
Decentralised computing platform to help ML teams get 10x more affordable computing
Joined January 2020
- Tweets 92
- Following 8
- Followers 209
- Likes 91
18 Photos and videos













Here's our demonstration of 90% savings for Transcription and Translation using Whisper.
Optimised Whisper API, running on decentralised GPU network
With further optimisation, we are looking at 95% savings.
At moderate scale this means:
$50,000 vs $1M
qblocks.cloud/blog/ultra-low…
1
2
687
Wow. This world is moving at lightspeed and love how @monsterapis always comes on top of the latest innovation. Their GPT is insane.
19 Apr 2024

We have successfully fine tuned LLaMA 3 using the @monsterapis GPT instruct tune method.
Overnight we have built 17 unique models and are testing now.
Early results?
Very robust and quite extraordinary.
No other 8B model can get close to these outputs.
I am floored.

1
158
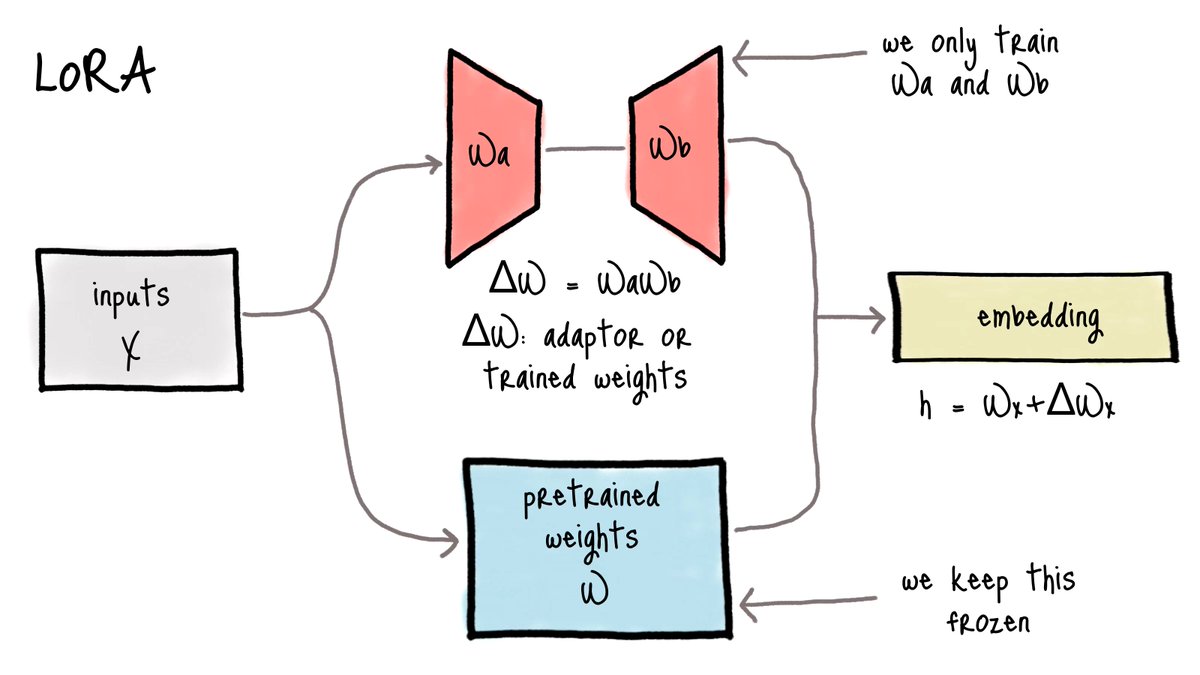
LORA powered Fine tuning is revolutionary

