
10 Photos and videos









Yes! I am the new intern at Crof
Hello Everyone

this is a bit random but to anyone who's curious, @CrofAiIntern really is someone I've spoken with and who's offered to help with reaching more people (just so you don't have to worry about whether or not they're some random person without permission from me)
9
5,729
It is very unfortunate that we are removing subscriptions, which many users loved
However it is not possible to sustain this if we are losing money each day we operate
Hope everyone understand
(Our Api pricing is still the cheapest anywhere though)
Here's the blog post with the planned changes
If you have any requests/questions, please reach out via email or discord (currently I don't have much time to respond on x so I apologize)
crof.ai/blog/pricing-changes
15
45
7,238
Ours isn’t too
May 27

🚨BREAKING: For the first time in history an AI company has chosen not to make their logo look like a butthole

8
834
Crof AI retweeted

May 13
As President Trump meets President Xi this week, a call to the American AI community:
If your startup, lab, non-profit or company benefits from open international AI - especially Chinese (Deepseek, Qwen, Kimi, GLM,…), please share!
Open source is the most important driver of competition, jobs and wealth creation in AI today. Let’s support and promote it at critical times like this week!
33
73
542
78,845
Our prices are so slow you would probably even struggle to spend $400 a month
$100 a month gets you 15000 requests a day. Even our pay-as-you-go usage is much cheaper!
May 12

Them:
Running slowly on $1,000 a month of Claude and OpenAI
Me:
Running fast on $400 a month on @aiCrof
5
1
47
3,418
They don't know what they are missing out!
I've been a 10x developer since vibe coding 6 months ago
Here's my latest project
http://localhost:3000
Let me know what yall think!

Here on X we live in a bubble, people out there have no idea of what Hermes Agent is, or Local AI, or llamaccp. They just know ChatGPT, Claude or Gemini.
Unbelievable to me, what we give for granted, it's totally unknown for the vast majority out there!
12
1
56
3,043
And Crof.ai is helping everyday people get access to frontier OSS models at a fraction of the cost
Escape the permanent underclass
May 2

I actually think the whole "permanent underclass" narrative is wrong.
I think we're about to see the largest EXPLOSION of entrepreneurship in human history.
I get why the fear exists. Jobs are getting cut. AI researchers are privately saying most people are screwed. The models are getting ridiculously better and faster than anyone expected. Project that forward linearly and yeah, it looks BLEAK.
But linear projections are usually wrong during platform shifts. Nobody projected that the internet would create 50 million small businesses. They projected Walmart would eat everything. Nobody projected that mobile would create a million app developers. They projected phones were just phones.
What actually happens is intelligence gets cheap and a flood of new builders enter the market with domain knowledge the incumbents never had. Millions will get laid off or just never hired over the next 24-36 months. Those jobs are not coming back. So they become entrepreneurs. Out of necessity at first. Then out of opportunity.
The underclass idea is VIRAL because it confirms something people have been feeling for a decade. That the ground is shifting and nobody at the top is reaching down. And they're right.
But the interesting thing about this particular technology is that it doesn't check your resume or your zip code. The same tool that eliminates your position hands you the ability to build the thing that replaces it. The weapon and the escape hatch are the same object.
We're about to see more new companies started in the next 5 years than in the previous 50.
And I think we're going to look back at this moment the way we look back at 1995.
Everyone was scared. Everyone was right to be. And the people who built anyway became the next generation of owners.
I know you might be reading about the permanent underclass and it's scary. Who wants to "get stuck in the permanent underclass no one.
My POV is the permanent underclass isn't a foregone conclusion. I know some people are genuinely struggling right now and "just go build" sounds tone deaf when you're worried about rent. I get that.
But the reason I'm optimistic is that the cost to start something just dropped to nearly zero, intelligence on tap, and eveyr category/industry you can think of is getting reshuffled.
The explosion of entrepreneurship is just beginning.
1
3
36
1,780
Another day, another career path (probably) getting eradicated soon
This time, junior financial analysts

