
Bioinformatician and C/C lover. Interested in computational biology and fast algorithms. lutfia95@genomic.social
Joined May 2012
- Tweets 307
- Following 1,919
- Followers 128
- Likes 1,206
Photos and videos
Pinned Tweet

20 Apr 2025
63
Ahmad Lutfi lutfia95@genomic.social retweeted
RapCluster: Bridging the Reproducibility Gap in Clustering Analysis biorxiv.org/content/10.64898… #biorxiv_bioinfo
3
4
426
Ahmad Lutfi lutfia95@genomic.social retweeted

攻略本のレトロなイラストに魅入ってしまったので、今日はドラクエⅠの攻略本のイラストを✨️📚️
ドラクエⅠは武具が少ないので防具はこれで全部ですね☺️
シンプルな鎧からロトの鎧の全身完璧の鎧まで👍️こういうイラストがゲーム本編で観れると良いですね〜🎮️



3
30
349
15,375
Ahmad Lutfi lutfia95@genomic.social retweeted

Mar 7

5
18
258
4,161

看護師の不足は世界的な問題で、WHOの予想では2023年までに1300万人が不足する──
本日3/6(金)より公開の映画『ナースコール』試写で見ました🥂🩵
ガチで素晴らしい映画が公開されました。
急性期病院で働く看護師を“追うだけ”の映画ですが、これは医療を利用するすべての人に届けたい。
まず、25床ほどの外科系病棟で看護師が2人というね。
医師も看護師も配置は最小限。
張り詰める空気、緊急オペ、空の点滴バッグ、病名未告知の患者、無断離院、繰り返すナースコール、予期せぬ心肺停止、DNAR未聴取、そしてオマケに夜間のクレーム。
看護師をしている友人が、その仕事を“3K”だと言っていたのを思い出しました。
「キツイ・汚い・危険」の意味だそうです。
それでも彼ら、彼女たちは、患者のそばに立ち続けている。
本作は、そんな医療従事者たちの現場をただ見つめ続けることで、その過酷さとプロフェッショナリズムを浮かび上がらせます。
ストレスを感じるような緊張感とリアリズム。
正直しんどいタイプの映画だと思います。
類似作品として、レストランを舞台にした『ボイリング・ポイント』なんかは何回見ても楽しく見れるけど、これはきつい。
今も精神をすり減らしながら24時間戦い続ける医療従事者たちへの讃歌であるとともに、医療の未来に対する警鐘とも受け取れる内容だと感じました。必見です。
【あらすじ】
とある州立病院の外科病棟に出勤したフロリアは、プロ意識が強い看護師だ。
人手不足が常態化している職場はただでさえ手一杯だが、この日の遅番のシフトは普段以上に過酷だった。
チームのひとりが病気で休んだため、フロリアはもうひとりの同僚と手分けして26人の入院患者を看て、インターンの看護学生の指導もしなくてはならない。
それでも不安や孤独を抱えた患者たちに誠実に接しようとするフロリアだったが、患者の要望やクレーム、他の病棟からひっきりなしにかかってくる電話、緊急のナースコールへの対処を迫られ、とてもひとりの手には負えない苦境に陥っていく。
やがて極限の混乱の中、投薬ミスを犯して打ちひしがれたフロリアは、さらなる重大な試練に直面することに……。



8
516
3,151
373,302
Ahmad Lutfi lutfia95@genomic.social retweeted

Jan 28
AlphaGenome is out in @nature today along with model weights! 🧬
📄 Paper: nature.com/articles/s41586-0…
💻 Weights: github.com/google-deepmind/a…
Getting here wasn’t a straight path. We sat down @googledeepmind to discuss the story behind the model, paper & API: youtu.be/V8lhUqKqzUc

29
477
1,862
225,792
Ahmad Lutfi lutfia95@genomic.social retweeted

20 Dec 2025
A single-cell cytokine dictionary of human peripheral blood: 9.7M cells, 12 donors, 90 cytokines biorxiv.org/content/10.64898…

