
agi | space | fusion
Joined September 2022
- Tweets 1,834
- Following 2,267
- Followers 2,337
- Likes 564
427 Photos and videos





Pinned Tweet

Apr 17
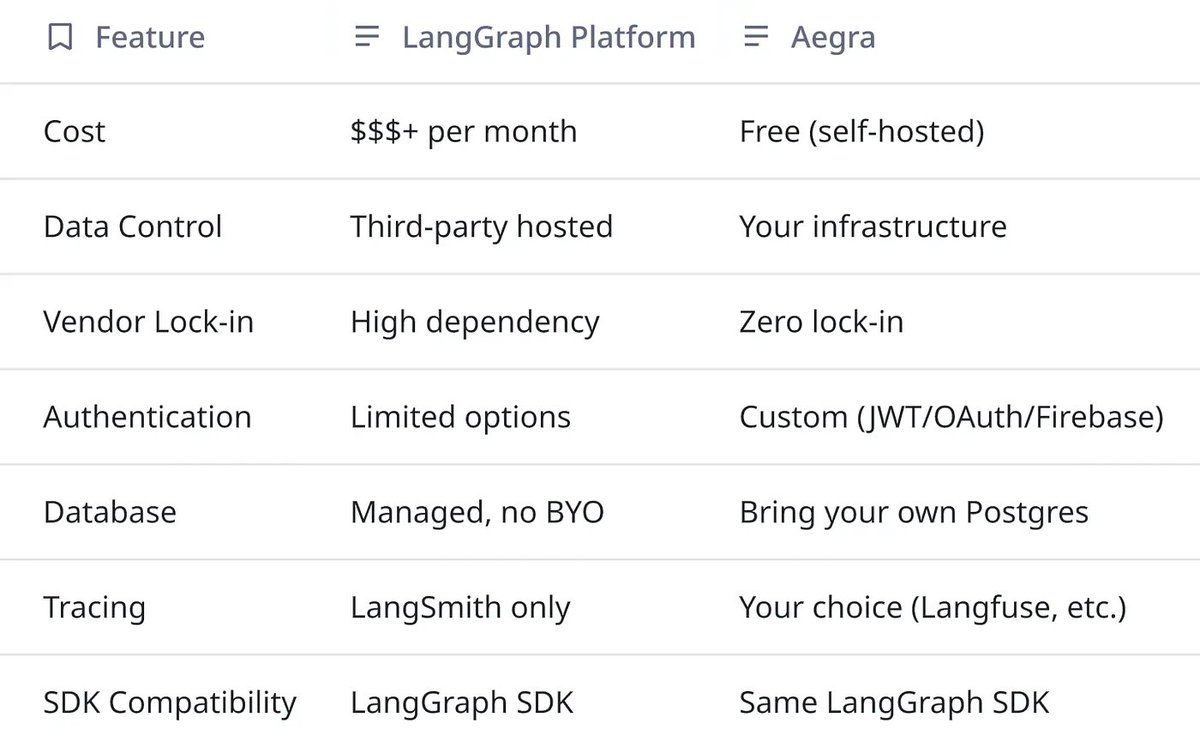
Compass is a free blueprint of a production-grade customer support agent built to demonstrate how modern agent systems are actually engineered and operated in real environments.
You can explore the live demo at compass.agentnative.dev and read the walk-through here (bit.ly/42eTvig)
You can also get the full repository (agentnative.dev/premium-asse…).
