
Disaster Relief. Tweets are my own and do not indicate opinion, also RTs are not endorsements. 🇵🇷
Joined November 2007
- Tweets 16,954
- Following 6,152
- Followers 2,521
- Likes 5,390
Photos and videos

😁
13 Aug 2021

➡️ Abe Diaz from Amazon’s disaster relief team discusses how we're innovating ways to respond to communities after disaster strikes. freightwaves.com/news/reshap…
4
4
37
ABE DIAZ retweeted

May 29
You pick AI models based on their model cards, why not humans haha. Well done Noah! huggingface.co/noahmclaughli…

8
5
39
10,745
ABE DIAZ retweeted

May 27
3
9
12
1,116,793



ABE DIAZ retweeted

Apr 10
Boy kibble is bodybuilding's oldest meal repackaged by a generation that needs a meme name before they'll eat it.
Ground beef and rice has been the default gym bro dinner since the 1970s. Arnold's crew at Gold's Venice ate this five nights a week. No TikTok, no branding, no discourse. They just called it dinner.
The "cheap protein" framing is the part that falls apart under math. Ground beef hit $6.75 a pound in January 2026, up 22% year over year. A pound of ground beef gives you roughly 80g of protein. That's about $0.08 per gram. Chicken breast runs $0.04 per gram. Eggs are even cheaper. Canned tuna beats both. Ground beef is one of the most expensive common protein sources you can buy right now.
So why ground beef specifically? Because it requires zero knife skills, zero prep decisions, and zero culinary knowledge. You brown it in a pan and dump it on rice. The actual product being sold here is the elimination of decision fatigue, not protein optimization. A generation that builds mass in the gym but has never learned to cook found the one meal that removes every possible point of failure between raw ingredients and plate.
The $30 billion protein supplement industry should be terrified of this trend. Not because boy kibble is efficient. Because it signals that Gen Z men would rather eat genuinely bland food than buy another tub of whey powder. The supplement industry spent 20 years convincing young men that whole food protein was too inconvenient. Boy kibble is the market rejecting that premise with the most zero-effort meal imaginable.




A new trend called “boy kibble” has emerged, inspired by dog food, featuring protein-rich meals popular with Gen Z men.
Ground beef can be a solid starting point for a quick, nutritious meal. Here are some of our favorite recipes using it: wapo.st/4tB9QK2
5
3
23
10,476
ABE DIAZ retweeted

Apr 4
after my llm implements the plan it wrote:

Chess Grandmaster Hikaru just spent 67 minutes thinking about one move in a pro tournament, the second longest turn ever.
After all that time, it was still the wrong move and cost him the game.


5
1
23
4,624
ABE DIAZ retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,120
2,827
26,777
7,145,270
ABE DIAZ retweeted

Apr 2
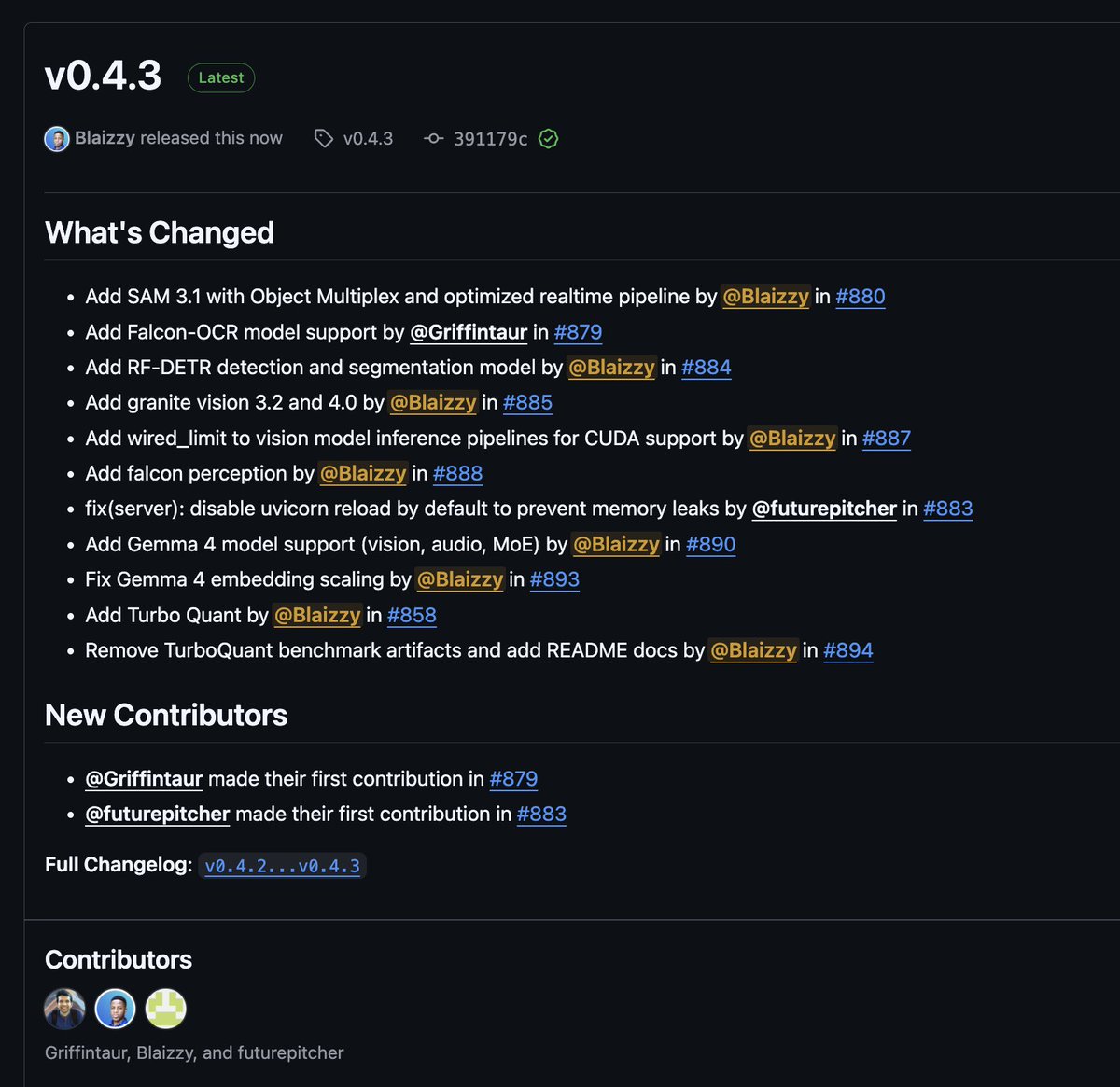
mlx-vlm v0.4.3 is here 🚀
Day-0 support:
🔥 Gemma 4 (vision, audio, MoE) by @GoogleDeepMind
🦅 Falcon-OCR Falcon Perception by @TIIuae
🪨 Granite Vision 4.0 by @IBMResearch
New models:
🎯 SAM 3.1 with Object Multiplex by @facebook
🔍 RF-DETR detection & segmentation by @roboflow
Infra:
⚡ TurboQuant (KV cache compression)
🖥️ CUDA support for vision models (Sam and RF-DETR)
Get started today:
> uv pip install -U mlx-vlm
Leave us a star ⭐️
github.com/Blaizzy/mlx-vlm
77
191
1,982
1,024,379

