
Assistant Professor @ NTUsg
Joined March 2011
- Tweets 21
- Following 147
- Followers 288
- Likes 155
1 Photos and videos


Happy to share that the @GoogleDeepMind Gemini team is starting a new research team in Singapore!
This new team will be focused on advanced reasoning, LLM/RL and improving bleeding edge SOTA models such as Gemini, Gemini Deep Think and beyond. 🔥
This team will be led by yours truly and reports up to Quoc Le (@quocleix)'s broader team in Mountain View which was recently in the center of both IMO gold medal and ICPC gold medal breakthroughs with Gemini Deep Think, amongst many other significant Gemini advancements. 🚀
We’re starting out with a very small but intensely capable force because talent density is key over anything else in the LLM era. Over the past few months, we have gone around and gathered the best of the best talent (in the region and beyond) and I’m confident we’ll have a super cracked team very soon.
If you are interested in joining and have made truly exceptional contributions in any domain or area, (engineering and/or research etc) please contact me.
This is quite an exciting time, with the Gemini / GenAI team at Google Deepmind leading the charge at the frontier. This is also the best opportunity to be on the critical path to AGI from the sunny island of Singapore. 🏝️
Many thanks to leadership support from @quocleix @JeffDean @benoitschilling, @EugenieRives and @demishassabis for the support of this team.
Wonderful and fun image generated by Nano Banana 👇

42
96
971
320,554

9 Sep 2025
Let the post-training of SG begin!

Had a really wonderful time hosting @JeffDean, @quocleix, @benoitschilling and @denny_zhou in Singapore for the @GoogleDeepMind Gemini Singapore 🇸🇬 event last week! 🔥
The event went super well imo, the vibes were on-point and an overwhelming number of people told me directly they were moved and very inspired! 😁
Moreover, the consensus amongst GDM speakers was also that the level of questions from the community were solid and reassuring that something good is going on here. Basically, signal to noise ratio was generally pretty good.
As I also said in my opening remarks, I think Singapore has a lot of raw pure talent, but today it is physically and spiritually far away from the true AI frontier for a myriad of reasons. Hence, increasing "frontier awareness" and "aura diffusion" (aka ecosystem building 😂) was something particularly high ROI (for us too!)
The way I see it is that SG is like a reasonably strong base pretrained model that hasn't been properly post-trained yet. It feels like the gears have started turn though, hopefully we'll make it happen. 🤞
We also had a lot of fun roaming SG. Visiting gardens by the bay on day-0, having 2-michelin star "tarvar" as the finale dinner, pickleball with Jeff on top of a random building, spotting anteaters at the night safari and last but not least, chatting with senior minister Lee Hsien Loong and visiting the Istana.
Was an epic week! 😁
More details of the 3/9/2025 event in the thread below 👇


4
1,420
Excited to share that I'll be hosting some of the world's best AI researchers and engineers for our @GoogleDeepMind Gemini event next week in Singapore 🇸🇬!
Join @JeffDean, @quocleix, @benoitschilling, @melvinjohnsonp and @denny_zhou for a day of technical conversations, panels and talks about AI, reasoning and our mission to build a world class AI frontier lab in Singapore.
If you're in town and would like to attend, please check the RSVP link below👇. Note, subject to capacity constraints and you'll need to be approved to join.

19
38
337
112,783
Alvin Chan retweeted

1 May 2024
Evals are notoriously difficult to get right but necessary to move the field forward. 🌟
As part of our commitment to science, we’re releasing a subset of our internal evals. 🙌
Vibe-Eval is an open and hard benchmark comprising 269 image-text prompts for measuring the progress of multimodal chat models.
Vibe-Eval has two goals:
🔹vibe-checking existing models on day to day tasks 🔹deeply probing into the capabilities of frontier models
These very difficult prompts were constructed by AI experts (us 🤭) with the intention to deliberately find examples where our model (Reka Core) is unable to solve.
On 50% of the prompts in the hard set, none of the existing models (including frontiers) can fully solve. 😲.
We benchmark 13 representative multimodal models using both human evaluation and automatic evaluation.
We also share our findings and insights about the challenges of curating and evaluating hard prompts.
Check out our paper and resources below ⬇️

