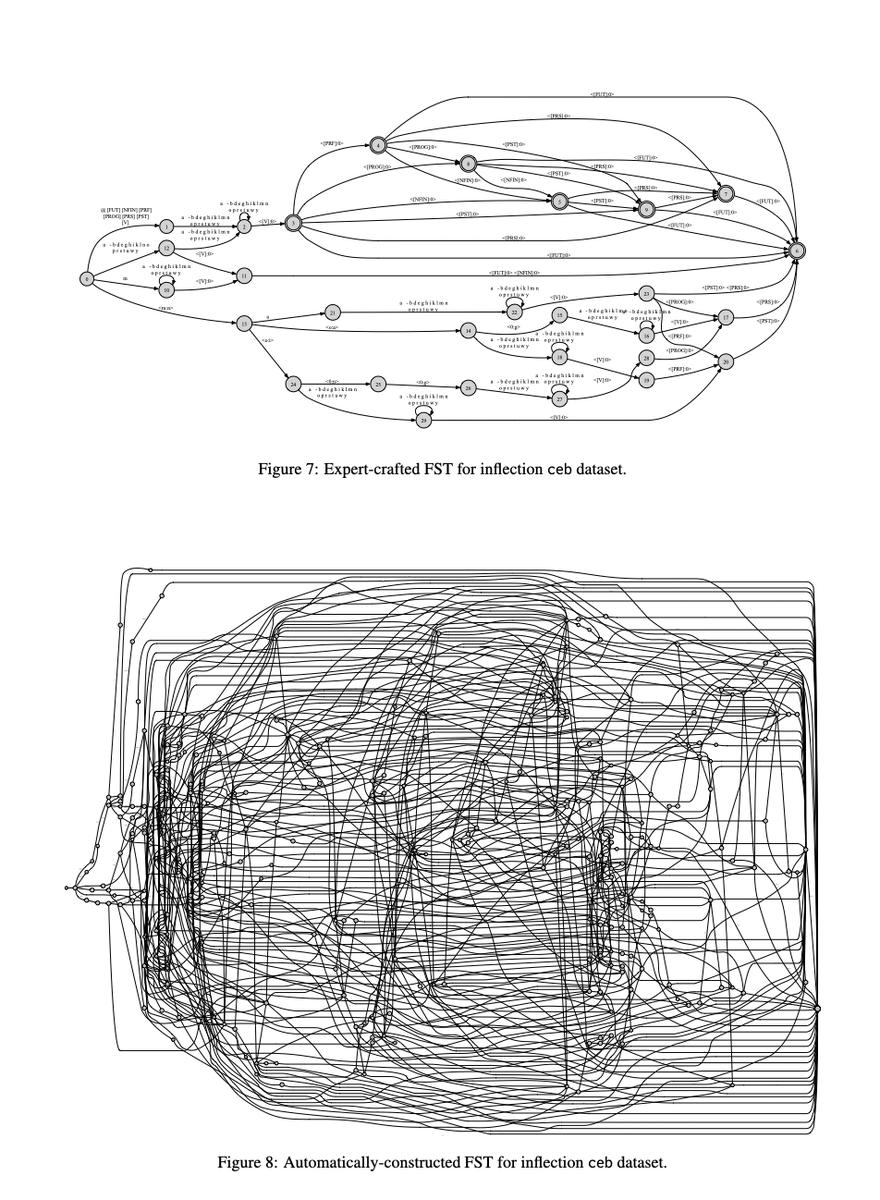
(1) Learning transducers from data has been an open problem for decades.
In a new paper with @lecslab, we present a highly effective approach that learns FSTs by imitating the hidden-state geometry of an RNN.
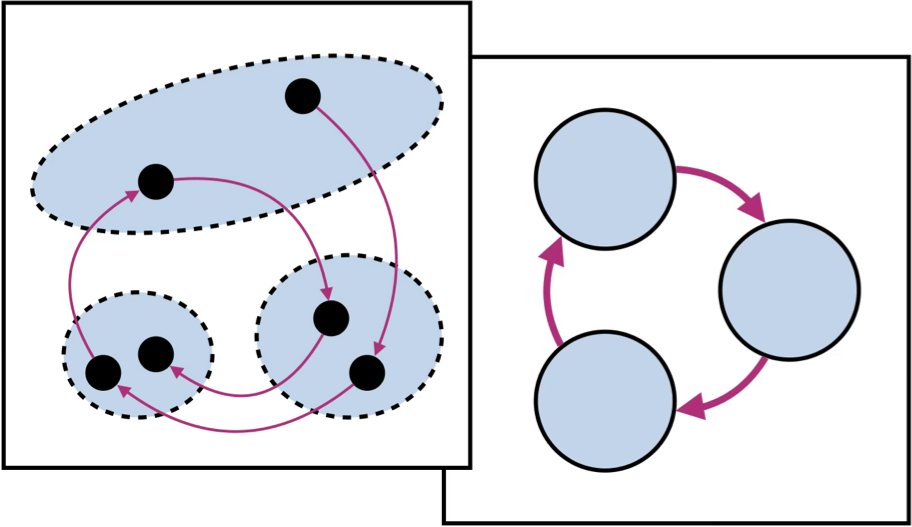
2
15
980