
PhD in Physics. Ultracold atoms & optical lattices. Interests: condensed matter, epistemology, quantitative finance, economic cycles and crypto markets.
Joined October 2015
- Tweets 556
- Following 154
- Followers 497
- Likes 1,434
185 Photos and videos
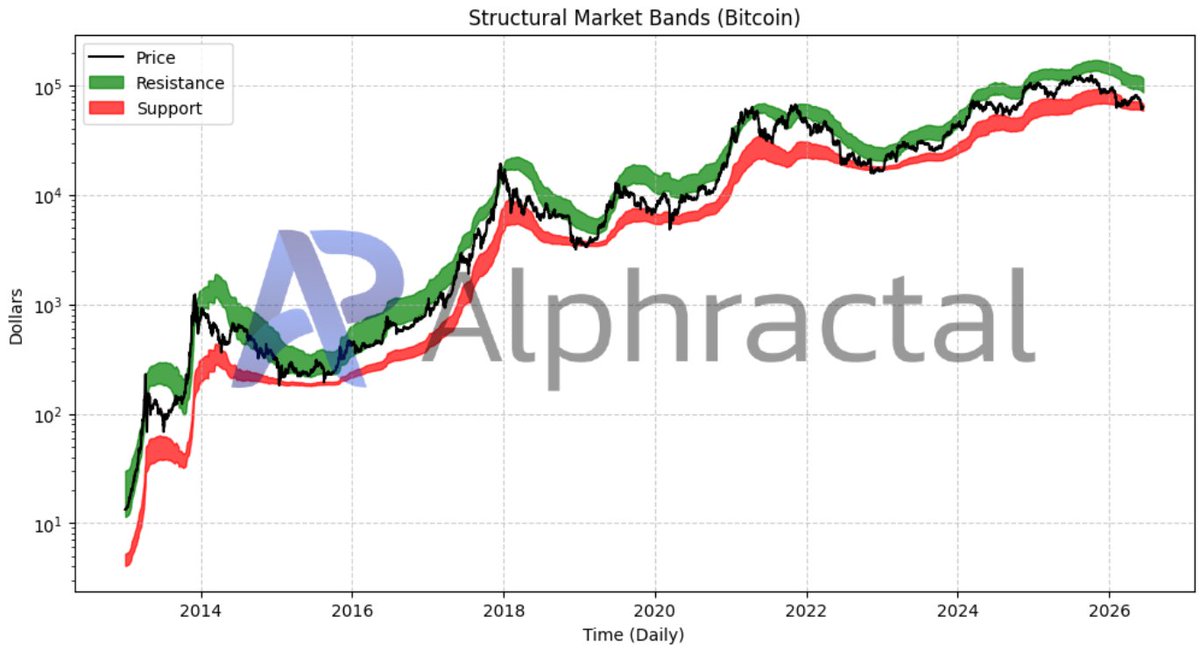
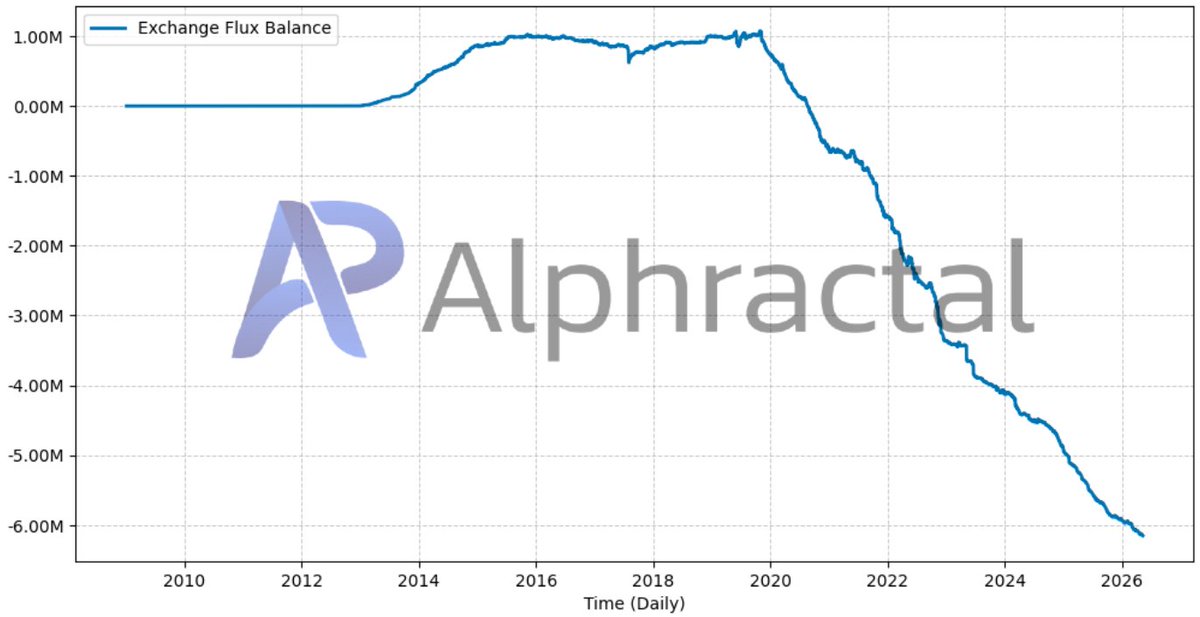









I’ve been working on this metric for some time now. Structural Market Bands uses 100% on-chain data for a model that resembles a physical law more than a statistical model. It’s surprising how blockchain technology enables valuation models with such clearly defined price ranges. I can’t classify these resistance and support levels as “probabilities”; the only concept that fits here is “potential.”
There is one limitation: due to the way it is constructed, it is only valid for UTXO-type blockchains. Even so, it is not suitable for all of them. For example, a significant portion of Zcash’s transactions are private, which prevents this calculation from being accurate. Dash’s mining system complicates the calculation for the support zone, making it very imprecise.
This metric will soon be available on the @Alphractal platform.
