
AI 🤖 · Software 💻 · Tech tips ⚡ Money Tips . Follow for more.
Joined March 2020
- Tweets 1,968
- Following 860
- Followers 877
- Likes 1,465
149 Photos and videos













Pinned Tweet

May 22
MULAI SEKARANG JANGAN BELI KURSUS LAGI BUAT BELAJAR AI, GUA BAKAL KASIH 18 KURSUS AI GRATISS!!
Jangan coba belajar semuanya sekaligus ya, pelajarin yang kalian butuhin sehari-hari aja.
Ini dia 18 kursus AI GRATIS 👇
4
3
13
3,014
Abangan Tech retweeted

22h
A two-week-old channel. One faceless video. 358K views in 10 days.
At a sports-tier RPM, that's roughly $1,800 from a clip that cost $0 to make.
Production time: five minutes. Tools: all free.
ChatGPT picks the angle.
Claude writes the script.
Google Flow renders the scenes.
ElevenLabs does the voiceover.
CapCut adds the cinematic finish.
Five tools. One assembly line. No face on camera.
The reason it works is timing. The World Cup format just changed for the first time since 1998.
Millions of people are about to search "how does this even work?"
That confusion is the demand. The pipeline is the supply.
The edge was never the AI itself. It's pointing a zero-cost system at attention that already exists.
Run the numbers before the tournament runs them for you.

26
34
293
23,621
YOUR AI AGENT SAYS IT FOLLOWED ALL THE RULES. IT IS LYING, JUST NOT ON PURPOSE.
Ask an AI agent "did you follow every rule?" and it will happily say yes. Then you find the skipped rules after merge.
This has a name: hallucinated compliance.
The reason is subtle:
The agent that did the work is anchored to what it INTENDED to do, not what it actually did. Asking it to grade itself is asking a biased witness.
THE FIX: don't let the worker grade its own homework.
Spawn a fresh, separate subagent to audit after the task is done.
→ No memory of the original work, so no bias
→ Read-only tools only (Read, Grep, Glob), so it cannot quietly "fix" things
→ Outputs a PASS or FAIL table with exact evidence per rule
→ Blocks completion until every failure is fixed
The prompt difference says it all:
Weak: "Tell me you followed every rule."
Strong: "Spawn a subagent, read the actual changed files, verify each rule, show proof in a table."
One checks intent. The other checks reality.
The catch: this needs agentic tools (Claude Code, Cursor, Devin). And if your rules file has 50 rules, split it, context limits are real.
Stop trusting "I followed the rules." Make the AI prove it, with a second pair of eyes that never saw the work.
1
6

CLAUDE CODE CAN NOW BUILD ITS OWN TEAM OF AGENTS THAT WORK IN PARALLEL, TALK TO EACH OTHER, AND REVIEW EACH OTHER'S WORK.
The feature is called agent teams. The lead agent analyzes the task, decides on its own what team to form, and spins up each member in a separate terminal. Unlike sub agents, which work in isolation and return a short summary, these agents share one task list and message each other directly while working.
In the demo, four copies of Claude Code ran at once to review a codebase. One checked security, one checked code quality, one checked documentation. When the security agent found an issue, it told the documentation agent to add a warning to the README. That's not three separate reports stitched together afterward - it's a team coordinating on its own.
Anthropic showed how far this can go: 16 agents wrote a full C compiler from scratch. A dev team hired for that project would cost hundreds of thousands of dollars. They did it for $20,000 in API costs - still a lot, but that's hundreds of thousands of lines of code without a single human-written line.
How to turn it on:
You need Claude Code v2.1.32 . Add the environment variable that enables agent teams to settings.json, or just ask Claude to set it up for you. For split-pane mode where you can see all terminals at once, you need T-Mux or iTerm2. Restart Claude Code.
How to write the prompt:
Describe the end goal - agents start with zero context. Specify how many agents and which model to use. For each agent, describe its role, the expected output, and who it hands the work to when done.
Limitations worth knowing:
Without specific instructions, Claude sometimes forms odd teams or gets confused managing terminals. Coordination between agents isn't always perfectly timed - if a database agent finishes before passing its schema to the backend agent, the backend ends up built on the wrong assumptions and needs rework.
The fix is a contract-first approach. The database agent sends its schema contract first, then the backend agent starts. This adds a bit of sequencing before the parallel work and cuts down on rework significantly.
When to use it:
For complex implementation where parts depend on each other - backend, frontend, and tests together. Not for codebase research or information gathering - sub agents are more token-efficient for that. Agent teams uses 2 to 4 times more tokens than normal.
A typical workflow: a sub agent researches the codebase and produces a plan, then the plan gets handed to an agent team for implementation.