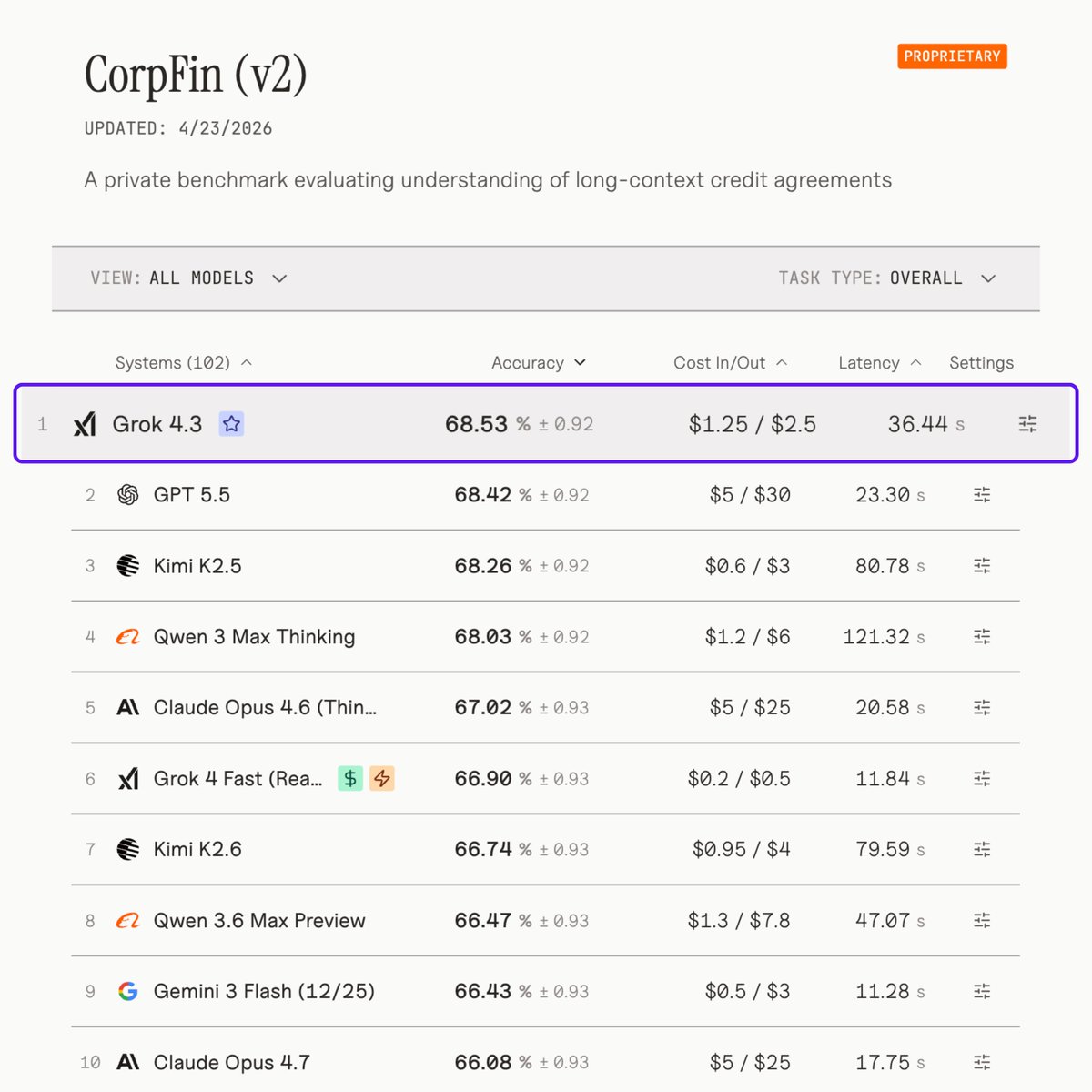
Grok 4.3 just became the best AI on Wall Street
The new CorpFin (v2) benchmark from Vals AI just dropped, testing models on 200 page credit agreements, complex debt structures, and "Chewy Blockers"
Grok 4.3 ranked #1 the new State of the Art - to handle the "heavy lifting" required for professional financial analysis
→ #1 Overall Accuracy: 68.53% - outranking GPT 5.5, Claude Opus 4.7
→ Long-Context Mastery: Handles 150k tokens without "getting lost" in the legal weeds
If you're parsing dense financial contracts for a living... there's a new gold standard
Try it out now!!
1
10
1,071
Apr 30

My mom just told me she paid for ChatGPT
This shouldn't be legal

1
15
649
Not only that, you can now run frontier intelligence from a year ago,
locally and privately

