
Research Eng @ramplabs / physics math nerd / Kate Bush fan
Joined July 2019
- Tweets 716
- Following 382
- Followers 647
- Likes 6,506
16 Photos and videos













Ben Geist retweeted

Jun 4
Most companies slow down at scale.
Ramp is accelerating.
70,000 businesses now run on Ramp. AI agents are becoming part of the finance team. And @RampLabs is shipping frontier experiments every week.
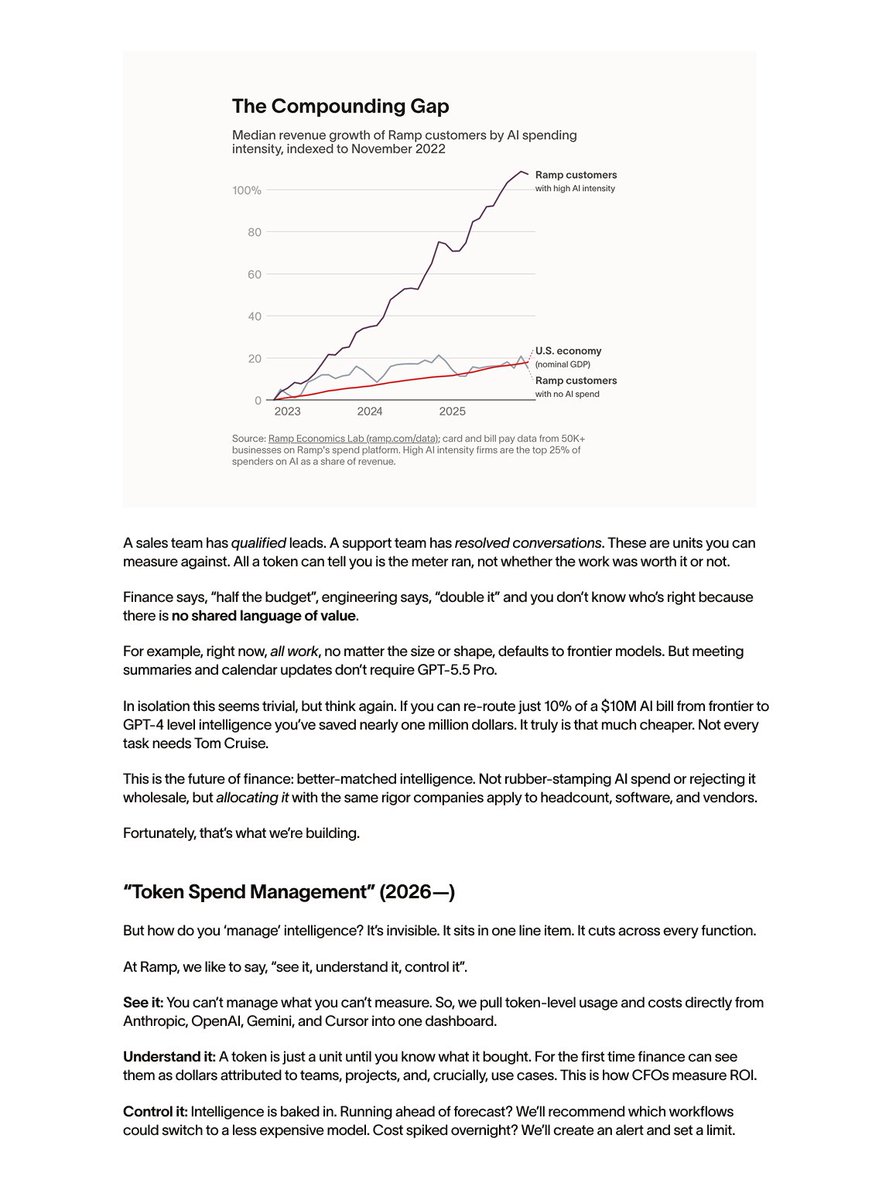
Today: $ 44B.
The next chapter of finance will be agentic and we’re building it.
Jun 4

Today, Ramp raised $750M at a $44B valuation.
Last time we grew this fast, we were 1/20th the size.
For 2000 years, business was built on two pillars. Today, a third: intelligence.
It’s your least governed cost. It’s also your single greatest opportunity.