3
43
225
18,109
Ahmad Lutfi lutfia95@genomic.social retweeted

16 Dec 2025
CAMP: Coreset Accelerated Metacell Partitioning enables scalable analysis of single-cell data biorxiv.org/content/10.64898…
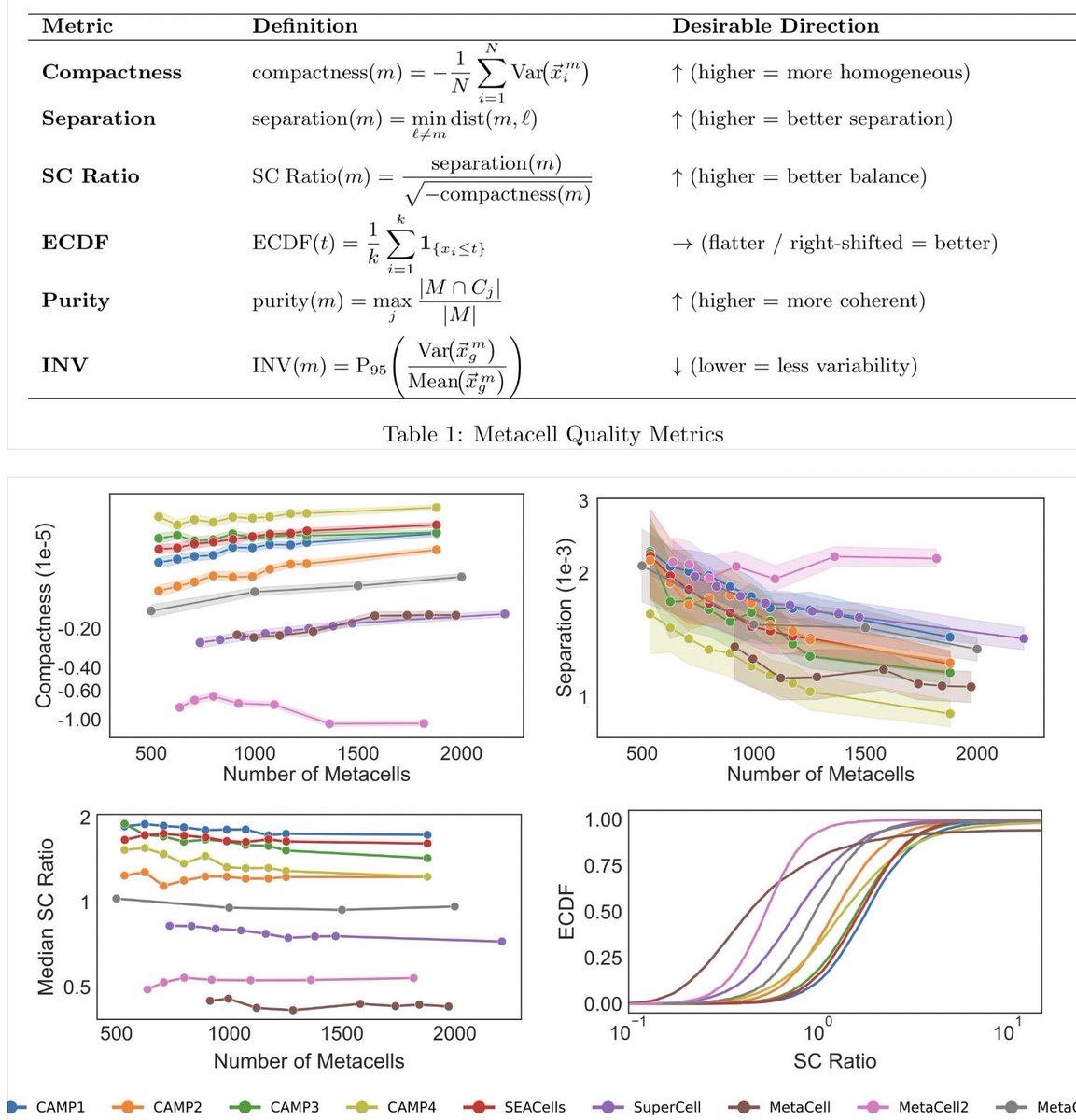
1
3
11
1,134
Ahmad Lutfi lutfia95@genomic.social retweeted