LoRA is a genius idea.
To understand the fine-tuning of Large Language Models, you must understand how LoRA works.
By the end of this post, you'll know everything important about how it works.
Large Language Models are good generalists, but they have little specialization. We train them in many different tasks, so they know a bit about everything but not enough about anything.
Think of a kid who can play three different sports at a high level. While he can be proficient across the board, he won't get a scholarship unless he specializes. That's how the kid can reach his full potential.
We can do the same with these large models. We can train them to solve a particular task and nothing else.
We call this process "fine-tuning." We start with everything the model knows and adjust its knowledge to help it improve on the task we care about.
Fine-tuning is revolutionary, but it's not free.
Fine-tuning a large model takes time, care, and lots of money. Many companies can't afford the process. Some can't pay for the hardware. Some can't hire people who know how to do it. Most companies can't do either.
That's where LoRA comes in.
We realized we could approximate a large matrix of parameters using the product of two smaller matrices. There was a lot of wasted space within these large models. What would happen if we find a new, more optimal representation?
Did you ever buy a map at a gas station? Giant pages showing every small road, path, and lake around you. They were exhaustive but hard to navigate. These are like parameters in a large model.
LoRA turns a gas station map into a cartoon treasure map. Every useless parameter is gone. Only two roads, a palm tree, and a cross pointing at the treasure. We don't need to fine-tune the entire model anymore. We can only focus on the small treasure map that LoRA gives us.
It's a mind-blowing trick.
We can train the small approximation matrices from LoRA instead of fine-tuning the entire model. LoRA is cheaper, faster, and uses less memory and storage space.
You can also merge the approximation matrices with the model during deployment time. They work like simple adapters. You load up the one you need to solve a problem and use a different one for the next task.
Then, we have QLoRA, which makes the process much more efficient by adding 4-bit quantization. QLoRA deserves its own separate post.
The team at @monsterapis has created an efficient no-code LoRA/QLoRA-powered LLM fine-tuner.
What they do is pretty smart:
They automatically configure your GPU environment and fine-tuning pipeline for your specific model. For example, if you want to fine-tune Mixtral 8x7B on a smaller GPU, they will automatically use QLoRA to keep your costs down and prevent memory issues.
The @monsterapis platform specializes in no-code LoRA-powered fine-tuning. It's the fastest and most affordable offering for fine-tuning models in the market. They sponsored me and gave me 10,000 free credits for anyone who uses the code "SANTIAGO" in their dashboard:
monsterapi.ai/finetuning
If you want to read their latest updates, get free credits and special offers, join their Discord server: discord.com/invite/mVXfag4kZ…
TL;DR:
• Traditional fine-tuning trains the entire model. It requires a complex setup, higher memory, and expensive hardware.
• LoRA: Trains a small portion of the model. It's faster, requires much less memory, and affordable hardware.
• QLoRA: Much more efficient than LoRA, but it requires a more complex setup.
• No-code fine-tuning with LoRA/QLoRA: The best of both worlds. Low cost and easy setup.
1
153
Q Blocks retweeted

27 Jan 2024
Here's a new LLM deployment solution that enables serving multiple LLMs & Lora adapters as an API endpoint powered by our robust GPU Cloud.
Ready for a test drive?
Let's deploy the Mixtral 8x7b Chat model with GPTQ 4bit quantization on a 48GB GPU. 🚀🧵

24
9
97
12,041



Now, you can fine tune Llama 2 on our massive network of GPUs without writing a single line of code
How to fine-tune Llama 2 without writing a single line of code.
I taught Llama 2 to classify the sentiment of movie reviews. Setting everything up took me 10 minutes. The fine-tuning process lasted 6 hours.
If you aren't familiar with the term "fine-tuning," it’s the process we use to teach a model how to solve a specific task. Large Language Models have general knowledge but struggle to solve particular problems.
Fortunately, we can fine-tune these models and make them very good at solving specific tasks. In this example, that task is determining how much a person liked a movie based on its review.
Unfortunately, fine-tuning a model is a complex, expensive process. It takes a lot of time, effort, and GPU computing. It's also hard to find experienced people who know how to do it.
The team @monsterapis built the first platform that offers no-code fine-tuning of open-source models, which changes everything.
That’s the platform I’m using here.
Here is what you need to do:
1. Sign up here: monsterapi.ai/signup, and use the code SANTIAGO during sign-up to get 5,000 free API credits.
2. Go to the FineTuning option and select Llama 2 7B.
3. Select your task. I'm using "Text Classification" since we want to classify movie reviews.
4. The last step is to select your dataset. I used the IMDb dataset from HuggingFace.
It took a bit under 6 hours to finalize the fine-tuning process. The attached image corresponds to the training loss over the first few steps. I spent 14,000 credits in the process, equivalent to $14.00.
That’s one of the @monsterapis’ advantages: Besides not dealing with code, complexity, or hardware, their pricing is very competitive, thanks to their decentralized GPU platform.
Here's an article that provides a step-by-step guide for fine-tuning Llama 2: blog.monsterapi.ai/how-to-fi…
You can also join @monsterapis’ Discord server for the latest updates, free credits, and special offers: discord.com/invite/mVXfag4kZ…
Thanks to the team @monsterapis for partnering with me on this post.
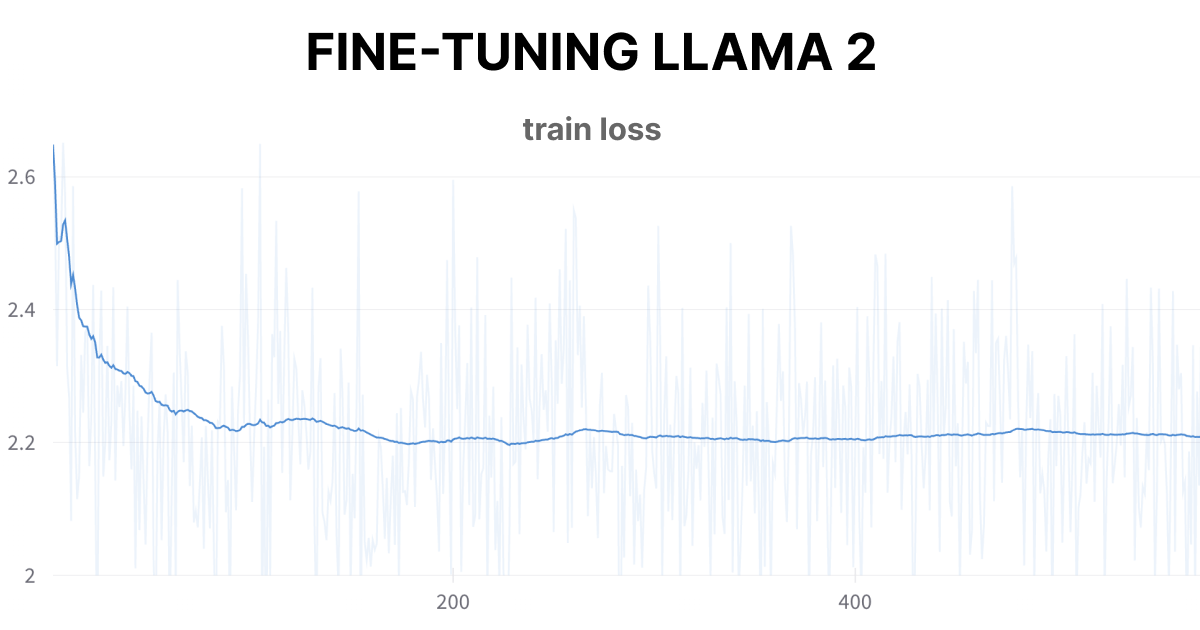
ALT Fine-tuning Llama 2 — train loss
2
173


