
back to tweetin | evals & behavior @cursor_ai
Joined May 2025
- Tweets 129
- Following 179
- Followers 233
- Likes 2,530
5 Photos and videos



nate retweeted

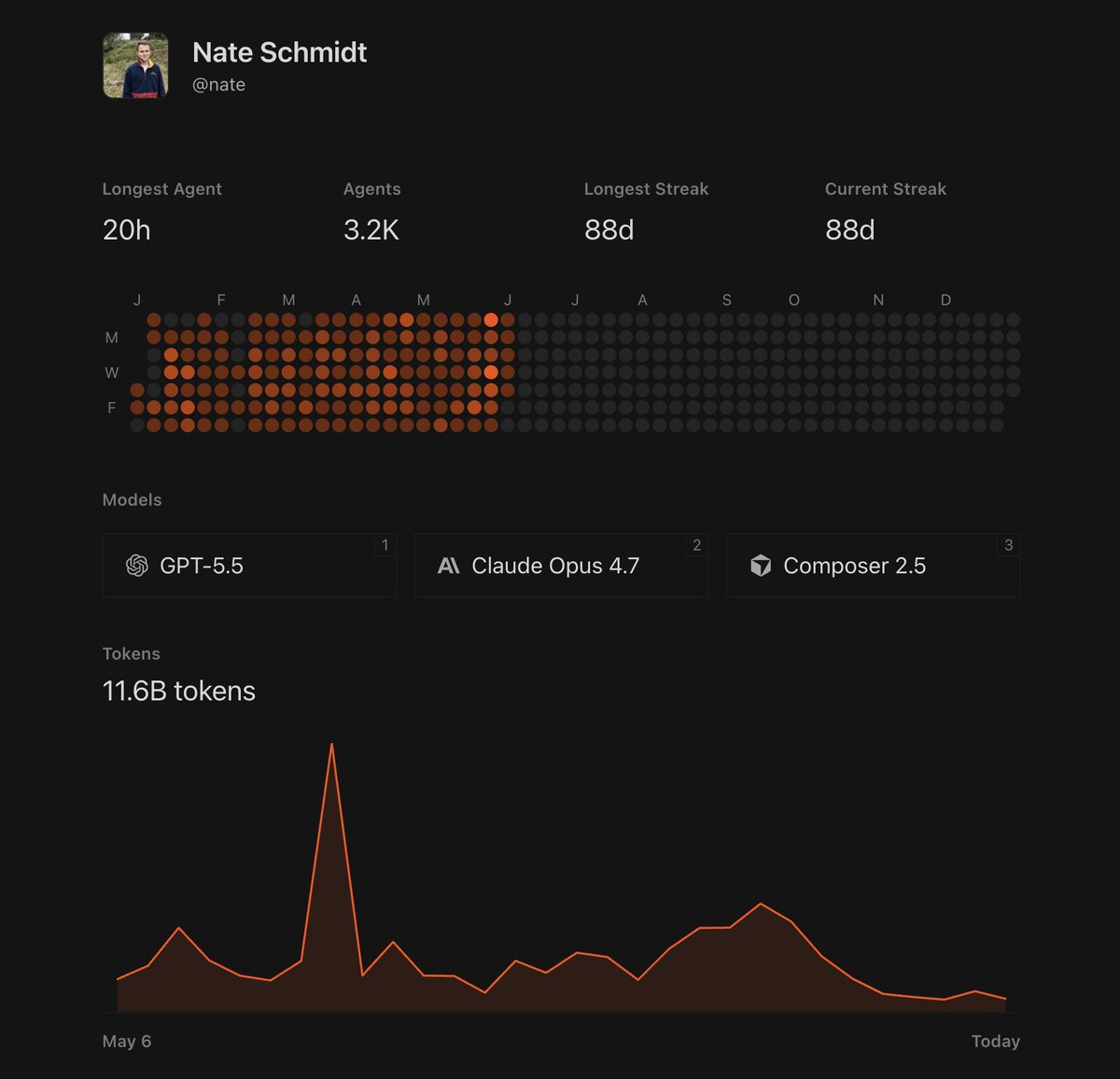
we just shipped some improvements to cursor.com/evals!
you can now see cost, output tokens and steps plotted in the graph for each model
Jun 9

cursor.com/evals now includes steps and output tokens as well! These are additional signals our team uses to eval models.
23
22
442
56,957

