
The Approximately Correct Machine Intelligence (ACMI) Lab at @mldcmu at @SCSatCMU. Growing the ML sandbox to address more of the real world. PI @zacharylipton
Joined February 2020
- Tweets 186
- Following 22
- Followers 3,290
- Likes 241
7 Photos and videos




Pinned Tweet

11 Nov 2021
RecSys often assumes static rewards but preferences evolve! Consider “satiation”: 🍕for meal 1: 😄, 🍕for meal 2: 🤔, 🍕for meal 3: 😭… [no🍕] … 🍕for meal 100: 😄.
In “Rebounding Bandits” we model dynamic rewards w linear dynamical systems arxiv.org/abs/2011.06741 #neurips2021
2
10
40
ACMI Lab (CMU) retweeted

9 Nov 2023
Yesterday, I had the honor of speaking in the US Senate AI Insight Forum on privacy & liability, moderated by @SenSchumer @SenatorRounds @SenatorHeinrich & @SenToddYoung. Each panelist submitted a written statement for @SenSchumer's website. Here’s mine:
abridge.com/blog/ai-policy-c…
21
31
191
96,018
ACMI Lab (CMU) retweeted

28 Jul 2023

3
25
5,607
4 Aug 2022
New paper "Domain Adaptation under Open Set Label Shift" by @acmi_lab PhD student Saurabh Garg w coadvisors @zacharylipton & Siva Balakrishnan.
Lays out theoretical foundations & practical algorithm, for one scenario where open set adaptation can work.
arxiv.org/abs/2207.13048
4 Aug 2022

Excited to share new @acmi_lab paper introducing the first(?) theoretically coherent setting for open set classification. Under the label shift assumption, we can now handle both label shift (among prev seen classes) & arrival of a never-before-seen class
arxiv.org/abs/2207.13048
2
1
8
ACMI Lab (CMU) retweeted

27 Jun 2022
Is flatness indicative of generalization? Not necessarily.
Our experimental study calls the relationship between flatness (as measured by the max Hessian eigenvalue) and generalization into question.
arxiv.org/abs/2206.10654
11
36
249
9 Jun 2022
New work by @acmi_lab PhD student @dkaushik96 tackles the thorny issue of when to designate ML crowdworkers as human subjects. Our analysis reveals nuances, ambiguities, a loophole, & practical guidance
authors: DK, @zacharylipton & @AlexJohnLondon
paper: arxiv.org/abs/2206.04039
9 Jun 2022

Preprint alert 🚨
With ML’s growing reliance on crowdsourcing, in this paper, @zacharylipton, @AlexJohnLondon, and I seek to resolve the human subject status of ML’s crowdworkers. More in the thread🧵 1/15
arxiv.org/abs/2206.04039
1
5
10
22 Jan 2022
Congrats to our nephew-turned-son Riccardo Fogliato on a great thesis proposal. Riccardo's tackles deep questions re (i) the performance and fairness properties of criminal risk assessment instruments; and (ii) {human model} hybrid decision-making systems.
acmilab.org/people/riccardo-…

Congratulations to @CMU_Stats Riccardo Fogliato on his successful PhD thesis proposal on “Data and Humans in Algorithmic Risk Assessment”!! Co-advised by Alexandra Chouldechova @HeinzCollege and Zachary Lipton @zacharylipton @mldcmu @teppercmu
10
21 Jan 2022
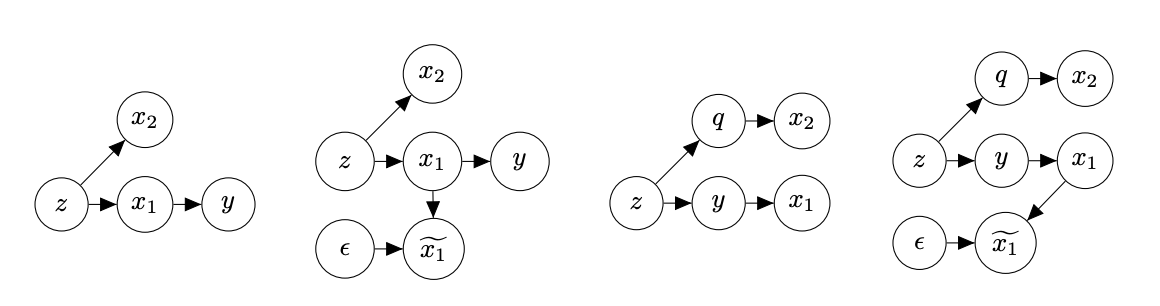
New work by @saurabh_garg67 (ICLR 2022) shows that in general, OOD accuracy is identified only when the optimal predictor is identified. Thus, any guarantee requires assumptions on nature of shift. Also discovers a simple method that works surprisingly well on many benchmarks.
15 Jan 2022

