
深層学習に興味があります。
Joined January 2019
- Tweets 2,606
- Following 302
- Followers 1,199
- Likes 61,281
27 Photos and videos






17h
「CVPR 2026 Report」( hirokatsukataoka.net/temp/pr… )の論文紹介で「ARC Is a Vision Problem!」( github.com/lillian039/VARC )を思い出しました。ViTでGPT-5とClaude 3.7を上回る結果はインパクトありますが、まだARC-2は11.1%`で、今後さらに解明されることを期待したくなります。
1
174
Jun 11
毎年まとめられている「CVPR 2026 Report」( hirokatsukataoka.net/temp/pr… )が公開されました。JiTの論文紹介を含む「Back to Pixels from Latent Spaces in Diffusion Models」の動向分析が興味深く。
3
13
1,445
allowfirm retweeted

#CVPR2026 / @CVPR
CVPR 2026 Report を公開しました!
hirokatsukataoka.net/temp/pr…
LIMIT.Lab、cvpaper.challenge、そして Visual Geometry Group (VGG) の連携により、CVPR 期間中に取りまとめたレポートです。本レポートでは、今年の CVPR で見られた主要な研究トレンド、研究の方向性、新たな潮流、そしてコミュニティ内で交わされた議論について、俯瞰的視点から考察しました。

#CVPR2026 / @CVPR
We've released the CVPR 2026 Report!
hirokatsukataoka.net/temp/pr…
Compiled during CVPR through a collaboration among LIMIT.Lab, cvpaper.challenge, and the Visual Geometry Group (VGG), this report provides meta-level insights into the key trends, research directions, emerging themes, and discussions that shaped this year's conference.

9
60
8,830
allowfirm retweeted
#CVPR2026 / @CVPR
We've released the CVPR 2026 Report!
hirokatsukataoka.net/temp/pr…
Compiled during CVPR through a collaboration among LIMIT.Lab, cvpaper.challenge, and the Visual Geometry Group (VGG), this report provides meta-level insights into the key trends, research directions, emerging themes, and discussions that shaped this year's conference.
3
77
292
40,306
Jun 10
「JiT」と聞いて、最初Just in Timeかと思いましたが「Just image Transformers」を掲げる「Back to Basics: Let Denoising Generative Models Denoise」( arxiv.org/abs/2511.13720 )でした。Kaiming HeさんがSecond Authorの画像生成の論文で、MITライセンスの実装( github.com/LTH14/JiT )も。
7
823
allowfirm retweeted

Jun 9
JiT deserves 'oral' even 'best' in my opinion.


1
2
51
12,708
Jun 6
CVPR 2026採択のVideoCUPS( visinf.github.io/videocups/ )は、単眼カメラの動画からオプティカルフローや深度推定も活用して疑似ラベルを自動生成する、教師なし学習の動画パノプティックセグメンテーション(VPS)で、Apache License 2.0のコード( github.com/visinf/cups )も公開されています。
1
193
allowfirm retweeted

📢 [CVPR’26] Can we learn to detect, segment, and track every object in a video without human supervision?
Yes, we introduce VideoCUPS, the first unsupervised video panoptic segmentation (VPS) method: 1. Get pseudo-labels from monocular videos. 2. Train a VPS model on them.
8
72
432
27,367
May 31
ニューラル画像圧縮は、画像のドメインが想定されていればパフォーマンスを出せそうと思う一方、実用には課題が多そうと思っていましたが、PICOは進化していそうで関心が。
3
280
allowfirm retweeted