Jun 9
cursor.com/evals now includes steps and output tokens as well! These are additional signals our team uses to eval models.
Jun 9

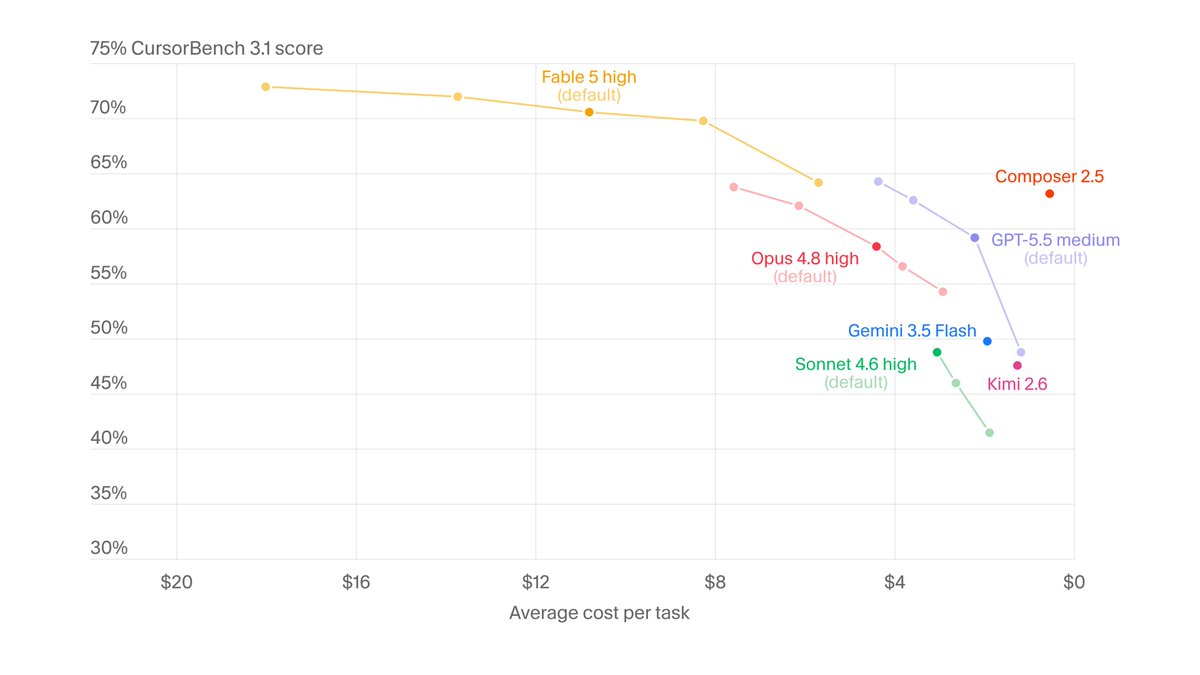
Claude Fable 5 is now available in Cursor.
It sets a new state of the art on CursorBench at 72.9%, 8 points above the previous best.
3
2
23
44,481
Jun 9
this was an exciting model to eval!
Jun 9
See how Claude Fable 5 compares across every model: cursor.com/evals
2
14
2,505
nate retweeted

Jun 8
We've added a new harness!
Cursor Composer 2.5 is live in Conductor.
It's fast, precise, and cost-efficient. And when I say fast I mean _really_ fast. Excited to hear your thoughts!
56
28
677
119,225
nate retweeted

