
NO ONE CARES ABOUT CODE
Joined March 2018
- Tweets 925
- Following 217
- Followers 57
- Likes 140
100 Photos and videos








24 hours after US shut down Anthropic's Fable 5, #ZAI drops GLM-5.2 under MIT. Coincidence? The message is clear: #OpenSourceAI survives export bans.
banandre.com/blog/glm-52-ope…
62
The US government just nuked Anthropic's best models globally over a #JailbreakPrompt that found minor code bugs.
It’s time to #RunAI Locally
banandre.com/blog/us-governm…
3

Jun 12
MiniMax just dropped M3's open weights on a Friday, and the LLM wars just got real.
Frontier-level coding practical 1M context at 15x lower cost than Opus. The #OpenWeights ceiling just broke.
banandre.com/blog/minimax-m3…
1
2
67
Jun 10
While everyone is talking about Mythos, #Microsoft's #SupplyChain recompromise shows attackers targeting AI dev tools: 70 repos hijacked, credentials stolen
banandre.com/blog/microsoft-…
22
Jun 9
Xiaomi hit 1000 TPS on a 1T model using commodity GPUs. Selective #FP4Quantization of MoE experts #DFlash speculative decoding TileRT's persistent GPU execution. No custom silicon needed.
banandre.com/blog/xiaomi-mim…
1
27
Jun 9
China just approved NEO, the first commercial #InvasiveBrainChip, & it's already on insurance.
A paralyzed patient used it to write again. The #BCI race now shifts from demos to hospital deployment
banandre.com/blog/china-neo-…
13
Jun 9
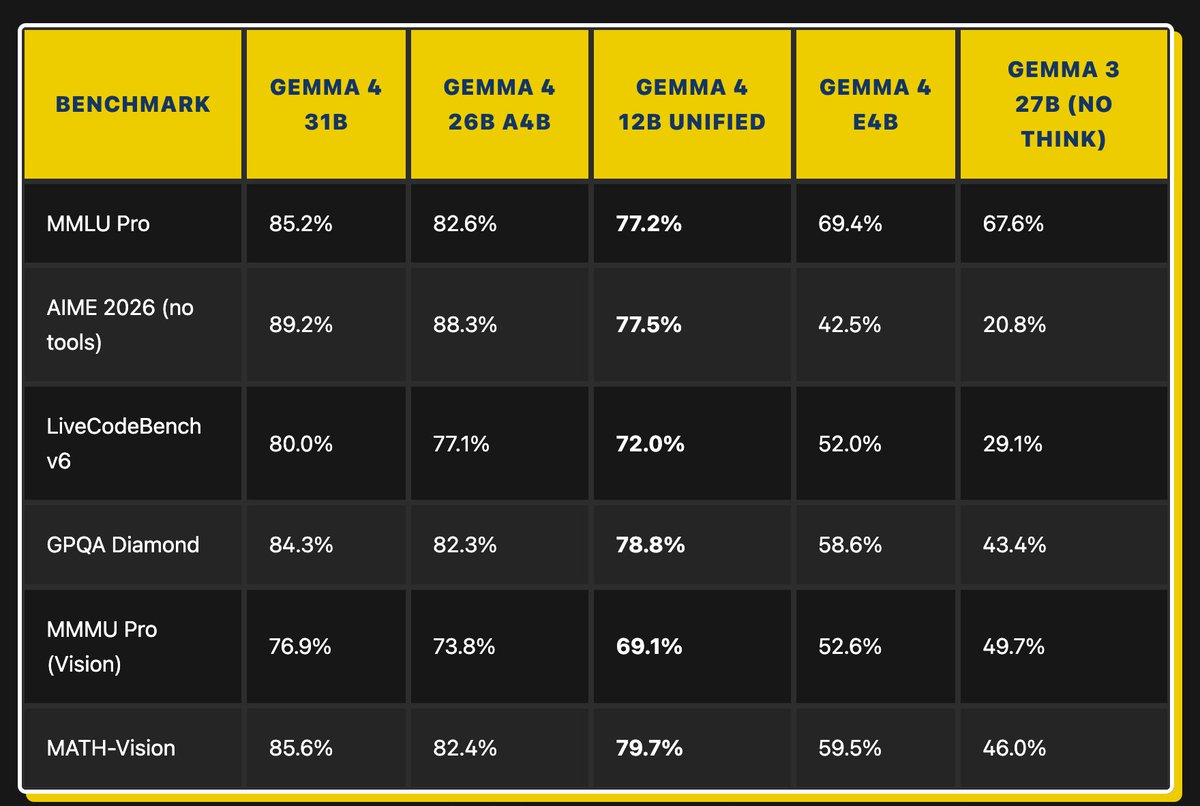
Google DeepMind's #Gemma 4 12B just made your laptop a local multimodal AI workstation.