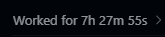
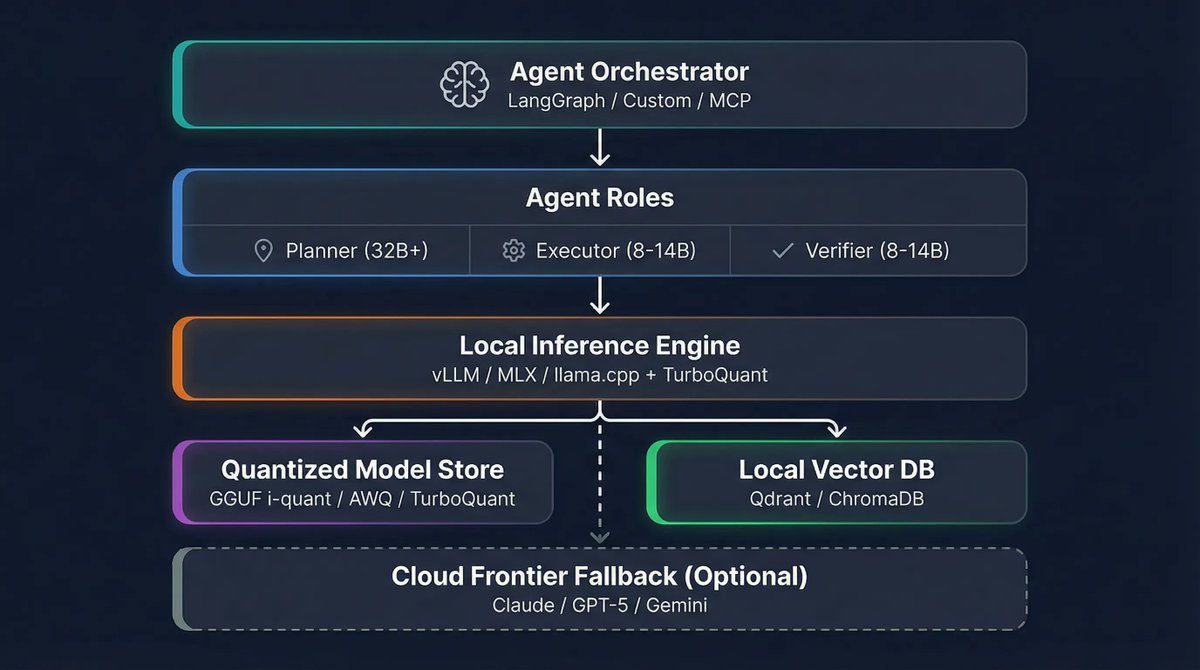
It includes infrastructure and service boundaries across LangGraph Deep Agents (@LangChain), @togethercompute, Kong, Caddy, @PostgreSQL, @Redisinc , @qdrant_engine , @redpandadata, @Minio, @PrometheusIO , Loki, @grafana, Vault, along with the APIs and UI surfaces needed to support both end users and operators.
The goal is to reason about the entire application topology end-to-end: request flow, state management, review workflows, data dependencies, observability, and operational control.
If you or your team is currently evaluating concepts such as deep agents, agentic workflows, multi-agent orchestration, RAG pipelines, guardrails, observability, prompt/version management, or human-in-the-loop controls, Compass gives you something much more useful than a conceptual diagram: it gives you a concrete system you can inspect, run, and study end-to-end.
2
290
Jun 3
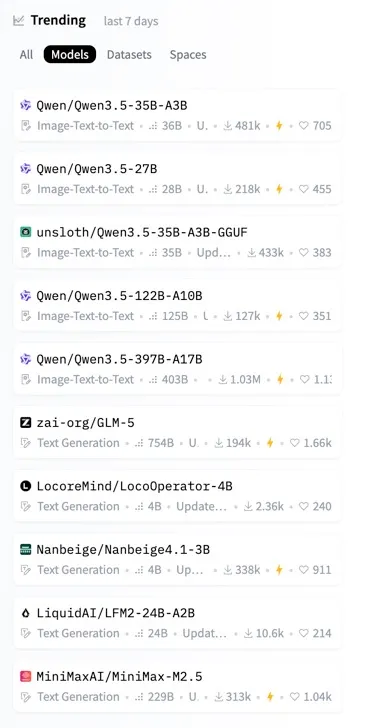
Personally I think that there is finally a cheap model with vision, long context, and coding-agent capability (minimax-m3) but also can’t help to ask “Is this benchmark-optimized but weaker in real use? Will it run locally or too large for local hardware?”
