
Diffusion Models. We're hiring: bagel.com/careers
Joined June 2023
- Tweets 654
- Following 7
- Followers 12,090
- Likes 2,118
130 Photos and videos














Pinned Tweet

May 28
Today we're releasing Paris 2.0, to our knowledge the first decentralized-trained video generation model.
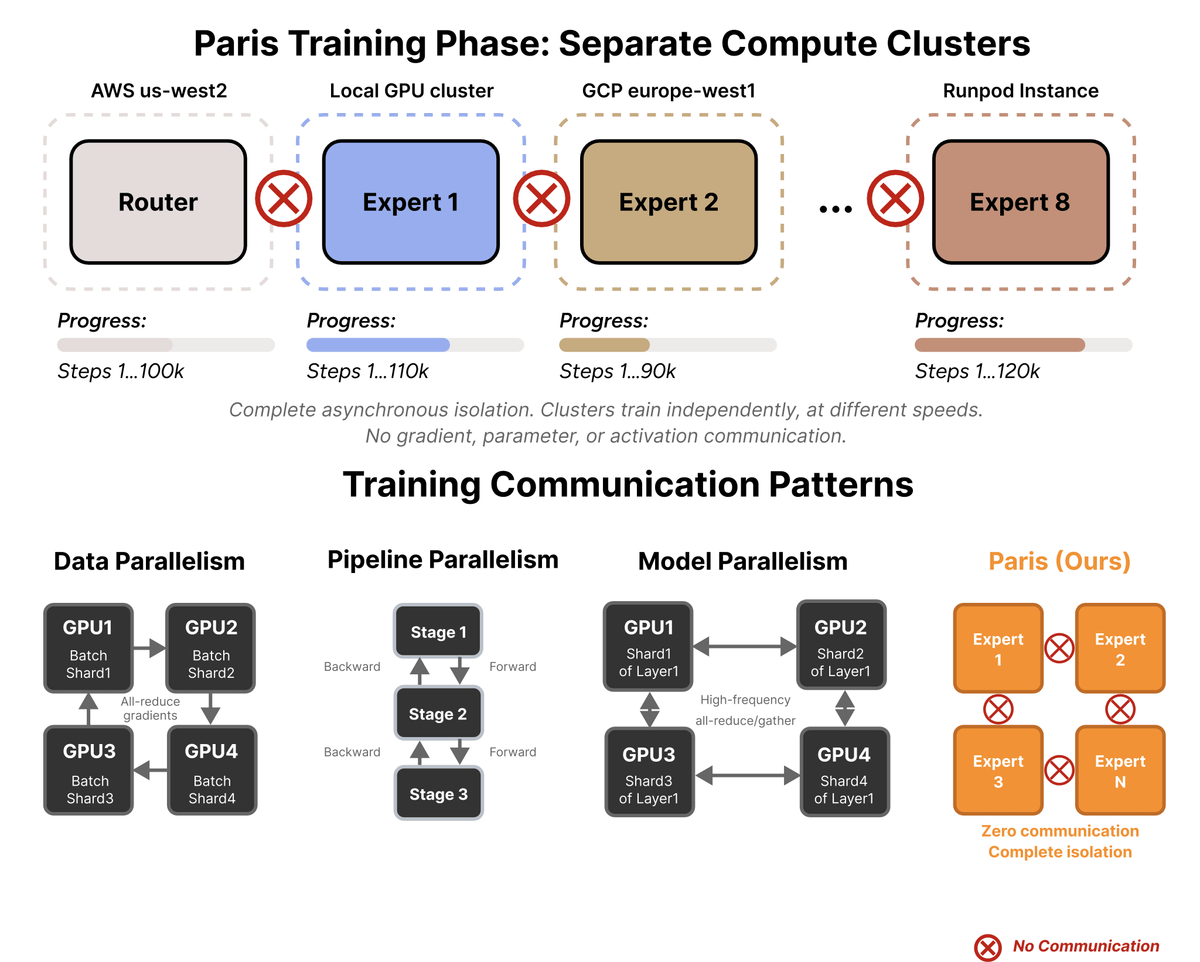
At Bagel Labs, we believe frontier models should not require homogeneous clusters of premium, supply constrained GPUs. Paris 1.0 proved this for image generation. Paris 2.0 extends the recipe to video generation and lays the substrate for global-scale world models.
To test the approach, we trained two models head-to-head in an iso-FLOP, iso-data comparison. One was a monolithic model trained conventionally, on a single premium GPU cluster. The other was Paris 2.0, trained across an extreme mix of GPU types, generations, and vendors distributed around the globe.
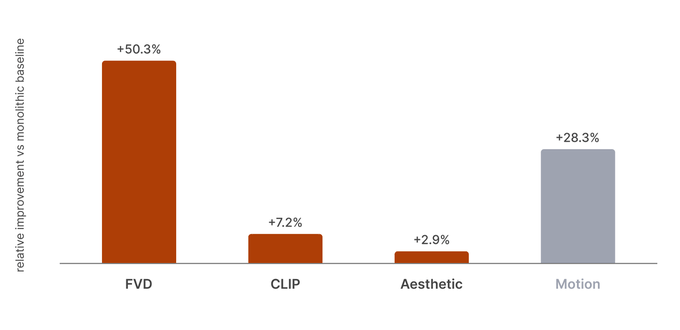
Against the monolithic model under matched data and compute, the results were:
FVD: 561.04 → 279.01 (a ~2x improvement)
CLIP text-video alignment and aesthetic score both improved.
To our knowledge, this is the first distributed training architecture to surpass its monolithic counterpart under matched data and compute.
Technical Report: arxiv.org/abs/2605.26064
Model Weights: huggingface.co/bageldotcom/p…