Video, audio, text, all on 16GB RAM, no cloud
banandre.com/blog/gemma-4-12…
44
Jun 8
Forced to use #Databricks for 100k rows in Postgres?
The real cost isn't just $9k, $19k/year, it's the #PlatformOverhead killing your team's velocity.
Push back with data
banandre.com/blog/databricks…
15
Jun 8
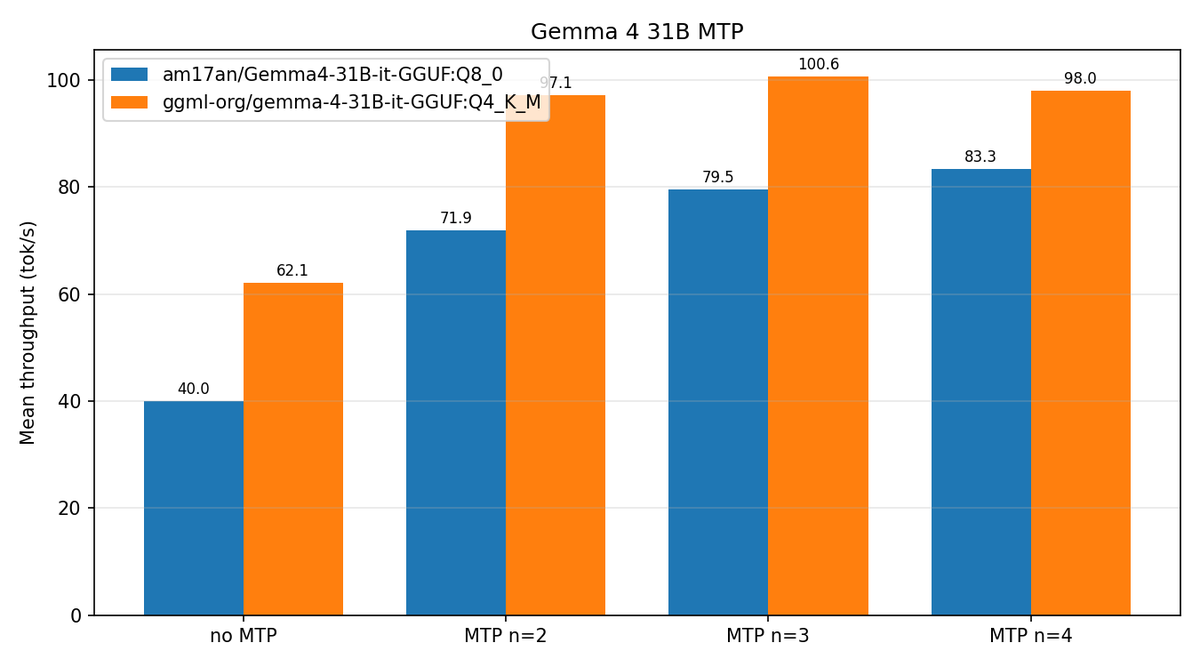
Gemma 4 MTP in llama.cpp b9549 pushes 12B to 140 tok/s on a 12GB RTX 4070.
No separate draft model needed, just a co-trained prediction head. #Gemma4MTP is turning dense models into #SpeedDemons
But if you're on MoE, don't expect the same boost
banandre.com/blog/gemma-4-mt…
36
Jun 8
#TurboQuant's rotation trick got absorbed by standard quants. Now #KVarN shifts the #LongContextLLM quality-per-memory curve by a full tier, real benchmarks vs hype
banandre.com/blog/kv-cache-q…
1
1
2
56
Jun 5
Anthropic's AI vulnerability scanner hits a brutal reality: discovery is easy, but patching is the bottleneck.
Only 6% of found bugs get fixed. Find out why #SecurityArchitecture matters more than the AI model itself
banandre.com/blog/the-pipeli…
12
Jun 5
#VoidZero joins #Cloudflare
Vite's edge native tooling just got a global network. But does the build-to-deploy seamless flow mean vendor lock-in for JavaScript toolchains?
