
Joined June 2012
- Tweets 382
- Following 349
- Followers 1,009
- Likes 3,825
8 Photos and videos



May 15
Broadly agree that there is some pressure to go faster via agents and hope your tests are good enough to catch problems.
That said, I still have hope that the overall quality of software will go up with agents debugging, testing and fixing bugs. They are good at this.
May 15

I strongly believe there are entire companies right now under heavy AI psychosis and its impossible to have rational conversations about it with them. I can't name any specific people because they include personal friends I deeply respect, but I worry about how this plays out.
I lived through the great MTBF vs MTTR (mean-time-between-failure vs. mean-time-to-recovery) reckoning of infrastructure during the transition to cloud and cloud automation. All those arguments are rearing their ugly heads again but now its... the whole software development industry (maybe the whole world, really).
It's frightening, because the psychosis folks operate under an almost absolute "MTTR is all you need" mentality: "its fine to ship bugs because the agents will fix them so quickly and at a scale humans can't do!" We learned in infrastructure that MTTR is great but you can't yeet resilient systems entirely.
The main issue is I don't even know how to bring this up to people I know personally, because bringing this topic up leads to immediately dismissals like "no no, it has full test coverage" or "bug reports are going down" or something, which just don't paint the whole picture.
We already learned this lesson once in infrastructure: you can automate yourself into a very resilient catastrophe machine. Systems can appear healthy by local metrics while globally becoming incomprehensible. Bug reports can go down while latent risk explodes. Test coverage can rise while semantic understanding falls. Changes happens so fast that nobody notices the underlying architecture decaying.
I worry.
1
4
881
May 8
Agreed, shared storage (Aurora, AlloyDB, HorizonDB, Neon, etc.) is the dominate design for cloud OTLP. It's not the best in every scenario, but it is for most use cases. You can push a lot of work (replication, full page writes, dirty page writes, etc.) into the storage layer

There is a new era of data tech that is effectively "__ on object storage":
Turbopuffer is "vector search on object storage"
Warpstream is "kafka on object storage"
Neon is "Postgres on Object Storage" or “Postgres on S3”.
It doesn’t mean that every read and write goes directly to S3. That would be incredibly slow. I’m saying that a Postgres database in the "Postgres on object storage" category can be faster than one in the "Postgres on a cluster of servers with NVMe disks" category.
No one is claiming that S3 is faster than NVMe but Postgres on S3 (with low latency storage in between) can be faster than Postgres running on NVMe with HA on. HA is important here, without HA you don’t do durable writes so it would be an unfair comparison.
While neon runs on s3, calls into s3 are almost never on the transaction reads or writes. Writes are sent into a consensus service and streamed into s3 asynchronously. So the claim can be expanded to Postgres running on a disaggregated storage which implements low latency tier on top of s3 is faster then Postgres with HA running on NVMe.
We are not the only ones making this claim. For example AWS Aurora says "Aurora has 5x the throughput of MySQL and 3x of PostgreSQL with full PostgreSQL and MySQL compatibility."
So why does disaggregating compute allow for higher throughput on Postgres and potentially lower latency as well? The reason is that we can offload a number of CPU and IO operations down to storage. We just published a blog post on how we can turn off full page writes which dramatically reduces WAL volume and saves on CPU cycles on the Postgres node.
In many scenarios this may be a wash because for many workloads you might not be write throughout bound and therefore Postgres checkpoints and full page writes don’t impact overall throughput. However this is general purpose enough to impact a large swath of workloads. It’s also important to mention that scaling write throughput is more important since Postgres is a single write system and you can’t scale writes with read replicas.
So is Postgres on S3 faster than Postgres on NVMe? We believe it can and will be. Postgres with disaggregated storage and several kernel performance optimizations has higher throughput than stock Postgres on NVMe with HA implemented via sync replication.
We'll share more including latency impact as we gather insights after rollout. Lots of things to learn here if saving CPU on full page writes can have a material impact on latency under high throughput. The idea is that if CPU is all used up, freeing up some CPU will impact both latency and throughput - but we'll see!
The statement is indeed provocative, but far from “shock value marketing” as some of the responses claim.
2
1
35
6,230
May 8
This approach gives you more CPU to run your workload.
I talked about this in more detail recently in Andy's CMU tech talk series. HorizonDB uses Azure blob store as its durable storage (same design as the Socrates paper)
youtu.be/EdgeqeW47_w?si=wkn-… via @YouTube
8
572
May 8
If I had known database twitter was going to blow up about NVMe vs blob store for OLTP today, we would have hit on that in a little more detail! Still, if you're interested in a career working on databases hopefully this podcast will be of some interest to you.