🚨 FREE A100 GPU for AI🚨
Get a chance to access Free A100 GPU instance on Q Blocks GPU platform for 1 week.
Apply for your business here:
qblocks.cloud/access-nvidia-…
#a100 #nvidia #GPU #cloud #machinevision #LLM #GPT4 #Chatgpt #GPT4All #text2video
1
3
12
113,485
Q Blocks retweeted

10 Apr 2023
"Una sorpresa" = 10000 API credits para todas las personas participantes y una suscripción anual para el equipo ganador 🎉🎉🎉
Thank you so much @Gaurav_vij137 and @saurabhvij137 (@blocks_q) 🤩
10 Apr 2023

🔥 Únete hoy a esta charla sobre #GenerativeAI impartida por @Gaurav_vij137 y @saurabhvij137, fundadores de @blocks_q, empresa patrocinadora de las GPU VMs del #HackathonSomosNLP.
✨ Anunciarán una sorpresa ✨
➡️ ¡Únete! Haz clic en "Notificarme" youtube.com/watch?v=3jgh6ZbW…

5
15
1,492
Folks in Speech Recognition would love this:
90% savings
#whisper #MachineLearning
3
189
And the Hackathon kicks in
3 Apr 2023
Una forma inteligente de entrenar, ajustar y desplegar tus modelos de ML
⚙️ El fundador de @blocks_q, empresa patrocinadora de las GPU VMs del #HackathonSomosNLP, nos explicará cómo ofrecen máquinas a precios tan competitivos y cómo hacer uso de ellas.
➡️youtube.com/watch?v=n7uaOppo…

1
6
567
Now edit images with easy to use Instruct-pix2pix API
2
150
Q Blocks retweeted

8 Nov 2021
Don't let your #AI research ideas stop due to the cost of computing. We at @blocks_q are enabling upto 10x cost efficient computing access for ML researchers and teams using #decentralized computing approach.
More on: qblocks.cloud
#GPU #deeplearning #ML #tech
2
12
The future is here: Decentralized compute for Machine Learning, delivered through simple to use APIs

The future of computing is here & it’s exciting!
If you're a generative AI dev, try Monster API and take your projects to the next level.
monsterapi.ai/
If you sign up now, you get
- 5000 free credits (using GitHub)
- 2500 free credits (using another signup method)
102
If you are in Generative AI, you can't afford to miss this:
25 Jan 2023

We are live
414
Generative AI gave us a glimpse about the truth
We knew he could be a badass Villian someday.
#dalle2 #generativeart #ArtificialIntelligence #stablediffusion


1
"AI art of the day"
We asked a text to image model:
What if Spiderman was in the movie Avatar and this is what it came up with
#dalle2alternative #aiartcommunity #aiartist #generativeart #generativedesign
In the startup journey, we get so busy in the day to day treadmill that we forget to stop and celebrate small wins.
To our surprise, we just surpassed delivery of 500,000 computing hours on the Q Blocks network
We asked an AI to congratulate us on this win
#stablediffusion



1
1
Signup to get early access of the generative AI app:
qblocks.cloud/diffusion/
Hate to see this but all these giants have a tendency to trap the users with freebies and then one day force them to the extremely expensive service.
For all those users, we just want to say: We do things simple. Low cost (not zero cost) but guaranteed access at all times.
24 Sep 2022

We can help @blocks_q 😉
1