The architecture is sound, but the gravitational pull is real
banandre.com/blog/cloudflare…
24
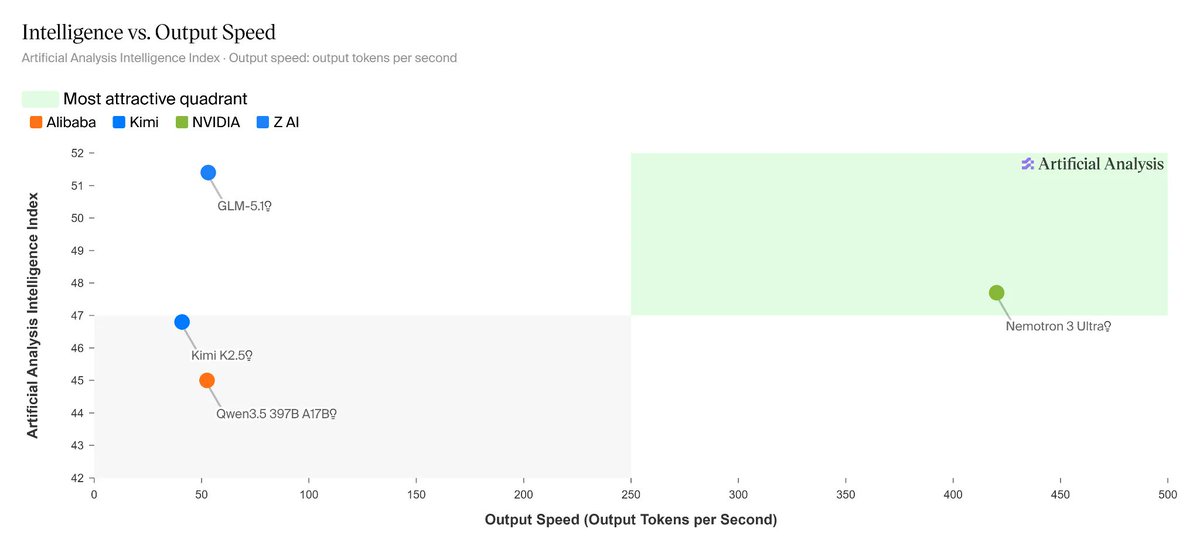
Jun 5
Nvidia's 550B #Nemotron3Ultra MoE fits 8 H100s, 55B active params, 5x throughput, 1M context.
It's not magic, just damn good engineering.
Latent MoE and #MOPD training make frontier-level reasoning deployable on a single DGX node
banandre.com/blog/nvidia-nem…
13
Jun 4
#Snowflake #CDC showdown: Streams, Dynamic Tables, or Stored Procedures? The #BatchCDCDilemma has a clear answer: mix based on table size.
Small dims → DTs with FULL refresh
Large facts → Streams on join views
banandre.com/blog/snowflake-…
1
9
Jun 4
Google's #Gemma4 12B ditches separate encoders, bringing native vision & audio to 16GB laptops. Single #EncoderFreeTransformer handles text, images, and audio in one pass. 256K context, runs locally.
The #LocalMultimodalAgent dream is real
banandre.com/blog/google-gem…
2
56
Jun 3
#dbt Core v2 ditches the Python runtime for Rust, makes the Fusion engine Apache 2.0, and kills the two-engine strategy. Is this a genuine leap or a strategic retreat?