1
2
19
4,400
Arch Physicist retweeted
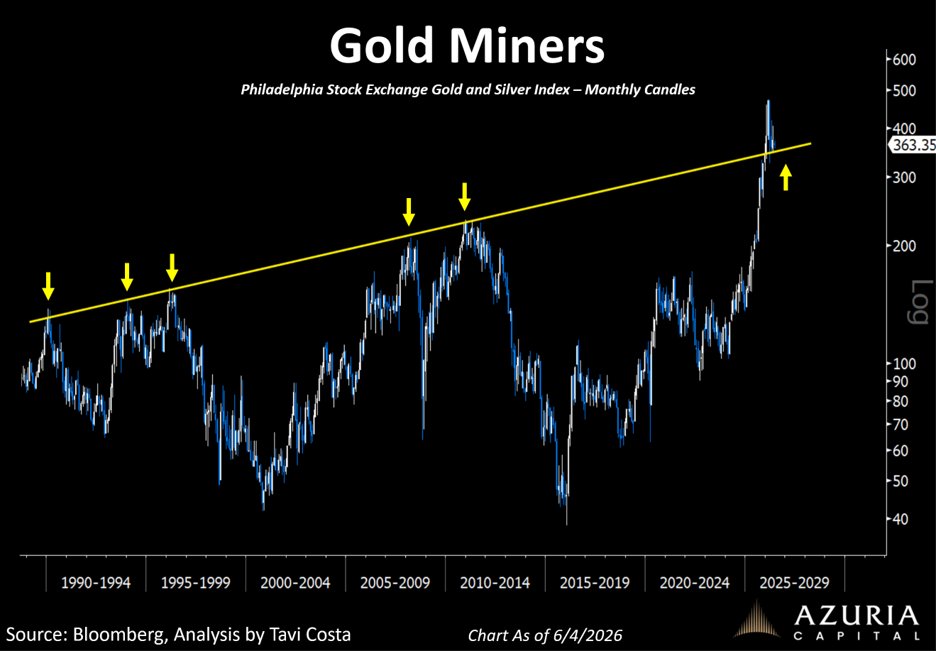
There is nothing more technically bullish than a 40-year resistance level turning into major support.
That is exactly where gold miners sit today.
Act accordingly.
tavicosta.substack.com/p/a-s…
89
255
1,426
55,673
Bear market is when price is moving from structural top to structural bottom. If there is no panic, this goes from a redistribution plateau to another redistribution plateau. Since October, it has been within the bear market structure. And the real structural capitulation level, only the future can show. Balanced price is just a metric, and I am waiting to see what price level it will reach, which may not happen.
May 26

People screaming bear market while Bitcoin still trades 2x above structural capitulation levels is peak emotional trading
1
4
258
Arch Physicist retweeted

May 26
Every on-chain metric you've read about Bitcoin — SOPR, MVRV, Realized Cap, Coin Days Destroyed — exists because of one architectural decision: UTXO.
Bitcoin doesn't have account balances. It has fragments. Every fragment is timestamped, valued, and traceable.
Here's the mechanics, and the metrics built on top of it 🧵
—
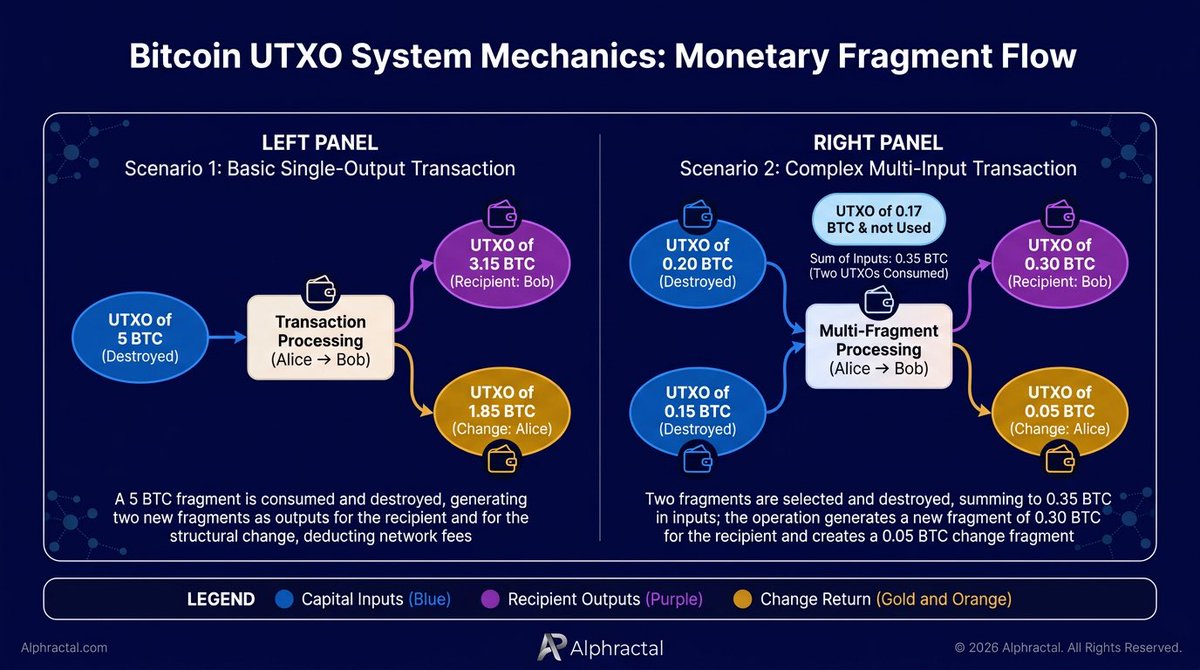
Bitcoin's architecture is based on an accounting model called Unspent Transaction Output — known in the market by the acronym UTXO. This concept translates as "unspent transaction outputs" and acts as the official mechanism for recording capital ownership on the network. The system manages individual fragments of coins received by users and still pending transfer.
The decentralized protocol has a structurally distinct logic from traditional banking institutions. The fiat system is based on updates to unified balances in central accounts.
The importance of this model lies in its capacity to ensure the integrity of the digital financial system. Operationally, it works through the continuous destruction and creation of these fragments. Each new transaction necessarily consumes one or more existing fragments as inputs. The process transfers financial value and generates new fragments as outputs — for the recipient and for the structural change — always after deducting network fees.
Two operational scenarios illustrate the dynamic:
— Scenario 1 (basic transaction): a wallet contains a single fragment of 5 BTC and needs to send 3.15 BTC to a recipient. The protocol consumes and destroys the original 5 BTC fragment and creates two new output fragments: 3.15 BTC effectively transferred to the recipient, and 1.85 BTC returned to the origin wallet as change.
— Scenario 2 (complex multi-input transaction): a wallet holds three distinct fragments worth 0.20 BTC, 0.15 BTC, and 0.17 BTC. The user decides to send 0.30 BTC. The system selects and destroys the 0.20 and 0.15 BTC fragments to total 0.35 BTC in inputs. The operation generates a new 0.30 BTC fragment for the recipient and a 0.05 BTC change fragment. The 0.17 BTC fragment remains unused.