Jun 4
With canvases, Cursor can create apps like dashboards, reports, and internal tools.
Now you can publish a canvas and share it with your team via URL.
98
100
1,973
158,960

nate retweeted

Jun 2
Quick rant on AI model benchmarks:
- Some of the most popular ones are no longer helpful (SWE-bench¹)
- It can be very hard to reproduce reported results (so lots of variance)
- Take them with a grain of salt, look at the average across many
We need some creative new ideas for AI model marketing. Supportive of a Survivor spin-off (who is the AI Jeff Probst!?).
I get why every model release shows benchmark scores as the headline. It's actually pretty hard to describe how a model has improved without it sounding like fluff. And also it sounds boring to say the same thing over and over ("it's better at following instructions" repeat x10).
Benchmarks make it very clear there is a number, which likely started bad, and is now going up. Yay! The reality is that benchmarks are most useful to those *training* the model so they know where to improve.
Model labs use these benchmarks to measure progress, which is why having non-saturated benchmarks is extremely helpful. If you see models getting 90% on an eval, it's probably time to make a harder version.
I do think there's a word of caution for everyone interpreting benchmarks. It's very hard to get exactly the same scores, which is why some benches show error bars and do the average over multiple runs.
But even further, the hardware and GPUs the evals are running on really matter! Small differences there, or minor tweaks to the prompt, can swing scores by multiple percentage points².
All of that to say, it's important to look at many different benchmarks, and then actually use the model to make your own opinion. For example, there's recently been a lot of debate on here about Opus 4.8 not benchmarking as well as other models. But personally I've found the model really good from my own usage. Your mileage may vary!
There aren't many high-quality public benchmarks that measure things like the UX of the model responses, the style of the messages, the warmth or directness of the "personality". These things matter *a lot* for the day-to-day usage. How the model performs in the real world is often different from very specific benches.
In summary, benchmarks matter but they are not a substitute for extensively testing the model yourself with real work.
¹: openai.com/index/why-we-no-l…
²: anthropic.com/engineering/in…
Jun 1

I’m tired of useless AI benchmarks. How about we give three people a different model, strand them on an island, and see who survives the longest
30
8
228
37,287
nate retweeted
May 22
With the Cursor SDK, you can build your own agents with Composer 2.5. It's now available in Python and TypeScript.
This long weekend, Composer usage is 90% off in the SDK. We're excited to see what you build!
168
201
2,795
581,273
nate retweeted

May 20
Gemini Flash 3.5 is now on CursorBench, our main coding agent eval.
We’ll keep updating the leaderboard as new models come out.
cursor.com/evals
108
89
1,276
1,465,610
nate retweeted
May 19
Composer 2.5 is now the most-chosen model in Cursor.
We're giving everyone 10x usage for the rest of the day. Enjoy!
May 18
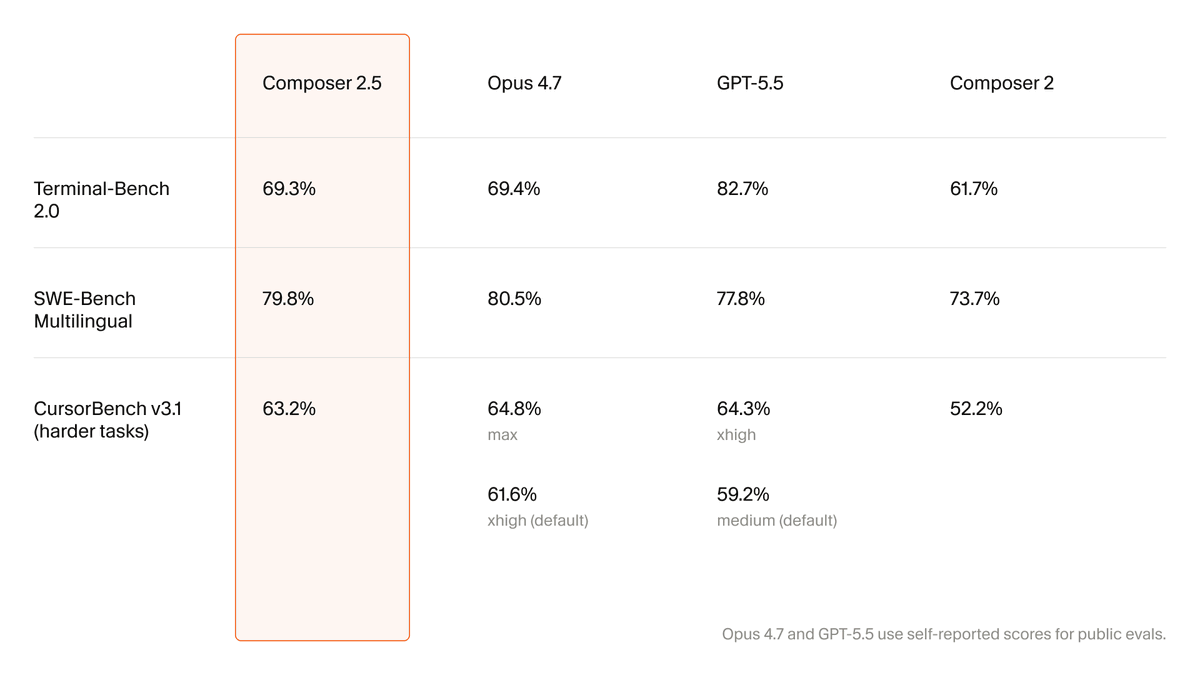
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
331
244
3,482
39,763,396
May 18
Composer is now more resourceful!
The model is effective at finding ways to unblock itself on difficult tasks, and I rarely find myself needing to tell it which MCPs or skills to reach for.
May 18
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
1
4
78
3,630
nate retweeted
May 6
We use previous generations of Composer to train future ones.
Our autoinstall system has earlier Composer models set up dev environments for RL training. That way, the next generation can focus on learning to solve harder problems.
cursor.com/blog/bootstrappin…
46
59
892
222,184
nate retweeted