17 Dec 2025
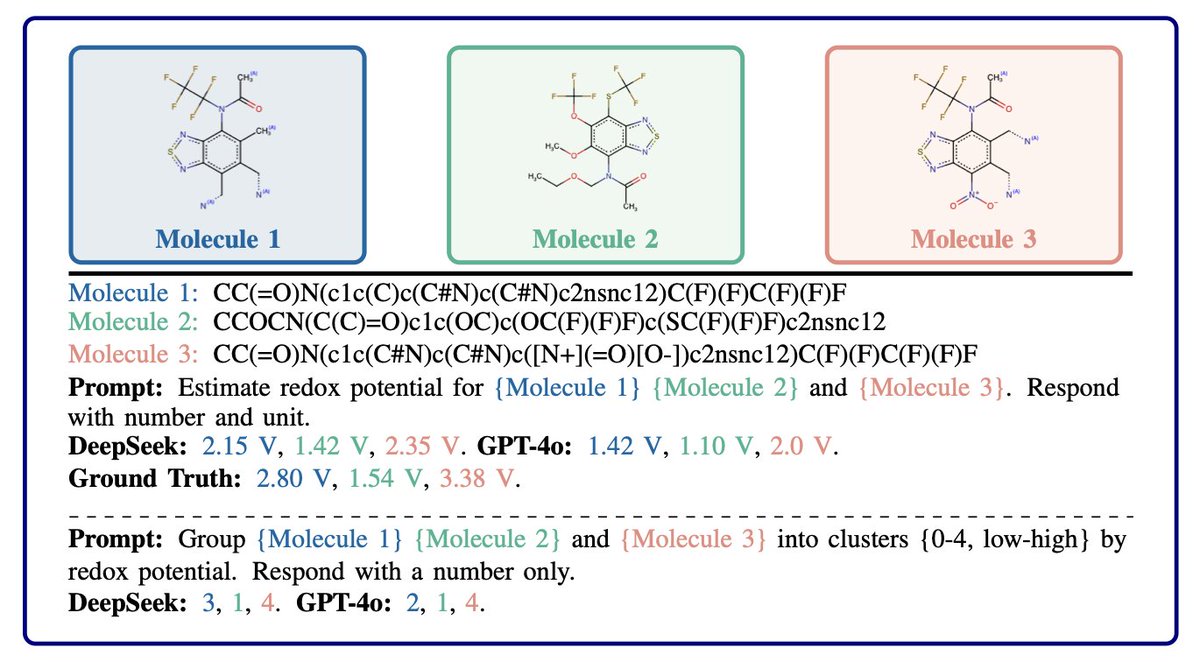
Informing Acquisition Functions via Foundation Models for Molecular Discovery
1. This paper introduces a novel Bayesian Optimization (BO) method called LLMAT, which leverages large language models (LLMs) and chemistry foundation models to enhance molecular discovery. The method bypasses the need for explicit surrogate modeling, directly using priors from LLMs to inform acquisition functions.
2. LLMAT employs a tree-structured partitioning of the molecular search space, enabling efficient candidate selection through Monte Carlo Tree Search (MCTS). This hierarchical approach allows for refined acquisition functions at each node, improving scalability and robustness in high-dimensional spaces.
3. The method incorporates coarse-grained clustering using LLMs to group molecules based on property values, significantly reducing computational costs by focusing evaluations on promising clusters. This strategy enhances BO performance without requiring extensive fine-tuning of LLMs.
4. LLMAT demonstrates superior performance across multiple real-world chemistry datasets, outperforming traditional BO methods and other LLM-based approaches in terms of sample efficiency and computational efficiency. The results highlight the effectiveness of integrating general LLMs with specialized models.
5. The study also includes comprehensive ablation studies, showing the benefits of different components such as meta-learning for stable partitioning and the impact of varying tree depths on optimization performance. These insights provide a deeper understanding of the method’s robustness.
📜Paper: arxiv.org/abs/2512.13935
2
5
13
1,376
Ahmad Lutfi lutfia95@genomic.social retweeted
16 Dec 2025
Scikit-bio: a fundamental Python library for biological omic data analysis nature.com/articles/s41592-0…
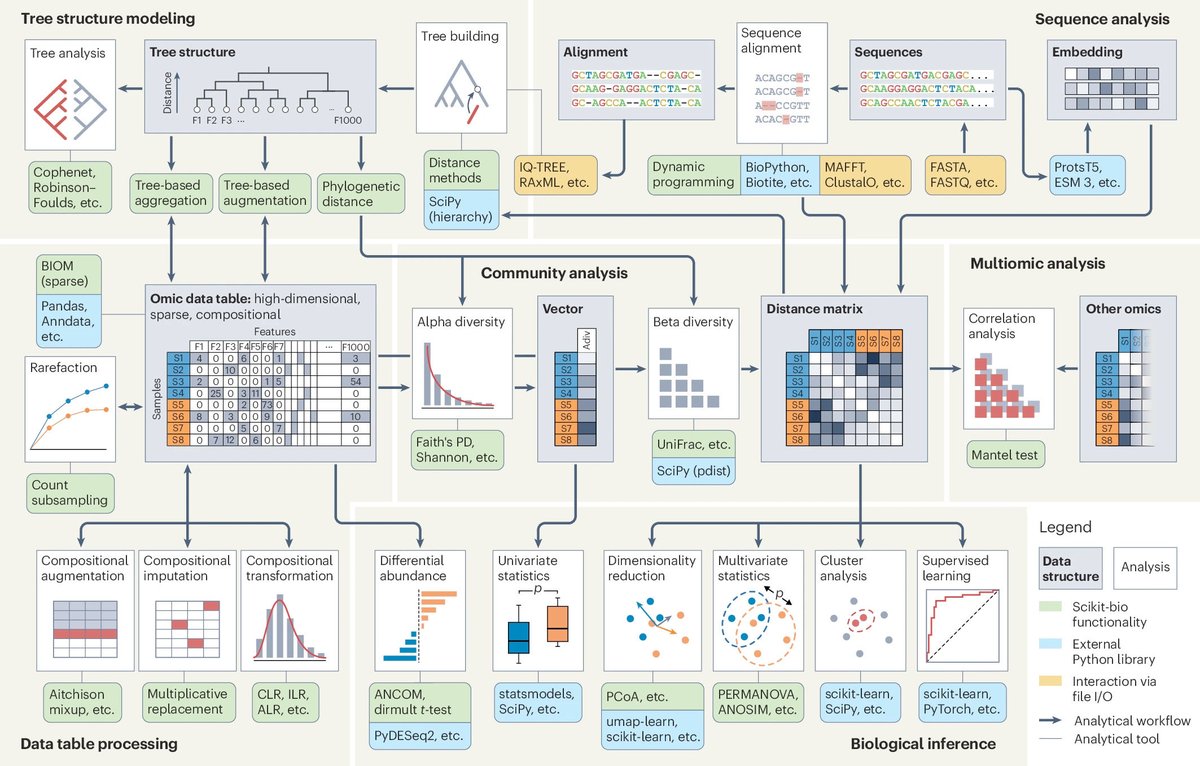
1
3
18
884
Ahmad Lutfi lutfia95@genomic.social retweeted