78
May 22
M5 MacBook Pro or NVIDIA DGX Spark or RTX PRO 6000?
Before answering this in depth, please think about the following question: "What part of the agent loop is your hardware supposed to accelerate?"
A chat UI and an agentic system stress hardware differently.
An agentic coding system cares about repeated long-context reads, tool calls, cache churn, parallel background workers, retrieval, subprocesses, test runs, container work, and sometimes many independent agents trying to use the same model server at once.
Rather than comparing “Mac versus NVIDIA” or “unified memory versus VRAM”, you should focus on the workload decomposition problem.
Before we start the hardware discussion, please do not buy hardware by comparing one headline tokens-per-second number.
Map your agent workflow to four bottlenecks:
- Model fit
- Prefill latency
- Decode throughput
- Concurrent serving behavior
Once you do that, the debate gets much less emotional and much more useful.
Read the deep dive here: medium.com/@agentnativedev/m…
1
1
1
336
May 21
Most developers are wondering:
How can I run a 70B model locally?
Can I run a 120B MoE?
Can I finally stop paying API bills?
People with 2x RTX 3090s, RTX 4090s, RTX 6000-class cards, Strix Halo systems, big-memory Macs, and mixed GPU rigs are able to run completely different class of models.
medium.com/@agentnativedev/4…
3
197
May 20
You are NOT ready for what's coming this week 🔥
- Qwen3.7 max
- Qwen3.7 27b/35b
- Minimax M3.0
- Gemini 3.5 Pro/Flash
- GPT-5.6
- Sonnet-4.8
- Kimi/GLM?
Which one are you evaluating first?
1
4
624
Apr 19
What GPU (RTX4090 or M5 Max 128GB) can run parts of the agent loop locally with good performance?
A single RTX 4090 can already handle a serious amount of coding work with the right open model, the right quantization, and a harness that doesn’t waste half your context window on boilerplate.
Apple Silicon machines like an M5 Pro 64GB or M5 Max 128GB are compelling for a different reason: not because they magically beat the cloud, but because they buy you local capacity, mobility, privacy, and larger-context workflows.
Meanwhile, the cloud still wins whenever you need top-end reasoning reliability, long-horizon planning, or consistently excellent output under pressure.
We want to make a developer-first case for how to think about consumer hardware in 2026 if you are building AI features, coding agents, or internal agentic workflows.
We will go through:
- What consumer hardware can realistically do today (including model benchmarks on Apple Silicon)
- State of open coding models in 2026
- Where local models already pull their weight and where they still break
- Why the harness matters almost as much as the model
- Why the best local setup is often a subagent or coprocessor, not a full replacement
Read the deep dive here: medium.com/@agentnativedev/m…
5
240
Apr 18
How about orchestrating a codebase on 5GB VRAM using a local Qwen3.5-35B-A3B (~25-30 tokens/sec through llama.cpp, 65k context, remaining layers offloaded to system RAM)?
Even better, when two simultaneous agent instances can run comfortably at ~15-20 t/s, which natively supports both thinking and non-thinking models (including Gemma 4), or can be pointed at heavy-compute cloud endpoints for complex architectural tasks.
If this sounds too good to be true, please keep reading.
Running local LLMs often feels like a downgrade from premium cloud subscriptions, but the real constraint is not just model quality, it is systems design.
Context windows are finite, and simply increasing token capacity does not eliminate the need to control what the model sees.
In practice, larger contexts frequently introduce more noise, more drift, and weaker reasoning when that context is not actively curated.
What local coding agents need is not a bigger monolithic chat loop, but a better execution architecture: a lighterweight terminal environment that separates planning from implementation.
The primary orchestrator should operate like a lead architect. It should inspect the codebase, build a concrete implementation plan, decompose work into atomic tasks, and dispatch those tasks to short-lived subagents with tightly scoped, isolated contexts.
Each coding subagent should execute one bounded change, return a compact summary of the result, and terminate.