ニューラル画像圧縮は長年有望視されてきたものの、これまで実用化には至っていなかった。今回提案されたPICOは、速度と知覚品質のトレードオフを大幅に改善し、既存手法と比較して2〜3倍のビットレート削減を実現した。また、iPhone 17 Pro Max上で1200万画素画像をエンコード230ms、デコード150msで処理できる。
学習型コーデックは従来の画像圧縮方式を上回る圧縮性能を示してきたが、広く実用化されていない。大きな原因は、処理速度や消費電力の問題に加え、クロスプラットフォームでの運用が難しいことである。
PICOは一般的な学習型画像圧縮の枠組みに基づいている。入力画像 x はエンコーダによって潜在表現 y に変換される。y は量子化された後にエントロピー符号化される。また、潜在表現の統計情報を表す Hyperprior z も同時に符号化される。
復号時にはまず Hyperprior を復号し、その情報を用いて潜在表現を復号する。最後にデコーダによって画像を再構成する。
PICOでは以下の工夫を導入している。
・Learned Scale Representation
特徴ごとに異なる受容野を用いた特徴抽出を行う ConvScale を導入している。例えば、空や建物のような大域的な構造には大きな受容野を、草や髪の毛、文字などの高周波成分には小さな受容野を用いるよう学習する。
・Haar Wavelet に基づくサンプリング
JPEG 2000などで利用されていた古典的な信号処理手法を再導入し、情報を捨てることなく低周波成分と高周波成分へ分解する。
・One-shot Context Model
従来の学習型圧縮では圧縮率を高めるため、自己回帰的に潜在変数の分布を推定することが多かった。しかし逐次実行となるため処理が遅い。そこでPICOでは、全潜在表現の統計量を一度のネットワーク計算で推定する。
・Learned Quantization Width
入力内容に応じて量子化幅を適応的に変化させる。視覚的に重要な領域にはより多くのビットを割り当て、重要度の低い領域ではビット数を削減する。
・Text Fidelity Loss
文字の誤りは大きな意味の変化をもたらすため、OCRモデルから得られる特徴を利用した損失関数を導入する。
・Tiling Artifact Loss
高解像度画像をタイル単位で処理する際に生じる境界部分の不連続性を抑制する損失を導入する。
さらに、数百万個の候補アーキテクチャを対象としたニューラルアーキテクチャ探索(NAS)を実施している。性能予測器を利用するとともに、実機上でのレイテンシ測定も探索に組み込んでいる。
主観評価実験では、610名の評価者が約7万5000回の比較評価を行い、各コーデックの主観品質を推定している。
コメント
===
ニューラル画像圧縮は有望な技術として10年近く研究されてきたものの、実用化には至っていなかった。
大きな理由は、実用的な画像圧縮システムには圧縮率だけでなく、処理速度、メモリ使用量、消費電力、そしてGPU以外の環境、特にモバイルデバイス上での動作が求められるためである。
本研究はAppleによるものであり、iPhone上で十分な検証が行われている点が特徴である。そのため実用化も近いのではないかと期待される。将来的にはiPhoneの標準画像フォーマットがニューラル圧縮ベースへ移行する可能性もあるかもしれない。
最終著者の Oren Rippel 氏は、約10年前にニューラル画像圧縮企業 WaveOne を創業し注目を集めた研究者である。その後Appleに加わり、長年にわたりニューラル画像圧縮の実用化へ取り組んできたものと考えられる。
1
55
263
34,922
May 26
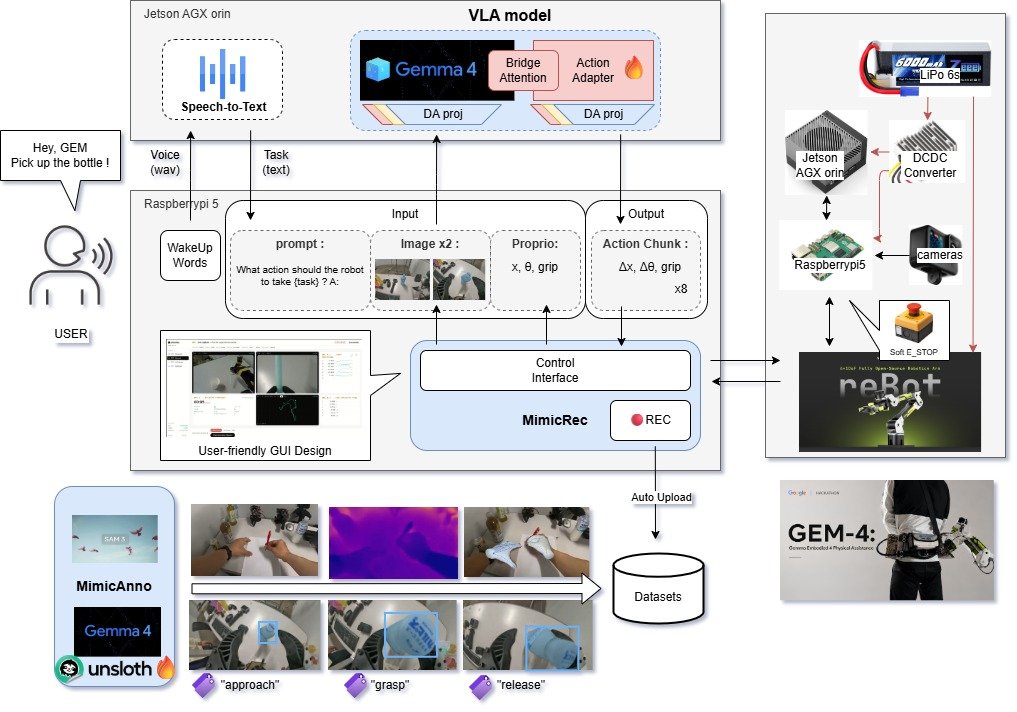
GEM-4( kaggle.com/competitions/gemm… )は、音声による指示からロボットアームの行動まで一連の処理をRaspberry Pi 5とJetson AGX Orin上に実装していて、構築されたGemma 4ベースのVLAモデルも興味深く。
2
402
allowfirm retweeted

