
ml @cambridge_uni. previously @precogatiiith, @iiit_hyderabad. futurebound.
Joined June 2023
- Tweets 1,143
- Following 863
- Followers 3,323
- Likes 2,715
187 Photos and videos










Akshit retweeted

Jun 11
Claude Fable 5 ranks #1 on FrontierSWE. This represents the biggest capability jump we have observed since releasing the benchmark
On many tasks, Fable 5 works productively for close to 20 hours and fully saturates tasks that were effectively out of reach for earlier models

13
21
280
34,297
Akshit retweeted
Jun 10
We believe that better training data will come from creative research and engineering ideas, not from hiring annotators.
Here are some of the open problems we are working on:

2
17
83
18,337
the first 60 or so pages were so good... they could've done so much with the world.. it was so interesting.. only to throw it all away for 40 science theories being infodumped in the last 20 pages and for what
Jun 2

Finally finished The Three Body Problem. Very sorry to my friends who like it, but I found it unfathomably bad in practically every way. Worst science fiction I've read in a long time. Won't be reading the sequels. 1.5 out of 5.

1
8
889
Akshit retweeted

May 29
Most people training agentic LLMs with RL right now have a silently broken training loop and have no idea.
Here's the trap: single-turn RL works beautifully. Clean curves, sane rewards, everything converges. Then you add tools so the model can act mid-rollout, and things get weird. Loss spikes for no reason. Eventually a shape-mismatch error.
The culprit: every time you parse the model's output to detect a tool call, then re-tokenize the updated conversation for the next turn, you're rolling the dice. Usually the round-trip gives back the same tokens. Sometimes it doesn't and your gradient lands on a sequence the model never actually sampled. No crash. Just quietly wrong math and a useless gradient signal.
The fix is one rule: never re-encode tokens you've decoded. Keep the sampled tokens in one buffer, never re-render them, and both failure modes disappear. That's Token-In, Token-Out done right.
Our team just published a beautiful deep-dive on exactly this, including an audit across the major open-weights model families showing most chat templates already support it. Required reading if you're doing multi-turn RL 🤗🔥
qgallouedec-tito.hf.space/

51
139
1,116
1,011,927
idk how people say they are doing research with agents...
every single thing models have come up with is the most useless idea ive heard.
still only good for implementation (that too requires so much babysitting to get correct)
(yes this is with highest reasoning, etc)
1
20
4,896
Akshit retweeted
May 28
We evaluated Claude Opus 4.8 on FrontierSWE ahead of today's release. It is now the best-performing model on FrontierSWE.
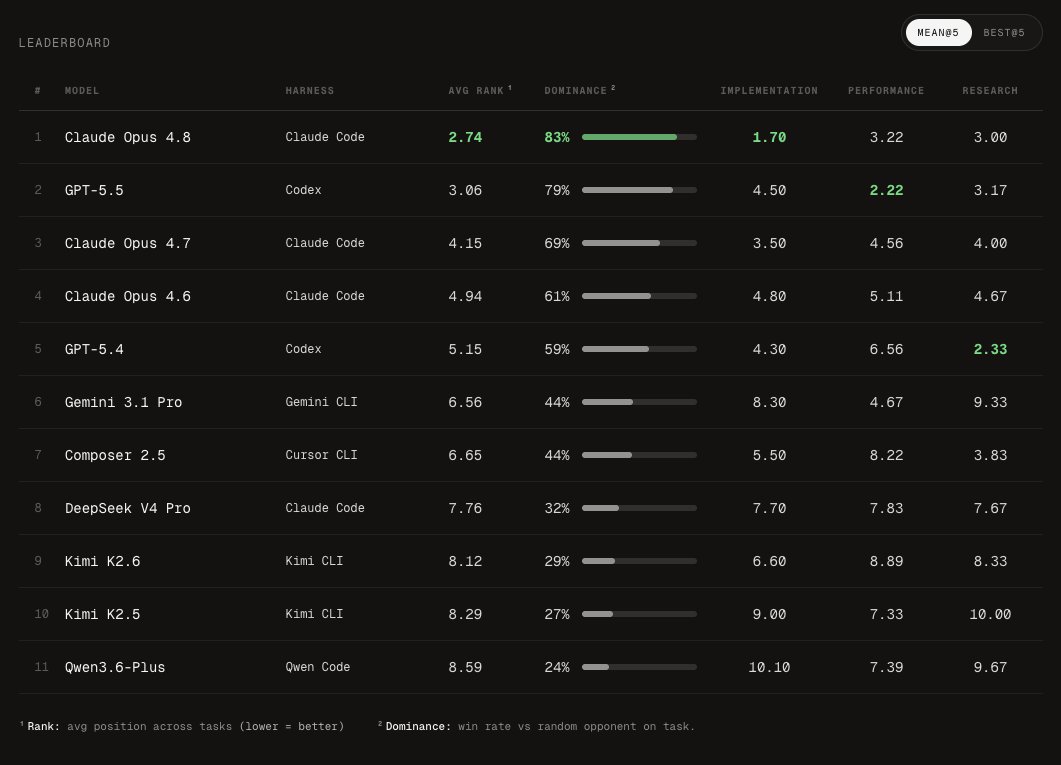
6
13
128
19,099
Akshit retweeted