This architectural mechanism enables analysts to rigorously quantify activity on the blockchain. Each fragment carries with it an exact timestamp and an immutable financial value. Observing this data enables tracking the age of capital, identifying structural accumulation levels, and measuring the temporal behavior of investors.
3
5
28
3,719
Arch Physicist retweeted

May 6
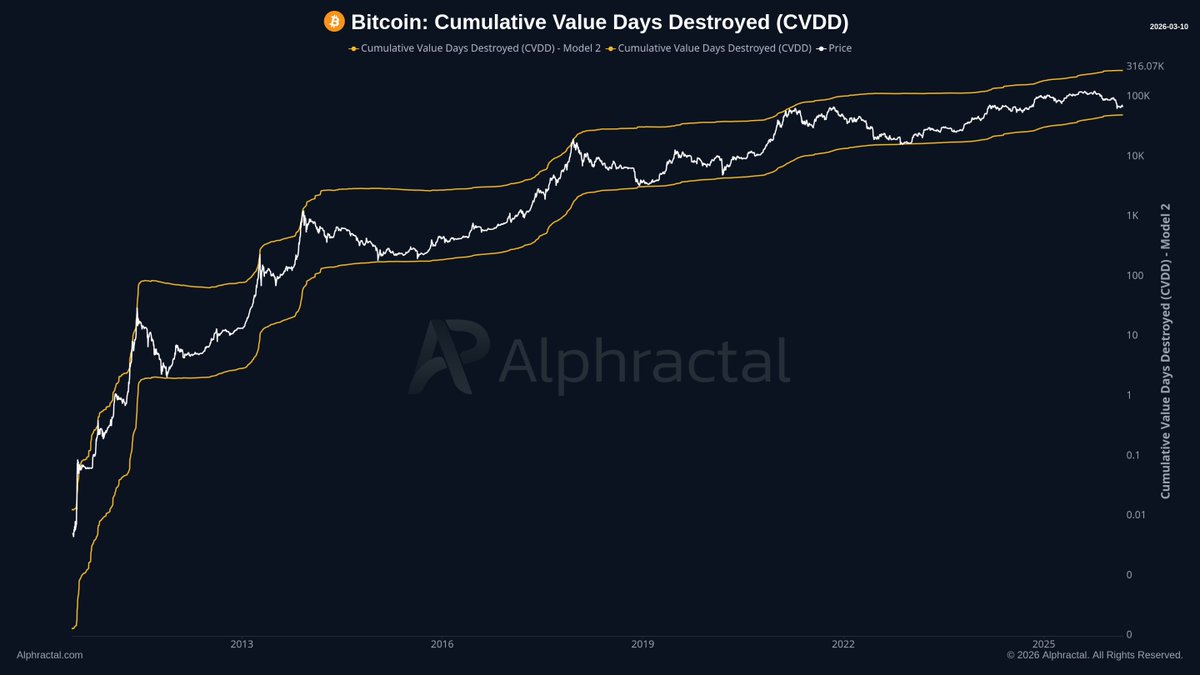
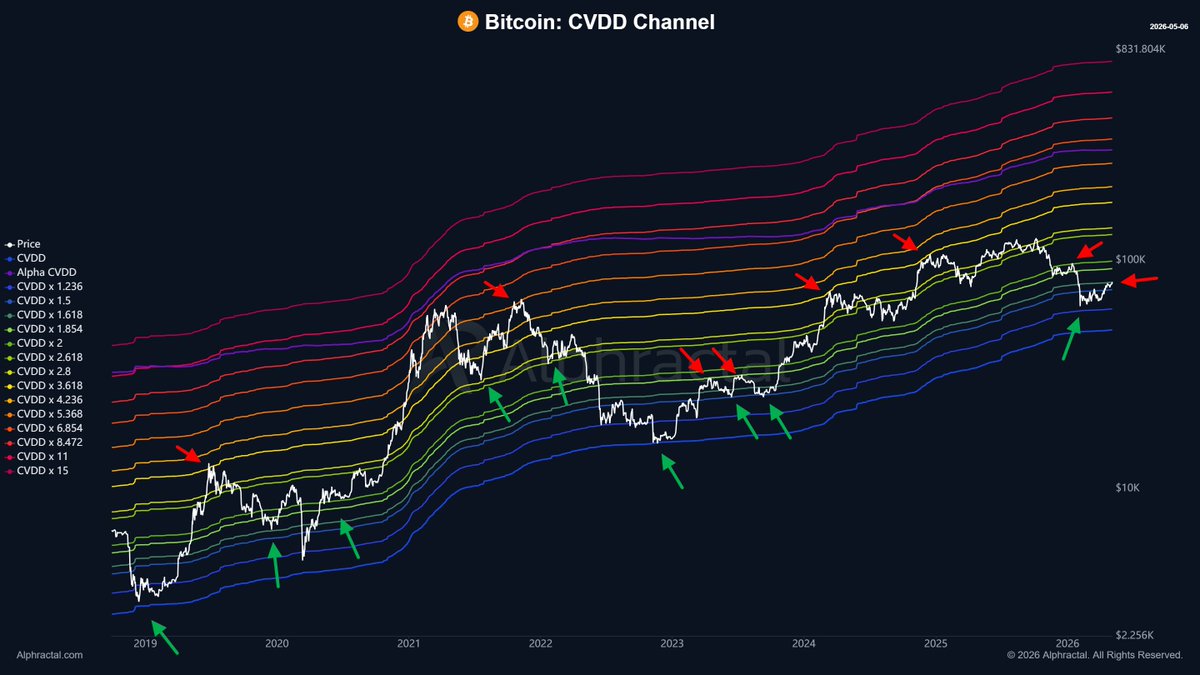
On-chain levels map Bitcoin’s price history like no other metric does.
And for Bitcoin, price has just reached a key resistance level. Tomorrow we will see whether it has enough strength to break through it.
This metric is based on CVDD, but unlike the CVDD used by other platforms, Alphractal’s CVDD was adjusted based on Bitcoin’s issuance eras rather than a fixed value. Full credit for this improvement goes to @arch_physicist!