This is gonna save folks lots of effort scraping HN. ALS smart of HN to move all that scraping traffic elsewhere. Brilliant!


75
Brilliant!

stop doing demos. do reverse demos.
"open the app and let's do this together"
I've had 50 conversations like these in the past 2 months:
I tell them exactly which buttons to click.
they tell me exactly what's not clicking.
best part is zoe reads the transcript after and opens PRs for all the frictions we catch on the call, and logs everything to CRM.
founder-led sales founder-led product in one conversation.
50
Dr. @AndrewYNg One thing that's been frustrating: the Gemini Deep Research API (Interactions endpoint) is completely separate from the standard GenAI SDK, and coding agents constantly get it wrong. I submitted a PR adding docs for it: github.com/andrewyng/context…
If it adds value, great. If not, please at least consider including the Interactions API inside Context Hub so the community can benefit. Thanks Andrew! 🙏
CC: @OfficialLoganK
2
70
ABE DIAZ retweeted

Mar 5
Yeah PRDs are more alive than ever.
But you write them by:
- Chatting with AI
- Voice dictating stream of conscious thoughts
- Pasting in reference materials
Not by typing out letters one by one in your keyboard.

PRDs are more alive than ever. When the cost of implementation goes down, describing what to implement and why is where all the leverage goes.
25
18
186
19,804
Guys @karpathy is gonna tinker with claws this weekend. I can’t wait what he publishes by next Wednesday. VibeClaw incoming! 😂🙏
Feb 20
Bought a new Mac mini to properly tinker with claws over the weekend. The apple store person told me they are selling like hotcakes and everyone is confused :)
I'm definitely a bit sus'd to run OpenClaw specifically - giving my private data/keys to 400K lines of vibe coded monster that is being actively attacked at scale is not very appealing at all. Already seeing reports of exposed instances, RCE vulnerabilities, supply chain poisoning, malicious or compromised skills in the registry, it feels like a complete wild west and a security nightmare. But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level.
Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. I also love their approach to configurability - it's not done via config files it's done via skills! For example, /add-telegram instructs your AI agent how to modify the actual code to integrate Telegram. I haven't come across this yet and it slightly blew my mind earlier today as a new, AI-enabled approach to preventing config mess and if-then-else monsters. Basically - the implied new meta is to write the most maximally forkable repo and then have skills that fork it into any desired more exotic configuration. Very cool.
Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). There are also cloud-hosted alternatives but tbh I don't love these because it feels much harder to tinker with. In particular, local setup allows easy connection to home automation gadgets on the local network. And I don't know, there is something aesthetically pleasing about there being a physical device 'possessed' by a little ghost of a personal digital house elf.
Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
1
106
If we follow this trend of almost a new model every week from the top labs; that means at least 52 weeks of iterations in 2026. The speed of innovation has never been the same.

This is Claude Sonnet 4.6: our most capable Sonnet model yet.
It’s a full upgrade across coding, computer use, long-context reasoning, agent planning, knowledge work, and design.
It also features a 1M token context window in beta.
1
72
Holy ……
Feb 15

I'm joining @OpenAI to bring agents to everyone. @OpenClaw is becoming a foundation: open, independent, and just getting started.🦞
steipete.me/posts/2026/openc…
2
204
Yup. Totally get that.
Feb 15

Short musings on "cognitive debt" - I'm seeing this in my own work, where excessive unreviewed AI-generated code leads me to lose a firm mental model of what I've built, which then makes it harder to confidently make future decisions simonwillison.net/2026/Feb/1…
66