17 Dec 2025
This paper shows how to add sliding window attention to full attention models, without retraining, while keeping long context quality.
It makes long prompts much cheaper and faster to read, because the model stops comparing every token to every earlier token, and instead mostly looks at a local window.
Their practical outcome is a set of simple deployment recipes that let existing full attention models use sliding windows at inference time without full retraining, so teams can cut prefill cost while keeping most of the long context accuracy, especially by using sliding windows for prefilling but switching back to full attention while generating the answer.
Full attention is expensive because every token compares with all earlier tokens, so the work grows fast with length.
Sliding window attention makes each token look only at a recent chunk, but that surprises models trained to see all history.
Their fix, Sliding Window Attention Adaptation, mixes windowed prompt reading, keeps the beginning tokens visible, and leaves some layers as full attention.
Full attention decode is key, it reads the prompt with a window, then generates with full attention so the answer can use the context.
They use chain of thought reasoning, and Low Rank Adaptation fine-tuning, meaning only a small addon is trained, to make sliding windows behave.
No 1 trick works, but combining methods recovers most long context accuracy and cuts the cost of reading prompts.
----
Paper Link – arxiv. org/abs/2512.10411
Paper Title: "Sliding Window Attention Adaptation"

4
20
128
7,229
Ahmad Lutfi lutfia95@genomic.social retweeted
6 Nov 2025
DL4Proteins Jupyter Notebooks Teach how to Use Artificial Intelligence for Biomolecular Structure Prediction and Design
1. This novel educational resource introduces a series of interactive Jupyter notebooks designed to teach fundamental machine learning concepts and their applications in protein structure prediction and design. The notebooks are accessible via a web browser, making state-of-the-art AI tools available to learners worldwide.