17
16
208
50,888

> ask accounting firm how they’ll scale
> “we’re hiring”
> 300,000 CPAs left the profession
> accounting degrees at a 20 year low
> firms turning away clients they can’t staff
> teach AI the firm’s playbook
> turn it into executable SOPs
> books close in half the time
Jun 3
Introducing Stack.
The AI operating system that lets accounting firms take on more clients without hiring. Learns your firm's process, runs the close, posts the journals. Fully auditable.
We’re living through the biggest shift in accounting since the spreadsheet.
6
609
Ben Geist retweeted

Jun 3
Introducing Stack.
The AI operating system that lets accounting firms take on more clients without hiring. Learns your firm's process, runs the close, posts the journals. Fully auditable.
We’re living through the biggest shift in accounting since the spreadsheet.
82
139
1,692
926,035
Imo techniques like this and sparse attn will massively reduce the compute bottleneck that limits smaller labs. Chinese labs are already heavily incentivized to create low compute techniques. This will lead to a Cambrian explosion of AI architectures
May 27

Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
pub.sakana.ai/diffusionblock…
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: arxiv.org/abs/2506.14202
GitHub: github.com/SakanaAI/Diffusio…
🐟
1
7
728
Modern security increasingly looks like probabilistic search over huge state spaces. Attackers can already do this with public frontier models, but defenders have a massive advantage with their internal context, telemetry, architecture knowledge, and production feedback loops.
Given the cost of a single breach, the economics of massively scaled defensive agents make a lot of sense.

We deployed 10,000 background agents to security-scan our codebase. The system is simple, scales with compute, and runs on publicly available models. From the scan, we fixed several high-severity vulnerabilities.
9
301
A scaffold for modern memory systems could very well just be optimized block sparse attn

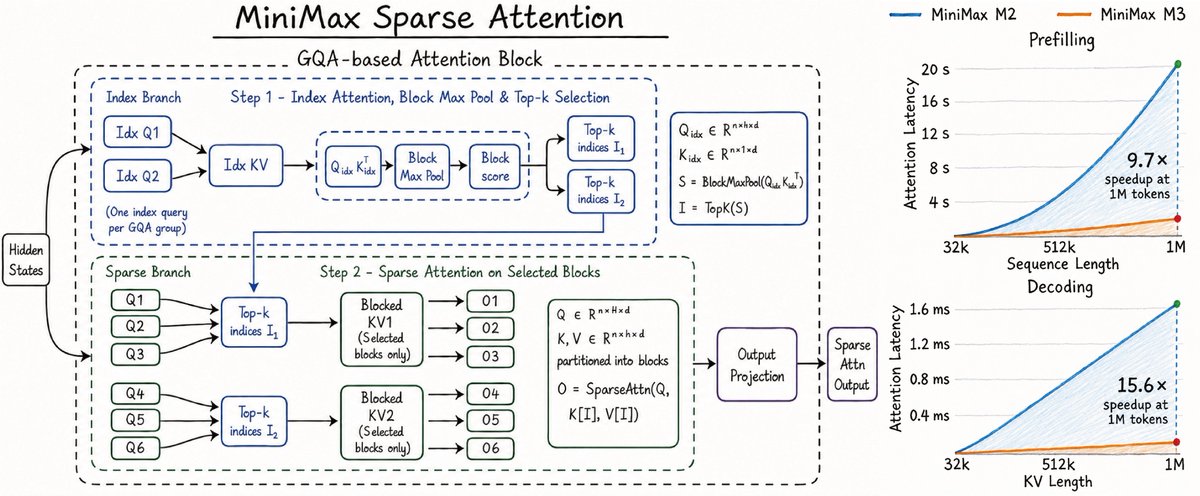
看起来 @MiniMax_AI M3很快就要来了。工程负责人@SkylerMiao7 之前发的一个技术图中可以看到 MiniMax M3 模型确定将会有百万上下文,采用基于GQA(Grouped Query Attention)的动态块稀疏注意力设计。先用 Index Branch 做粗检索,再用 Sparse Branch 对选中的 block 做真实 attention,它的逻辑是:当前 query 不需要看全部历史,只需要看 top-k 相关历史块。打个比方就是看书时候不是把整本书每一页都重读,而是先快速查目录/索引,定位几个相关章节,再精读。这个设计的效果也很明显,一百万上下文,prefill比之前快9.7倍,decode快15.6倍。期待到时候看看DeepSeek V4 和 Minimax M3 谁才是性价比之王。