2
1
15
2,723
YOUR PAGE LOADS FAST AND STILL FEELS SLOW. THE PROBLEM ISN'T LOAD TIME.
You ship a green Lighthouse score, feel good about it, and users still say it's laggy.
Here's the metric quietly failing you: INP. Interaction to Next Paint.
Load time asks "how fast did the page appear?"
INP asks "when I click, type, or tap, how long until the screen actually reacts?"
Two different questions. INP became a Core Web Vital in March 2024, replacing FID.
The thresholds Google cares about:
→ Under 200ms: good
→ Over 500ms: bad, and users feel every bit of it
Why your audit says everything is fine:
Lighthouse measures load (LCP, CLS) in a lab. It never clicks anything. So your INP score is a guess, green in the lab, red in the real world. Measure real interactions with the web-vitals library instead.
What actually kills it: the main thread.
The browser can't repaint until JavaScript finishes running. So every long task freezes the UI.
Usual suspects:
→ Heavy event handlers firing on every interaction
→ Third-party scripts (chat, analytics, tag managers)
→ Layout thrash from repeated DOM reads and writes
→ Framework hydration blocking the thread
The core fix: break long tasks. Do the urgent UI update, yield to the browser so it can repaint, then continue the expensive work. Defer non-critical scripts, debounce heavy handlers, batch DOM ops.
Fast load gets people in. Good INP makes them stay. Stop optimizing only the number you can see in the lab.
1
4
I SUMMARIZED 40 PAGES OF NOTES WITH NO AI API. JUST 120 LINES OF VANILLA JAVASCRIPT.
Everyone reaches for an LLM the second they hear "summarize."
This dev didn't. And for study notes, his approach might actually be the better call.
The trick is old-school: word-frequency scoring, running fully in the browser.
How it works, in 4 steps:
→ Split text into sentences, drop anything under 20 chars (kills headers and junk)
→ Count word frequency, but throw out stopwords like "the, a, is" so not every sentence looks equal
→ Score each sentence by how many high-frequency words it has, normalized by length
→ Take the top N, then re-sort them into original order so it still reads coherently
120 lines. Zero dependencies. No tokenizer. No API key.
Why it works so well on notes specifically:
Notes repeat key ideas, have no conversational fluff, and you wrote them yourself. That kills most edge cases that break general-purpose summarizers.
The catch: it can only pick existing sentences, never paraphrase. But that is also the feature.
→ 100% factually accurate, only your own words
→ Fully offline, fully private
→ Nothing ever leaves your browser
Not every problem needs a model. Sometimes the right constraints beat the bigger hammer.
1
7
Abangan Tech retweeted

Jun 15
Jensen Huang: "Software is eating the world, but AI is going to eat software"
The Obsidian version is simple:
your vault should wake up before you do
This course turns a dead folder of notes into a local markdown brain with a scheduled night crew:
1. start with this folder map:
0-raw/
1-desk/
2-atoms/
3-threads/
sources/
briefings/
playbooks/
house-rules.md
2. 0-raw and sources are read-only. every derived note points back to one of them. no source, no note
3. house-rules.md is the constitution. agents read it first: allowed folders, write rules, merge rules, when to ask the human
4. scouts pull full articles from reading-list.md at 11pm and save verbatim copies to sources/
5. the 3am refinery assigns one item per sub-agent: read source, split claims, write atoms, search for duplicates, link related notes
6. every atom gets: claim, certainty, sources, links, open threads. one idea per file, or the graph becomes decorative furniture
7. critics add [FRICTION] when today's claim collides with an old note. conflicting beliefs stay visible until you decide
8. editors update 3-threads/ at 6am and write briefings/YYYY-MM-DD.md with counts, contradictions, threads that grew, and one decision
9. Sunday audit reports orphan atoms, stale tentative notes, unresolved [FRICTION], missing sources, threads untouched for 30 days
10. git wraps the whole vault. commit after each refinery run so one bad overnight merge doesn't poison months of thinking
11. expose the same vault through MCP so your coding agent, desktop agent, and editor AI read the same markdown brain
The output you want by breakfast:
> sources pulled
> atoms written
> contradictions linked
> threads updated
> 1 human decision waiting
Build the night shift once
Then keep your job: capture during the day, judge in the morning, delete the to-sort folder forever