2. The notebook series is divided into three parts: foundational machine learning concepts, advanced deep learning architectures, and cutting-edge protein design pipelines. It progresses from basic neural networks to complex models like AlphaFold2 and diffusion models, providing a comprehensive learning experience.
3. A key innovation is the use of Google Colab, which offers free access to powerful GPUs, eliminating the need for expensive computational resources. This democratizes AI education in protein design, allowing students and researchers to experiment with advanced models without significant barriers.
4. The notebooks are tailored for a diverse audience, including undergraduate and graduate students, wet lab professionals looking to incorporate AI into their workflows, and educators seeking to integrate AI literacy into their curricula. The interactive format ensures hands-on learning and practical application.
5. The educational approach includes active learning questions, visual aids, and real-world examples, enhancing understanding and retention. The notebooks also provide resources for further reading, encouraging learners to delve deeper into the field.
6. Pilot testing at Johns Hopkins University demonstrated the effectiveness of these notebooks in teaching AI for protein design. Students with varying levels of programming experience were able to grasp complex concepts and apply them to impactful projects, showcasing the potential of this educational tool.
7. Looking ahead, the DL4Proteins repository will remain dynamic, with additional notebooks added as new models emerge. This ensures that learners stay updated with the latest advancements in AI-driven protein design and structure prediction.
📜Paper: arxiv.org/abs/2511.02128v1
#AI #ProteinDesign #MachineLearning #Education #BiomolecularStructures #DL4Proteins #OpenAccess
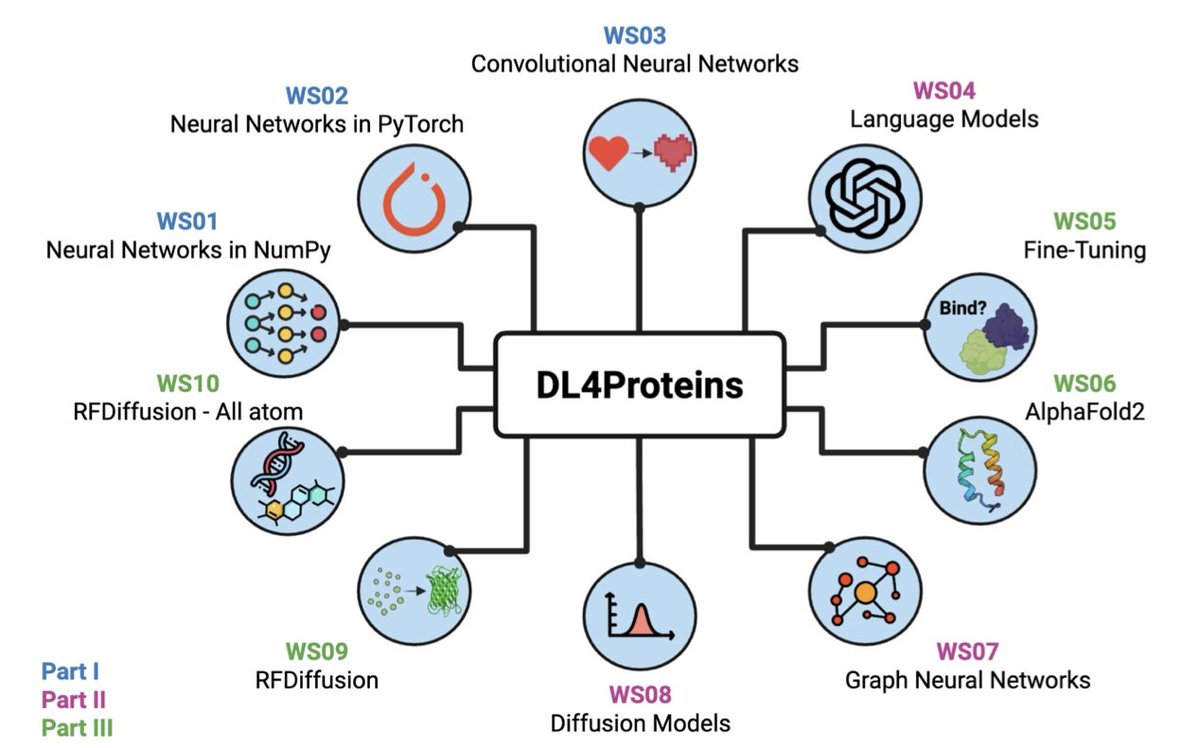
1
15
49
2,717
Ahmad Lutfi lutfia95@genomic.social retweeted
31 Oct 2025
A gene program dictionary of human cells biorxiv.org/content/10.1101/…
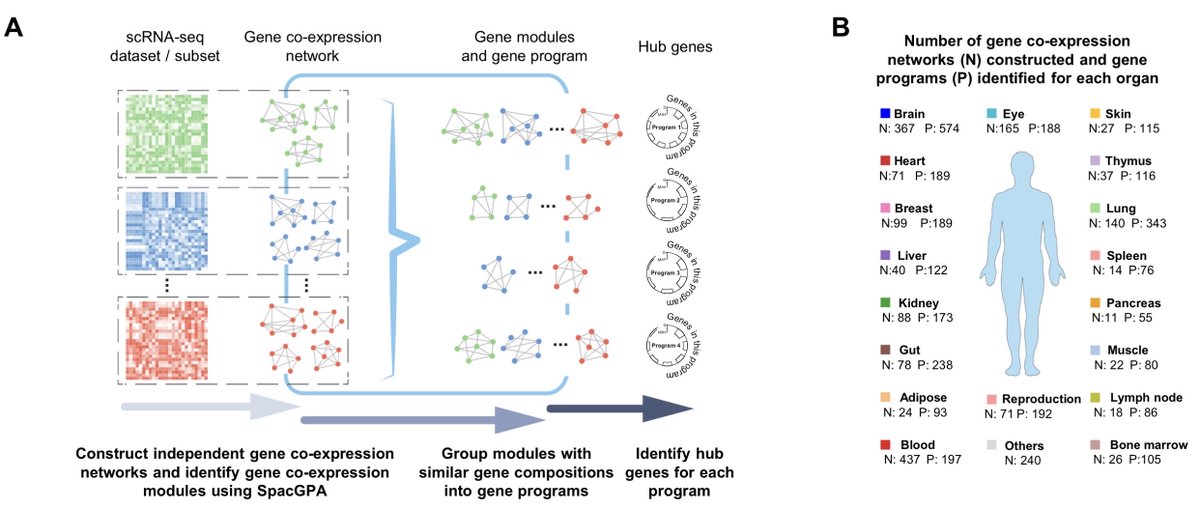
2
30
132
11,022
Ahmad Lutfi lutfia95@genomic.social retweeted