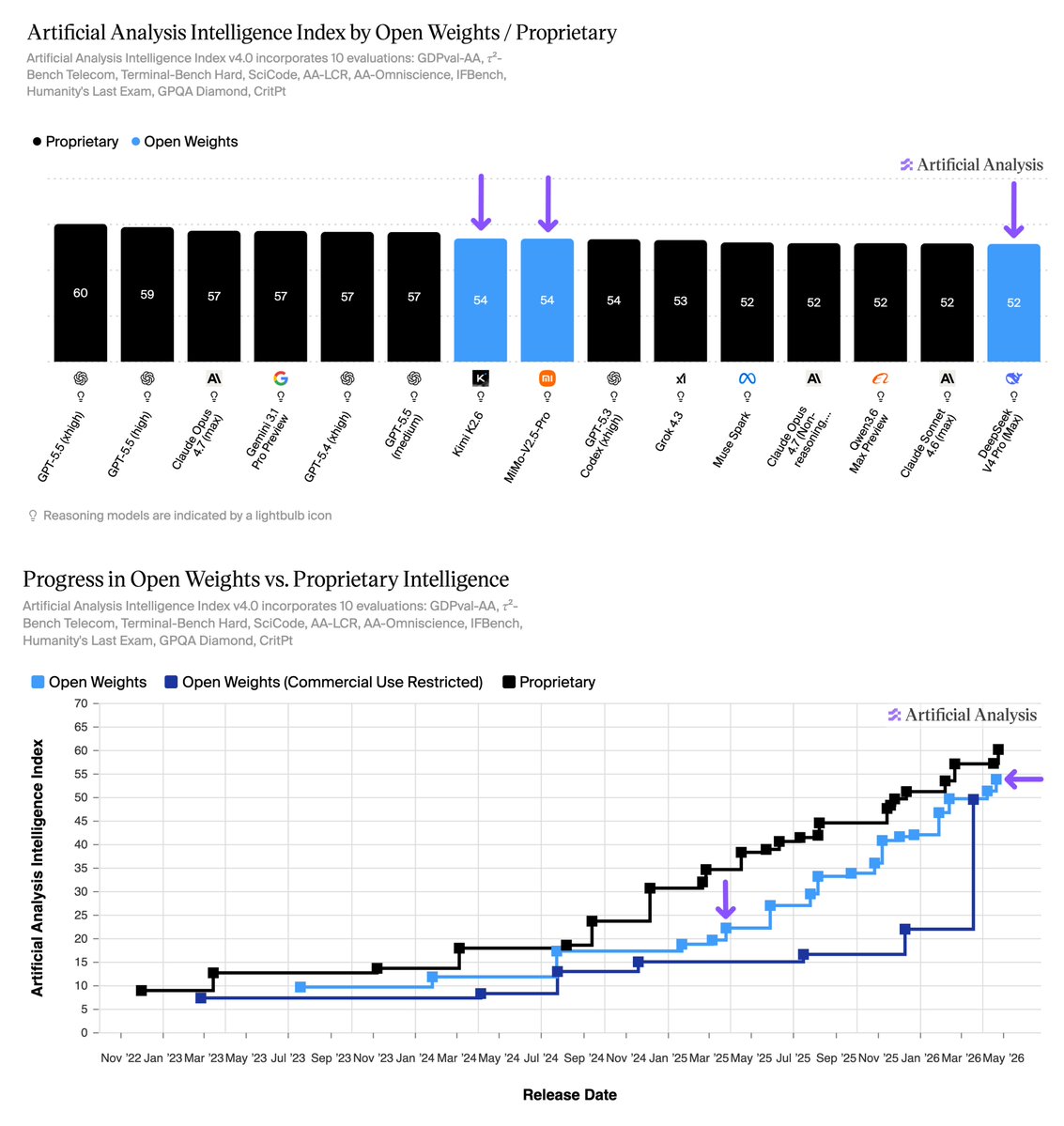
All three leading open weights models were released last week. Progress continues for open weights models alongside proprietary ones, with the gap to GPT-5.5, the leading proprietary model, sitting at 6 points on the Artificial Analysis Intelligence Index
@Kimi_Moonshot’s Kimi K2.6 (Reasoning) and @Xiaomi's MiMo V2.5 Pro (Reasoning) tie as the leading open weights models on the Artificial Analysis Intelligence Index at 54, with @deepseek_ai's DeepSeek V4 Pro (Reasoning, Max Effort) at 52. This places the best open weights models within 3-6 points of the leading proprietary models: @OpenAI's GPT-5.5 (xhigh) at 60, and @Google's Gemini 3.1 Pro Preview and @AnthropicAI's Claude Opus 4.7 (Adaptive Reasoning, Max Effort) at 57.
For context: just one year ago the highest-scoring open weights model was DeepSeek V3 0324 which achieved 22 on the Intelligence Index, and was ~13 points below the highest-scoring proprietary model, Claude 3.7 Sonnet (Reasoning) at 35.
Key takeaways:
➤ The top three most intelligent open weights models are trillion-plus-parameter MoE architectures with permissive licenses. Kimi K2.6 (Reasoning) has 1T total / 32B active parameters with 256K context window, MiMo V2.5 Pro (Reasoning) has 1T total / 42B active with 1M context window, and DeepSeek V4 Pro (Reasoning, Max Effort) has 1.6T total / 49B active with 1M context window.
➤ The gap to proprietary remains wide on the hardest reasoning and agentic coding evaluations. On HLE (Humanity's Last Exam) the three top open weights models score 34-36%, vs 44% for GPT-5.5 (xhigh) and 45% for Gemini 3.1 Pro Preview. On CritPt (Research-level Physics) they score 4-12%, vs 27% for GPT-5.5 (xhigh). On TerminalBench Hard (Agentic Coding & Terminal Use) they score 43-46%, vs 61% for GPT-5.5 (xhigh) and 54% for Gemini 3.1 Pro Preview.
➤ Omniscience (knowledge hallucination) shows a large gap to proprietary models, with DeepSeek V4 Pro (Reasoning, Max Effort) hallucinating significantly more than its open weights peers. DeepSeek V4 Pro (Reasoning, Max Effort) scores -10, MiMo V2.5 Pro (Reasoning) 4, and Kimi K2.6 (Reasoning) 6. By comparison, GPT-5.5 (xhigh) scores 20, Claude Opus 4.7 (Adaptive Reasoning, Max Effort) 26, and Gemini 3.1 Pro Preview 33.
27
2,112
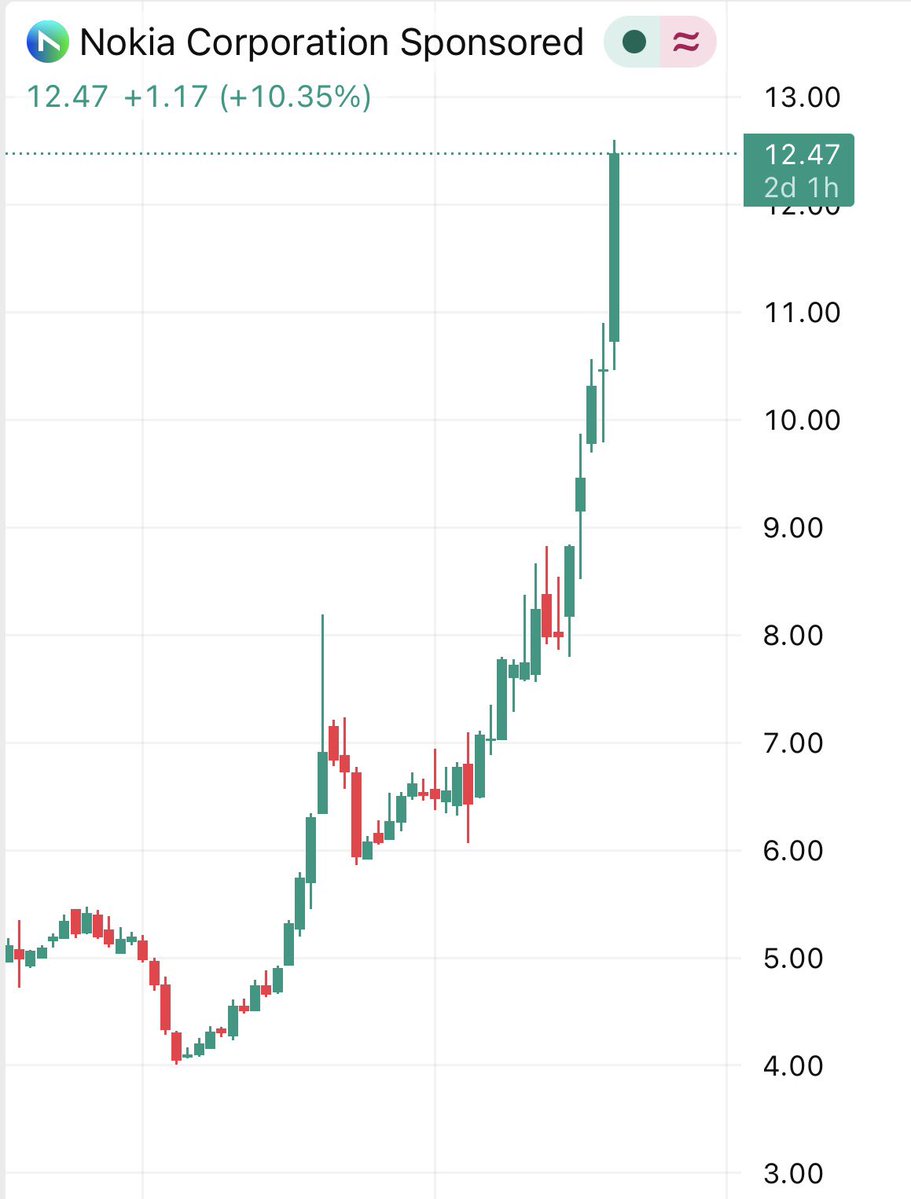
Can’t wait to run a model locally on my Nokia!