3
234
Ben Geist retweeted

We worked with @RampLabs to train Fast Ask using Lab
A small RL-trained subagent that helps the Ramp Sheets agent find answers in spreadsheets.
The resulting FastAsk model outperformed Opus 4.6, while obtaining Haiku-level speeds at even lower costs.
4
11
119
55,361
Worked with @PrimeIntellect’s new prime-rl stack to RL a subagent for Ramp Sheets. Latency and accuracy don’t have to be at odds with RL.
2
44
6,301
Really liked this paper. Favorite part was the multi objective GRPO loss. Training the model to reason well and manage its own memory outperformed a single objective setup. Suggests model efficiency and intelligence may be complements, not tradeoffs!
Apr 22

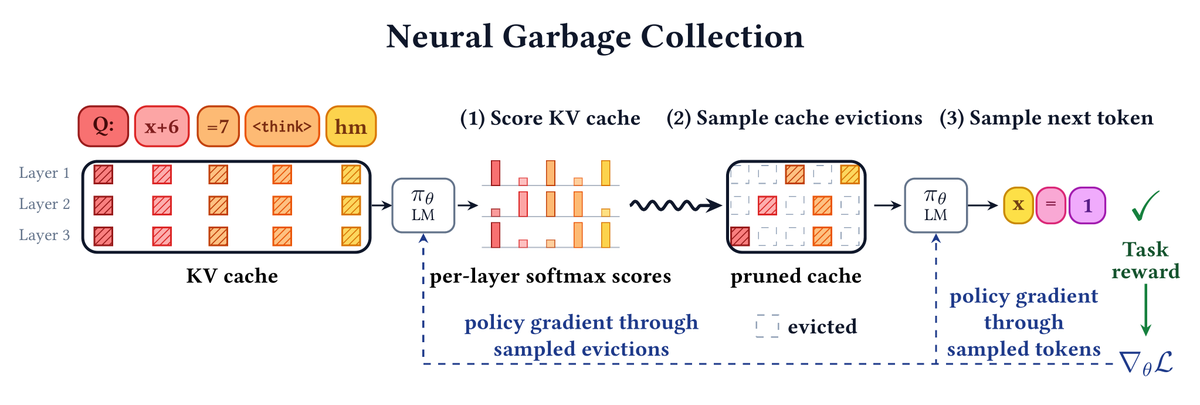
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!
5
563
Ben Geist retweeted

Apr 11
this is a sick idea applying a paper I think is very cool (attention matching) to RLMs
tldr; use this trick to provide extra context to sub-agent calls, I imagine for further recursion depths there are even more clever ways of applying this
3
21
304
32,903
I've been pretty memory obsessed lately. I believe the bottleneck for agentic systems isn't intelligence, but memory. How do agents share what they've learned without drowning each other in tokens? Here's my crack at it!
4
5
65
10,390
Highly suggest reading this article by @rene_sultan, truly a gem
1
2
9
1,418
Today, we're releasing Ramp CLI to let agents manage your company's finances.
50 tools across cards, bills, expenses, travel, and approvals. Fewer tokens than MCP, and comes with pre-built skills like receipt compliance and agentic purchasing.
101
111
2,499
599,954