7
37
182
106,179
Our @RekaAILabs Tech Report / Paper is out! 🔥
Tech reports with completely no information are kinda boring so we’re revealing some interesting information on how we train our series of Reka models including tokens, architecture, data & human evaluation workflows. 😃
We tried our best to give a behind-the-scenes experience 😊. In particular, if you enjoyed my previous blog post about training LLMs in the wilderness, there’s a dedicated section on that in this report! 🌴
We can’t disclose literally everything but we tried our best to make it interesting, I promise. 🙏
Here’s a rundown summary of some of the highlights.
🔹Edge and Flash are outrageously strong 7B and 21B models. They are trained on 4.5-5T tokens in total. Also, they have been improved significantly since their first public appearance! They outperform many popular faces. Some data mixture information is in the report.
🔹We discuss our internal human evaluation workflow, prompt distribution, and how we use Core for model development and automatic evaluation.
🔹We describe our infrastructure setup for training large models, quantifying node failures, and report loss curves for training our models.
🔹Aside from the hardware lottery, we also show how this affects node stability across time. Once we were told our cluster became less stable because there were "big guys" moving things around the data center. 😅
On performance which you might have already seen on other threads.
🔹Core approaches frontier-class models like Claude3 Opus and GPT4-V. It outperforms Claude3 Opus on third-party blind human evaluation for multimodal chat, outperforms Gemini Ultra on video QA, and is quite competitive to other frontier models on core text metrics. It also matches GPT4-V on MMMU!
🔹Core ranks #2 on our internal multimodal chat leaderboard, right after GPT4-V. On text, it ranks #3 just behind Claude Opus and GPT4 Turbo. Core outperforms GPT-4 (0613) on this ranking.
This has been a focused and concentrated effort of a small team of ~20 people in the past 4 months (yes, we got access to 90% of our compute only late December last year! 🚀).
This tech report tells our story. Enjoy! Happy to answer any questions in replies or DM!
PS: it was nice writing in latex after one whole year!
PPS: I had quite some fun writing this 😊. There's some puns and easter eggs and interesting tidbits in there. Trust me. 😏
Link: publications.reka.ai/reka-co…

10
54
405
52,210
Didn't get much chance to share this yesterday with everything else going on with the Reka core launch but here's the most non-cherry picked showcase of Reka Core vs GPT-4 vs Claude Opus on multimodal chat tasks. 👇
We put together this showcase with examples our team created. How's it not cherry picked?
Our team just manually crowdsourced some prompts and examples, ran all 3 models, and load them on this simple website UI. I didn't even look at most of these.
You can get the sense of how all 3 models perform on multimodal chat from this site.
link: showcase.reka.ai/


5
10
80
19,181
Alvin Chan retweeted
15 Apr 2024
Meet Reka Core, our best and most capable multimodal language model yet. 🔮
It’s been a busy few months training this model and we are glad to finally ship it! 💪
Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body trailer.👇
49
232
1,126
757,865
22 Mar 2024
*Fully funded PhD position opening @NTUsg *💥 I have two openings for Ph.D. students to work on Deep Learning for Drug Discovery and Multi-Modal Large Language Models in Medicine.
Apply here 👉🏽 linkedin.com/jobs/view/38674…
Thanks for sharing!
2
10
15
8,007
We are excited to share Reka Flash ✨, a new state-of-the-art 21B multimodal model that rivals Gemini Pro and GPT 3.5 on key language & vision benchmarks 📈.
We've trained this model from scratch and ground zero with a small (but amazingly capable team 🧙♂️) and relatively finite resources. We're amazed at how strong it is 🦾. I'm proud of our financially optimal LLM team.
Abandoning one's comfort zone is surely difficult and having to redo things from scratch is often scary & daunting. Many things in the wilderness don't work from the get go and it was often a huge pain in the neck 😢.
I should write a separate post someday of how much we have we've had to rebuilt (and suffered 🤣). Everything from robust training infra, proper (human) evaluation pipelines and proper RLHF setups. I am thankful of the crazy talented team we have here ☺️.
Meanwhile, our largest most capable model Reka-Core is finishing soon and we're already very excited by early results 📈. More to come very soon!
9 months in. Excited to be back at the frontier 🔥.
Check out our blogpost here: reka.ai/reka-flash-an-effici…
12 Feb 2024