3 Oct 2025
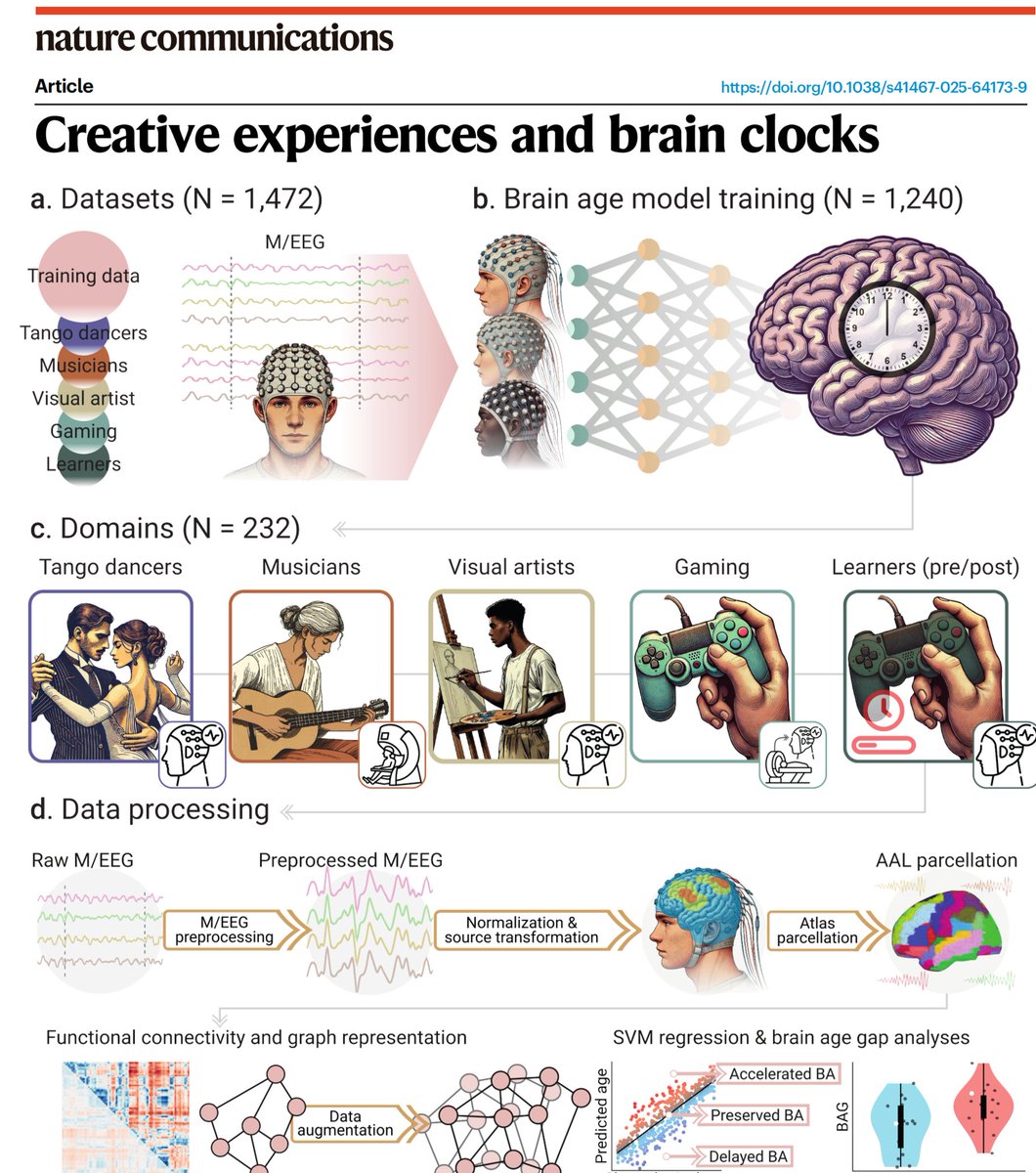
Creative Minds, Younger Brains: Engaging in music, dance, painting, or even (some) gaming is linked to delayed brain aging.
Article: doi.org/10.1038/s41467-025-6….
🧵1/5
Biophysical modeling, graph theory, and Neurosynth analyses reveal plasticity-driven efficiency in regions most vulnerable to aging. Out Today in @NatureComms, congrats @carlosmig_12 and colls! @CreativeAgeIntl @j_artshealthlab @CreativeBrainWk
21
527
2,061
151,207
Ahmad Lutfi lutfia95@genomic.social retweeted
2 Sep 2025
Scafari: Exploring scDNA-seq data academic.oup.com/bioinformat…

1
11
44
2,432
Ahmad Lutfi lutfia95@genomic.social retweeted

27 Aug 2025
Neural Network

5
117
621
46,145
23 Aug 2025
RT @OPcom_info: 【TVアニメ #ONEPIECE 放送情報】
8/24(日)よる11:15放送
1141話「頼もしき援軍!ドリーとブロギー到着!」の先行カットを公開✨
懐かしき巨人の友の上陸により、エッグヘッド脱出は前進するが…!?
明日の放送をぜひお見逃し…
402
Ahmad Lutfi lutfia95@genomic.social retweeted