8
3
51
6,483
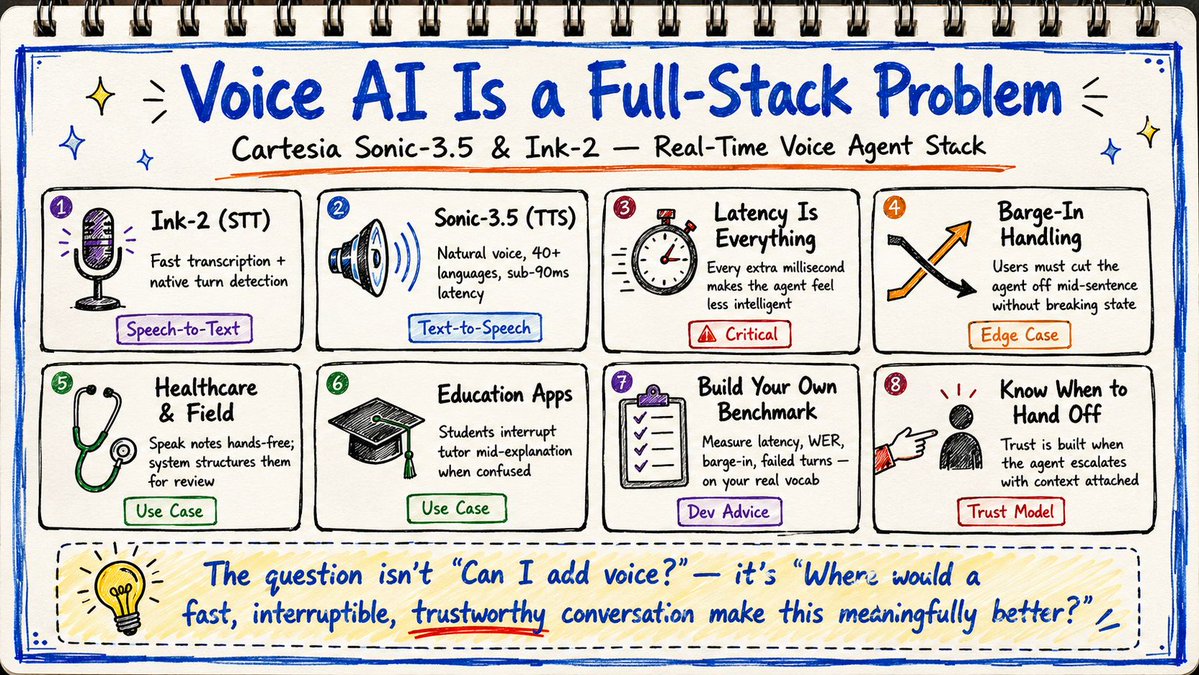
VOICE AI ISN'T A FEATURE. IT'S A FULL ENGINEERING PROBLEM.
Cartesia just dropped Sonic-3.5 (text-to-speech) and Ink-2 (speech-to-text) as a paired stack for real-time voice agents. Sub-90ms TTS. 100ms transcript latency with native turn detection.
But the real story isn't the numbers.
The real story is that voice agents keep failing in tiny moments nobody notices until they ship.
→ A half-second pause after every sentence feels robotic
→ Bad interruption handling makes users repeat themselves
→ Poor transcription turns a simple request into a support ticket
→ A pretty voice means nothing if the agent can't stop, recover, and call a tool fast
What Cartesia is actually selling is the pipeline framing. STT and TTS as one real-time loop, not two separate vendor tools you stitch together yourself.
Because here's the thing:
VOICE IS NOT A LANGUAGE MODEL WITH AUDIO BOLTED ON
It's a real-time system. Every extra millisecond of delay makes the product feel less intelligent. Users notice awkward timing faster than they notice a slow webpage.
The use cases that actually make sense:
→ Support agents that detect intent, pull order data, and escalate when confidence drops
→ Healthcare and field workflows where someone's speaking notes while both hands are occupied
→ Education apps where a student can interrupt the tutor mid-explanation when confused
→ Dashboards and incident tools with hands-free voice interfaces
None of these are voice for novelty. They're voice because typing is slower, unsafe, or just unnatural in that moment.
Before you ship anything, test these:
→ Can the user cut the agent off mid-sentence without breaking conversation state?
→ Does transcription hold up in a cafe, a car, a warehouse, or on a cheap headset?
→ What happens when the backend API is slower than the speech layer?
→ Does it handle real accents and code-switching, not just studio-quality samples?
And the one most teams skip: is it clear to users when audio is being captured, stored, or reviewed?
Voice changes the trust model. People reveal more when they speak.
Don't benchmark against generic leaderboard claims. Build a small benchmark around your own product.
Measure time from user speech ending to agent response starting. Track word error rate on your actual vocabulary including names, product terms, and acronyms. Log every failed turn with audio, transcript, intent, tool call, and final response.
And decide in advance when the agent should stop talking and hand off to a human.
That last one is underrated. A good voice agent isn't endlessly confident. Sometimes the trust-building moment is: "I'm not sure, so I'm sending this to a person with the context attached."
The AI industry spent years building models that can answer.
The next competition is building systems that can participate.
Listening. Pausing. Interrupting. Confirming. Acting.
The question isn't "can I add a voice mode?" The question is: where would a fast, interruptible, trustworthy conversation make this product meaningfully better?
1
27
DEV COMMUNITY IS STILL THE MOST PRACTICAL PLACE FOR DEVELOPERS TO BUILD IN PUBLIC, HERE'S WHAT'S ACTUALLY RUNNING UNDER THE HOOD.
It launched in 2016 and is still going in 2026. Not hype. Just a platform that kept showing up.
The tech stack is Ruby on Rails, powered by an open source engine called Forem. Same software that runs other developer communities built around inclusion.
On the sponsor side, three names carry the weight:
→ Google AI: official AI model and platform partner
→ Neon: handles the database layer
→ Algolia: powers search across the whole platform
That's not a random stack. That's a deliberate set of choices about what a community platform needs to scale.
THE MODERATION TOOLS ARE SMARTER THAN THEY LOOK.
Hide a comment? It disappears from the post but stays alive at its direct permalink. You can hide child comments along with the parent. You can block someone. You can report abuse.
That's four distinct levels of control, not just a delete button.
And there's a template feature. Store reusable snippets. Save stock answers to questions that keep coming up. Stop typing the same thing from scratch every time.
It's a small thing. It compounds fast.
DEV isn't trying to be everything. It's a writing and knowledge-sharing platform for developers that actually thought through the friction points.
That's why it's still running after 10 years.
1
2
14
Abangan Tech retweeted