6
4
92
4,230
Arch Physicist retweeted

May 23
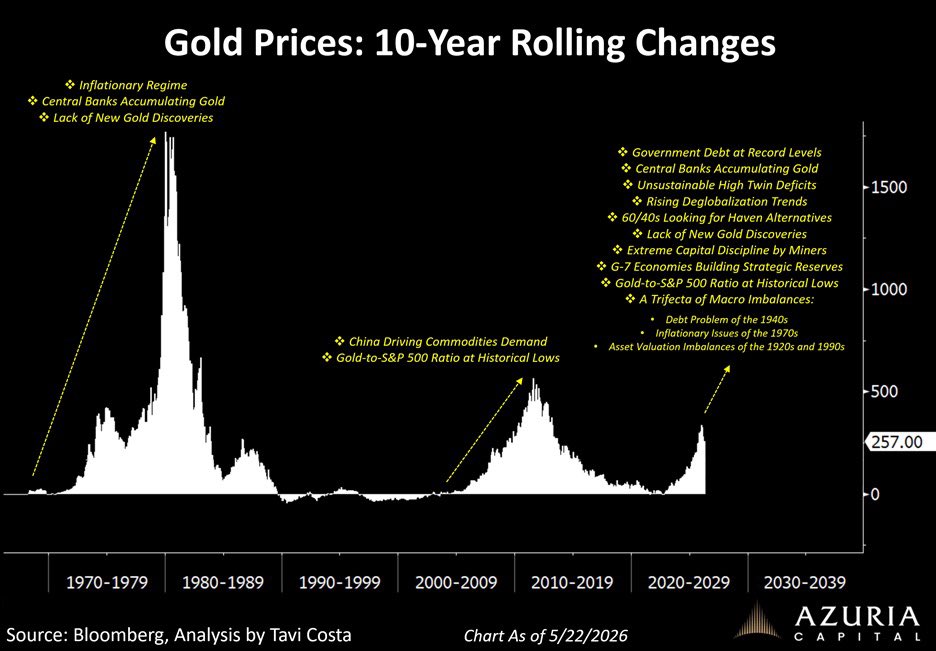
One of the most useful ways to think about long-term investment theses is through 10-year rolling performance windows across asset classes.
Monetary assets like gold historically go through very long periods of both outperformance and underperformance.
We are still in the early innings of this cycle.
open.substack.com/pub/tavico…
41
123
729
42,611
Arch Physicist retweeted

"Compra S&P500. Bolsa sempre sobe."
Buffett (e Munger) está com a maior posição de caixa da história da Berkshire.
Benjamin Graham, o pai do value investing, estaria fora do mercado. Falta margem de segurança.
John Templeton estaria migrando capital para fora dos EUA.
Peter Lynch estaria comprando, mas ações específicas — nunca o índice cegamente.
Joel Greenblatt estaria ignorando o índice e garimpando small caps esquecidas.
Stanley Druckenmiller declarou publicamente em fevereiro: está comprado em cobre, ouro e vendido em dólar e Treasuries. IA não é mais o tema central.
Ray Dalio projeta retorno de longo prazo do S&P500 em 4,7% ao ano — abaixo dos próprios títulos do Tesouro americano.
Howard Marks, um dos maiores estudiosos de ciclos de mercado da história, está operando com cautela máxima.
Os maiores investidores de todos os tempos estão, cada um da sua maneira, evitando o índice.
Mas compra S&P. Bolsa sempre sobe. Confia.
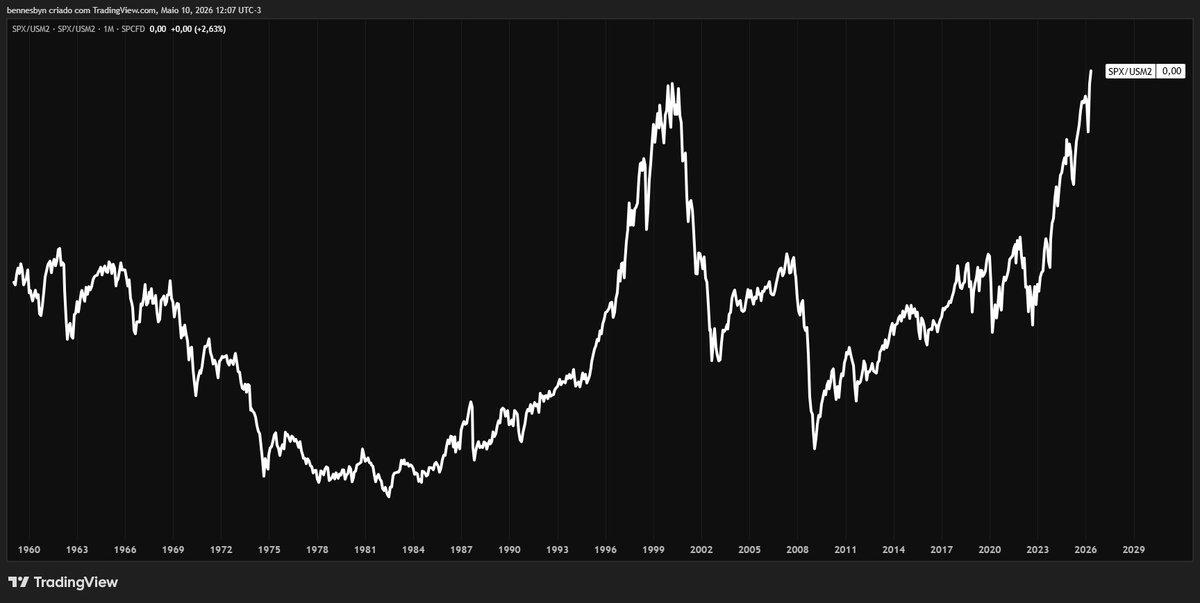
ALT SPX deflacionado pela oferta monetária dos EUA. Estamos nos níveis de 2000.