Introducing Reka Flash, our efficient and highly capable multimodal language model.
Try it at Reka playground 🛝 for free today.
🧵 Thread, blog & links below 👇
51
71
551
153,029
Alvin Chan retweeted
3 Oct 2023
We are excited to announce the 1st version of our multimodal assistant, Yasa-1, a language assistant with visual and auditory sensors that can take actions via code execution 🪄.
Yasa-1 can understand text, images, videos, sounds & more! 🚀
Check out more details below👇
23
151
864
814,220
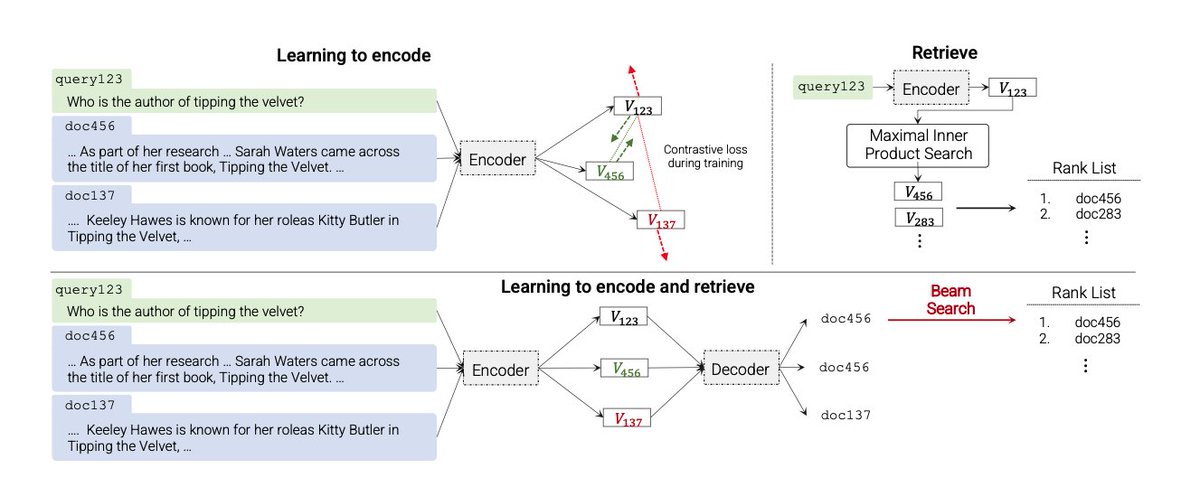
Excited to share our latest work at @GoogleAI on "Transformer Memory as a Differentiable Search Index"!
TL;DR? We parameterize a search system with only a single Transformer model 😎. Everything in the corpus is encoded in the model! 🙌
Paper: arxiv.org/abs/2202.06991
10
146
695
8 Jul 2021
We explore how AI can generate sequences across natural language and proteins with attributes that go beyond the training data. Thanks to @thisismadani, @benwkrause and @nikhil_ai for the wonderful internship experience in @SFResearch!
Find out more here: blog.einstein.ai/genhance
8 Jul 2021