🎙️ New #TalkingPostgres podcast Ep39 is out!
@a_prout, distinguished engineer at Microsoft, talked about his engineering journey from MemSQL to HorizonDB, shared-storage, & why good systems programmers are paranoid
🎧 talkingpostgres.com/episodes…
📺 youtu.be/L_2kyfL9LN0?si=6o5o…

ALT Smiling headshot of engineer Adam Prout wearing glasses, along with his name in big letters and the podcast thumbnail graphic for Talking Postgres
1
2
30
3,003
Adam Prout retweeted

🎙️ New #TalkingPostgres podcast Ep39 is out!
@a_prout, distinguished engineer at Microsoft, talked about his engineering journey from MemSQL to HorizonDB, shared-storage, & why good systems programmers are paranoid
🎧 talkingpostgres.com/episodes…
📺 youtu.be/L_2kyfL9LN0?si=6o5o…
ALT Smiling headshot of engineer Adam Prout wearing glasses, along with his name in big letters and the podcast thumbnail graphic for Talking Postgres
1
2
7
3,244
May 6
If you're interested in:
- how databases (and database services) are built
- how building a database service at a startup compares to doing it at big tech
- how Postgres vs MySQL vs SQL Server are different/same (I've work on/around all three!)
come check this out!
Looking forward to talking to database architect Adam Prout @a_prout today/Wed 6 May at 10am PDT on the #TalkingPostgres podcast!
Ep39 topic: From MemSQL to HorizonDB, an engineer's journey
Where? Live on the Microsoft Open Source Discord. Join us: aka.ms/talkingpostgres-ep39-…

ALT Smiling headshots of guest Adam Prout and host Claire Giordano for Ep39 of Talking Postgres, along with the topic "From MemSQL to HorizonDB, an engineer's journey"
4
413
Apr 28
Agents are great testers and bug fixers if focused on this work. For code bases with a high quality bar (databases) and massive test suites, agents root causing bugs and proposing fixes is a big time saver. I hope they keep improving as testers!
medium.com/@adamprout/agents…
1
2
22
5,608
Adam Prout retweeted

Apr 24
It is personal now. I have a new archenemy. I was having a great time at @AntithesisHQ's conference (the lineup for this year is fantastic), but then @carlsverre ruined my day. I hate that guy now.
How? he told me about Hegel, and then I ended up spending the whole day fixing stuff. Carl might have saved me some 3 months of work. But he ruined my day.
Can I ever forgive him? Read more 👇
4
3
93
9,385
Feb 23
Representing team Postgres... I'll talk about some of the changes we've made to Azure (and to Postgres) to improve the performance/reliability/security of running PostgreSQL in the cloud.
Feb 23

Today's Postgres vs. World Seminar Speaker: Adam Prout (@a_prout) will present the architecture of the newly released Microsoft Azure HorizonDB. Zoom talk open to public at 4:30pm ET. YouTube video available after: db.cs.cmu.edu/events/pg-vs-w…
3
7
65
17,057
Adam Prout retweeted

Spring 2026 @CMUDB Seminar Series: PostgreSQL vs. The World
db.cs.cmu.edu/seminars/sprin…
Starts Mon Feb 2nd @ 4:30pm EST. We will alternate between a speaker from either a @Postgres DBMS or a non-Postgres DBMS.
Open to the public over Zoom. All videos available on YouTube afterwards.