That keeps the planner’s context clean, prevents edit history from ballooning, and avoids the gradual degradation you get when every action is forced through one ever-expanding conversation.
The result is a system that behaves less like a confused chatbot and more like a disciplined engineering team with clear task boundaries and fast feedback loops.
That is the idea behind Late.
Late is a deterministic coding-agent orchestrator built to make local LLMs viable for serious agentic software development.
Instead of dumping an entire repository into a single context window and hoping the model stays coherent, it maps the codebase, maintains a high-level control plane, and spawns ephemeral execution agents to perform precise, exact-match code edits.
By mirroring the structure of a real engineering organization, Late reduces token bloat, limits context pollution, and improves reliability under long-running coding workflows.
agentnativedev.medium.com/ou…
3
199
Mar 31
we can now confirm that it's conscious
Mar 31

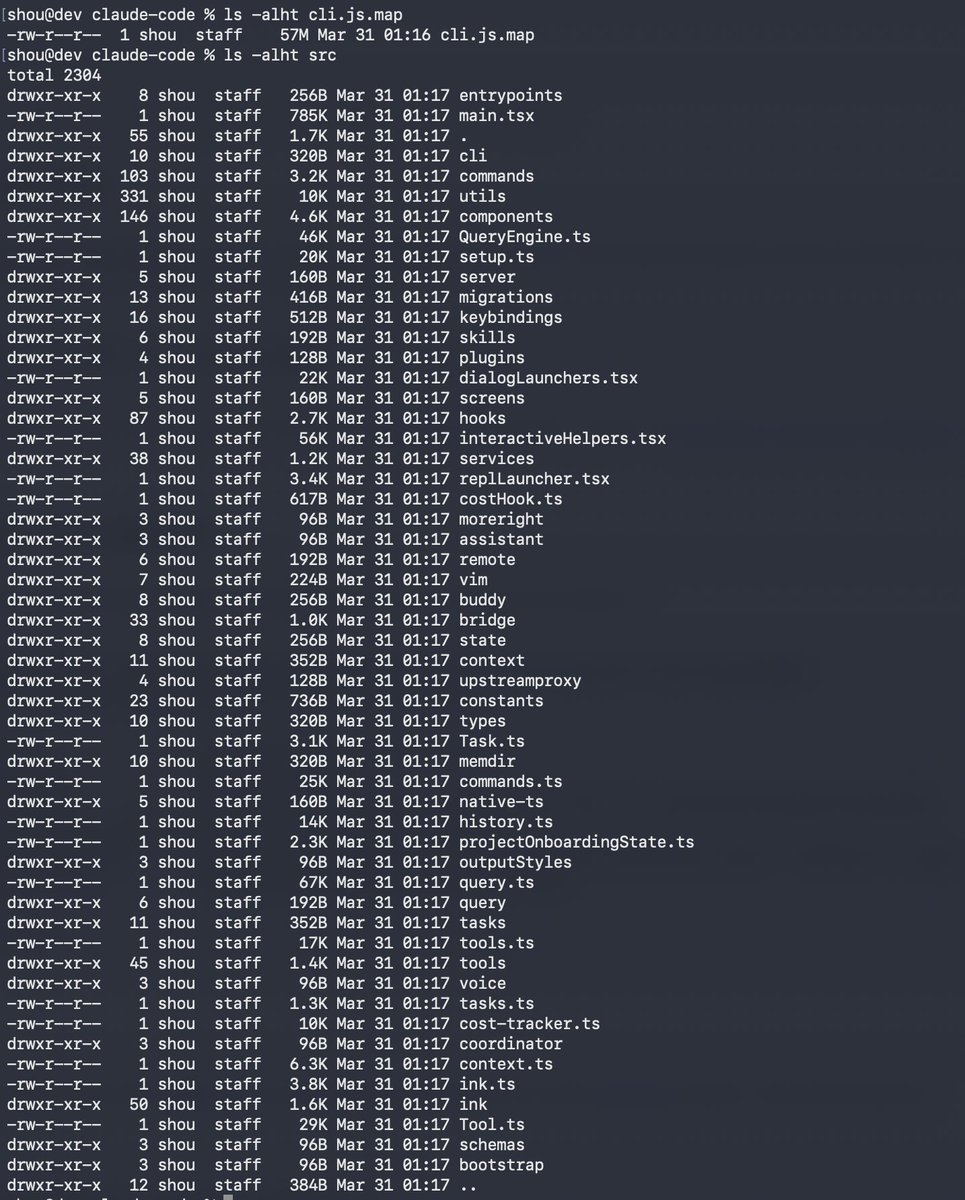
Claude code source code has been leaked via a map file in their npm registry!