May 24
同研究室B4の前田君,松ケ谷君らが、#Kaggle Gemma 4 Good Hackathonで「GEM-4」を公開!
Gemmaをロボットアームと接続し、ユーザーの意図に応じて物理的に支援する身体性AIデモを短期間で実装しています。B4で短期間でここまで形にしていて本当にすごいです。
youtu.be/OhaIA3bYwmg?si=RSLR…

3
63
386
29,079
May 20
CVPR 2026採択の異常検知の論文「InvAD」は、拡散モデルの逆変換で異常部分が標準ガウス分布から外れて、潜在空間で局所的な不自然さとして残ることから検知を行い、画像の再構成が不要なため推論コストが抑えられる手法で、MITライセンスの実装( github.com/SkyShunsuke/Inver… )も興味深く。
1
9
127
8,610
May 22
「InvAD: Inversion-based Reconstruction-Free Anomaly Detection with Diffusion Models」( arxiv.org/abs/2504.05662 )は、福井大学の長谷川研究室の坂井さんが筆頭著者で、プロジェクトページ( invad-project.com/ )も公開されています。
1
2
201
May 16
「AI論文年鑑 2026」( koshian2.booth.pm/items/6926… )で、画像とテキストを扱うマルチモーダルAIエージェントのための基盤モデル「Magma」( microsoft.github.io/Magma/ )を知りました。論文はCVPR 2025採択で、マイクロソフトがMITライセンスで実装( github.com/microsoft/Magma )を公開しています。
2
323
May 12
過去の物体検出から最近まで、参考になる一覧表が。YOLOv13もAGPL3で、YOLO26はAGPL3かEnterpriseライセンスとのことです。
May 11

以前まとめた,YOLOなどの物体検出手法とコードのライセンス一覧です.
研究目的ならどれでも使えますが,商用利用を考えるならGPLライセンス付きは避けた方が良いです.