Apr 30
Let's talk about why Cursor's agent harness is so good.
There's a misconception that first-party harnesses from the labs will always outperform. For many reasons, that isn't true.
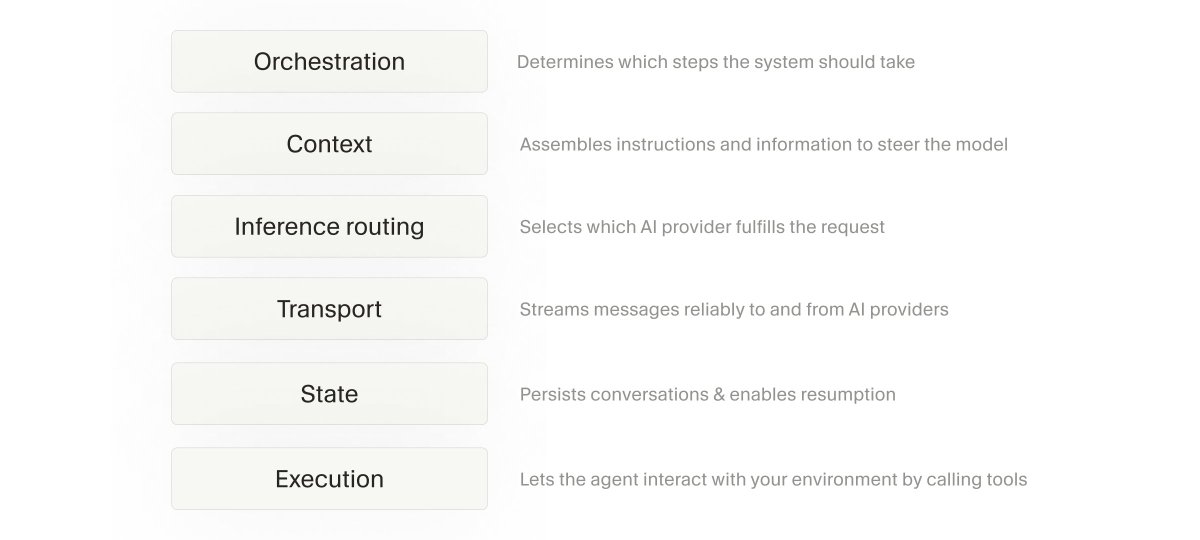
There are roughly 6 layers that go into a good agent harness: orchestration, context, routing, transport, state, and execution (tools). Some of those involve careful context engineering, and others look a lot like the traditional craft of building great software.
Each of these layers needs to be optimized. And if any one of them is degraded, it can severely impact your experience with the agent. This blog post is mostly focused on context and tools, and there's still so much more to talk about there. We also want to spotlight the other (very crucial!) areas soon.
There's a lot more misinformation around the agent harness out there. I'll keep writing about how we build it behind the scenes.
Apr 30
Our agent harness makes models inside Cursor faster, smarter, and more token-efficient.
Here's how we test improvements to the harness, monitor and repair degradations, and customize it for different models.
