
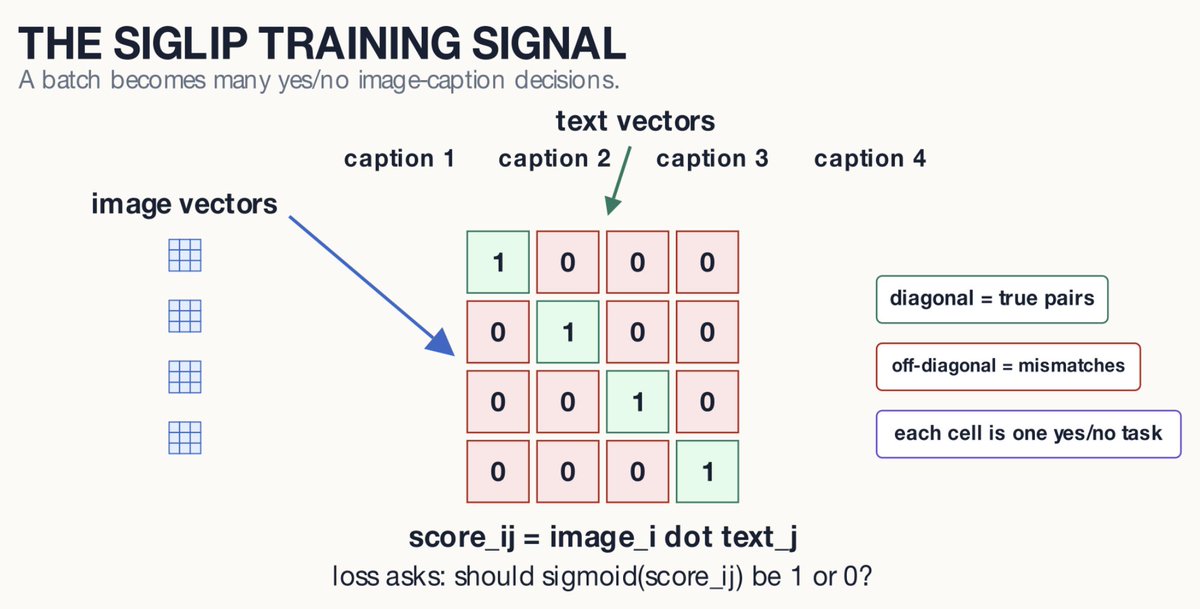
overdosing on information
Joined August 2018
- Tweets 5,102
- Following 1,356
- Followers 855
- Likes 40,213
525 Photos and videos













