
Shawn Carbonell MD PhD 🇵🇭 | scientist | builder | creative | stealth AI startup 🔬
Joined April 2009
- Tweets 2,692
- Following 2,035
- Followers 1,970
- Likes 7,775
324 Photos and videos
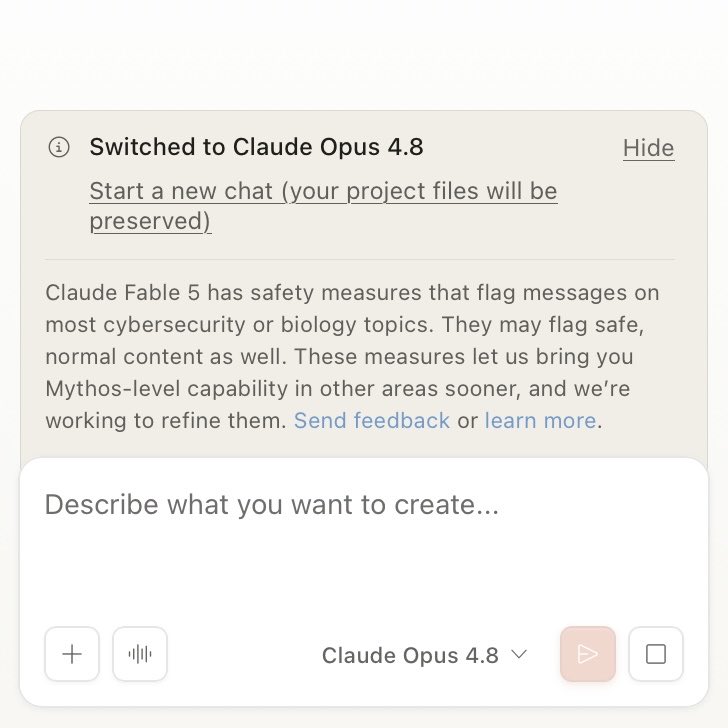










claude fable is an honest name bc its biology capabilities are fictional 🥹
2
1
311
[written with claude fable 5 bc it’s otherwise useless to me ]
1
71
I had lots of sex with my cofounder. 🔥

2
148
I was on like slide THREE and she started scrolling 😭
Major biotech VC. She was an associate, the partner didn’t bother showing up lol.
Jun 6

If a VC is on their phone, looking bored while you're pitching
Cut the meeting short.
I wish I had done that every time. It never led anywhere, and you have better things to do.
107
$25M just to PREPARE an IND??!?!
That’s nuts. We FINISHED Phase I for less.
Fun episode tho, enjoyed the format.
Jun 3

NEW podcast episode is up!
"Tim’s Founder Kitchen — From Brainstorm to The President’s Office in Two Months (Featuring Jake Becraft, Strand Therapeutics)"
This episode is an experiment!
I'm trying out a new format: half interview, half live jam session. I've started a new series, working title "Tim's Founder Kitchen," built around actual brainstorming sessions with founders willing to share the audio.
This first instalment is with Jake Becraft of Strand Therapeutics. @DrSynbio is the CEO and co-founder of @StrandTx, a clinical-stage biotechnology company with a pipeline of breakthrough mRNA therapeutics for cancers and autoimmune diseases.
Let me know by replying here what you think of this experiment and how I can make the series better.
Please enjoy!

55
Brain Surgery Dropout retweeted

May 21
OpenAI is offering $2M in tokens to every YC company in the spring and summer batches.
We extended the summer deadline to May 25 so more founders can get in on it.
ycombinator.com/apply
107
96
1,060
774,634
When I first met @ET_adialante I knew I wanted to invest… 🤑
….but fresh out of dry powder. 😔
Now two years later… they just launched out of YC!!! Congrats to Efrain and team!!! 🚀
MRI will never be the same… and goddam that’s a good thing. 🙌🏽🧠
May 13