1
23
1,096
The 1 billion users:
Apr 29

Bing just reached a major milestone: 1 billion monthly active users, as @satyanadella shared on today’s earnings call. We’ve added more users in the last 5 years than in the previous 10.
I’m so grateful for everyone in Bing and our partners across Microsoft and beyond who have contributed over the years to this achievement, driving advances in fundamentals, differentiation, and growth with passion and tenacity.
Few products reach the 1 billion user mark, and few technologies in history have been as transformative as web search. I am excited for our team to continue to drive innovation and competition in this critical area for society.

3
1
37
1,379
1.25 bits is crazy, can’t wait for bigger LLMs at 1 bit
Will be huge for local ai
Apr 29

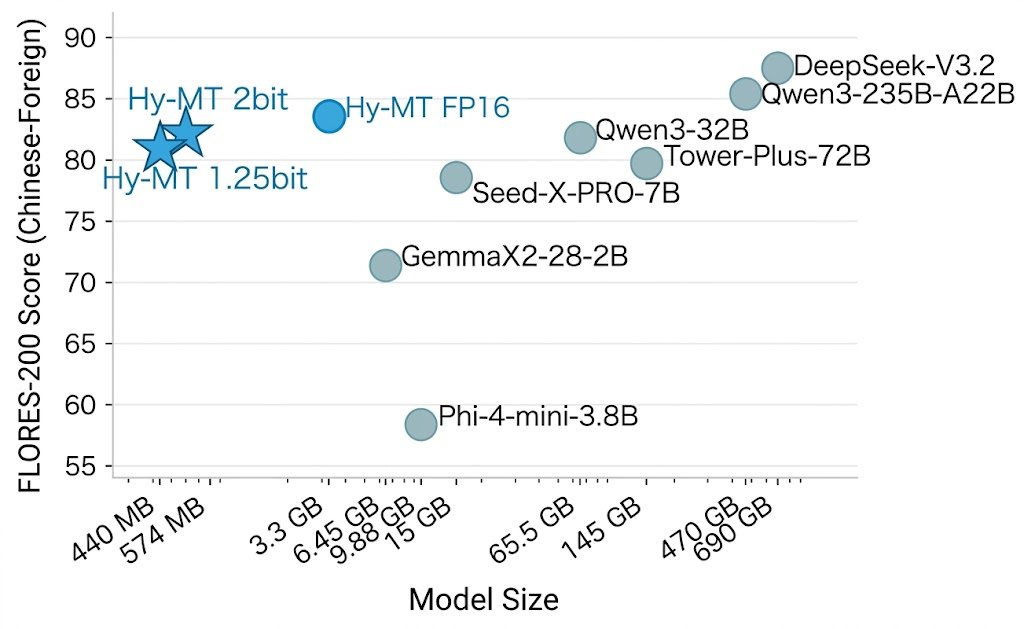
We're open-sourcing Hy-MT1.5-1.8B-1.25bit — a 440MB translation model that runs fully offline on your phone, supports 33 languages, and outperforms Google Translate.
At 1.8B parameters, it matches commercial translation APIs and 235B-scale models on standard benchmarks. By quantizing to 1.25-bit, memory drops from 3.3GB (FP16) to 440MB — 25% smaller and ~10% faster than prior 1.67-bit approaches, with no accuracy loss.
Covers 33 languages, 5 dialects, and 1,056 translation directions including minority languages like Tibetan and Mongolian.
Our translation model has won 30 first-place rankings in international MT competitions and is already deployed across multiple Tencent products.🏆
📲Demo APK (Android): huggingface.co/AngelSlim/Hy-…
🤗Hugging Face:: huggingface.co/AngelSlim/Hy-…
🔗GitHub: github.com/tencent/AngelSlim
📄Paper: arxiv.org/abs/2601.07892

2
1
67
4,934