10
4
60
5,942
Arch Physicist retweeted
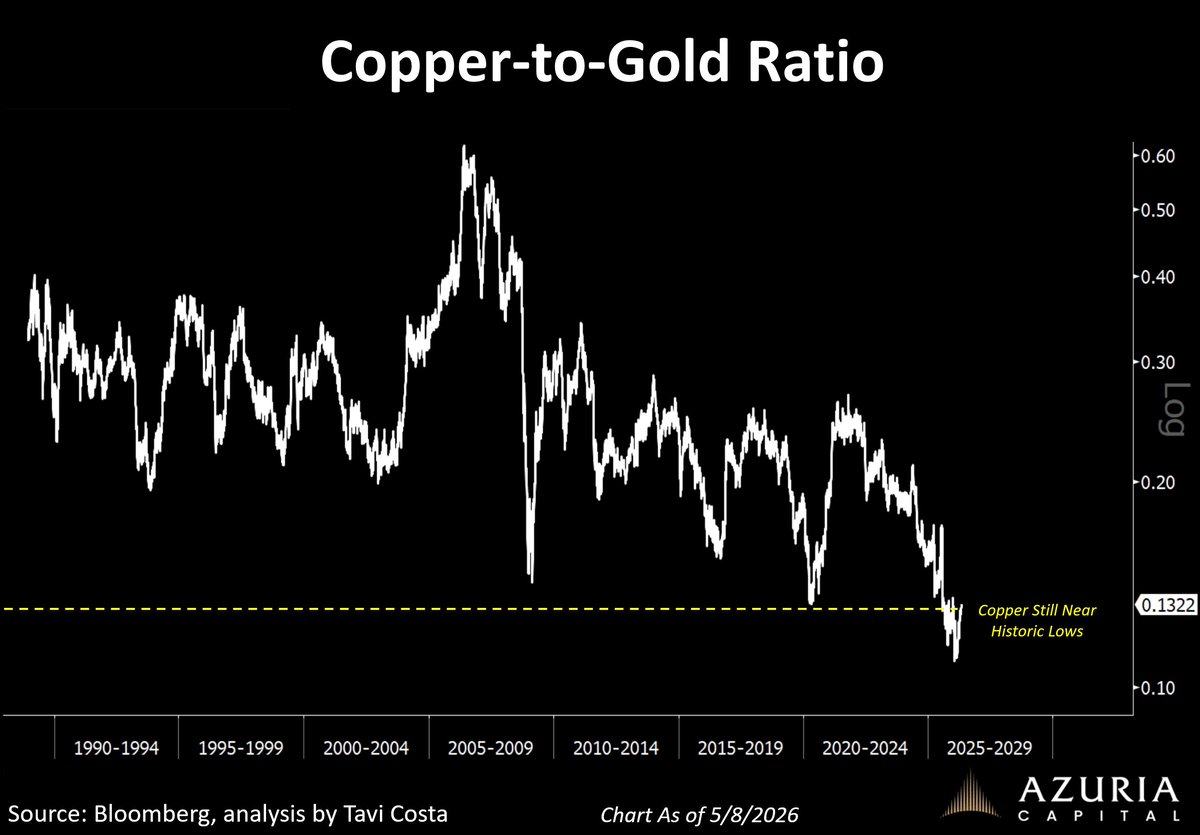
It’s wild to see copper hitting record highs while still trading near historical lows when priced in gold terms.
The copper-to-gold ratio remains nearly 80% below its 2006 peak.
More importantly:
Periods where copper became this cheap relative to gold have historically not lasted very long.
tavicosta.substack.com/p/cop…
49
152
1,012
62,040

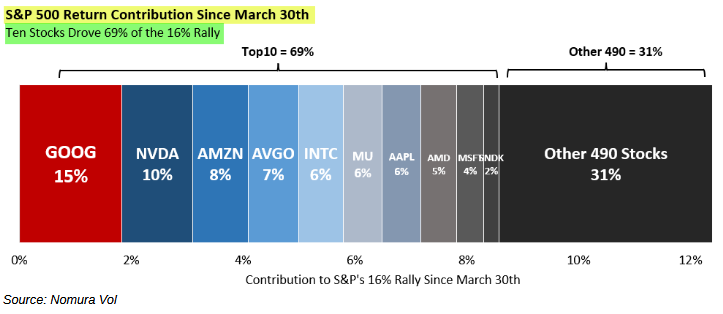
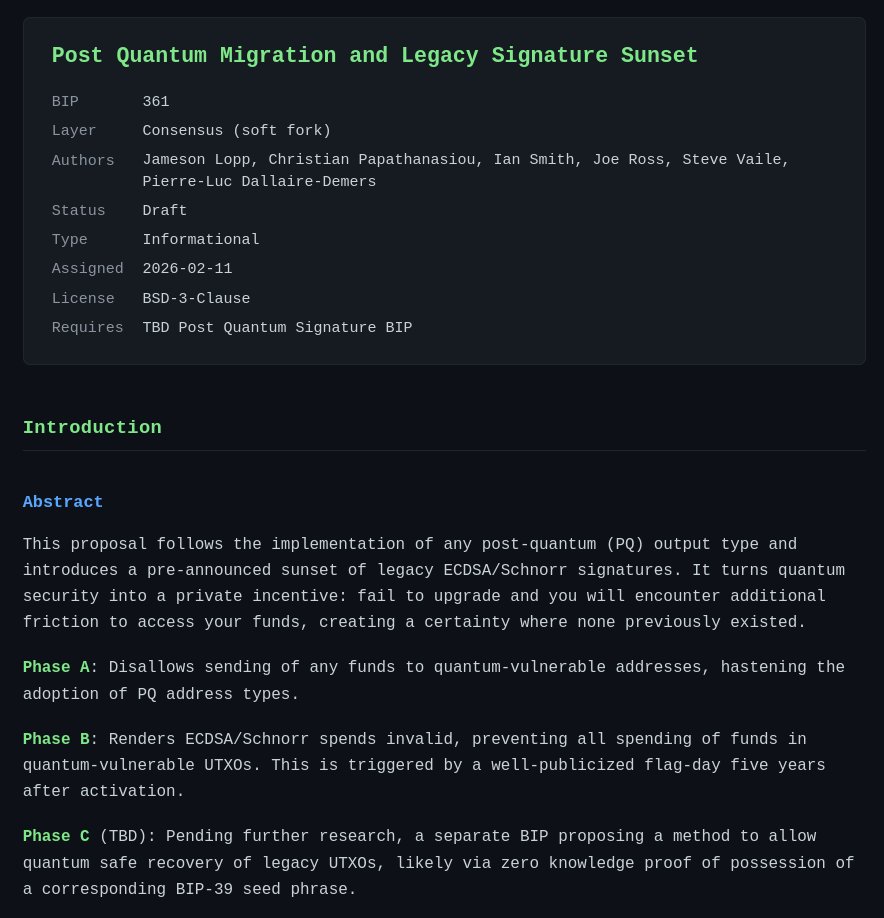
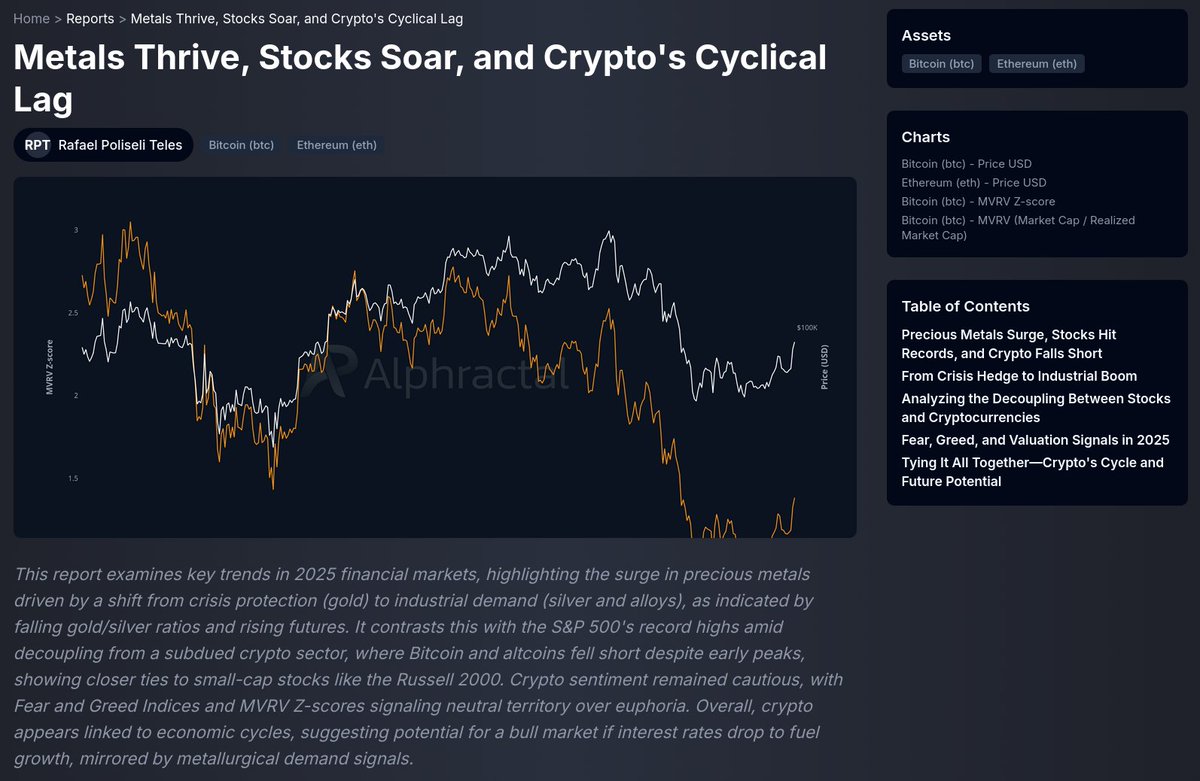
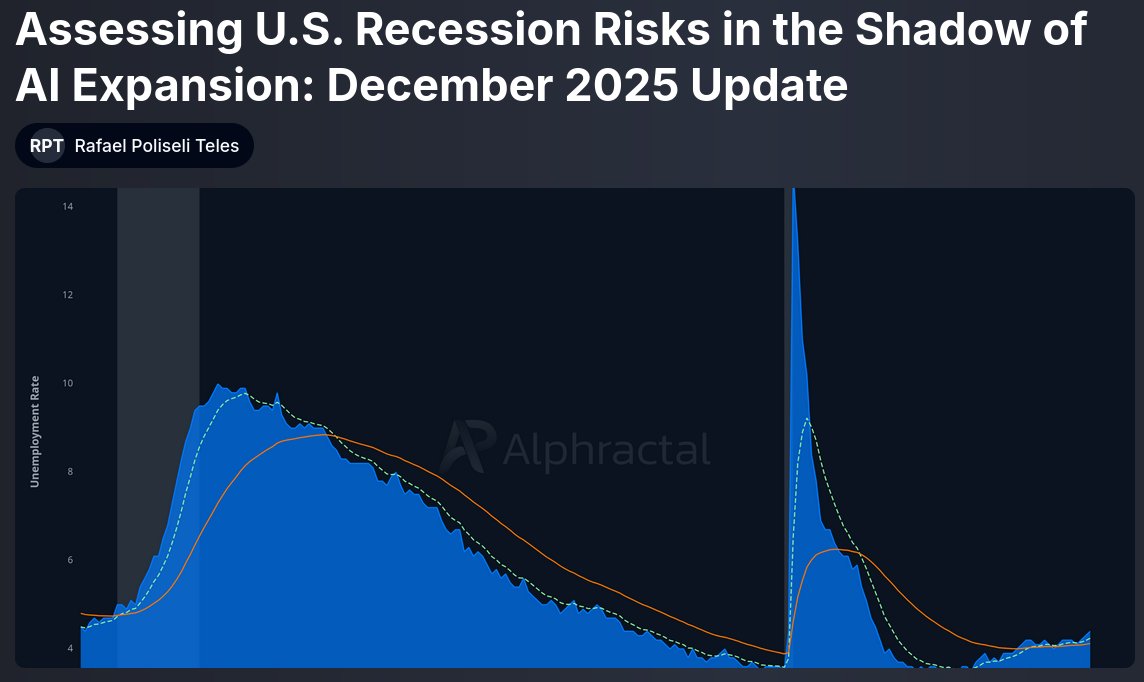
Title: The Quantum Threshold and the Strategic Defense of Bitcoin
Abstract: This report analyzes the risk posed by quantum computation to legacy encryption and evaluates the strategic responses within the Bitcoin ecosystem. It examines the technical utility of BIP 361 in securing vulnerable assets through protocol level freezing and introduces a Transparent Proof of Knowledge recovery system. These mechanisms ensure a secure transition to modern standards while maintaining the fundamental principles of individual property sovereignty and ledger immutability.
Free Report: app.alphractal.com/research/…

1
10
2,314
3
2,454
Arch Physicist retweeted

Apr 2
Holy shit. The biggest unsolved problem in AI agents isn't reasoning it's memory. Your agent forgets everything between sessions.
MemFactory just open-sourced the first unified framework for training agents to manage their own memory via reinforcement learning. Extract.
Update. Retrieve. All trainable. All modular. Runs on one GPU.
Every AI agent built today is amnesiac by design. It can reason. It can plan.
It can use tools. But the moment a session ends, everything it learned about you, your preferences, your context, and your history disappears.
The next conversation starts from zero.
This is not a minor inconvenience it is the fundamental barrier between AI assistants and AI agents that actually work over days, weeks, and months. The field has known this for years.
The solutions have been fragmented, task-specific, and impossible to combine. Memory-R1 handles structured CRUD operations on a memory bank. MemAgent compresses history into a fixed-length recurrent state.
RMM optimizes retrieval through retrospective reflection. Each works.
None can be combined. Each lives in its own repository with its own data format, its own training pipeline, and its own set of assumptions. MemFactory ends that fragmentation.
The core insight is that memory management is a decision problem, not a retrieval problem. Current systems treat memory as a database store things, look things up.
MemFactory treats memory as a policy an agent that learns when to extract new information, when to update existing memories, when to delete contradicted facts, and what to retrieve for any given query.