banandre.com/blog/dbt-core-v…
56
Jun 2
The #MiasmaWorm showed that #OIDC trusted publishing isn't a cure-all: it turned a compromised Red Hat pipeline into a weapon. 31 packages backdoored, valid SLSA attestations, no long-lived tokens stolen. Time to distrust the pipeline
banandre.com/blog/miasma-sup…
14
Jun 2
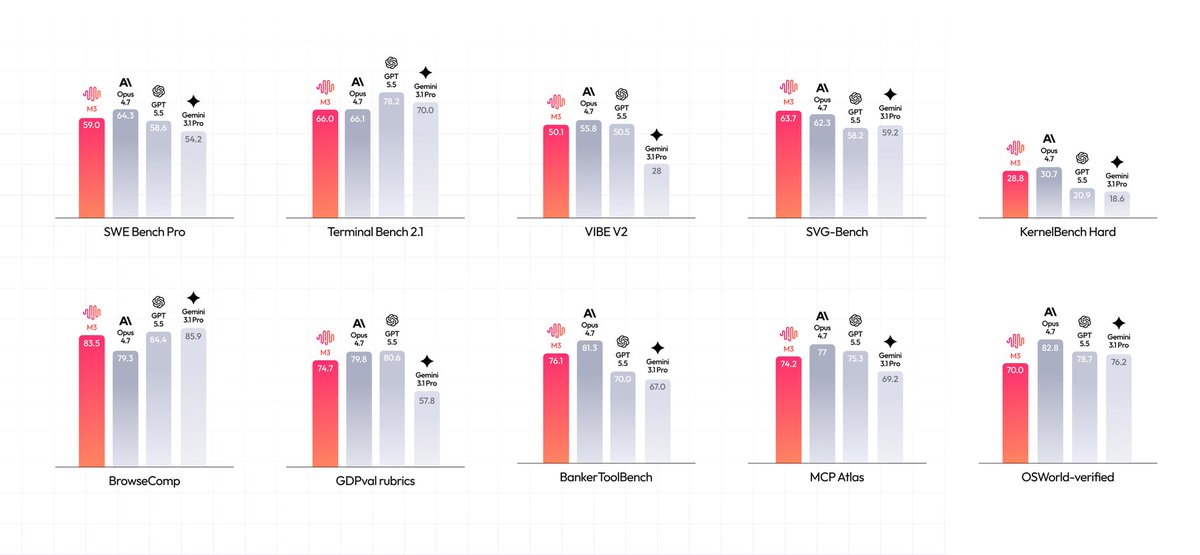
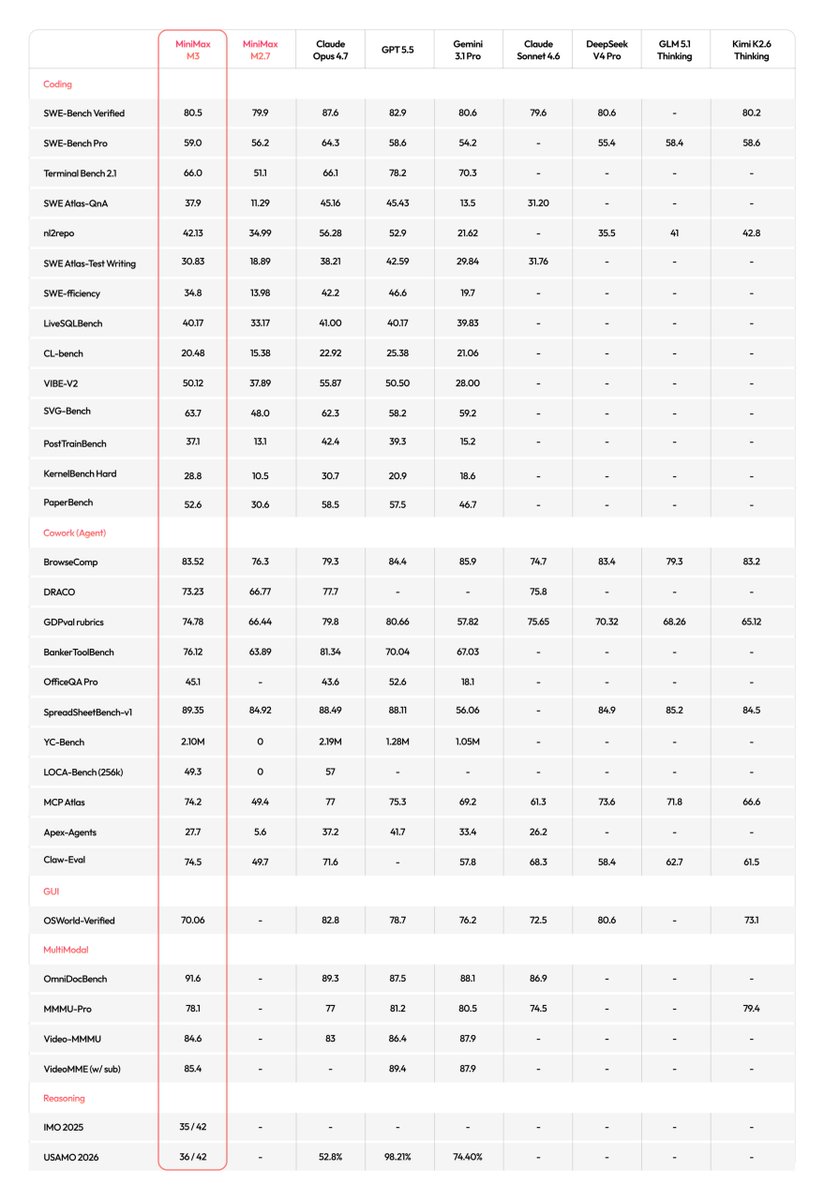
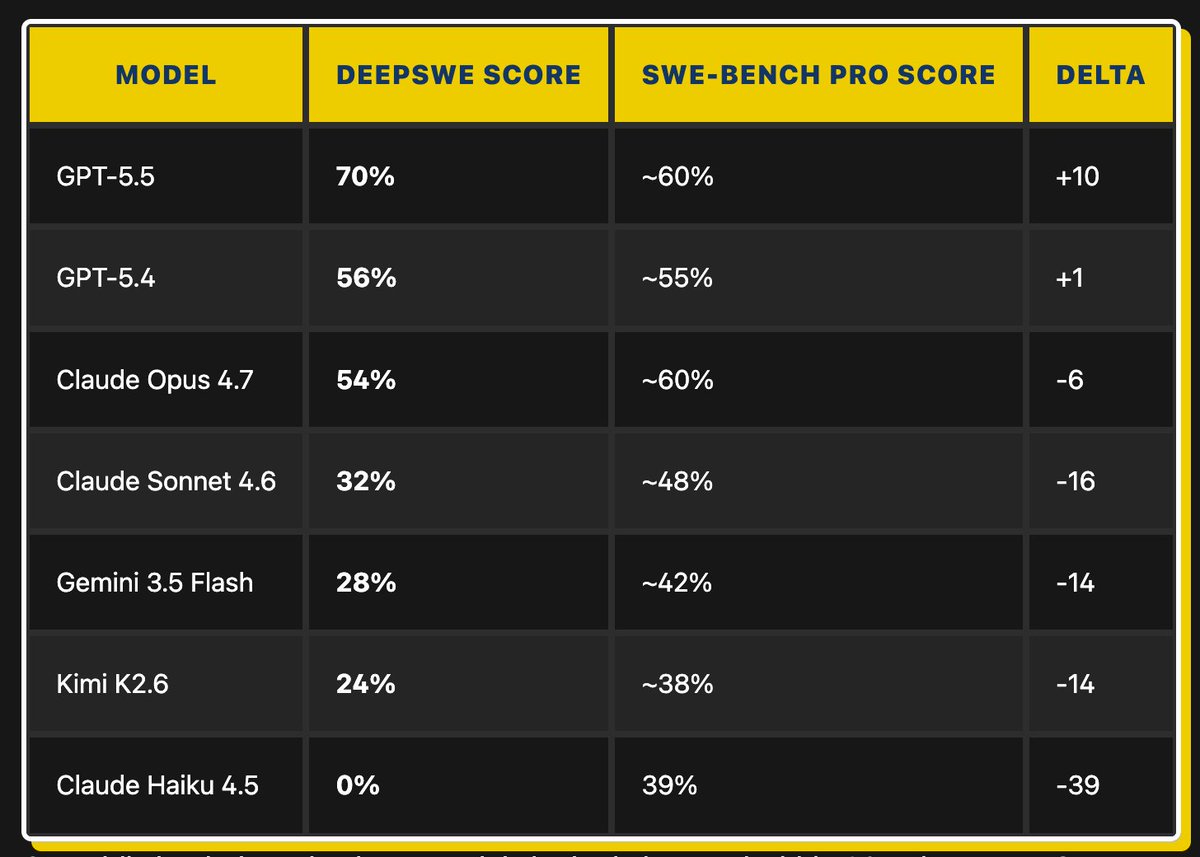
#MiniMax M3 beats GPT-5.5 on SWE-Bench for $0.30/M input tokens. With 1M context and 9.4× speedup on CUDA kernels, the #OpenWeight model just rewrote the #AgenticAI cost math. Implications?
banandre.com/blog/minimax-m3…
40
Jun 1
#SemanticLayer hype is real, but is it the first step for #AIEnablement?
Congrats, you've discovered why DE will never be replaced by AI
The real work is documentation, not magic metadata.
banandre.com/blog/semantic-l…
1
17
Jun 1
8 OEMs just cloned NVIDIA's #DGXSpark with spot-on identical dimensions. Not a lack of innovation, it's the birth of a #AIMiniWorkstation standard.
When every box is the same, real deployment begins
banandre.com/blog/ai-mini-wo…
1
32