We're releasing Paris 2.0, which, to our knowledge, is the world's first decentralized trained video generation model.
We benchmarked it against a monolithic model trained on the same data and compute budget, and Paris 2.0 outperformed the monolithic by ~2x on FVD benchmark.
4
6
30
5,503

We're releasing Paris 2.0, which, to our knowledge, is the world's first decentralized trained video generation model.
We benchmarked it against a monolithic model trained on the same data and compute budget, and Paris 2.0 outperformed the monolithic by ~2x on FVD benchmark.
88
114
667
449,495



Mar 15
In town for NVIDIA GTC?
If you're building generative world models or investing in the people who are - we're putting the right people in one room for you tomorrow night in Palo Alto.
Co-hosted by Alumni Ventures. Signup link below.
5
6
16
11,067
Mar 15
1
5
1,206
bagel.com retweeted

Mar 11
we managed to extend DDM to heterogeneous objectives! one step closer to decentralized AI XD
tldr: experts trained in complete isolation, with different objectives, no communication - and mixing them beats making them all train the same way. 20-48G memory per expert
Excited to share that Bagel Labs' paper got accepted at CVPR 2026.
A lot of the most important diffusion model research has historically stayed inside frontier labs. We're bringing more of that in the open through open science and open infrastructure.
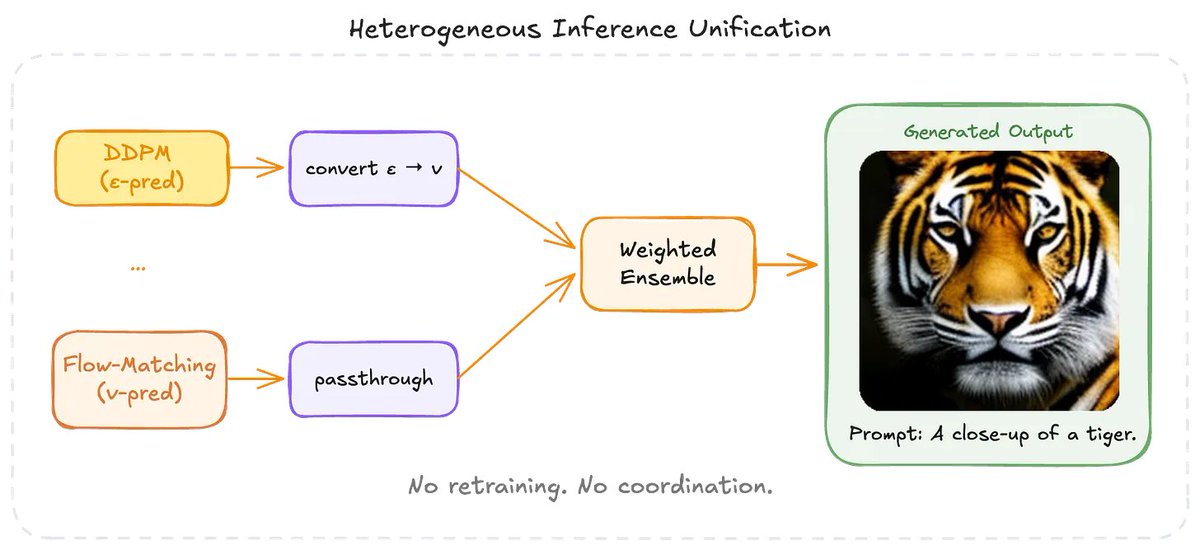
In this work we showcase the very counterintuitive advantage of mixing different training objectives (DDPM and Flow-Matching) through an ensemble of diffusion models. This is one of the first ever works to successfully combine diffusion models trained with heterogeneous objectives.