ALT PostgreSQL vs. The World Seminar Series — Spring 2026 https://db.cs.cmu.edu/seminars/spring2026/
2
51
281
16,611
22 Nov 2025
The pg_duckdb extension is now available to use with Azure Postgres. It's a quick way to get faster analytical query results from Postgres via running queries with duckdb's very good vectorized query engine.
techcommunity.microsoft.com/…
2
1
6
1,188
22 Nov 2025
feedback welcome.
We're interested in improving PostgreSQL's support for analytical queries at Microsoft. Is pg_duckdb enough?
2
205
18 Nov 2025
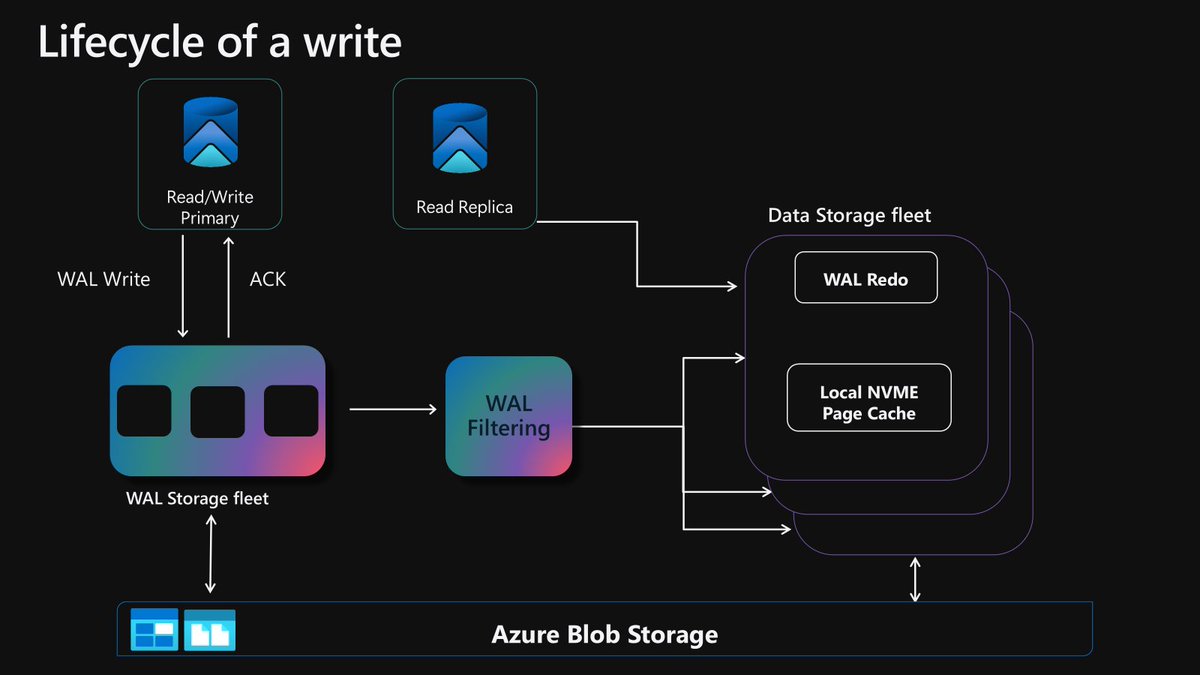
We’re shipping something new for PostgreSQL on Azure. HorizonDB pairs upstream compatibility with disaggregated storage designed for Postgres. We push most replication and durability work into the storage layer leaving more CPU for PostgreSQL to run queries and transactions.
1
3
7
549
18 Nov 2025
Check out the live stream tomorrow 9 AM PT if interested. I'll talk about it in more detail:
ignite.microsoft.com/en-US/s…
1
1
2
217
12 Sep 2025
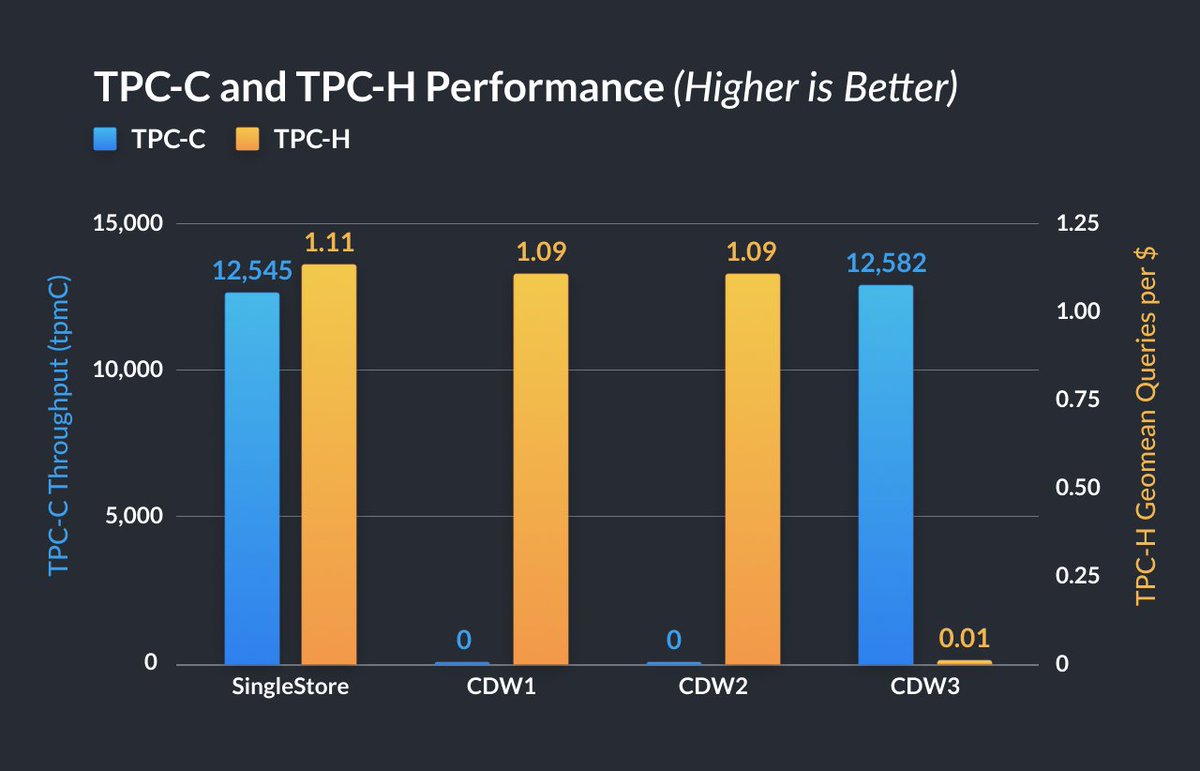
Congrats team @SingleStoreDB
Thats two @nikitabase founded database companies acquired in the past ~3 months for XXX millions each (Neon -> Databricks, MemSQL/Singlestore -> private equity)?
How often has that happened before?
10 Sep 2025

