
Research Scientist at The Boston Dynamics AI Institute. Prev at Brown CS, Ph.D. from MIT. Making robots easy to program and deploy. ajshah.info
Joined August 2013
- Tweets 155
- Following 289
- Followers 220
- Likes 469
11 Photos and videos










Ankit Shah retweeted

21 Jul 2025
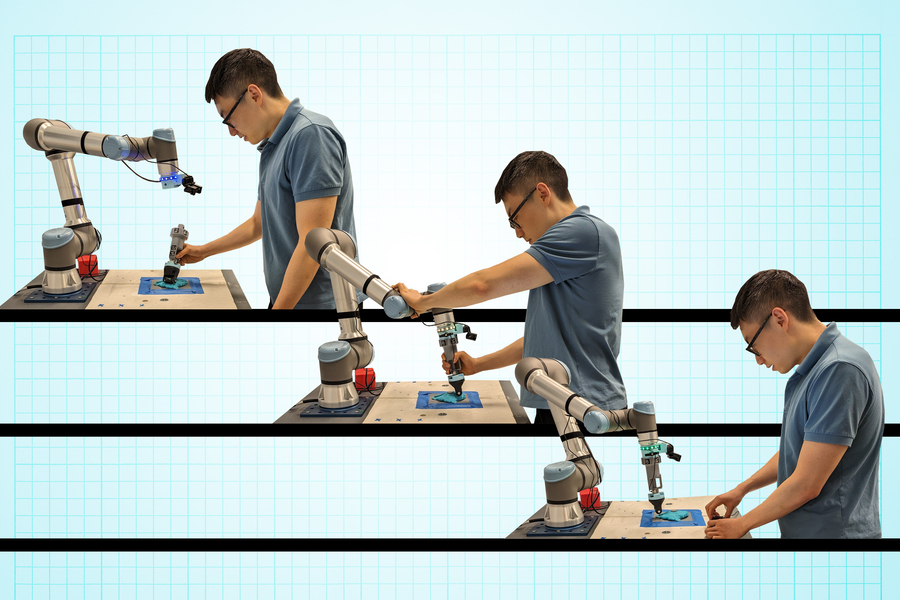
A new handheld interface from MIT gives anyone the ability to train a robot for tasks in fields like manufacturing.
The versatile tool can teach a robot new skills using one of three approaches: natural teaching, kinesthetic training, & teleoperation: bit.ly/4nTAw6F
7
28
96
13,798
Ankit Shah retweeted

30 Jun 2025
Yale Philosophy offers a course on “Formal Philosophical Methods” — a broad introduction to probability, logic, formal semantics, etc.
Instructor Calum McNamara has now made all materials for the course (78 pages) freely available
static1.squarespace.com/stat…

14
128
586
42,302
Ankit Shah retweeted

25 Jun 2025
Wow!
The core finding in the much-maligned Apple paper from @ParshinShojaee et al – that reasoning models generalize poorly in the face of complexity – has been conceptually replicated three times in three weeks.
C. Opus sure didn’t see that coming. And a lot of people owe Ms. Shojaee an apology.
25 Jun 2025

The programs we look at are quite simple and all represent novel combinations of familiar operations. We also find lower performance for more complex programs, especially for the compositions. Also, I have a sense that LLMs can handle OOD problems easier when represented in code
3
15
58
17,893
Ankit Shah retweeted

Ok I’ve read it now and as I expected the complaints about it are ill founded. It seems fine. I think it convincingly shows a lot of what I’ve been saying about these thinking models.

I still haven’t read that Apple paper but I see a lot of people complaining about it. To me, the complaints I’ve seen seem ill founded given what I understand about it, but obviously it’s hard for me to judge without having read the paper. What are the most reasonable complaints?
5
12
232
15,623
Ankit Shah retweeted

10 Mar 2025
Friends, need your help.
@antarikshB, a senior from IIT B has launched an incredible project of organizing all Sanskrit literature in one place, in a user-friendly manner.
The service is free, not-for-profit, created purely out of passion. Media coverage will go a long way in ensuring the service reaches the right people.
Could you help by RT-ing and perhaps tag the right people?
(link below)
176
2,468
4,969
243,617
Ankit Shah retweeted

30 Oct 2024
I like how they use the infinite rotation to make planning easier. Taking advantage of how your humanoid doesn't need to be human
3
6
67
4,060
Ankit Shah retweeted

15 Oct 2024
How can robots understand spatiotemporal language in novel environments without retraining? 🗣️🤖
In our #IROS2024 paper, we present a modular system that uses LLMs and a VLM to ground spatiotemporal navigation commands in unseen environments described by multimodal semantic maps
1
11
22
3,594
Ankit Shah retweeted