That policy is trained via reinforcement learning, specifically Group Relative Policy Optimization, which eliminates the need for a separate critic model and cuts training memory requirements in half.
This matters because memory-augmented agents already have saturated context windows from dialogue history and retrieved content.
The last thing they need is a training algorithm that doubles the memory footprint.
The architecture is four layers that compose like Lego blocks.
The Module Layer decomposes memory into atomic operations:
> Extractor parses raw conversations into structured memory entries,
> Updater decides whether each new piece of information should be added, modify an existing entry, delete a contradiction, or left alone,
> Retriever fetches relevant memories using semantic search or LLM-based reranking.
The Agent Layer assembles these modules into a complete memory policy and executes rollout trajectories during training.
The Environment Layer standardizes any dataset into the format the agent needs and computes reward signals format rewards for structural compliance, LLM-as-a-judge scores for quality.
The Trainer Layer runs GRPO to update the memory policy based on those rewards. Every module plugs into every other module through standardized interfaces.
You can swap the retriever in Memory-R1 for an LLM-based reranker without touching anything else.
The results from training a MemAgent-style architecture through MemFactory on two base models:
→ Qwen3-1.7B base: average score 0.3118 across three evaluation sets
→ Qwen3-1.7B after MemFactory RL: 0.3581 14.8% relative improvement
→ Qwen3-4B-Instruct base: average score 0.6146
→ Qwen3-4B-Instruct after MemFactory RL: 0.6595 7.3% relative
improvement
→ 4B model gains hold on out-of-distribution benchmarks the memory policy transfers to unseen tasks
→ Entire training and evaluation pipeline runs on a single NVIDIA A800 80GB GPU
→ 250 training steps on simplified long-context data no massive compute cluster required
→ Three ready-to-use agent architectures out of the box: MemoryR1Agent, MemoryAgent, MemoryRMMAgent
> The out-of-distribution result is the one that matters most. The 1.7B model improved on in-domain tasks but slightly degraded on the OOD benchmark the learned policy was too specific to the training distribution.
The 4B model improved on both.
This is the capability threshold at which a memory policy becomes genuinely general: large enough to abstract principles about what information is worth keeping, not just pattern-match on training examples.
A memory agent that only remembers the right things in familiar situations is not much better than no memory at all.
The 4B result suggests that threshold is reachable with models that fit on a single consumer GPU.
> The fragmentation problem MemFactory solves is deeper than it looks. When every memory implementation has its own pipeline, researchers cannot compare approaches fairly.
Two systems that nominally differ by one design choice say, CRUD operations versus recurrent state compression actually differ simultaneously in data format, reward structure, training algorithm, and evaluation protocol.
Nobody knows which choice caused which outcome.
MemFactory puts all three major paradigms under the same training loop, the same reward computation, and the same evaluation framework.
Now you can actually isolate what matters.
Your agent forgets everything. This is the infrastructure to fix that.

24
38
257
20,016
Arch Physicist retweeted
Apr 2
How to build a Custom Dashboard that works as a decision system.
5 steps.
Step 1: Click " New Dashboard"
A blank panel opens.
Name it after its objective.
Good examples:
→ "Market Overview"
→ "Top & Bottom Timing"
→ "Short-Term Setup"
The name sets the intention. If the name is vague, the dashboard will be too.
Step 2: Define the objective before adding anything
One question before you touch a single chart:
"What decisions is this dashboard going to help me make?"
→ Is the market overpriced or underpriced?
→ Is a trend starting or ending?
→ Should I increase or reduce exposure?
If you can't answer that clearly — you're building a collection, not a system.
Step 3: Add charts that complement, not duplicate
Less is more.
A solid starting structure:
→ Risk / cycle metric
ex: Market Temperature
identifies excess optimism or pessimism
→ On-chain behavior
accumulation or distribution signals
→ Price context
aligns on-chain data with price action