Can generative AI learn to extrapolate? We explore how to generate sequences that enhance desired attributes-- beyond what was seen in training. Works pretty well in #NLP and #proteins!
Blog: blog.einstein.ai/genhance
Paper: arxiv.org/abs/2107.02968
Code: github.com/salesforce/genhan…
1
5
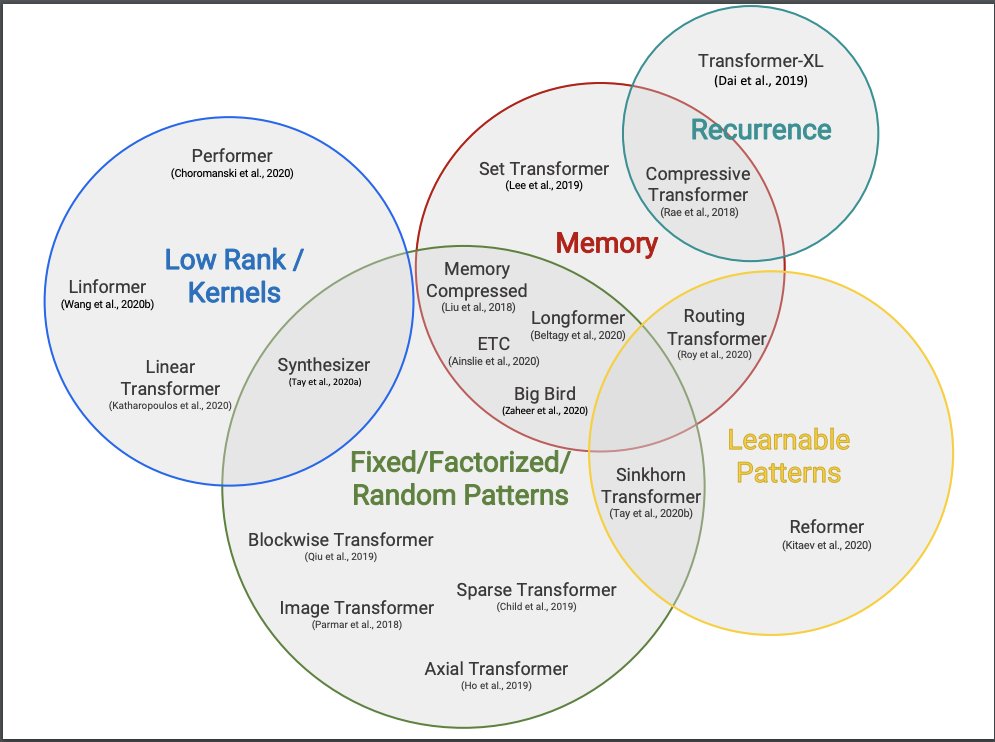
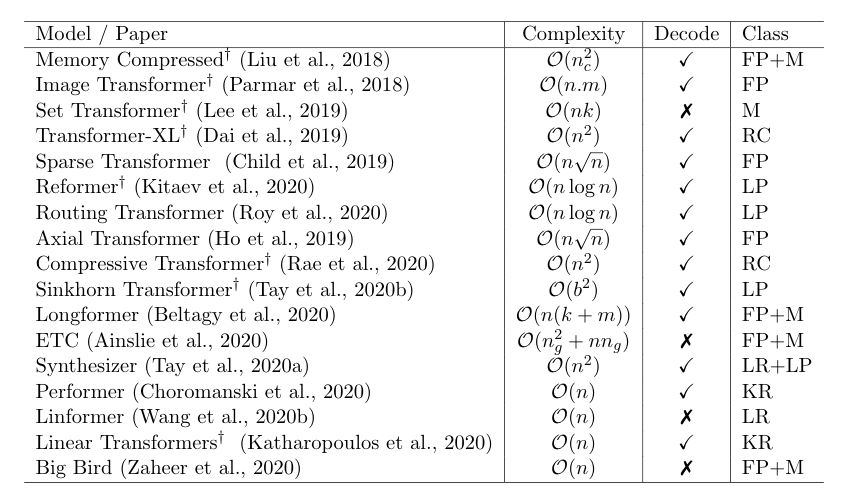
Inspired by the dizzying number of efficient Transformers ("x-formers") models that are coming out lately, we wrote a survey paper to organize all this information. Check it out at arxiv.org/abs/2009.06732.
Joint work with @m__dehghani @dara_bahri and @metzlerd. @GoogleAI 😀😃
16
255
848
Alvin Chan retweeted

8 Jul 2020
It is our pleasure to announce the Call for Papers for ICLR 2021. For the first time there will be an abstract submission (due September 28) before the full paper deadline (October 2).
For details see: iclr.cc/Conferences/2021/Cal…
Looking forward to many exciting submissions!
7
158
572
16 Jun 2020
Thrilled to share that our #CVPR2020 oral paper
“What It Thinks Is Important Is Important: Robustness Transfers Through Input Gradients”
will be live today at 10am/pm (PST time)!
Video: bit.ly/3e1rqAp
Paper: openaccess.thecvf.com/conten…
Code: bit.ly/3e9ICE2
3