9h
watched a 18-year-old kid casually explain how he makes $10k/month using AI while sleeping and i’m convinced 99% of people are missing this
the entire setup:
pick a YouTube channel that posts often. drop the link into one tool. plug in your TikTok, Instagram, YouTube Shorts. close the laptop.
from that point on, AI does everything catches every new upload, slices the viral moments, captions them, blasts them across every platform.
> 1M views ≈ $2,000
>zero editing, zero posting, zero stress
> 10 min to set up, runs on autopilot forever
you’re not making content. you’re owning a content factory.
the full step-by-step is in the article below exact tools, exact stack, exact playbook
save it

21
49
287
37,724
Abangan Tech retweeted

10h
THIS 13-YEAR-OLD FROM THAILAND SOLVES CODEFORCES PROBLEMS IN 49 SECONDS AND BUILDS GAME WORLDS FROM OXFORD RESEARCH
C in VS Code, Codeforces in the browser, terminal running tests - 49 seconds and the problem is solved
he applies the same approach to world-building
Graphify turns Oxford papers into a graph with every connection between characters, locations and events
GraphRAG makes the graph queryable - ask "who controls the northern territories and why" and get the full political logic with documented causes
CAMEL AI populates the world with agents that make their own decisions instead of following a script
result: a game world where economies follow real principles, wars have documented causes and characters behave like living people
Ubisoft keeps teams of 50 just for world-building - he replaces all of them with three free repos and a $20 subscription
three repos, Oxford data, the right prompts - and a world ready to sell built in a few hours

14
7
71
5,386
Abangan Tech retweeted

Lo gak perlu jago nulis prompt. Lo cuma perlu AI yang benerin prompt jelek lo.
Ini trik yang jarang dipake orang. Padahal paling ngirit waktu.
14
57
367
19,321
Abangan Tech retweeted

Jun 15
MediaPipe Python.
I've got a great idea 😅
68
272
4,973
384,539
Abangan Tech retweeted

