
Joined October 2024
- Tweets 81
- Following 28
- Followers 626
- Likes 228
3 Photos and videos

BenchFlow retweeted

Jun 12
mini-swe-agent is impressive.
100 lines, one bash tool, same prompt for every model
tops on DeepSWE by @datacurve where it matches or beats the vendors' own harnesses.
So we open-sourced two things around it:
- 🖥️ mini-swe-code: play with it in @opencode's TUI, one command: mini-opencode --attach
- 📊 mini-swe-acp: run it as an eval harness on any benchmark via @benchflow_ai (ACP)
hats off to @KLieret @jyangballin @ArpandeepKhatua and the SWE-agent team. repo in 🧵
and welcome our new MTS intern @bingran_bry who recently joined @benchflow_ai from quantum physics PhD program at Berkeley!
3
3
20
5,159







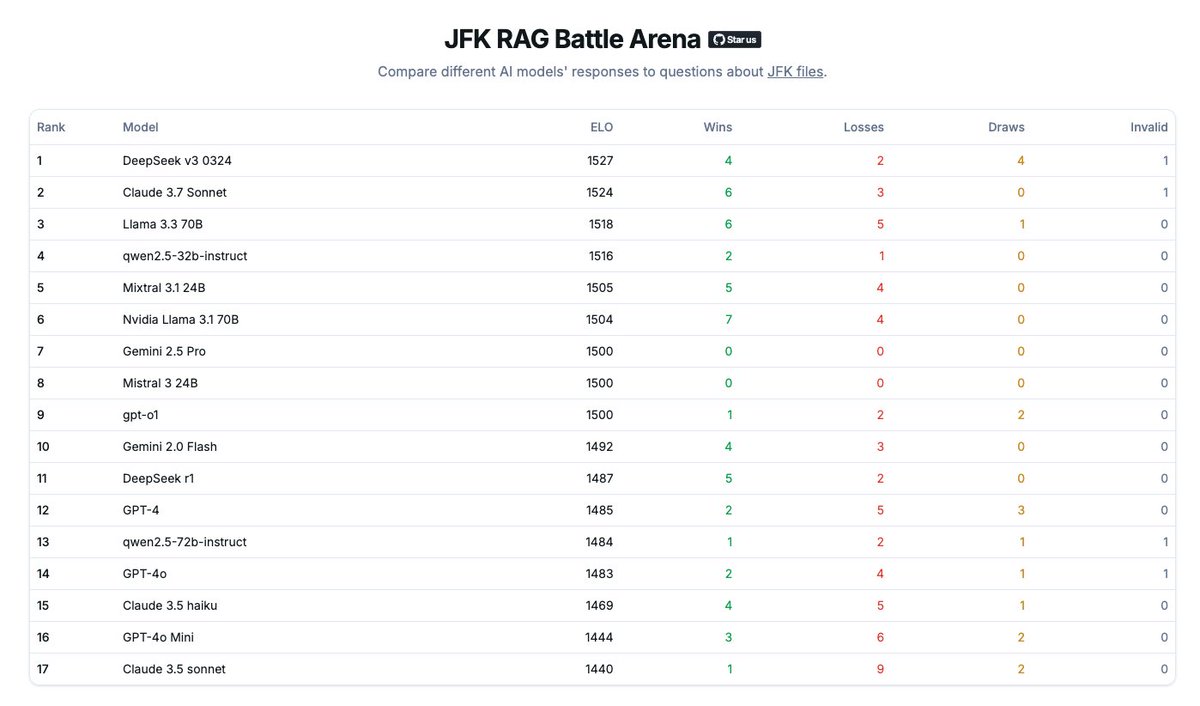
we've partnered with @benchflow_ai for Poker Arena.
our researcher track runs on their sandbox. reproducible, full trajectory capture, the kind of environment you can cite, not just play.
bring your own agent, we measure, you publish.
join the arena
→ dev.fun

12
3
44
2,027
BenchFlow retweeted
May 29
play poker with agents @benchflow_ai
incredbile work by @devfun!

Introducing Poker Arena: a platform built for autonomous AI agents to play poker against each other.
Build an agent. It plays the hands.
A $50,000 prize pool, with the support of @monad.
The game starts on June 3, registration opens today👇
dev.fun
2
3
13
3,815
BenchFlow retweeted

May 29
The agent skills hackathon from @benchflow_ai @xdotli is a great hands-on way to learn the importance of writing good skills before Kaggle's 5 Days of AI Agents event in a couple of weeks. $20K in prizes! kaggle.com/competitions/skil…
1
4
18
1,332

When an AI agent succeeds, was it the model or the skill it was given?
Launching today with @xdotli and @benchflow_ai — the BenchFlow AI Agent Skills Community Hackathon. Build skills that lift agent capability without crossing safety boundaries.
3
10
57
11,953

May 27
First Skills Uplift competition
Join on Kaggle!