14 Oct 2024
Recent results like Apple’s show that LLMs (even o1) flub on reasoning with simple changes to problems that shouldn’t matter. A consensus is building that it shows they are “just pattern matching.” But that metaphor is misleading: good reasoning itself can also be framed as “just pattern matching” at each step. The issue is not that we are merely seeing pattern matching, but that we are seeing *bad* pattern matching, at the wrong level of abstraction. If you think about it, that is a more serious pathology because it doesn’t separate when it works vs. when it doesn’t work into conveniently distinct buckets of computational tasks, In a sense, calling it “just pattern matching” implies an easier fix than there really is, as if all it will take is a better o1.
28
24
210
36,706
Ankit Shah retweeted

30 Sep 2024
Evaluation in robot learning papers, or, please stop using only success rate
a paper and a 🧵
arxiv.org/abs/2409.09491
1
38
200
37,215
Ankit Shah retweeted

12 Sep 2024
My (pure) speculation about what OpenAI o1 might be doing
[Caveat: I don't know anything more about the internal workings of o1 than the handful of lines about what they are actually doing in that blog post--and on the face of it, it is not more informative than "It uses Python er.. RL".. But here is what I told my students as one possible way it might be working]
There are two things--RL and "Private CoT" that are mentioned in the writeup. So imagine you are trying to transplant a "generalized AlphaGo"--let's call it GPTGo--onto the underlying LLM token prediction substate.
To do this, you need to know
(1) What are the GPTGo moves? For AlphaGo, we had GO moves). What would be the right moves when the task is just "expand the prompt".. ?
(2) Where is it getting its external success/failure signal from? for AlphaGo, we had simulators/verifiers giving the success/failure signal. The most interesting question in glomming the Self-play idea for general AI agent is where is it getting this signal? (See e.g. x.com/rao2z/status/171625758… )
My guess is that the moves are auto-generated CoTs (thus the moves have very high branching factor). Let's assume--for simplification--that we have a CoT-generating LLM, that generates these CoTs conditioned on the prompt.
The success signal is from training data with correct answers. When the expanded prompt seems to contain the correct answer (presumably LLM-judged?), then it is success. If not failure.
The RL task is: Given the original problem prompt, generate and select a CoT, and use it to continue to extend the prompt (possibly generating subgoal CoTs after every few stages). Get the final success/failure signal for the example (for which you do have answer).
Loop on a gazillion training examples with answers, and multiple times per example. [The training examples with answers can either be coming from benchmarks, or from synthetic data with problems and their solutions--using external solvers; see x.com/rao2z/status/171625758…]
Let RL do its thing to figure out credit-blame assignment for the CoTs that were used in that example. Incorporate this RL backup signal into the CoT genertor's weights (?).
<At this point, you now have a CoT generator that is better than before the RL stage>
During inference, stage, you can basically do rollouts (a la the original AlphaGo) to further improve the effectiveness of the moves ("internal CoT's"). The higher the roll out, the longer the time.
My guess is that what O1 is printing as a summary is just a summary of the "winning path" (according to it)--rather than the full roll out tree.
===
Assuming I am on the right path here in guessing what o1 is doing, a couple corollaries:
1. This can at least be better than just fine tuning on the synthetic data (again see x.com/rao2z/status/171625758…)--we are getting more leverage out of the data by learning move (auto CoT) generators. [Think behavior cloning vs. RL..]
2. There will not still be any guarantees that the answers provided are "correct"--they may be probabilistically a little more correct (subject to the training data). If you want guarantees, you still will need some sort of LLM-Modulo approach even on top of this (c.f. arxiv.org/abs/2402.01817).
3. It is certainly not clear that anyone will be willing to really wait for long periods of time during inference (it is already painful to wait for 10 sec for a 10 word last letter concatenation!). See x.com/rao2z/status/183431495…
The kind of people who will wait for longer periods would certainly want guarantees--and there are deep and narrow System 2's a plenty that can be used for many such cases.
4. There is a bit of a Ship of Theseus feel to calling o1 an LLM--considering how far it is from the other LLM models (all of which essentially have teacher-forced training and sub-real-time next token prediction. That said, this is certainly an interesting way to build a generalized system 2'ish component on top of LLM substrates--but without guarantees. I think we will need to understand how this would combine with other efforts to get System 2 behavior--including LLM-Modulo (arxiv.org/abs/2402.01817) that give guarantees for specific classes.
to be contd..