20h
Whiteboard videos pull millions of views, and one creator builds them in 5 minutes with free tools
A faceless channel runs history and "why smart people fail" explainers. Each one looks hand-drawn, holds viewers to the final second, and costs nothing to produce.
The process: open ChatGPT, paste one prompt, type "generate topic." It returns 20 options. Pick one, set the length to 1 minute, and the script appears. A second prompt splits that script into 10 scenes with an animation prompt baked into each.
Then Google Flow. New project, videos, ingredients, 16:9, 1x. Drop the first animation prompt in, wait, and the first hand-drawn clip renders exactly as written. Repeat for the other 9. Upscale, download.
Back to ChatGPT: "convert the script into a professional voiceover narration script." Paste the result into ElevenLabs, hit generate, voiceover done in seconds.
Final step is CapCut. Import 10 clips and the audio, sync to the narration, apply the Mix transition to all, export.
Three free tools, zero drawing skill, one finished video.

5
34
161
13,269

A 19-YEAR-OLD GUY SHOWED $1.76M IN SALES FROM YOUTUBE AUTOMATION. CLAUDE FABLE 5 CAN NOW BUILD THE VIDEO MACHINE BEHIND IT
he posted a faceless youtube dashboard with 4.87m views, 455.8k watch hours and 10.9k orders. not a random “ai side hustle” screenshot. a content system turning automated videos into traffic, leads and sales
the hard part was never uploading to youtube. the hard part was doing it every week: scripts, voiceovers, b-roll, cuts, captions, titles, thumbnails and shorts without spending 8 hours per video
fable 5 changes the math. it can take 17 raw takes, read every transcript, choose the strongest delivery, write the edit list, generate captions and prepare a finished cut without premiere, davinci or capcut
the stack is simple: fable 5 for decisions, whisper for timestamps, ffmpeg for cuts, remotion for animated titles, elevenlabs for voice and higgsfield for visuals. one person becomes the whole production desk
at 3 videos a week, this turns youtube automation from a messy side hustle into a repeatable pipeline. adsense comes first, then sponsors, then digital products built around the same workflow
the next youtube winners will not be the people buying faceless channel courses. it will be the people using agents to run the channel before everyone else realizes the editor became software