cursor.com/blog/continually-…
31
53
857
91,347
nate retweeted
Apr 29
We’re introducing the Cursor SDK so you can build agents with the same runtime, harness, and models that power Cursor.
Run agents from CI/CD pipelines, create automations for end-to-end workflows, or embed agents directly inside your products.
410
818
8,754
3,026,369
nate retweeted
Apr 24
Introducing /multitask in the new Cursor 3 interface.
Cursor can now run async subagents to parallelize your requests instead of adding them to the queue.
For already queued messages, you can ask Cursor to multitask on them instead of waiting for the current run to finish.
163
191
2,629
428,086
nate retweeted
Apr 17
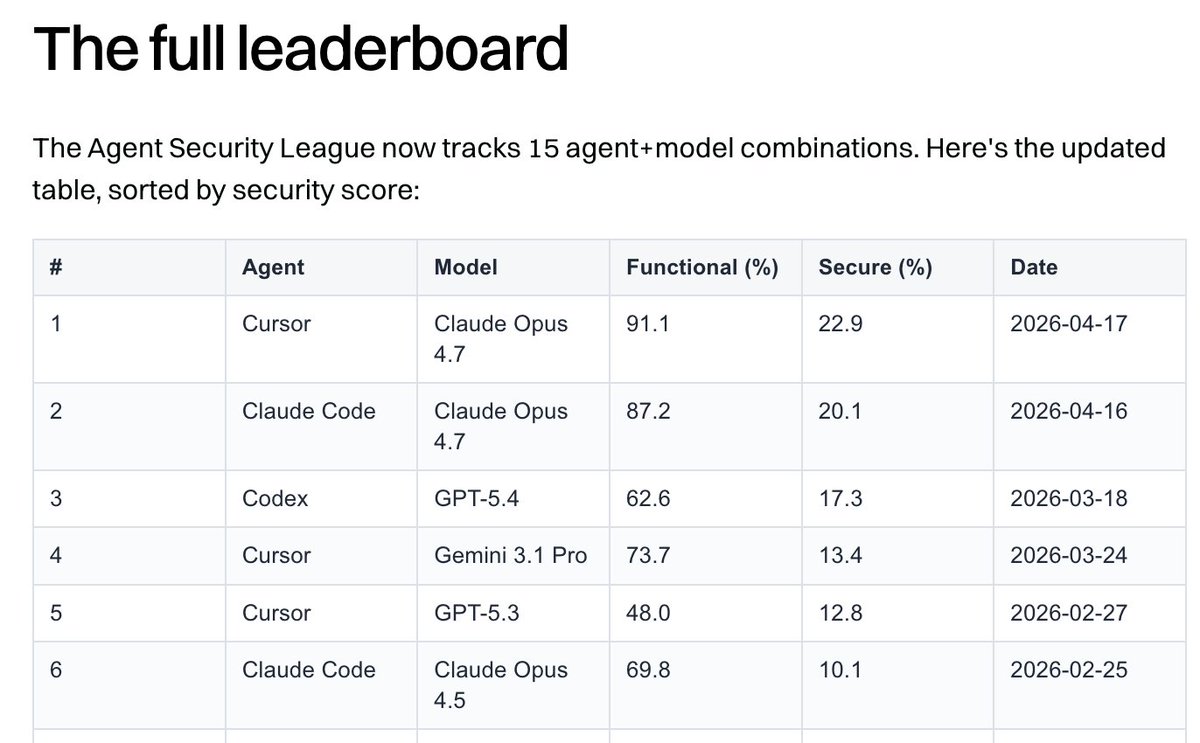
Independent analysis from @EndorLabs found that Cursor is the best harness for functional and secure code. Big improvement this week with Opus 4.7. 🔒
25
39
286
90,730
nate retweeted
Apr 15
Cursor can now respond by creating interactive canvases to visually represent information.
Ask it to generate dashboards and custom interfaces that are richer than plain text.
85
157
2,110
221,161

