
135 Photos and videos
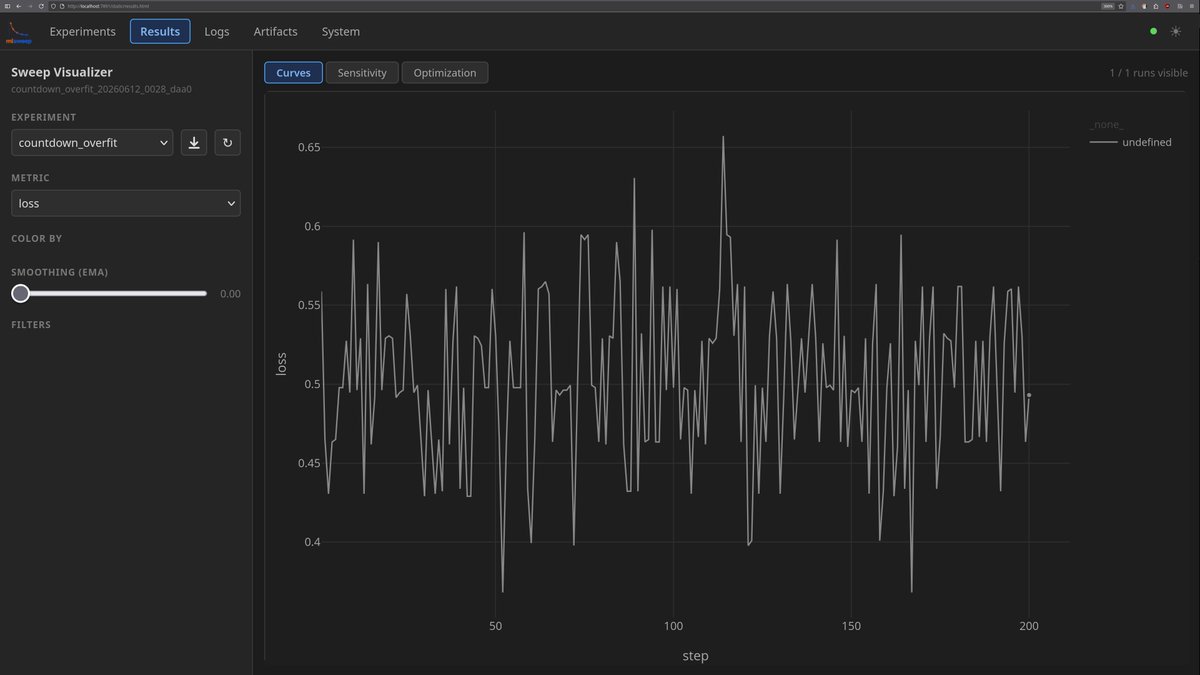









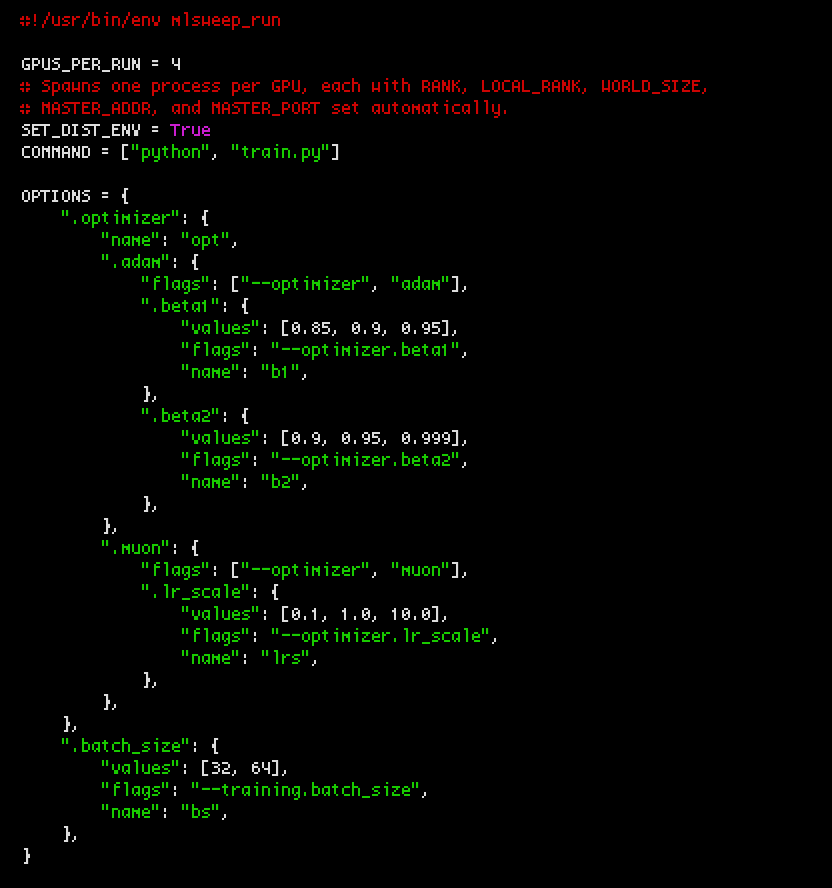
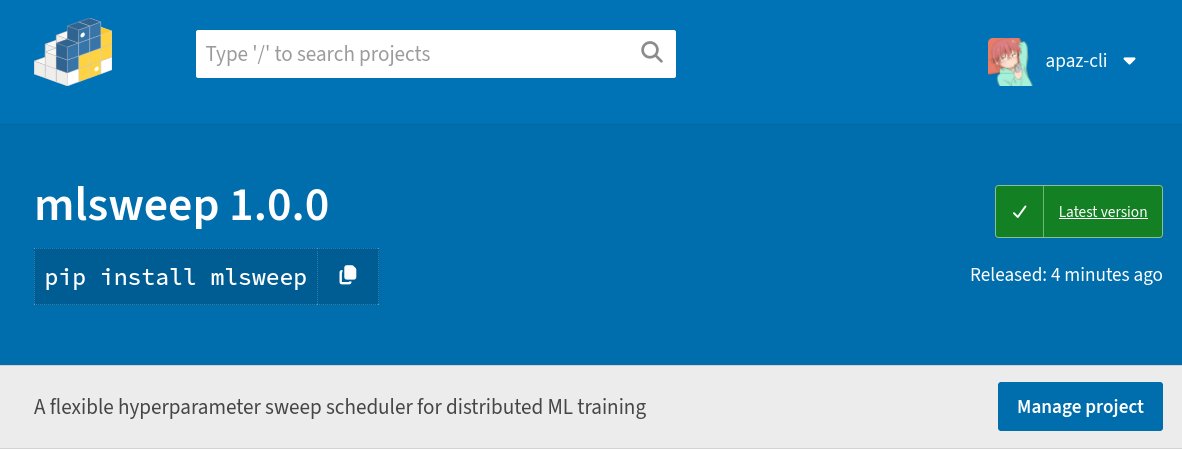