12 Sep 2024

One thing about o1 model is to what extent end users are actually at all interested in "waiting" (see the death of online computation thread below). And if they are actually have the patience, there do exist guaranteed deep/narrow System 2 solvers for specific problems!
24
112
561
147,314
Ankit Shah retweeted

5 Aug 2024
@jasonxyliu will present their @IJCAIconf survey paper on robotic language grounding. Please check out his talk (8/8 11:30) if you are at #IJCAI2024
In colab w/ @VanyaCohen, Raymond Mooney from @UTAustin, @StefanieTellex from @BrownCSDept, @drdavidjwatkins from The AI Institute
5 Aug 2024

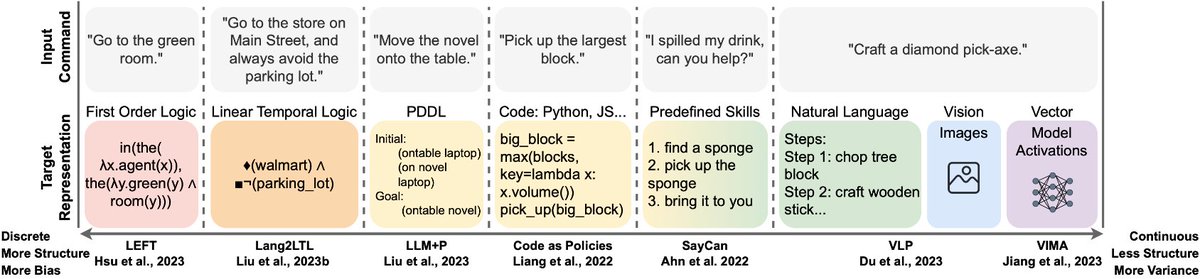
How do robots understand natural language?
#IJCAI2024 survey paper on robotic language grounding
We situated papers into a spectrum w/ two poles, grounding language to symbols and high-dimensional embeddings. We discussed tradeoffs, open problems & exciting future directions!
3
10
997
Ankit Shah retweeted
27 Jul 2024
All the talk recordings are available at youtube.com/playlist?list=PL…
1
1
135
Ankit Shah retweeted
18 Jul 2024
We will hear from an amazing line of speakers at our #RSS2024 workshop on robotic task specification tomorrow at 2 PM (CEST) in Aula Hall B
@HadasKressGazit, @PeterStone_TX, @ybisk, @dabelcs, @cedcolas
More details at: sites.google.com/view/rss-ta…

1
5
6
2,427

RL in POMDPs is hard because you need memory. Remembering *everything* is expensive, and RNNs can only get you so far applied naively.
New paper: 🎉 we introduce a theory-backed loss function that greatly improves RNN performance! 🧵 1/n
5
56
322
45,458

Ever wonder if LLMs use tools🛠️ the way we ask them?
We explore LLMs using classical planners: are they writing *correct* PDDL (planning) problems?
Say hi👋 to Planetarium🪐, a benchmark of 132k natural language & PDDL problems.
📜 Preprint: arxiv.org/abs/2407.03321
🧵1/n

9
40
193
189,178

14 May 2024
Enforcing safety constraints with an LLM-modulo planner. Presented by @ZiyiYang96 at #ICRA2024
13 May 2024

I'm at #ICRA2024 and will be presenting my paper titled "Plug in the Safety Chip: Enforcing Constraints for LLM-driven Robot Agents" (yzylmc.github.io/safety-chip…). Excited 🦾🤖
2
7
935
14 May 2024
Solving new tasks zero shot using prior experience in a related task! Find @jasonxyliu at #ICRA2024
13 May 2024
How can robots reuse learned policies to solve novel tasks without retraining?
In our #ICRA2024 paper, we leverage the compositionality of task specification to transfer skills learned from a set of training tasks to solve novel tasks zero-shot
3
201
Ankit Shah retweeted
13 May 2024
How can robots reuse learned policies to solve novel tasks without retraining?
In our #ICRA2024 paper, we leverage the compositionality of task specification to transfer skills learned from a set of training tasks to solve novel tasks zero-shot
1
3
12
2,288
Ankit Shah retweeted

7 May 2024
Back on April 1st I posted my three laws of robotics. Here are my three laws of AI.
1. When an AI system performs a task, human observers immediately estimate its general competence in areas that seem related. Usually that estimate is wildly overinflated.
2. Most successful AI deployments have a human somewhere in the loop (perhaps the person they are helping) and their intelligence smooths the edges.
3. Without carefully boxing in how an AI system is deployed there is always a long tail of special cases that take decades to discover and fix. Paradoxically all those fixes are AI-complete themselves.
8
47
162
26,607