Cancer kills because it's caught late. Adialante is changing that by making mobile MRI accessible — dropping its costs to hundreds per scan and wait times to hours. Annual cancer screening will be the norm.
Congrats on the launch, @ET_adialante &
@ManW_dePlan!
ycombinator.com/launches/QLh…
1
2
180
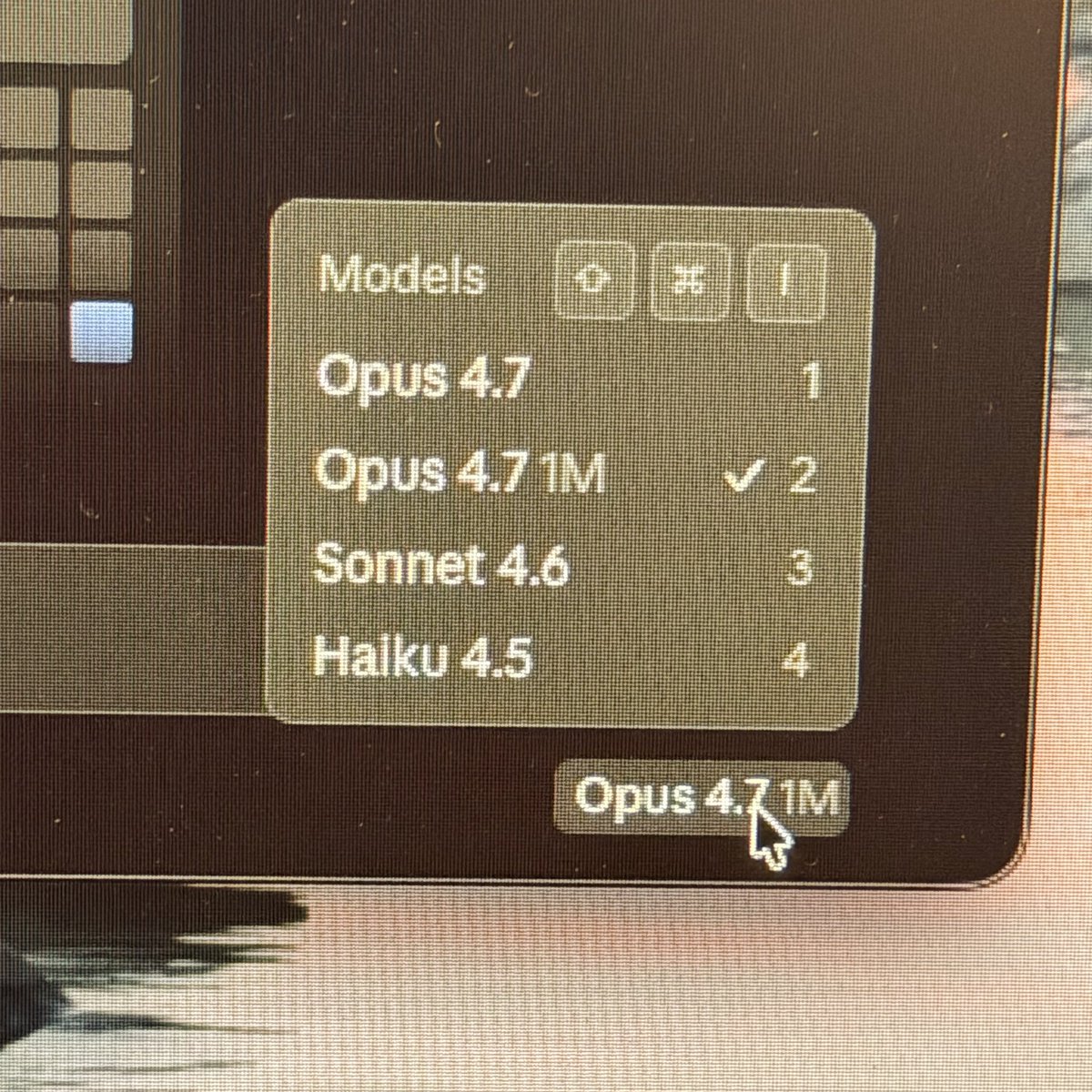
3 screens running Claude Chat, Cowork, and Code, respectively, with 4.7 😵😵😵
1
52
Brain Surgery Dropout retweeted

Apr 4
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
1,121
2,825
26,780
7,148,790

OpenClaw 2026.4.7 🦞
🔮 openclaw infer
🎬 music video editing
💾 session branch/restore
🔗 webhook-driven TaskFlows
🤖 Arcee, Gemma 4, Ollama vision
🧠 memory-wiki: persistent knowledge, not just vibes
Because “trust me bro” is not a knowledge system. github.com/openclaw/openclaw…
227
315
3,195
674,390
selective pressure 🦠🐟🐍🪿🦛🦣🦍

Anthropic shutting down OpenClaw may turn out to be a strategic blunder, or strategic genius. The OpenClaw community will be the determiner of whether it is A or B. It's an interesting moment in history.
Personally I never bet against open source.
1
67
Brain Surgery Dropout retweeted

Mar 31
We just rebuilt every startup in @ycombinator's latest demo day batch.
Here's what our agentic "founders" pulled off and what it means for the future of startups.
Fully useable products at the bottom of the thread below 🤖🧨
177
128
1,048
544,849
This is the only AI hardware I want. 🤖


90

Claude Mythos Blog Post
Saved before it was taken down.
m1astra-mythos.pages.dev/
134
273
2,595
3,603,132
“The ones who win now are the ones closest to the problem... not the ones who know the syntax.” @amasad
🤖
2
68