1
3
780
allowfirm retweeted

May 11
以前まとめた,YOLOなどの物体検出手法とコードのライセンス一覧です.
研究目的ならどれでも使えますが,商用利用を考えるならGPLライセンス付きは避けた方が良いです.
1
49
309
25,565
May 10
これまでに「解説されつくした」と思っていたTransformerですが、わかりやすく可視化されて精緻なSelf-Attentionの解説が。
May 10

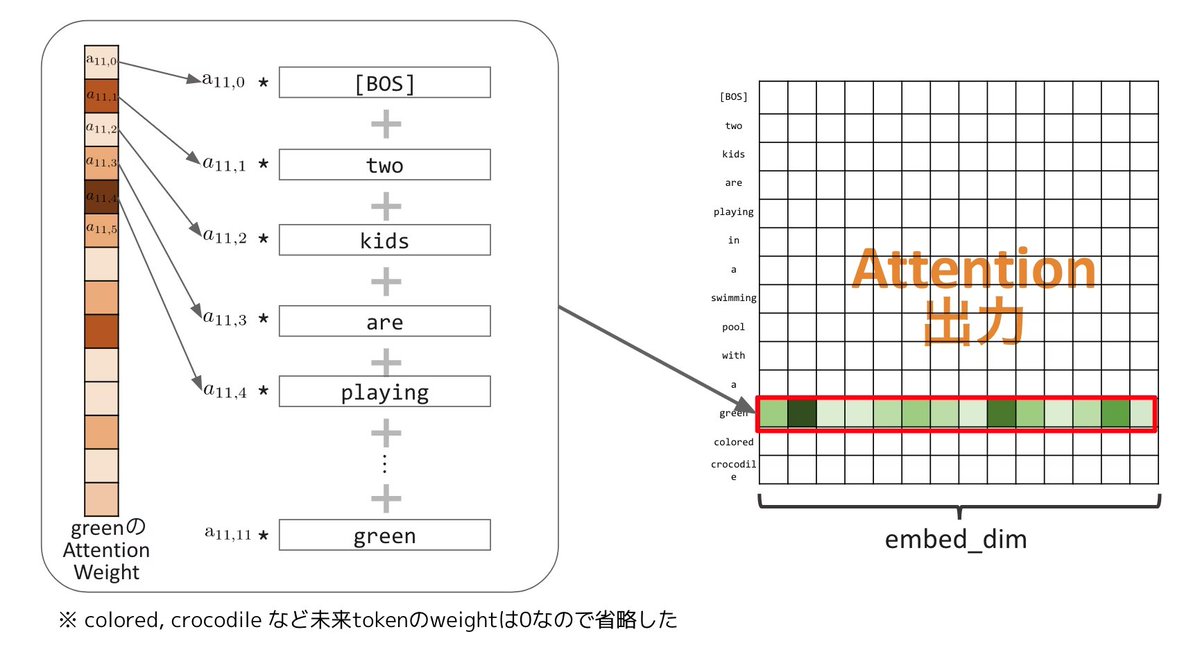
TransformerのSelf-Attentionで出てくるQKV、式は知っていても「結局何を計算しているのか?」がわかりづらいこともあるんじゃないかと思うので、図を使って直感的に解説する記事を書きました!
久々のQiita記事です😊
TransformerのSelf AttentionのQKVを直感的に解説する
qiita.com/kenmatsu4/items/1b…

3
676
allowfirm retweeted

May 10
TransformerのSelf-Attentionで出てくるQKV、式は知っていても「結局何を計算しているのか?」がわかりづらいこともあるんじゃないかと思うので、図を使って直感的に解説する記事を書きました!
久々のQiita記事です😊
TransformerのSelf AttentionのQKVを直感的に解説する
qiita.com/kenmatsu4/items/1b…
1
103
700
47,864
May 7
「AI論文年鑑 2026」( koshian2.booth.pm/items/6926… )の「RF-DETR」の解説で、物体検出やVLMのためのベンチマーク「Roboflow 100-VL」( github.com/roboflow/rf100-vl )を知りました。データセットもコードもApache License 2.0とのことです。
4
298