The journey continues! Excited to announce @capital_vector's growth buyout of @SingleStoreDB. I look forward to partnering with Amish Mehta & team to innovate, serve customers, and build a multi-generational company.
SingleStore Announces Growth Buyout Led by Vector Capital - businesswire.com/news/home/2…
9
1,277
11 Jul 2025
Great Post. I almost wrote something similar myself after reading all the FUD spit out by PlanetScale about Metal. There are trade-offs between shared-nothing and shared-storage, but shared-storage is the dominate arch for cloud OLTP (AWS Aurora, SQL Hyperscale, Neon, etc.).
11 Jul 2025

Separation of storage and compute ≠ slow reads from extra hops
On Neon, the compute layer can use LFC (Local File Cache) to serve hot reads without a trip to storage layer.
3
6
63
8,871
Adam Prout retweeted

15 May 2025
It’s strange how quickly software companies go from making engineers accessible to customers to hiding them behind sales / marketing / evangelists /account management / customer support / customer success / executives / developer relations / lawyers / user research / etc. It’s got to be hard to build something great when you can never talk to the customer.
40
18
350
27,339
23 Jan 2025
A step towards an open-source standard DocumentDB API (everyone aims to be "mostly" MongoDB compatible today...and you can do that with this project too)
opensource.microsoft.com/blo…
1
5
627
6 Dec 2024
Are there any SQL databases other than the newly announced Aurora DSQL that use optimistic concurrency control as a default (or only) option ? I’m not aware of any…
6 Dec 2024

Lessons learned the hard way from the field:
Optimistic vs Pessimistic concurrency control
TiDB used to be OCC only but had to change to PCC and OCC is now optional.
link.medium.com/PoctqlJS5Ob
7
4
2,162
11 Nov 2024
I was fortunate to touch the wreckage of my great uncle Robert Hodgins' Avro Lancaster heavy bomber (ND742) this summer. He was shot down over Paris about a week after D-Day. Lest we forget.
1
8
513