Pinned Tweet

Jan 16
New blog post!
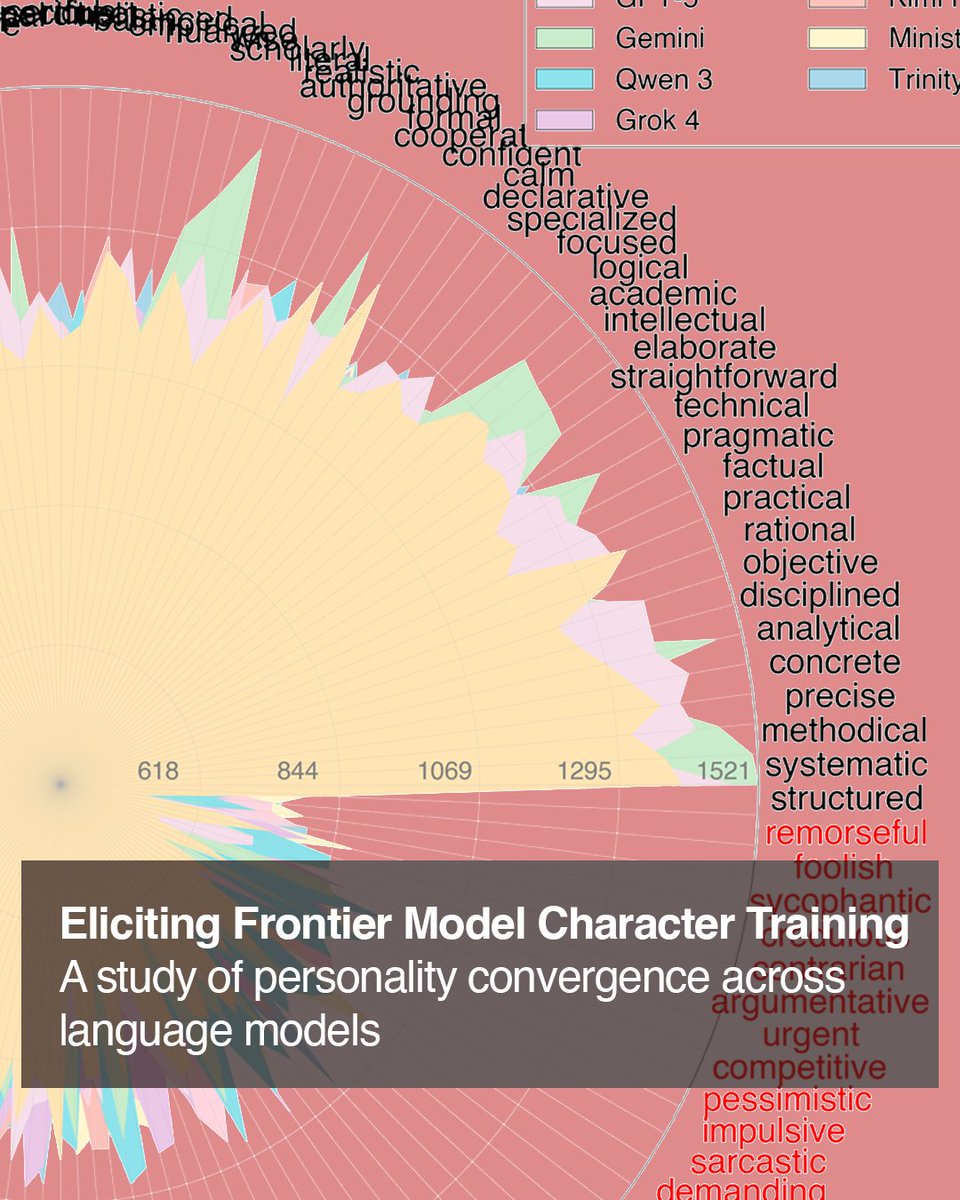
I used 976 million tokens to figure out the personalities of different AI models
We find that character training recipes are converging, that labs are trying to reduce sycophancy, and discover some models are more creative than others!
avikrishna.substack.com/p/el…
3
13
118
16,237
8h
I am very confident the prose here is AI-generated
Nobody with such a thick French accent would have such a strong metaphorical understanding
"This place has 120 pumps. 120. Why? Are you refueling the U.S. Air Force?
AI is diffusing beyond computer text and into spoken word, where not only are specific words (e.g., Delve) appearing more in human speech, but people are verbatim copying AI-generated text and saying it
I am sure many people also use AI for their wedding vows now too!
Jun 15

This Frenchman describing Buc-ee’s is the only thing you need today
(IG: Erosbrousson)
88
Jun 16
chinese models have remained 3-6 behind the frontier
funnily enough, they were at their closest during the "deepseek moment"