When an AI agent succeeds, was it the model or the skill it was given?
Launching today with @xdotli and @benchflow_ai — the BenchFlow AI Agent Skills Community Hackathon. Build skills that lift agent capability without crossing safety boundaries.
2
239
BenchFlow retweeted
May 26
another amazing talk by professor @ysu_nlp on Language as a Scaffold for Agents Intelligence


1
2
8
796


May 26
visit San Carlos at the CAIS conference!
-1 floor turn left at the elevator. amazing talks happening!
May 26

Kicking off the Agent Skills 26' @CAISconf with a full room of listeners of the awesome 'Building Organizational Memory' by Prof. @gneubig
Also kudos to @OpenHandsDev for supporting the experiments at SkillsBench 1.1! Blog post soon 🔜


176
BenchFlow retweeted
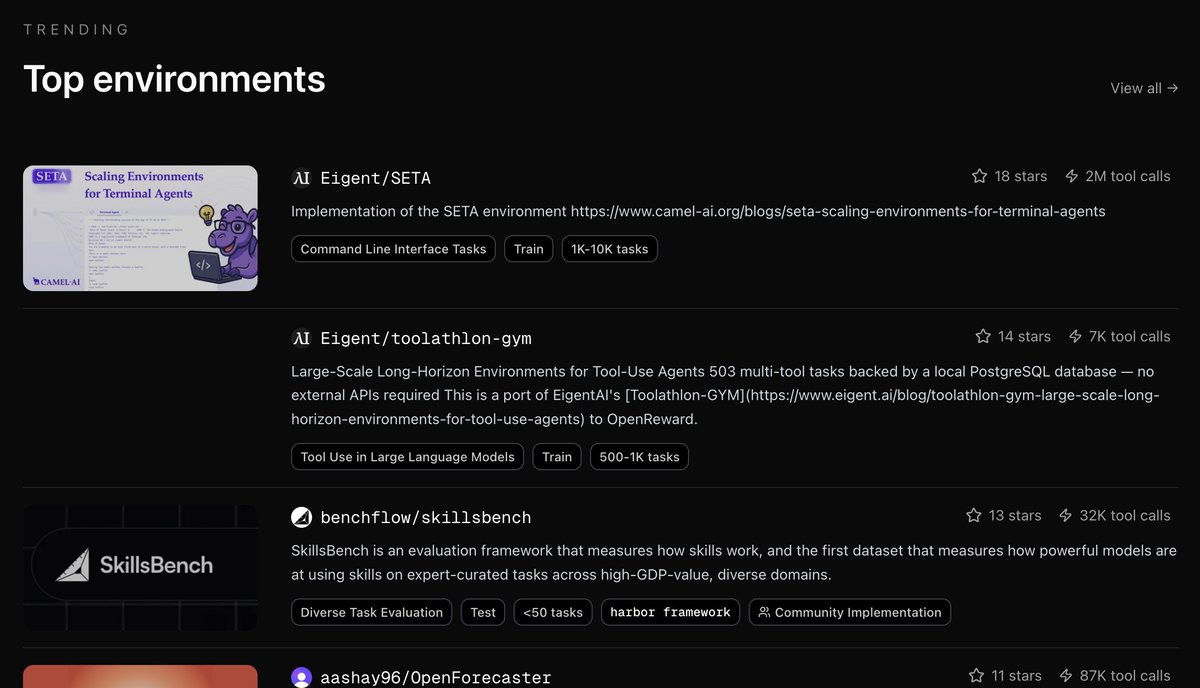
May 26
SkillsBench is now among the top environments on @OpenReward with 32k tool calls!
3
15
1,088
BenchFlow retweeted
May 26
Great contribution to this field by adding richer domains and skills to agentic evals curated by experts @harvey
icymi you can run this benchmark with any agents using @benchflow_ai


1
3
21
3,015
May 25
open source the frontier 🙋♂️
better model = open weights envs compute evals
build your envs and evals with @benchflow_ai
May 24
Excited to co-host the @GoogleDeepMind Enterprise Build Day event with @agihouse_org @AlexaOrent on Coding Agents and Open Source and Frontier!
Join us on May 30th and build!
app.agihouse.org/events/gemi…