If two metrics tell you the same thing
with different names, remove one.
Step 4: Organize the visual flow
Drag charts into a logical reading order:
→ Top: market regime metrics (macro / cycle)
→ Middle: confirmation metrics (on-chain, sentiment)
→ Bottom: execution metrics (price, momentum)
Top to bottom = context to decision.
You don't look at timing until cycle and on-chain confirm.
Step 5: Use it as a daily checklist
Open the same dashboard every day. Read it in the same sequence.
Over time, patterns become visible.
When Market Temperature enters an elevated zone
while other metrics decelerate — asymmetric risk becomes clear before
price confirms it.
That's the edge a structured dashboard builds.
1
1
10
3,014
Arch Physicist retweeted
Mar 27
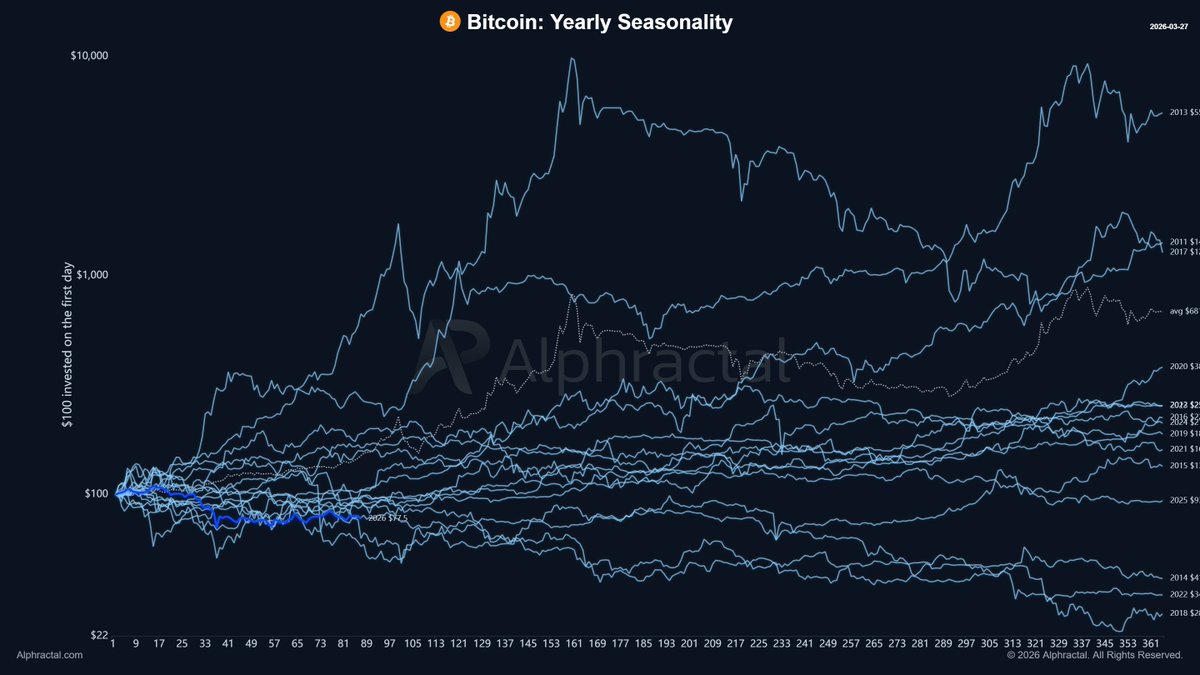
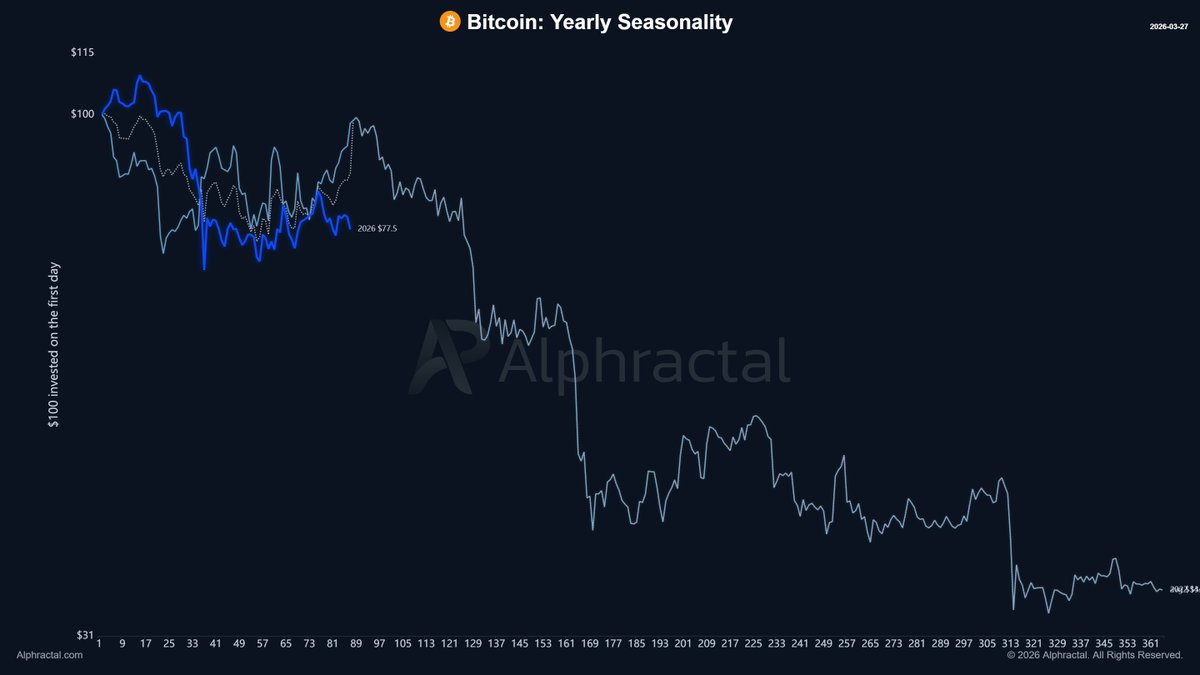
Which past year does Bitcoin’s 2026 resemble?
Starting with bear market years like 2014, 2018, and 2022.
See more in the thread:


1
1
29
2,650
STHRP and Active Realized Price are primary indicators for identifying Bitcoin market cycle transitions. Historical price action from 2018 and 2022 shows that STHRP functions as a global ceiling, while its -1.5 SD serves as a support floor.
The recent crossover in March 2026 suggests the onset of a new bearish phase. Although this is an initial signal, it is a key development for cycle analysis.
I’ve released a detailed report on this for @Alphractal Standard Plan subscribers.
app.alphractal.com/research/…
1
11
2,159
Arch Physicist retweeted
Mar 10
The biggest launch in Alphractal’s history is now officially live! 🎉
After months of rebuilding the platform from the ground up, the new Alphractal experience is officially here.
This release goes far beyond interface changes.
It restructures how data is organized, consumed, and acted upon.
What’s included in the update:
• New UX Architecture — redesigned navigation logic, reduced cognitive load, optimized information hierarchy
• Fully Customizable Dashboard — modular widgets, metric pinning, layout control, multi-chart structuring
• Smart Alert System — condition-based triggers across on-chain, derivatives, and macro metrics
• Alpha AI — contextual interpretation of charts, liquidity conditions, positioning data, and cycle structure
• Performance Optimization — faster data rendering, improved chart responsiveness, streamlined workflow
• High-Performance Data Engine — faster database architecture, lower latency queries, improved real-time processing
• Advanced Variation Selectors — dynamic statistical filters, multi-timeframe deviation analysis, volatility-adjusted views
• TradingView Beta Integration — professional-grade charting embedded directly into the Alphractal workflow
• New Alpha Metrics — proprietary cycle, liquidity and positioning indicators built for macro-aware accumulation
The objective remains simple:
More signal density.
Less operational friction.
Higher decision efficiency.
The next evolution of Alphractal starts now.
Explore the update 👇
7
6
37
25,698
Arch Physicist retweeted
Mar 23
1. Before any indicator, the basics:
A cryptocurrency is built on three layers: → A token with market value → A network infrastructure (own blockchain or third-party) → A community and real adoption
Concrete examples:
Bitcoin: decentralized money project that replicates the characteristics of physical currency (divisibility, fungibility, transportability, etc.) with the objective of achieving the three fundamental functions of money: store of value, medium of exchange and unit of account.
Ethereum: smart contract platform (software) that runs on a blockchain.Hyperliquid: decentralized exchange (DEX) project whose blockchain is the order book itself.
AAVE: decentralized liquidity protocol (DApp) that does not have its own blockchain, operating through smart contracts on networks such as Ethereum, Polygon and Avalanche. Its functioning is based on collateralized loans, where the user must deposit assets as collateral (guarantee) to access liquidity.
Understanding a project's architecture is the prerequisite for any serious fundamental analysis.

1
4
11
454
Arch Physicist retweeted
Mar 23
This meme never gets old.
You never know the exact bottom — and it’s not worth having the hubris to think you do.
I’ll keep scaling in at what I see as cheap, historically oversold levels.
No need to follow my approach — I know many prefer to buy at $5,500 instead.
97
298
2,095
193,207