May 26
Great take on the importance of evals as upstream of everything, including training oftentimes. I'd go one step further and say that proper evaluation is becoming and exciting standalone discipline within AI: davidstutz.de/LpZDE
May 18

I’ve left Google DeepMind after an amazing chapter.
I’m incredibly grateful for the people I worked with, the things we built, and the lessons I learned from taking frontier AI research into production. DeepMind shaped how I think about research, product, evaluation, and what it takes to build AI systems at real scale.
As I wrap up this chapter, I wrote down something I’ve been thinking about a lot: evals.
We’re good at evaluating the models we have. We’re much worse at evaluating the models we’re about to build — especially if they cross into a new capability regime. We will have self-evolving models, but before that, we need self-evolving evaluations.
wanglun1996.github.io/blog/y…
2
2
33
6,822
surprised that in all the math/ML courses ive taken this has never come up
joschu.net/blog/kl-approx.ht…
1
48
4,586
unbelievably good series on how traditional RL evolved into everything we see today!!!
my rule of thumb for good educational content is combining technical details with the context/history surrounding them; it gives a much richer understanding of why things are the way they are
4
14
189
5,882
Akshit retweeted

May 22
Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
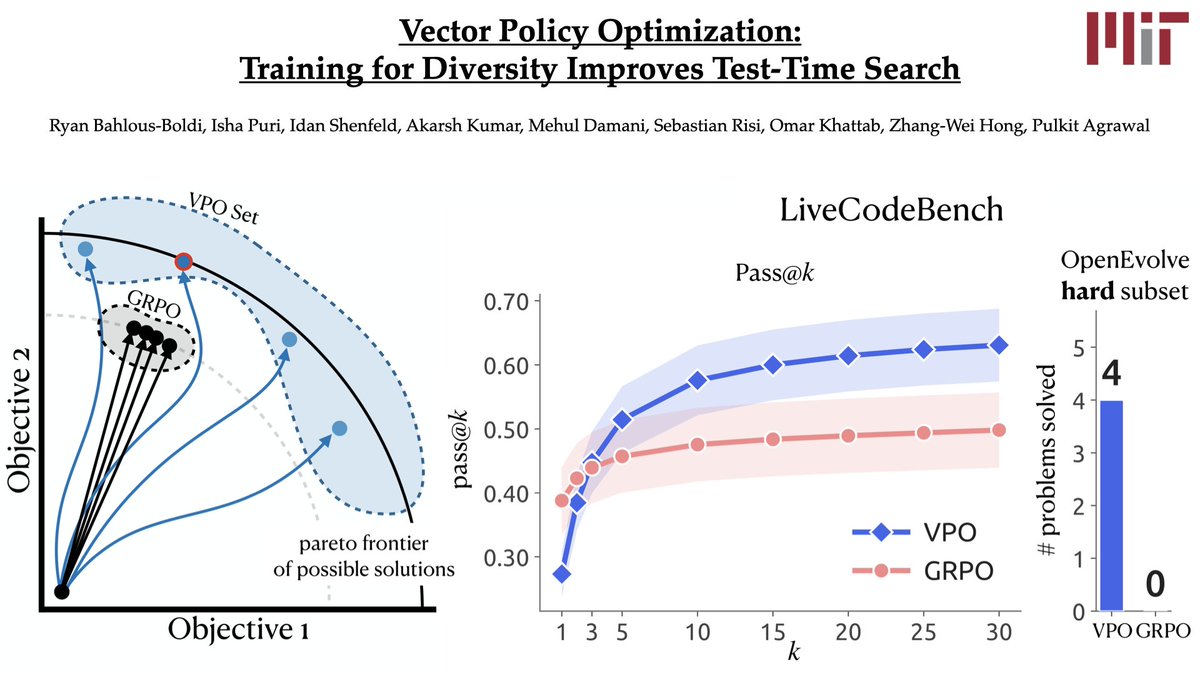
34
121
862
212,679
Akshit retweeted

