web craftsman
Joined February 2007
- Tweets 40,498
- Following 837
- Followers 2,191
- Likes 1,944
2,450 Photos and videos









Pinned Tweet
Jan 24
My GitHub Sponsors profile is live! You can sponsor me to support my open source work github.com/sponsors/benoitc?…
1
1
5
1,472
erlang-rocksdb 3.0.0 released. Now on RocksDB 11.1.1, with abort/resume compactions and new FIFO/table/DB options. Deprecated API cleaned up for the new major. github.com/EnkiMultimedia/er…
#erlang #elixir
1
1
10
341
AI may help you to get faster at writing/generating. But at the end what count is what you're able to maintain .
1
55
Jun 13
One of the reason AI shouldn't rely only on services and some expensive hardware. We need true open AI able to work on cheap and diverse hardware. Today it's US market protection but can be any other country.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
2
170
Jun 12
Livery v0.3.0 is out: one handler set over HTTP/1.1, HTTP/2 and HTTP/3 on the BEAM.
Since 0.2.0: deferred responses (pick the status at the first byte), per-SNI certs on H3, a composable HTTP client (balancing, retries, push streaming), router nesting, and faster H1/H2 writes. github.com/benoitc/livery
18
792
Jun 12
hackney 4.3.0 is out: HTTPS connection pooling, TLS 1.3 session resumption, smarter SNI, and QUIC/WebTransport bumps for the Erlang HTTP client.
github.com/benoitc/hackney/r…
4
18
434
Jun 12
how some tezms are transforming agile cycles in strict cycles that can't be moved and stop them artificially to react to prod issues.
90

benoît chesneau retweeted

Jun 9
One of my personal favorite features announced at WWDC will I suspect be a sleeper hit: container machines, allowing your Mac to run a lightweight, persistent Linux environment with your home directory and repos automatically mounted: github.com/apple/container/b…
228
815
9,696
727,892
benoît chesneau retweeted

Jun 9
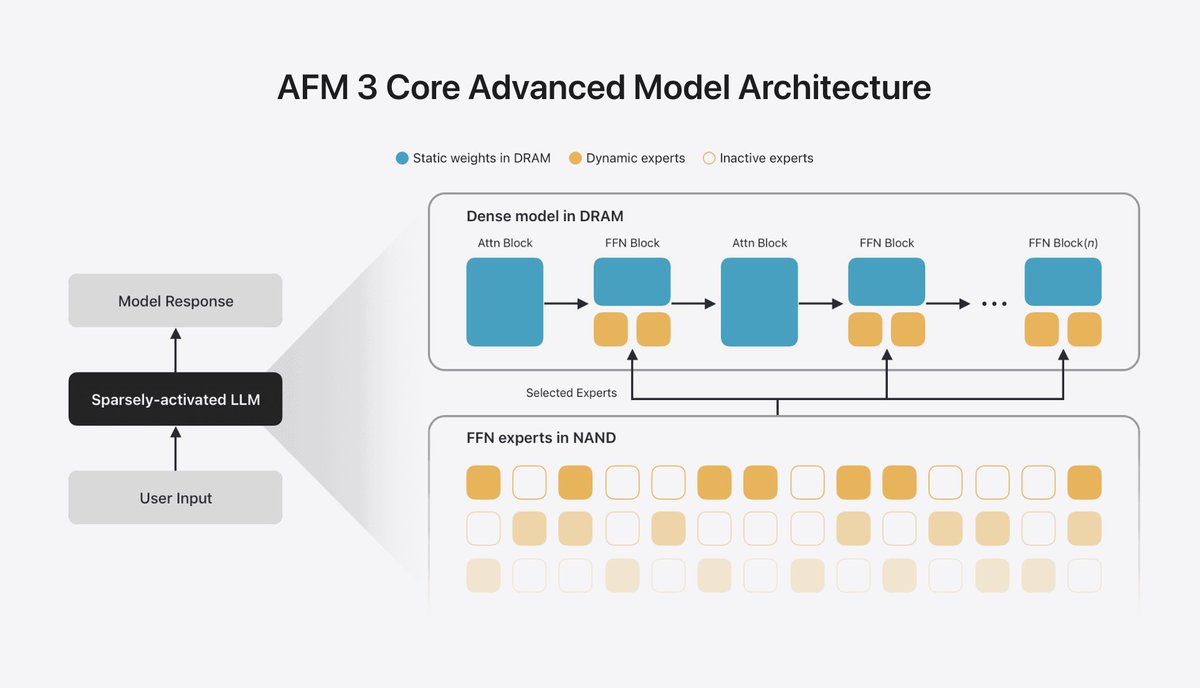
It's very cool that Apple shipped a 20B parameter on-device.