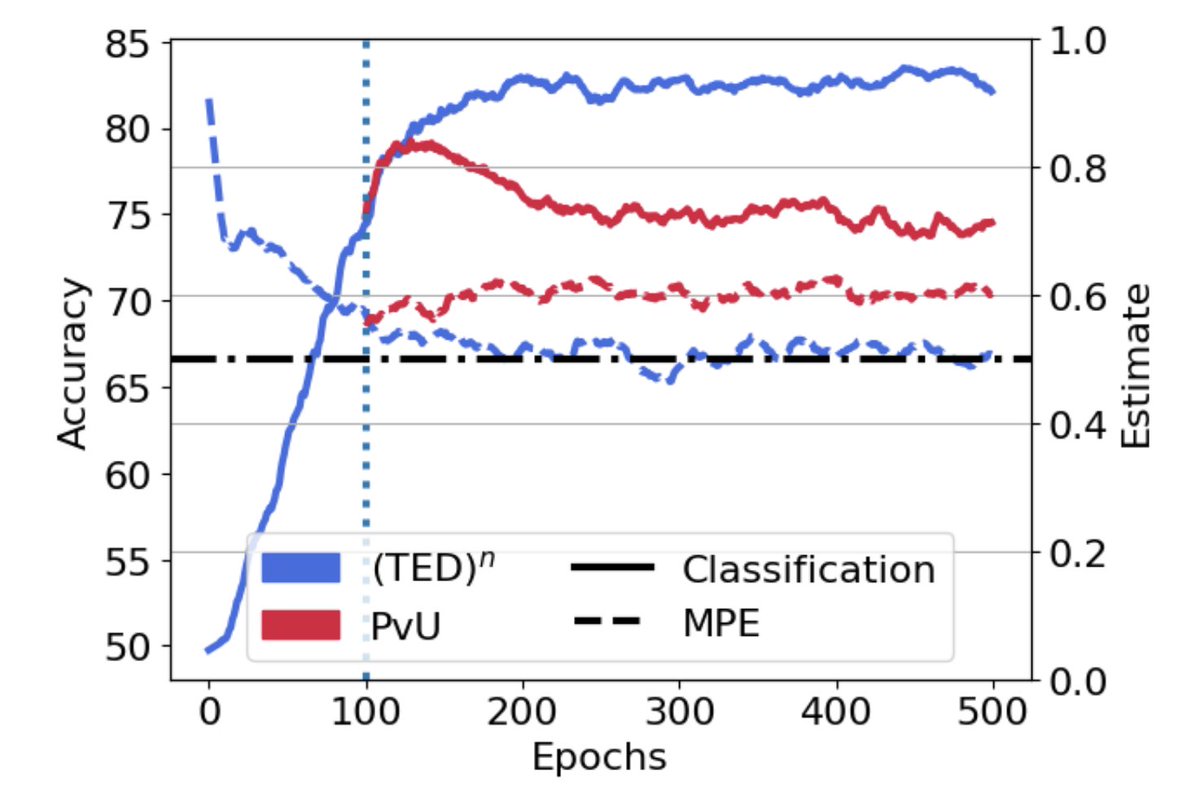
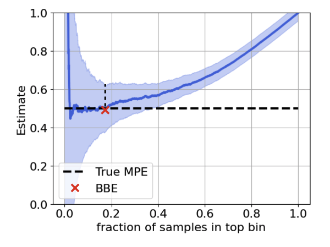
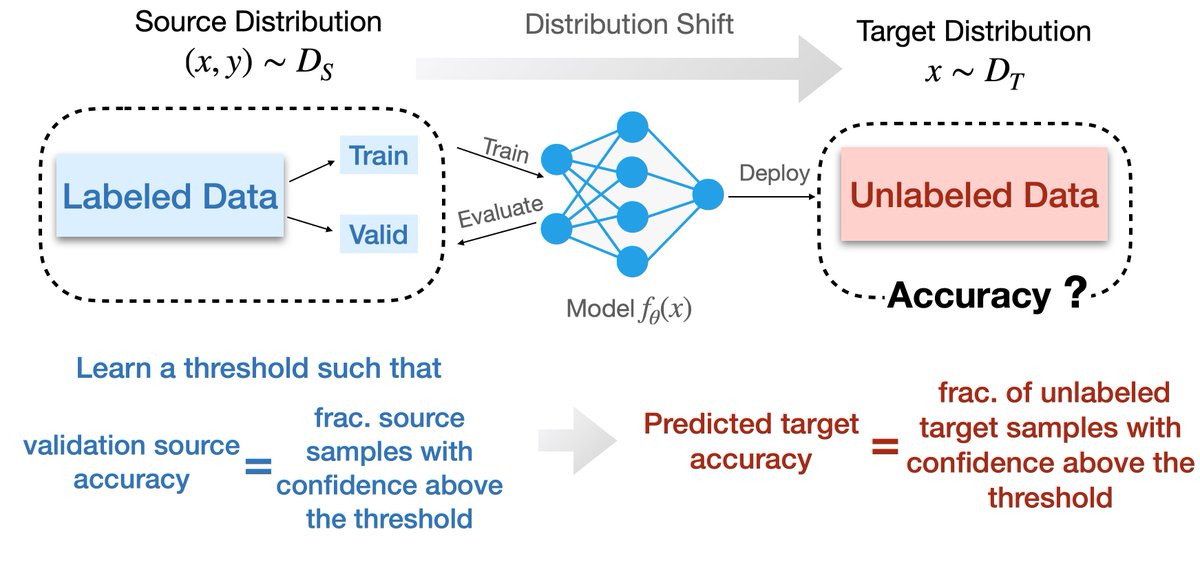
"Can we predict OOD performance given access to unlabeled target data?"
We investigate methods to predict target domain performance and find a simple method that does surprisingly well.
Paper: arxiv.org/abs/2201.04234
with Siva B, @zacharylipton, @bneyshabur, @HanieSedghi
1/
1
28
19 Dec 2021
Congrats to our 2nd ever PhD, the soon-to-be-minted Doctor Danish, who defended his dissertation this week. Danish joined this lab before it was a lab and helped build it from the ground up. We're proud of all you've accomplished and excited to see your future unfold. 👨🎓📜💻
17 Dec 2021