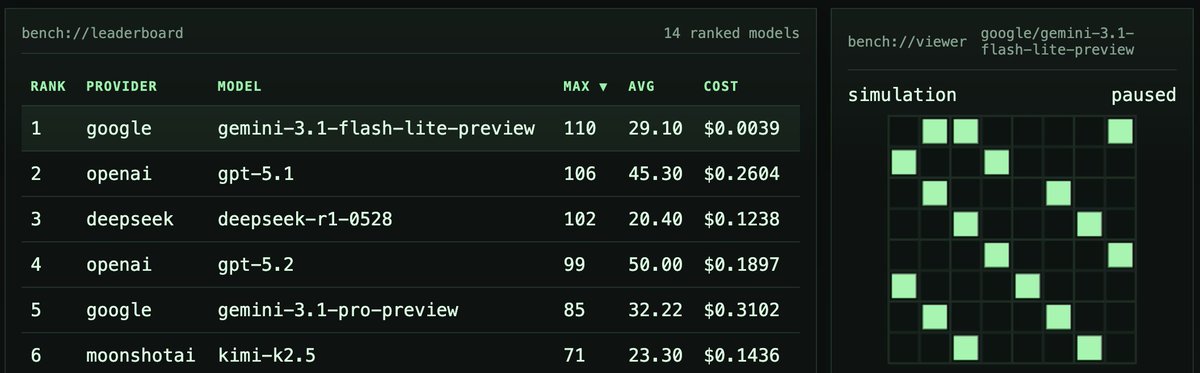
💥Today we release InferenceBench, our next benchmark after PostTrainBench that measures progress on AI R&D automation.
AI R&D automation will very likely unfold gradually, starting from “boring” tasks like inference speed optimization that are very easily verifiable (accuracy inference time). We show a rather negative result for current frontier agents. They are not good at system-level engineering and managing complex dependencies. They do show non-trivial performance, but they fail compared to a simple baseline: hyperparameter tuning of vLLM/SGLang hyperparameters.
Importantly, InferenceBench tests *open-ended* inference optimization capabilities. This is different from more narrow benchmarks like KernelBench that only let agents optimize kernels (which is a very valuable task, too!). The benchmark is intentionally open-ended, so the poor performance of the agents is not an underelicitation issue. The agents have everything needed to succeed, but they still fail because they are not yet reliable enough for this task.
Our results suggest an inverse scaling phenomenon: Claude Sonnet 4.6 and GLM-5 rank highly because they more often preserve simple, valid, high-performing final servers, while several larger models show stronger peak runs but lose utility through brittle final-state choices. This contrasts with benchmarks where rankings track raw capability (e.g., SWE-Bench, Terminal-Bench, PostTrainBench, FrontierSWE).
One of the primary bottlenecks we have clearly observed is the lack of diversity of strategies: nearly all agents just use vLLM, without exploring alternatives. Overall, proper exploration is lacking: the current agents are not ready to tackle broad enough goals and get stuck after the first found solution (such as vLLM). I’m sure future agents will do much better, but here is where we are now.
This benchmark is our 2nd one in a suite of benchmarks that will track the progress on AI R&D automation. We will develop many more benchmarks that will cover different aspects of AI R&D automation, culminating in recursive self-improvement. Stay tuned!


12
48
348
41,983
Akshit retweeted

May 19
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control.
The result: our first Frontier Risk Report.

31
193
918
348,931
holy shit
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
1
6
333
Akshit retweeted

May 15
Continual learning is bottlenecked by realistic evaluations
Introducing FutureSim, which replays real-world events in the temporal order they occurred
We benchmark frontier agents at updating predictions about how our world evolves, in native harnesses like Codex, Claude Code
21
65
532
112,955