You can't put 20B parameters in RAM at any reasonable precision. To make it work they are using pretty exotic architecture by today's standards.
A small model predicts from the query (or prompt) which experts to load from Nand into RAM. The key distinction from a typical MoE is that you do this once per query and then generate all the tokens with the same experts (instead of switching the experts for every token).
77
297
3,197
225,231
Jun 7
hackney 4.2.2 is out: a patch that fixes a pool crash where a connection dying mid-checkout could take the whole pool down with noproc.
github.com/benoitc/hackney/r…
#erlang
3
166
Jun 6
Livery v0.2.4 is out: HTTP/2 large responses now ~2.4x faster (one coalesced socket write instead of one per frame), plus a mid-response disconnect fix and a runtime concurrency cap. BEAM web framework, one handler set over HTTP/1.1, HTTP/2, and HTTP/3 →
github.com/benoitc/livery
1
1
30
1,198
Jun 6
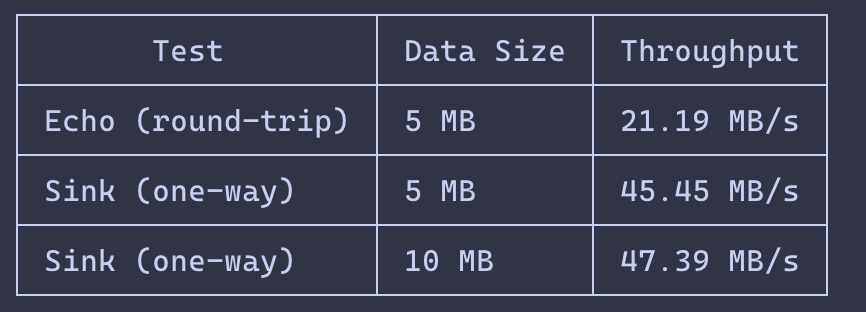
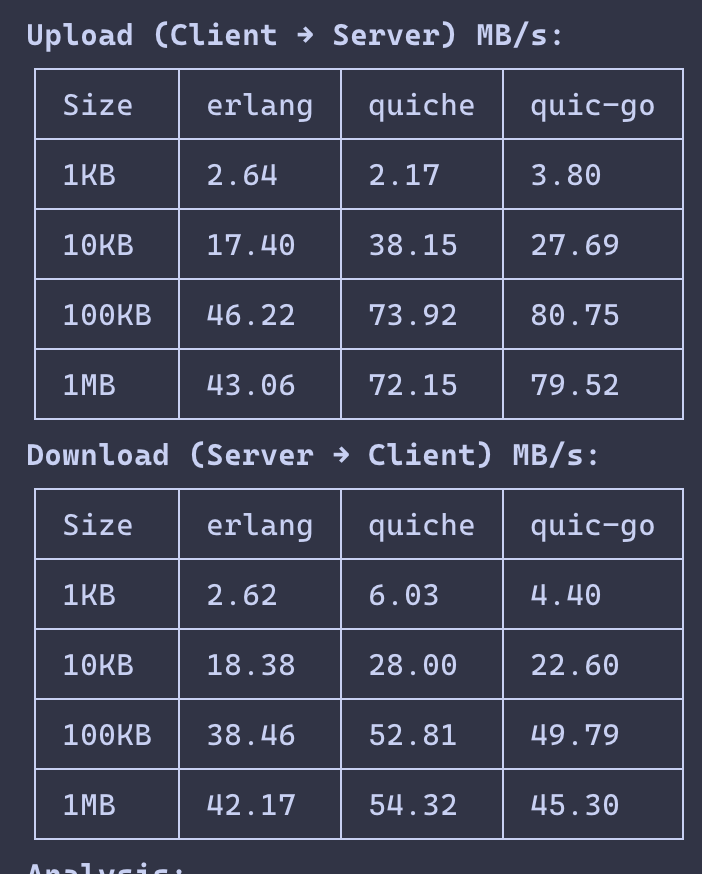
Livery, a BEAM web framework, was ~2x behind on large HTTP/2 responses.