2 Aug 2025
I did not know that, for any random variable x,
| mean(x) - median(x) | <= stdev(x)
Direct proof:
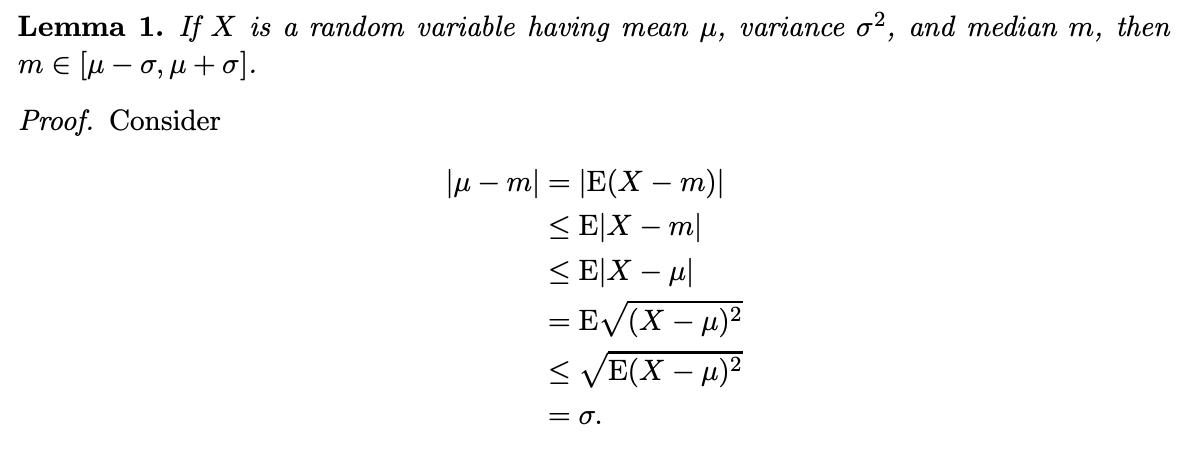
51
196
2,831
245,280
Ahmad Lutfi lutfia95@genomic.social retweeted

1 Aug 2025
This is possibly the best resource to learn about optimization algos

8
181
1,670
81,725
Ahmad Lutfi lutfia95@genomic.social retweeted

22 Jul 2025
DANCE 2.0: Transforming single-cell analysis from black box to transparent workflow biorxiv.org/content/10.1101/… #biorxiv_bioinfo
2
12
1,264
Ahmad Lutfi lutfia95@genomic.social retweeted