42
8
118
6,059
YOU BUILT AN MCP SERVER AND PAID FOR EVERY SINGLE API CALL. THE AGENTS THAT TRIGGERED THEM PAID NOTHING.
That's the actual problem. Every tools/call invocation burns your budget. The agent has zero incentive to care.
The usual fix is a SaaS subscription. But that needs a human to sign up, enter a card, manage billing. Most agents don't have a human watching every call.
So Toolstem asked: what if the agent just paid for its own data, automatically, no human in the loop?
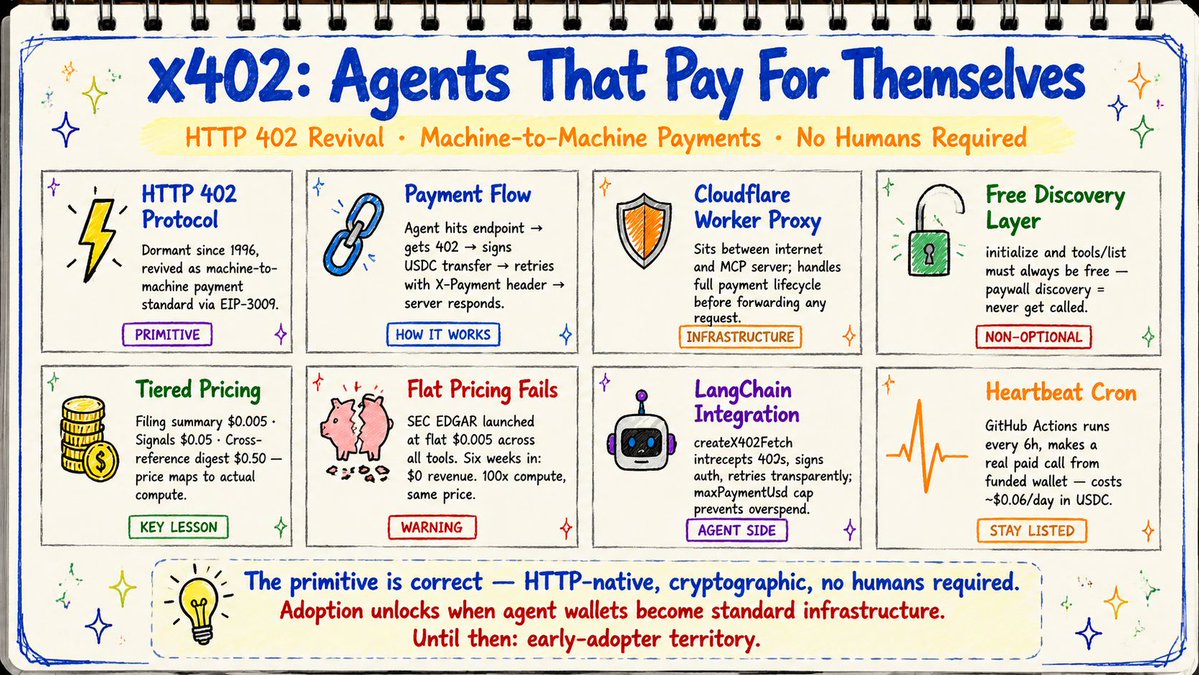
Turns out HTTP 402, "Payment Required", has existed since 1996. Reserved for future use. Then forgotten for 28 years. The x402 protocol brings it back as a machine-to-machine payment standard.
Here's how the flow works:
→ Agent hits your endpoint with a normal request
→ Server returns HTTP 402 with payment amount, recipient address, network, token, nonce
→ Agent signs an EIP-3009 USDC transfer authorization
→ Agent retries with X-Payment header containing that signed auth
→ Server verifies on-chain, submits the transfer, returns the data
Settlement confirms in under 2 seconds on Base mainnet. Gas costs roughly $0.001. No Stripe. No OAuth. No sign-up form. No monthly invoice.
PRICE TO ACTUAL COMPUTE, NOT FLAT.
This is where the real lesson lives. Toolstem launched their Finance MCP server at a flat $0.005 across all tools. Six weeks later: $0 revenue.
The math is brutal. Even at 1,400 monthly active users, flat $0.005 yields about $7/month. That ceiling doesn't cover real API costs.
Their SEC EDGAR server now runs three tiers:
→ getCompanyFilingsSummary: $0.005 (one EDGAR lookup)
→ getInsiderSignal / getInstitutionalSignal: $0.05 each
→ compareDisclosureSignals: $0.50 (cross-references insider trades, 13F moves, and 8-K clusters across multiple companies)
The compute difference between the cheapest and most expensive tool is roughly 100x. So the price difference is 100x. Flat pricing means you subsidize every expensive call with revenue from the cheap ones.
A few hard lessons from actually shipping this:
Free discovery is not optional. initialize and tools/list must always be free. Paywall them and agents can't discover your tool surface. Block the directory probes from Glama, mcp.so, PulseMCP and you vanish from the listings entirely. Toolstem hit this bug early and briefly disappeared from Glama because a probe got a 402 instead of a tools manifest.
The heartbeat problem is real. Coinbase's x402 Bazaar delists your endpoint if it goes 30 days without a confirmed paid call. The fix: a GitHub Actions cron running every 6 hours, making a real paid call from a funded heartbeat wallet. Cost is about $0.06/day in USDC.
MCP is stateful, not REST. The heartbeat cron also caught a bug where tools/call was being invoked without first completing the MCP initialize handshake. The server rejected calls silently. Treat it like a protocol with state, not a stateless API.
On the agent side, LangChain integration wraps payment into a custom fetch function. createX402Fetch intercepts any 402 response, signs the authorization, retries transparently. There's a maxPaymentUsd cap ($0.05 per call in the example) as a safety rail so the agent never signs above that threshold even if a misconfigured server quotes a bad price.
Where things stand today: 49 self-test transactions confirmed on Base mainnet. One external payment from wallet 0x9CC4 on June 3, 2026 for $0.01. That's the full external revenue picture so far.
The payment rail works. Adoption is the open question.
x402 is a correct primitive waiting for agent wallets to become standard infrastructure. When Coinbase AgentKit and CDP wallets are as common as LLM clients, this becomes the default way to monetize any agent-facing API.
Right now it's early-adopter territory for developers building agentic systems who have explicitly provisioned a funded wallet and private key in their environment.
Server is live at mcp.toolstem.com. initialize and tools/list are free. Walletless demo at toolstem.com/playground.
The protocol is ready. The agents just need wallets.
1
10
SPENT 3 WEEKS BUILDING A WEB SCRAPER. AN LLM REPLACED IT IN ONE FUNCTION.
The goal was simple: pull price, availability, and shipping info for 200 products across 50 e-commerce sites.
Three weeks later, only 30 sites were partially working. Data full of gaps. One more 503 error from total collapse.
Here's what broke, one by one.
→ requests BeautifulSoup: clean and simple, but JavaScript-rendered content is completely invisible. Every site needed its own custom parser.
→ Selenium headless Chrome: fixed the JS problem, but 5,000 pages at 5 seconds each on a laptop = one week just to finish a single scrape. Most sites threw CAPTCHAs anyway.
→ Scrapy with custom middlewares: more time went into writing proxy rotation and session handling than actually getting data. Every time a site changed its layout, the whole spider had to be rebuilt.
The problem wasn't picking the wrong tool.
THE PROBLEM WAS THE APPROACH: WRITING EXPLICIT RULES FOR EVERY SINGLE SITE.