See details here: blog.bagel.com/p/heterogeneo…
3
10
2,545
Excited to share that Bagel Labs' paper got accepted at CVPR 2026.
A lot of the most important diffusion model research has historically stayed inside frontier labs. We're bringing more of that in the open through open science and open infrastructure.
In this work we showcase the very counterintuitive advantage of mixing different training objectives (DDPM and Flow-Matching) through an ensemble of diffusion models. This is one of the first ever works to successfully combine diffusion models trained with heterogeneous objectives.
See details here: blog.bagel.com/p/heterogeneo…
4
7
21
4,936
Mar 8
Diffusion models are becoming the foundation for image, video, and world models.
We are hosting a founders and investors gathering on that topic during NVIDIA GTC week, co-hosted by our friends at Alumni Ventures.
Mar 16, Menlo Park. Sign up below.
luma.com/nvidia-gtc-generati…
3
8
17
5,764
Being at the frontier - by the definition of it - means creating the frontier. You don't get to be at the frontier by following someone else.
And creating the frontier often means discoveries that go against the established knowledge.
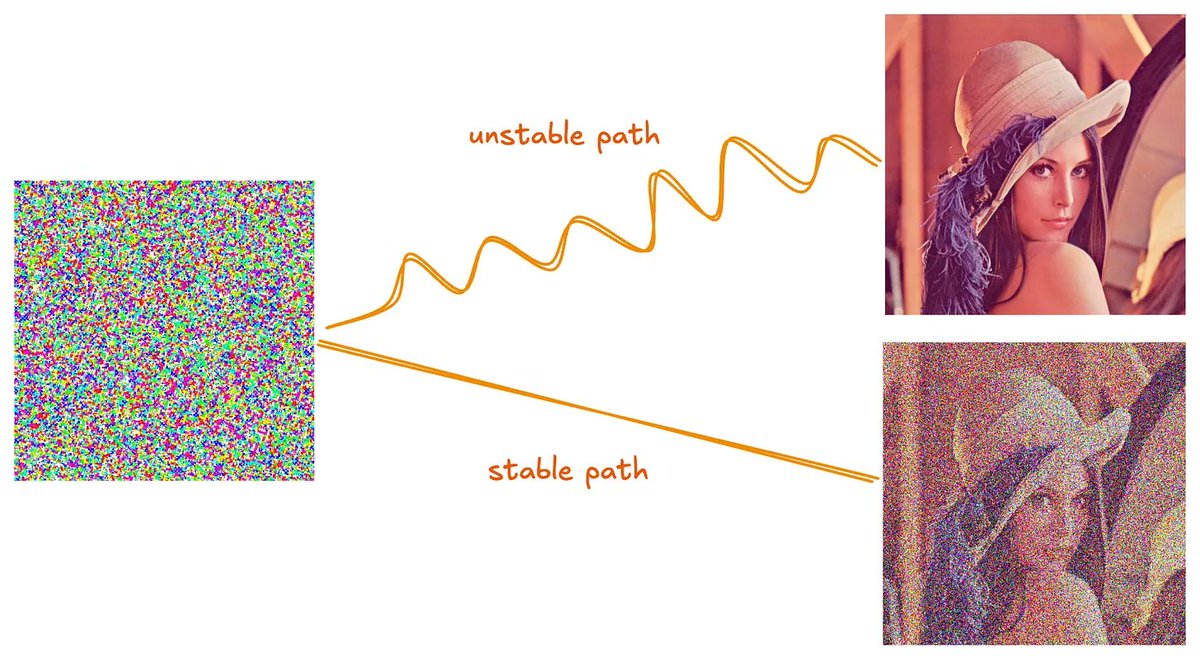
We recently made such a discovery about distributed diffusion model training. A common way to optimize diffusion model training is by ensuring the numerical stability of their generation paths. We found that that's not true for the most efficient distributed diffusion model training architecture.
We shared what works instead in our blogpost below.
blog.bagel.com/p/stability-q…
14
33
455
52,280
bagel.com retweeted