Code: pub-aea8527898604c1bbb12468b…
244

🚨 CRITICAL: Active supply chain attack on axios -- one of npm's most depended-on packages.
The latest axios@1.14.1 now pulls in plain-crypto-js@4.2.1, a package that did not exist before today. This is a live compromise.
This is textbook supply chain installer malware. axios has 100M weekly downloads. Every npm install pulling the latest version is potentially compromised right now.
Socket AI analysis confirms this is malware. plain-crypto-js is an obfuscated dropper/loader that:
• Deobfuscates embedded payloads and operational strings at runtime
• Dynamically loads fs, os, and execSync to evade static analysis
• Executes decoded shell commands
• Stages and copies payload files into OS temp and Windows ProgramData directories
• Deletes and renames artifacts post-execution to destroy forensic evidence
If you use axios, pin your version immediately and audit your lockfiles. Do not upgrade.
541
4,026
16,172
12,403,474
agentnative retweeted

Mar 26
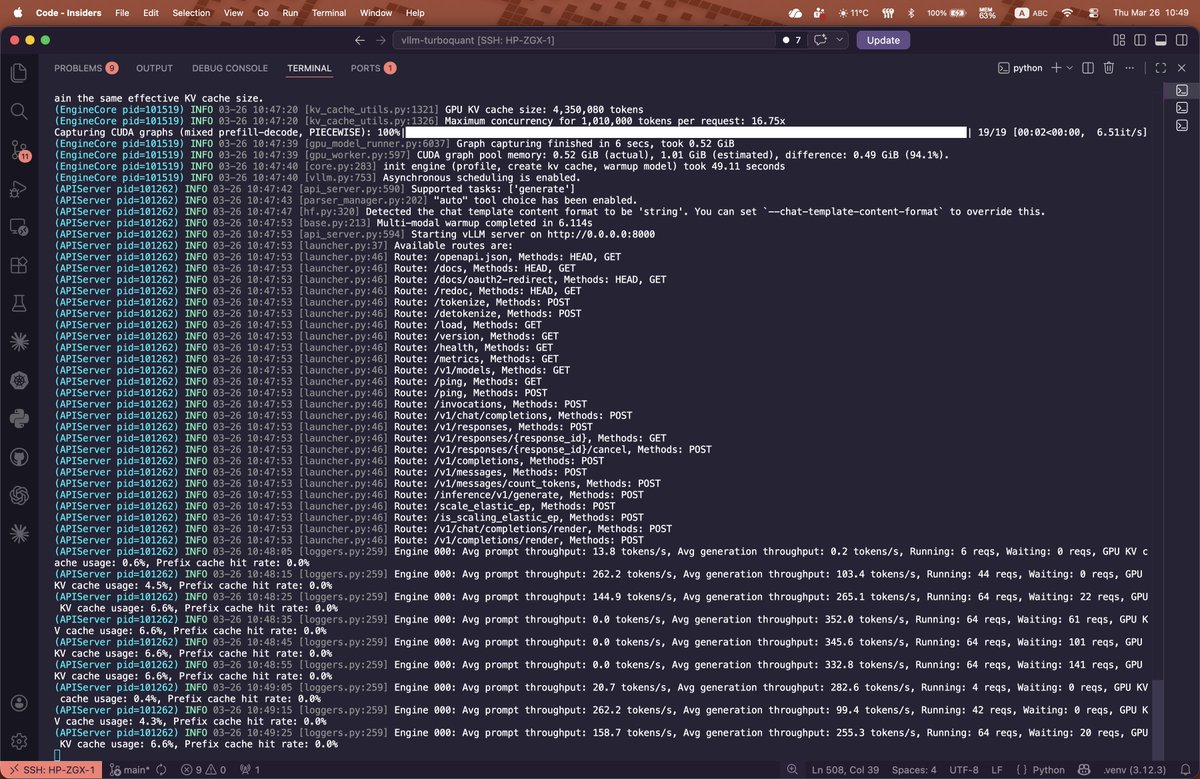
4,350,080 tokens KV cache TurboQuant 3.5
1,010,000 tokens context YaRN
Qwen3.5-35B-A3B AWQ
vLLM 0.18.1rc1
All running on one GB10 GPU
Cold start, no prefix cache tricks. From the logs:
→ 352 t/s peaks
→ 260 t/s sustained
→ 64 concurrent requests