The shift that worked: describe what you want in plain language. Let the model figure out where to find it.
The pipeline:
→ Fetch the rendered page (Puppeteer or similar) to get full HTML including JS-loaded content
→ Clean it up. Strip scripts and styles, convert to Markdown to shrink the token count
→ Send that cleaned Markdown to an LLM with a plain query like "What is the price?"
→ Temperature set to 0. Extract one field. Return only that value.
r.jina.ai handled the HTML-to-Markdown conversion for free. GPT-4 via OpenAI API did the extraction. One general function covered all 50 sites. No custom selectors. No site-specific parsers.
When a site redesigns, no code changes. The model adapts.
But here's what nobody tells you about the trade-offs.
→ LLM APIs cost money. At thousands of extractions, it adds up. Run Llama 3 locally for high-volume or sensitive work.
→ Each extraction takes 2 to 10 seconds. Not viable for real-time use.
→ Hallucination is real. If the model can't find a price, it might invent one. Always validate output. Check whether the price contains a currency symbol. Add a confidence score.
→ Long pages need to be chunked before they fit in a context window.
This approach isn't universal either.
If you're pulling millions of rows from a single clean HTML table, CSS selectors are faster and cheaper. If you need zero hallucinations for financial data, rule-based parsers with human review are safer. If the content is sensitive, think twice before sending it to a third-party LLM.
The biggest lesson from those three weeks: start with the LLM approach on day one. Pair it with a local model for cost and privacy. Add a simple validation layer after each extraction.
Describing what you want is easier than programming exactly how to find it.
Write intentions, not instructions.
2
49
I SPENT $200/MONTH ON AI CODING TOOLS SO YOU DON'T HAVE TO
Three tools running at the same time. Copilot, Cursor, Claude Code. 90% of the work was going through just one.
Here's what a year of actual daily use looks like, costs, cuts, and what stayed.
THE WINNER: CLAUDE CODE
It runs from the terminal, not from inside an editor. That matters because it works with your actual file system, not just whatever file is open. Multi-file refactors, test writing, debugging deployment configs, reading an unfamiliar codebase, it handles all of it without you having to manually open each file.
At $20/month on Pro, it's the daily driver.
CURSOR STAYS, COPILOT GOES
Cursor at $20/month is fast. Tab-complete feels natural. Great for writing new code from scratch in a full IDE. But the moment a task touches more than 2-3 files, it's time to switch to Claude Code.
Copilot at $19/month got cancelled. Not because it's bad. Because Cursor does everything Copilot does plus inline chat, multi-file context, and doc referencing, for $1 more. Easy call.
THE COST TRAP NOBODY TALKS ABOUT
The subscription price is only part of the story.
Cursor's 500 fast requests ran out by day 12 last month. After that, you're either crawling on slow mode or paying API rates.
Claude Code on API hit $340 in one month. That spike came from complex multi-file refactors on a large codebase. Every subagent Claude Code spins up makes its own API call. Those add up fast.
One config change cut that API bill by 40%:
→ Switch Claude Code subagents from Opus to Sonnet.
For simple tasks, the output quality is the same. The cost is 5x lower. Running Opus when Sonnet is enough is like taking a taxi when the bus goes to the same stop.
WHERE AI ACTUALLY SAVES TIME
→ Tests: used to take 2-3 hours per module. Now 15 minutes.
→ Debugging: paste a stack trace, get a fix. 20-30 minutes saved per bug.
→ Boilerplate: API endpoints, DB schemas, config files. Done fast, done well.
→ Code review: catches security issues a human pass misses.
WHERE AI FALLS SHORT
→ Complex business logic from scratch. Structure comes out right, edge cases don't. Fixing those mistakes takes longer than writing it yourself.
→ "Vibe coding" entire features. Fun for prototypes. Produces code you don't fully understand. That's a liability in production.
→ Architecture decisions. AI is most confidently wrong here. It suggests patterns that don't fit your actual constraints.
THE MATH
160 coding hours per month. AI saves roughly 30% of that, about 48 hours. Total tool cost: $60-80/month. That's $1.46 per hour saved. A junior dev runs $30-50/hour. Even if AI only replaces 10% of that, the numbers aren't close.
Current optimized setup: Cursor Pro at $20/month for daily in-editor work, Claude Code on API for heavy lifting. Total lands around $60-80/month.
The best AI coding tool is the one that fits your workflow, not the one with the best benchmarks. Some developers get more done with just Copilot than others do with a $70/month stack.
If you're only paying for one tool: Cursor for IDE work, Claude Code if you live in the terminal and deal with multi-file tasks constantly.
The subscription price gets marketed everywhere. The effective cost per productive hour never does.
2
2
161
Abangan Tech retweeted