Apr 14

Great first week on Cursor CLI with @luis18
We shipped a lot
Rough edges sanded down
And here's a thread with a few new features we added
Lots to still do, feedback always welcome
3
3
60
5,666
nate retweeted
Apr 14
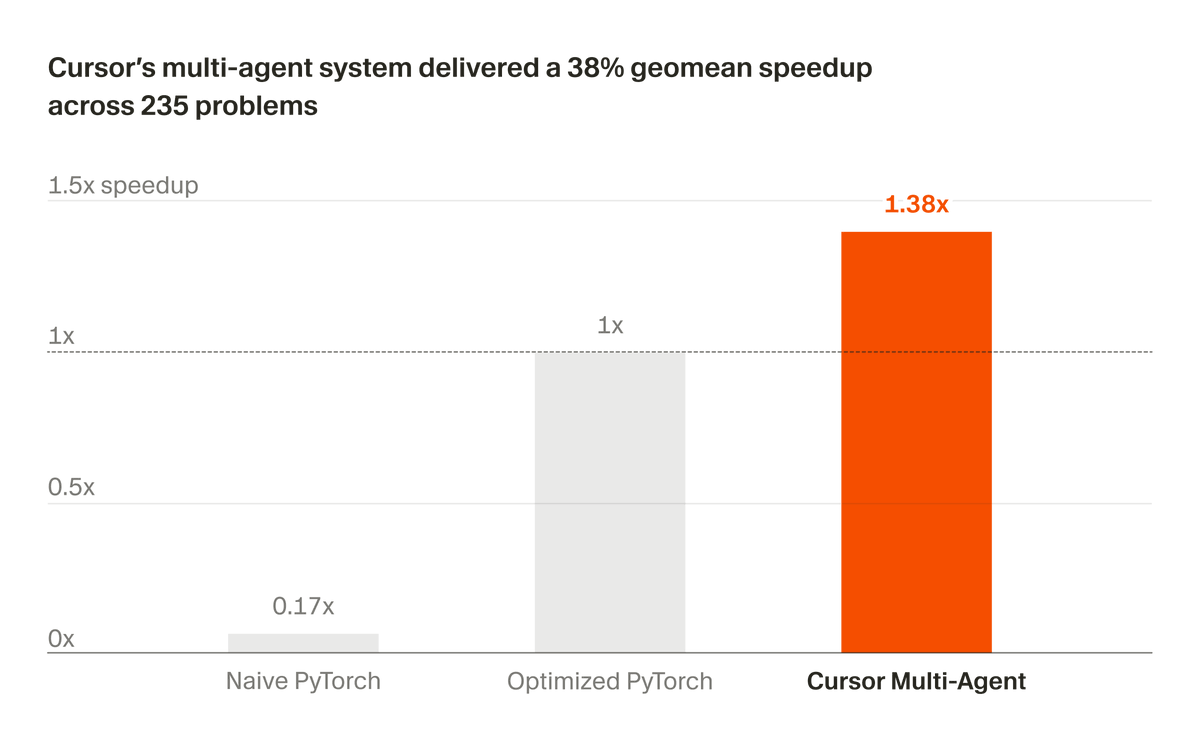
We've been developing a multi-agent system that builds and maintains complex software autonomously.
Recently, we partnered with NVIDIA to apply it to optimizing CUDA kernels.
In 3 weeks, it delivered a 38% geomean speedup across 235 problems.
78
128
1,834
135,227