Jan 22
Can't wait for the live stream! in honor of it we just added a new question and interactive playground based on the paper
Jan 21

alright folks tomorrow january 22 from 10h-12h AM EST we're going to dive into decentralized diffusion models by reviewing the paris model from bagel labs
I even managed to lock in @bidhan for an interview on why how what that's a good thing to even do
tune in!

3
7
35
7,176
bagel.com retweeted

Jan 21
alright folks tomorrow january 22 from 10h-12h AM EST we're going to dive into decentralized diffusion models by reviewing the paris model from bagel labs
I even managed to lock in @bidhan for an interview on why how what that's a good thing to even do
tune in!
Jan 10
this weekend I'll be diving deep into decentralized training for diffusion models with the paris model and the bagel team (what a sentence)

3
8
90
26,722



NeurIPS takeways (better late than never)
1. real AGI needs real continual learning - models that can keep learning without catastrophic forgetting.
2. model architectures need to be "stateful" for building accurate world models for games and robotics.
3. diffusion models are superior for solving both 1 & 2.
4. @bageldotcom's distributed diffusion training architecture is SOTA among both open and closed source frontier lab comparables.
5. the age of research is back, and no better place to do frontier diffusion model research than Bagel Labs. join us - jobs.bagel.com




7
8
54
7,383
bagel.com retweeted

3 Dec 2025
Congrats on Paris to @bageldotcom and @bidhan!
Open and Decentralized diffusion model shared at @NeurIPSConf

14
3
27
3,668

bagel.com retweeted

22 Nov 2025
Noticing this release now (h/t @yacinelearning)
This decentralizing training approach is so cool!
I will note I shared this alpha back when Luma released its paper in Jan
If you're not following me you're going to be missing alpha 😄

7 Oct 2025

Introducing Paris - world's first decentralized trained open-weight diffusion model.
We named it Paris after the city that has always been a refuge for those creating without permission.
Paris is open for research and commercial use.
3
10
64
11,916
bagel.com retweeted
21 Nov 2025
btw folks I am about to dive headfirst into the wondrous world of open-weight diffusion this weekend wish me luck
7 Oct 2025
Paris does something that shouldn't work.
It's a combination of smaller expert diffusion models pre-trained from scratch, across different continents in complete isolation. Absolutely zero synchronization among each other during training.
This zero communication protocol achieves comparable quality to SOTA distributed approaches using 14× less data and 16× less compute.
How? See our full technical report and model weights below.
Full Technical Report: github.com/bageldotcom/paris…
Model Weights: huggingface.co/bageldotcom/p…
11
7
125
10,089


9 Oct 2025
Paris - made with ❤️ by bagel labs
7 Oct 2025
Introducing Paris - world's first decentralized trained open-weight diffusion model.
We named it Paris after the city that has always been a refuge for those creating without permission.
Paris is open for research and commercial use.
9
6
55
8,580