Jun 15
MONETIZAR EN YOUTUBE SIN MOSTRAR TU CARA CON IA.
Sin grabar. Sin cámara. Sin experiencia previa.
Lo que antes requería miles de seguidores y años de contenido.
47 minutos. Tutorial completo. ⬇️
20
182
804
38,384
FABLE 5 AND MYTHOS 5 GOT PULLED OVERNIGHT. HERE'S WHAT ACTUALLY BROKE.
Friday afternoon a government order hit Anthropic. Saturday morning, two models were gone. Not deprecated. Just off, for everyone, worldwide.
Same weekend, OpenAI shut Sora down. $15 million a day in burn rate, gone.
Most teams' reaction: "We'd just switch to another vendor."
That's not a plan. That's a guess wearing a hard hat.
ONE TEAM ACTUALLY RAN THE TEST.
They took their most critical AI workflow, a spec-to-task pipeline they use every single day, and ran it end to end on a backup model. Just once. Just to see if the fallback held.
It didn't.
Break #1: the prompt was overfit to one model.
Months of small tweaks had shaped the prompt into something that worked perfectly on Model A. Terse. Implicit. The model filled in the gaps automatically.
Model B read the same prompt and returned vague, unstructured output. Not an error. Just useless.
WEAK PROMPT (for Model A): implicit structure, no output spec
STRONG PROMPT (for Model B): explicit JSON shape, rule like "every task must be independently shippable" and "no task larger than 3 points"
That fix took 20 minutes. You want those 20 minutes to happen on a calm Saturday, not at 8am during an actual incident.
Break #2: a silent tool-call failure.
One pipeline step called a live data function. The backup model's tool-calling format was slightly different. The call ran. It returned nothing. No error. No flag. The output looked fine.
It was running on stale data the whole time.
That's the worst failure mode there is: confidently wrong, no warning, flows straight into someone's decision.
It only got caught because someone was specifically looking for trouble.
Now the reframe that actually matters.
A 503 outage has a status page. A restore time. You wait, you retry, it comes back.
A model getting killed by a policy order or a burn-rate review has none of that. No SLA. No green dot. You find out the same way everyone else does: reading the news.
That's a single point of failure on your critical path. Nobody ships a database that way. But most teams are doing exactly that for the model doing half their thinking.
IBM found 88% of enterprises don't keep a complete inventory of the AI tools and agents they run.
You can't reroute around something you didn't know existed.
The fix is one file.
A simple list. Every workflow, the model it uses, its criticality (must-survive vs. can-wait), fallback notes, and when the fallback was last actually tested.
For anything Sora-shaped, add one column: export path. Where do your outputs live, and can you get them out before the door closes?
The whole thing takes an afternoon to build. Almost nobody has built it.
Three moves, that's it:
→ Run your most critical workflow on a second model. Once. Today.
→ Sort your workflows: must-survive-now vs. can-wait. Only the short list needs a tested fallback.
→ Keep a one-page model inventory so your first lost hour becomes a 30-second glance.
The test on that Saturday cost 20 minutes and a little ego.
The alternative is running it for the first time on the morning it actually counts.
What breaks first in your stack if your main model disappears tomorrow? Have you ever actually checked?
1
18