The first suspect was flow control, but increasing the window changed nothing. eprof showed the real issue: one ssl:send per frame, causing ~8 TLS writes per 100KB response.
Coalescing frames into one write: 28k → 66k req/s. 2.4x.
Measure first.
1
1
31
1,231
Jun 5
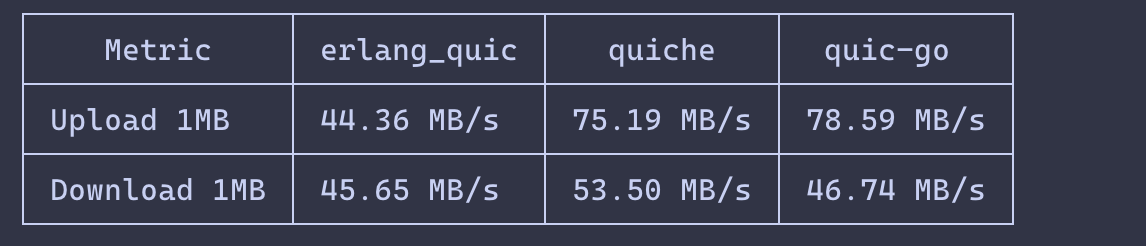
hackney 4.2.1 is out. A dependency refresh: quic 1.6.4, webtransport 0.3.2, and certifi 2.17.0. Drop-in upgrade from 4.2, no API changes.
hex.pm/packages/hackney
#erlang #elixir
13
517
Jun 5
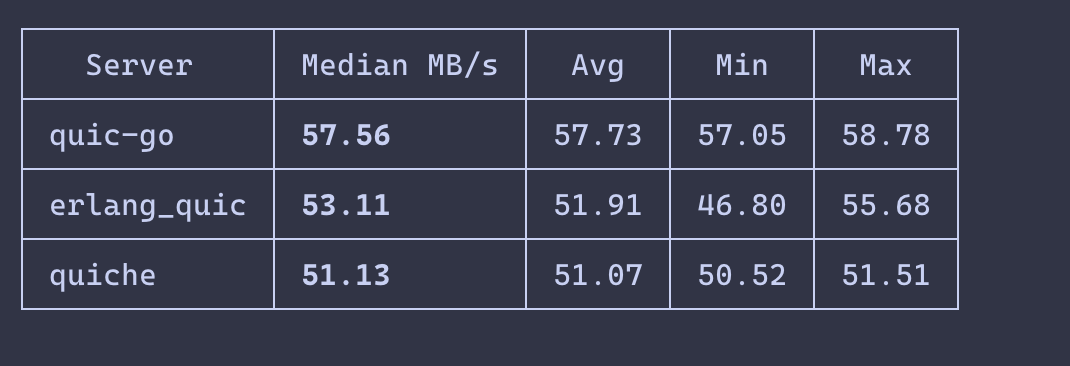
Erlang QUIC (Pure Erlang QUIC implementation (RFC 9000/9001).) version 1.6.4 released.
Small performance when tracking body size in HTTP3.
github.com/benoitc/erlang_qu…
#erlang #elixir
1
17
685
Jun 5
Erlang webtransport (An Erlang implementation of the WebTransport protocol) 0.3.2 including this update has been released has well. Enjoy!
github.com/benoitc/erlang-we…
#erlang #elixir
1
177
Jun 5
erlang-certifi 2.17.0 released .
Updated CA bundle to Mozilla's May 2026 set (119 roots). Removed distrusted Entrust roots.
github.com/certifi/erlang-ce…
#erlang #elixir
13
652
Jun 4
Livery 0.2.0 is out: an Erlang web framework serving one handler over HTTP/1, HTTP/2 and HTTP/3 from a single runtime, on a pure-Erlang QUIC stack. inspired by Axum and Tower.
github.com/benoitc/livery
2
1
37
1,495
Jun 3
hackney 4.2.0 is out. HTTP/3 gains IPv6 and 0-RTT, TLS now recovers from expired cross-signed roots (the Let's Encrypt ISRG X1 case) on every protocol, plus two regression fixes.
Drop-in upgrade from 4.1, no API changes.
hex.pm/packages/hackney
#erlang #elixir
1
1
19
796
May 31
why do we have diffetent tools syntax per models... would be cool to have a standard or generic protocol forbit like responses fot chat ... this maake things complicated to support multiple languages
1
3
250