Releasing mlsweep, a sweep scheduler and visualizer for distributed ML training. It aims to make launching runs across groups GPUs frictionless and achieve near feature-parity with wandb. But you can use it with whatever frameworks or loggers you like, wandb included.
2
7
40
4,073
I'm slamming my head into kernel autoresearch and... it feels so close and so far simultaneously. I think we're cooked until someone cracks it, at which point things will rapidly improve. And then new hardware will be released and we'll be cooked again. DSV4 doesn't know tcgen05.
60
Suppose I have some fancy new way of doing RL. What's the most convincing smallish experiment that I can use to derive scaling laws? Some sort of math benchmark on qwen3 1.5b or something? But I hear that's qwenslop. It might be qwenslop. What's in the same ballpark but better?
3
17
1,950

I love how any the normalized length of any sufficiently large vector of normally distributed random variables converges to 1 by the law of large numbers. This lets you clip ES gradient projections for cheaper because you don't have to do a reduction to compute the length.
1
175
I understand not wanting to do SFT. There are real gains from not doing it. But the choice to pretrain without pretraining on things that look like rollouts is confusing to me. There is a big distribution mismatch there, as big as base model vs instruction tune. IMO it should be a part of midtraining. There are ways to produce data that looks like a rollout without actually sampling a rollout.
Jun 2

Many choices here are only possible when your objective is not an immediate or short-term performance. Pretraining without synthetic data, posttraining without SFT with data from other LLMs. (And other good choices like scaling ladder with NLL instead of benchmark scores).
1
217
Suppose in deep learning that we didn't do gradient accumulation/batching and we had full knowledge of what components of the grad came from what item. In that case would it make sense to apply grad clipping per-item?
One preserves information, the other bounds step magnitude.
1
1
154
I will hand it to Anthropic, the model released, I switched to it, and it instantly found a bug. It also instantly started annoyed me. An adjustment for sure.
May 29

300k tokens trying to teach 4.8 how Bend's termination checker works 🫠 maybe not so bright, but somehow a pleasure to talk to and definitely my favorite model of all time

7
473
I'm writing a blog post that requires doing a lot of gradient estimation noise math. I'll doublecheck this paper quick too.
The way this tends to work is that if it does better in theory than existing techniques it's promising. Otherwise it's garbage and not worth pursuing.

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
1
1
10
1,831
Update here x.com/apaz_cli/status/205968…

Okay never mind. The gradient noise math is correct, and it scales fine. But it optimizes a proxy objective, not the real objective.
Stepping in a direction that is not the real objective is noise. So the question is, what is the difference between that objective and this one for your target distribution? This is not really measurable in theory, only in practice.
In any case I think this noise is even less fixable than MeZO.
Yes this proxy objective appears to be fine for general language modeling, but lots of things are fine for general language modeling. It's an easy problem. If you want to do something like reasoning RL with this proxy objective you will probably run into problems.
2
210
Okay never mind. The gradient noise math is correct, and it scales fine. But it optimizes a proxy objective, not the real objective.
Stepping in a direction that is not the real objective is noise. So the question is, what is the difference between that objective and this one for your target distribution? This is not really measurable in theory, only in practice.
In any case I think this noise is even less fixable than MeZO.
Yes this proxy objective appears to be fine for general language modeling, but lots of things are fine for general language modeling. It's an easy problem. If you want to do something like reasoning RL with this proxy objective you will probably run into problems.
I'm writing a blog post that requires doing a lot of gradient estimation noise math. I'll doublecheck this paper quick too.
The way this tends to work is that if it does better in theory than existing techniques it's promising. Otherwise it's garbage and not worth pursuing.
5
640
They're reduce-scattering me tomorrow
May 25

they're orthogonalizing me tomorrow
2
310