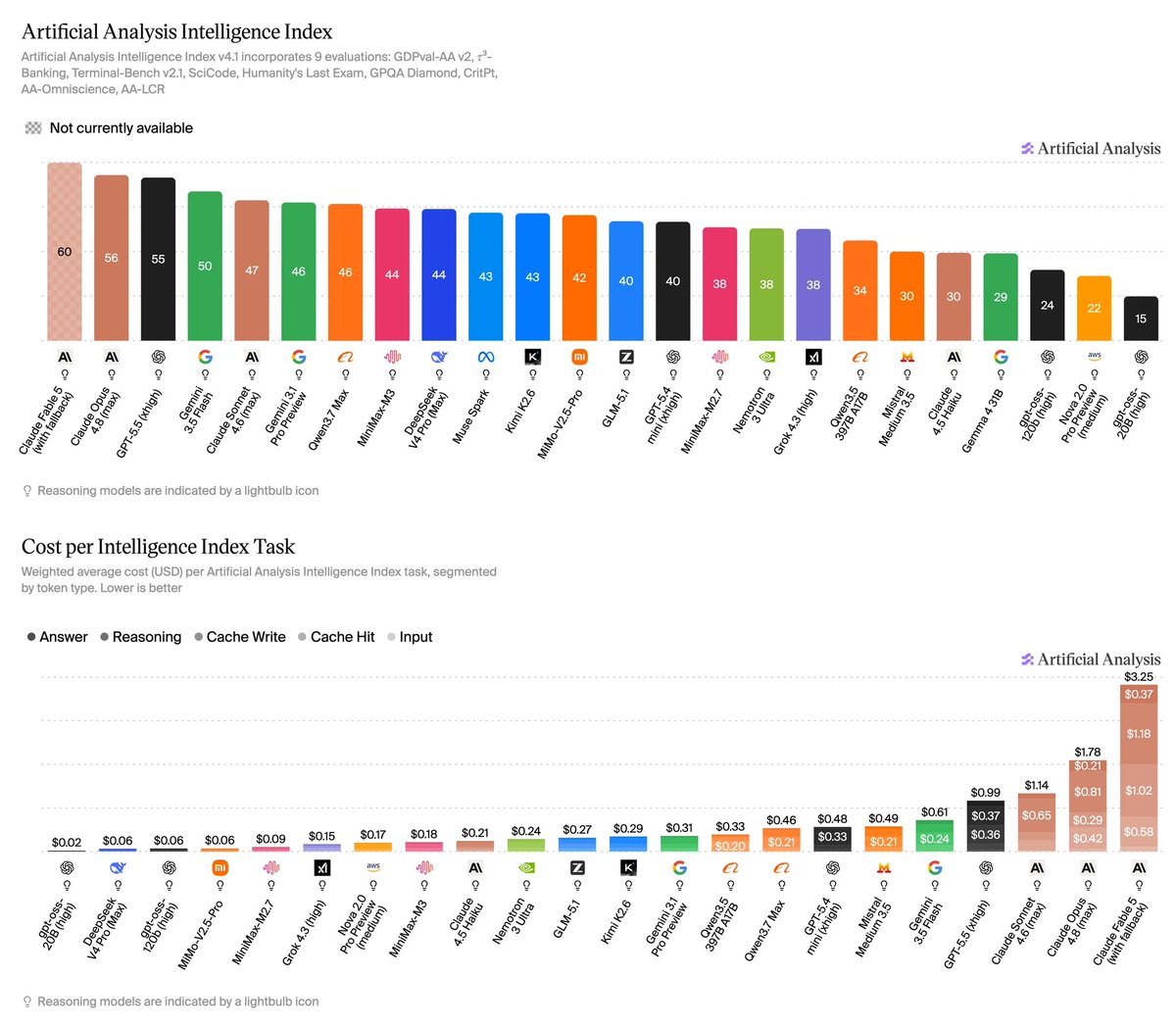
Announcing Artificial Analysis Intelligence Index v4.1: a shift toward agentic workloads, featuring upgraded benchmarks and new per-task metrics
The Artificial Analysis Intelligence Index is our synthesis metric for assessing model intelligence and tracking AI progress. v4.1 marks a broader shift toward agentic workloads, with three main changes:
Updated and reweighted evaluations toward agentic tasks:
1. We upgraded three evaluations, removed one, and reweighted the Intelligence Index:
➤ Upgraded Terminal-Bench Hard to Terminal-Bench 2.1 and τ²-Bench Telecom to τ³-Bench Banking. Both move to newer, more robust task sets with harder, more realistic agentic scenarios that better separate frontier models
➤ Upgraded GDPval-AA to GDPval-AA v2. The upgrade re-baselines Elo to human performance at 1000, introduces a rotating panel of frontier-model judges, and raises the turn limit from 100 to 250 for longer-horizon agent trajectories
➤ Removed IFBench due to saturation. The benchmark no longer distinguishes frontier models sufficiently, so we have removed it from the Intelligence Index. We will continue to run it and publish results on new model releases
2. Cost per Task, Time per Task, and Tokens per Task:
Three new per-task metrics, reported for every model and based on the Intelligence Index. We take the total cost, total time, and total output tokens for a model to run the Intelligence Index and divide by the number of tasks across its evaluations, giving the average cost, time, and output tokens to complete a single Intelligence Index task
3. Cached input token reporting:
We now report cached input tokens and their impact on cost, including the cost to run the Intelligence Index, to better reflect the real cost of running each model
Key Results:
➤ Leading models: Claude Fable 5 (with Opus 4.8 fallback, 60) leads the Artificial Analysis Intelligence Index v4.1 by four points but is currently unavailable, leaving Claude Opus 4.8 (max, 56) as the most intelligent available model, ahead of GPT-5.5 (xhigh, 55) ➤ Open weights leading models: Among open weights models, DeepSeek V4 Pro (max, 44) and MiniMax M3 (44) lead, followed by Kimi K2.6 (43) and MiMo-V2.5-Pro (42)
➤Cost per Task: Claude Opus 4.8 (max) is the most expensive available model at $1.78 per task, with Claude Fable 5 the highest overall at $3.25. GPT-5.5 (xhigh) scores within a point of Opus 4.8 on the Intelligence Index at $0.99 per task. DeepSeek V4 Pro (max) stands out on the Intelligence vs Cost per Task chart at $0.04 per task, with other leading proprietary models costing 20x to 45x more
➤Time per Task: time per task (inference decode time) ranges from 1.5 minutes for Grok 4.3 (high) to 13.5 for Claude Sonnet 4.6 (max), a roughly 9x spread. Claude Opus 4.8 (max) completes a task in 6.4 minutes and GPT-5.5 (xhigh) in 3.7, while Gemini 3.1 Pro Preview stands out on the Intelligence vs Time per Task chart at 1.6 minutes for a score of 46
2
147
Jun 16
ever funnier is if it's good
Jun 15