Excited to end the year on a high: I passed my PhD defense today!
*Absolutely* loved my PhD years @LTIatCMU—I could have spent another 3 years! Major thanks to @zacharylipton, @gneubig, @professorwcohen for being wonderful advisors. [1/n]



1
3
60
14 Nov 2021
Research experience is great, published papers can be impressive, but (generally) they are neither necessary nor sufficient for joining our lab. Some of our criteria:
13
72
676
14 Nov 2021
4. Fire—will this person bring some attitude to the lab? Can they forcefully disagree when appropriate? Will they spot flaws in a research direction? can can they cut against consensus? Will they spark creative directions, and do they have the drive to push them into reality? 🔥
1
66
14 Nov 2021
Pubs on a CV signal many things. It's not easy to bang out papers pre-PhD. But merely knowing that a researcher has been published or even that they have reliably have contributed to projects that met the bar for conference peer review carries little signal re the above.
3
1
79
11 Nov 2021
RecSys often assumes static rewards but preferences evolve! Consider “satiation”: 🍕for meal 1: 😄, 🍕for meal 2: 🤔, 🍕for meal 3: 😭… [no🍕] … 🍕for meal 100: 😄.
In “Rebounding Bandits” we model dynamic rewards w linear dynamical systems arxiv.org/abs/2011.06741 #neurips2021
2
10
40
11 Nov 2021
In addition to modeling satiation, our key technical innovation—modeling rewards as dynamical systems—may have broader applications & (given a different parameterization) be used to model other phenomena, such as brand loyalty & binging, & may prove useful beyond RecSys. (6/n)
1
11 Nov 2021
Work led by ACMI PhD student @leqi_liu, with Fatma Kılınç-Karzan, @zacharylipton, and Alan Montgomery.
Paper link: arxiv.org/abs/2011.06741 (n=7/n)