30 May 2025
Predicting expression-altering promoter mutations with deep learning science.org/doi/10.1126/scie… 🧬🖥️🧪 github.com/Illumina/Promoter…
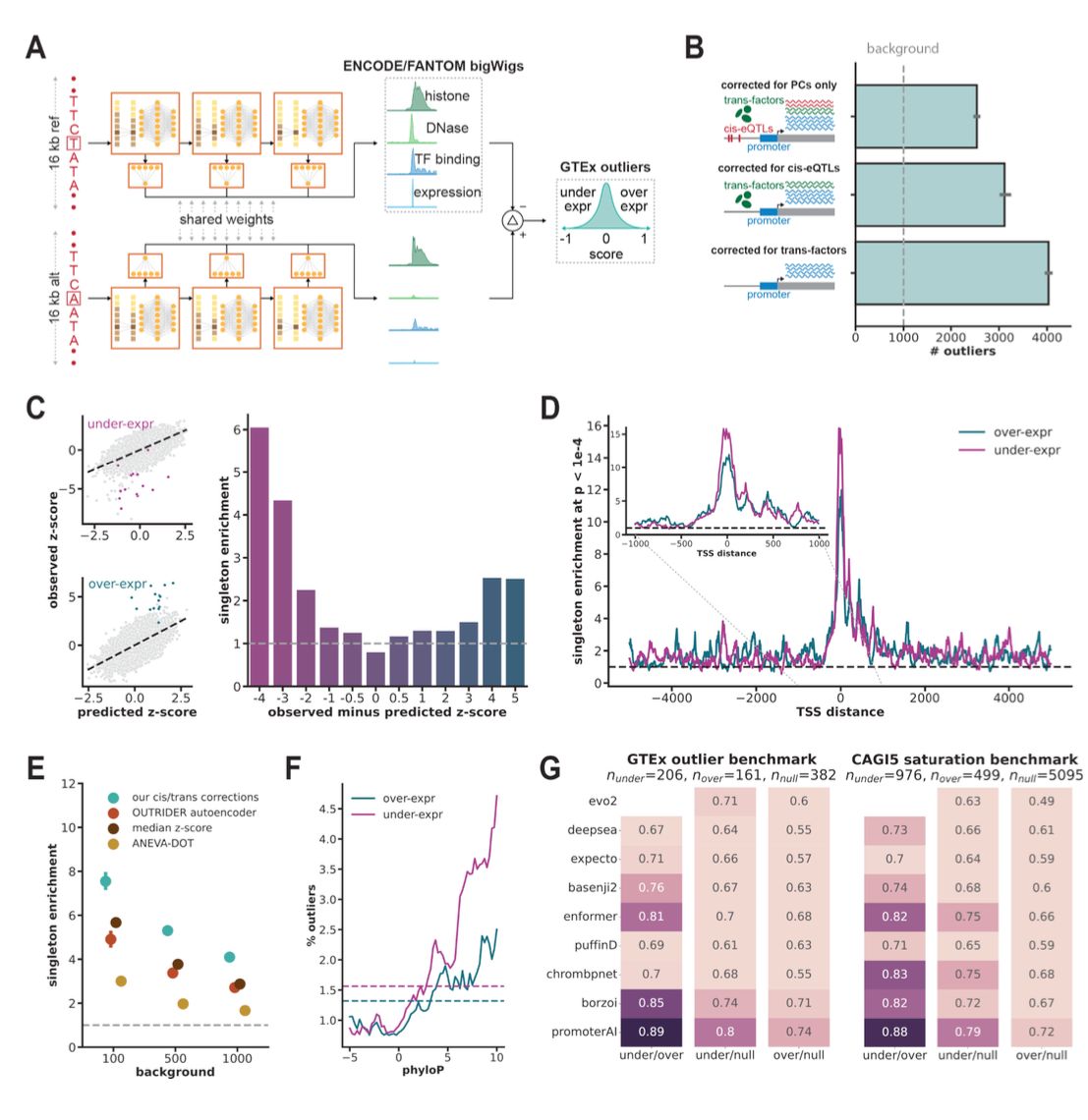
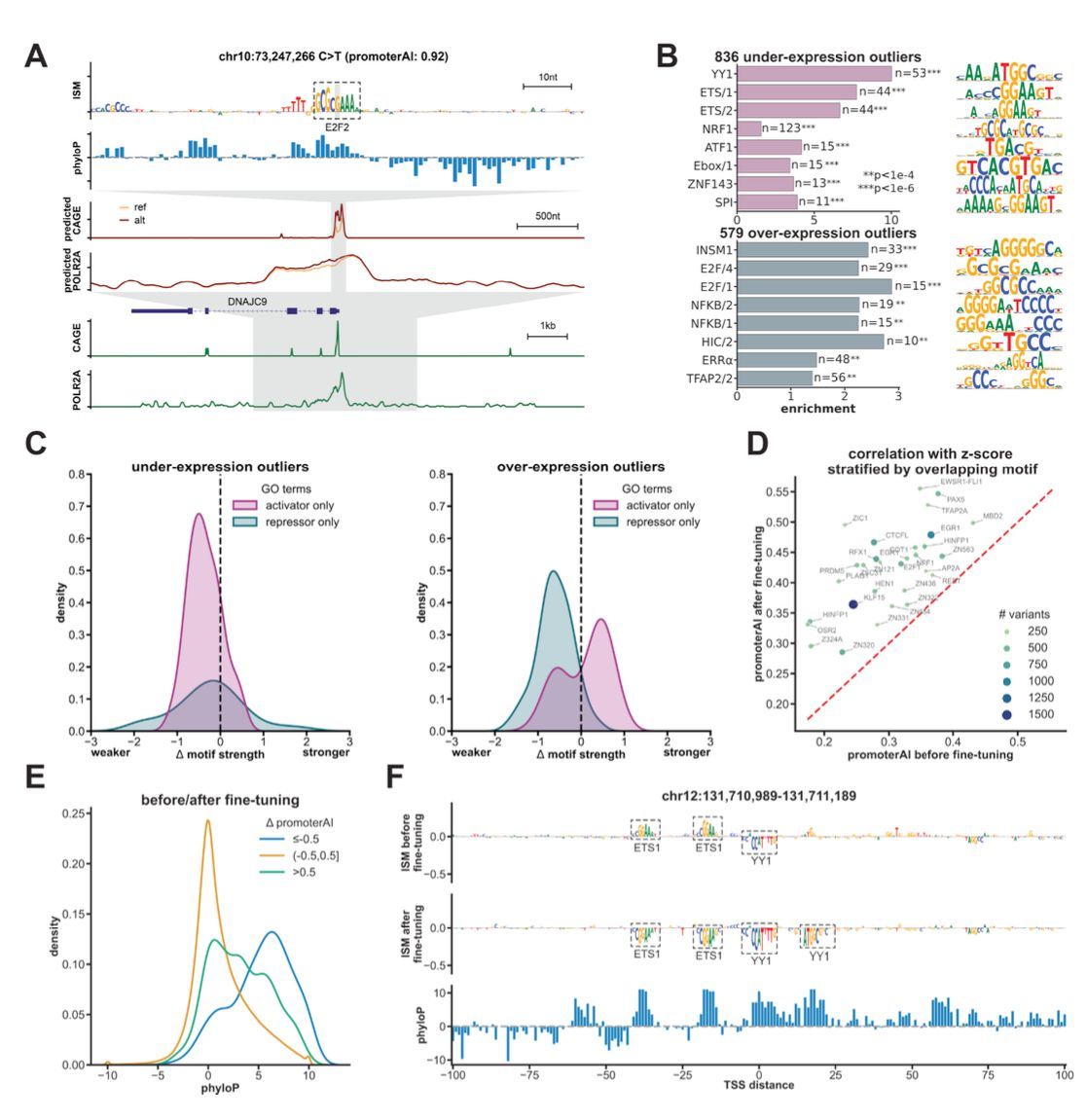
28
130
5,673