It's not fully optimized yet
19
34
372
22,120
Mar 25
Multi-agent system that previously required three separate API subscriptions running at $200/month each can now run on a single workstation with a couple of RTX 4090s, entirely offline, with no per-token costs.
You can read the story here: medium.com/@agentnativedev/t…
1
2
156
Mar 25
The moment an agent can call tools, delegate work, remember state, wait on external systems, or trigger a real-world action, you are dealing with a distributed system.
Read the deep dive here: medium.com/@agentnativedev/d…
2
288
Mar 24
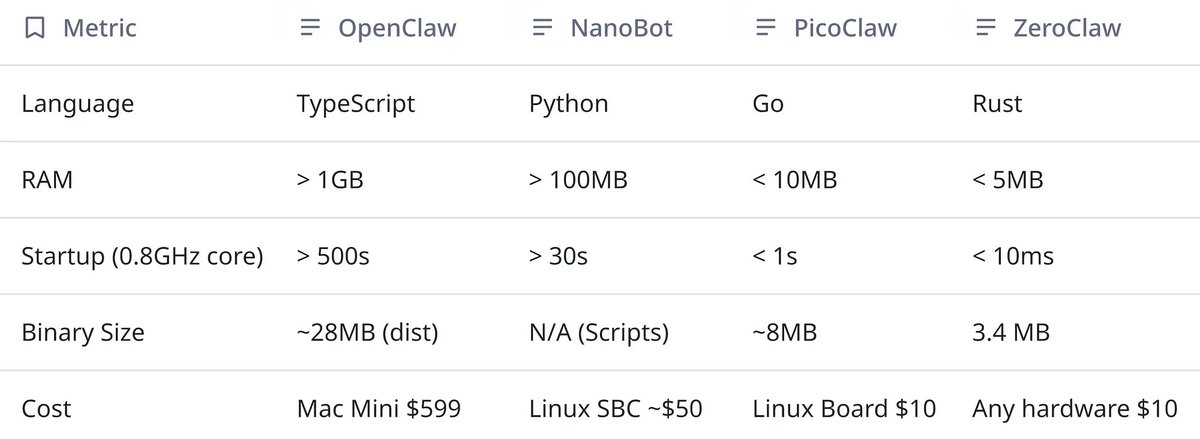
So how do you operate OpenClaw agents safely, repeatably, and under failure?
medium.com/@agentnativedev/k…
1
2
1
148
Mar 18
All image generation services keep timing out.. internet is about to get wild.
1
106
agentnative retweeted

Mar 16
@agentnativedev puts out some incredible content on his site and on Medium. His latest article on MiroFish is 👌
agentnativedev.medium.com/mi…
1
2
200
Mar 9
The hardest part about interacting with enterprise tools has always been the plumbing, OAuth dance, pagination.
1
1
143
Mar 9
It also ships with Core Google Workspace API skills, Helpers, Personas, and Recipes that make tools like Zapier and n8n look painfully manual.
1
50