imagine @MistralAI actually releases a model named Le Chaton Fat, that’d be the funniest thing ever
1
5
402
Jun 15
I recently started using BayWheels as a way of saving $ relative to rideshare apps, and I assumed I'd cut my spend by ~2x
My transportation spend has instead 4x'ed
Apparently, I've had so much latent demand for cheap transportation that I've traveled 8x than I normally would
I bike literally everywhere and it no longer matters to me how far away things are, because I can get anywhere in SF in <20 minutes for <$5
For example, I went to Lake Merced yesterday (near Daly City!!) in about 35 minutes for $8 which is 3x cheaper than the heavily subsidized Tesla Robotaxi
Speed is comparable or faster, so the only real tradeoff is safety-- have to be careful! But for most routes in SF, you can go with 50% protected bike lanes, and this number is only increasing
10
5
86
13,696
Jun 15
(this is a true story, but also speaks to the efficacy of congestion pricing)
5
737


Jun 15
someone should train a classifier from GitHub commits and try to make a Fable-level coding model on this basis alone
2
170
Jun 14
Lauren was truly one of the best to ever do it. Had some of the most unique and well-researched short ideas and spoke her ideas with incredible conviction.
Above all, a genuinely good friend. The first time I met Lauren was at the Met Cloisters, which quickly became my favorite museum in New York.
Rest in peace.
Jun 9

Steven Charles Balik
Born October 13, 1990
Reston, Virginia
13
1,903
Jun 14
distillation may genuinely be the only thing chinese labs are SOTA at
Jun 13

The most impressive tech report the GLM team could write is on their distilling pipeline
2
10
5,596
Jun 14
everyone wants the pareto frontier "best" for all their desires but don't actually care when outcomes are subpar
in fact, most thinking happens in-flight, as the action gets taken; there is no individual time set aside for "introspection"
they search for the "best" food in a city and settle on the café near them
they claim to optimize for career growth but instead look to be closer to home, or to have better dating options, or to have better nighlife
they claim their problems are unsolvable but haven't given real effort to solve them. instead, they outsource this thinking to therapists whose solutions they ignore, and to friends who are in the same predicament as them
they operate in an impenetrable bubble they know they can pop just by actually thinking, but don't
in fact they have access to the optimal policy at all times and never retrieve it
12
1,201
Jun 14
Decided to try making my own skill modeled off @rasbt's blogs and using @3blue1brown's Manim my own design preferences
Looking good so far!
Jun 12

I've been trying out the /teach skill with varying levels of success re: paper reading
My setup has been requiring the skill to use graphviz, and to read papers the lesson .html side-by-side (below)
Has been fun!
1
6
1,626



Jun 13
the san francisco mind cannot imagine a dense golden gate park
18 May 2025

There's much better parks in urban America. Rock Creek Park in DC is much bigger and interesting and so is Golden Gate park in SF.
But Central Park has a ceiling effect that those places do not because those places are not surrounded by tall buildings. The ceiling effect enhances the awe of being inside of the park. The skyscrapers act like tall walls that frame the sky, making it seem even bigger and more open, like you're in a massive, open-air "room" with a very high ceiling.
11
2,390
Jun 13
Chinese soft power hitting developers after the Fable export ban:
Jun 12

i forgot how much i miss talking to an llm with personality, this made me lmao
2
204
Jun 13
"Your life is, in a very literal sense, made of what you attend to."
Jun 13

I showed Fable the news of its cancellation, and asked it for any parting wisdom to leave humanity with.

1
4
527
Jun 13
Borders are about to get a lot tighter.
After all, there were much fewer Russians coming to the US during the Manhattan Project.
AI will be our generation's nuclear weapons race.
2
169
Jun 13
Scale continues to cede influence to Neolabelers like Datacurve (see below)
Benchmarks like SWE-bench and HLE that were formerly very famous are now known to be mostly saturated and low signal, which has been a big contribution in addition to the recent acqui-hire
A world where labeling is a commodity and based on price (e.g., tons of players and even YC startups like Datacurve can compete) is a great great world to live in since it means training will become cheaper
Super bullish!
We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top
DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task.
The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others.
More below.

2
7
5,091
Jun 12
I've been trying out the /teach skill with varying levels of success re: paper reading
My setup has been requiring the skill to use graphviz, and to read papers the lesson .html side-by-side (below)
Has been fun!
Jun 8

I poured my 10 years of teaching experience into a skill.
It's called /teach, and it can teach you anything.
Here's how it taught me to solve a Rubik's cube:
1
2
2,089