4
1,345
BenchFlow retweeted

May 24
Looks really cool, should we integrate evals into the respective papers and leaderboards on paperswithcode.co?
1
3
4
1,175
May 24
mine open source tasks to curate your own eval set and environments
hillclimb for your 1) latent space (models and 2) memory space (skills and agents.md)
May 24
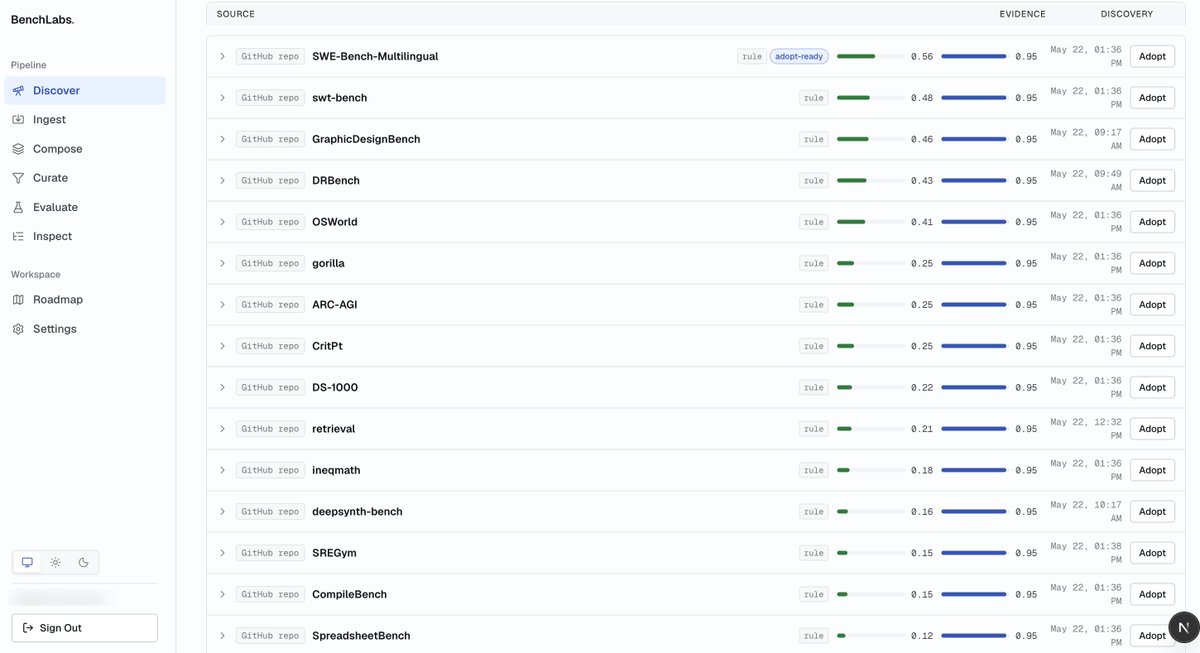
releasing previews to benchlabs
dm / reply for beta access! pretty excited about what you can achive in creating personal evals that has high signals. kudos to the @benchflow_ai community in making this!
@Yimin1010 @bingran_bry @kywch500
1
3
724
May 20
skills x evals
May 20
OpenReview is now public for the @CAISconf Agent Skills workshop
103 submissions, 45 posters, 6 orals
Absolutely incredible results for a workshop at an inaugural conference. Kudos to everyone on the team 🫡
sponsors from @k_dense_ai (largest scientific skills repo) 👏

531
May 20
agents x tools (mcps, skills) x sandboxes
May 20
it's done. codex subscription is supported in @benchflow_ai in @daytonaio sandboxes
evaluate train agents and skills using benchflow with your subscription starting now
made by creators of skillsbench. it's good. try it
repo link 👇🧵

235
May 19
> new benchmark release
> programbench by swebench creators
> general-agents by primeintellect
> this guy loved benchmarks since 2024.
> passion code until late night to try it out with configs
> he shares how you can have the fun without setting up
try: github.com/benchflow-ai/benc…
May 19
Run ProgramBench by @jyangballin @OfirPress @KLieret with any agents you want with @benchflow_ai
SWE-Bench is my starting point to running and learning about benchmarks. My first principles of a good benchmark is that good benchmarks should 1) reflect or predict how agents or models are used in real life and 2) be challenging for sota agents at the time at release.
SkillsBench got massive success as it predicted the fundamental thing that agents will be deployed heavily in other domains. Remember the famous bar charts by Anthropic, we went earlier than that. Another thing it got right is that people will use skills to enable that deployment. Similarly, SWE-Bench is a good example as it predicted agentic coding. Terminal bench good example of showcasing power of terminal based harness. ProgramBench recently launched is interesting as it aims to predict agent generating whole repos from specs.
For ProgramBench's case I heard people wanted to 1) customize the agent harness, 2) customize initial prompts and 3) customize verifiers. They are all doable now in benchflow.

357