
Secure your content and power collaboration on one platform with Box. Questions about your account or need product support? Tweet @BoxSupport.
Joined May 2008
- Tweets 13,229
- Following 3,148
- Followers 78,442
- Likes 4,300
3,557 Photos and videos















The latest State of AI in the Enterprise report from Box is out!
One year ago, 8% of organizations described themselves as advanced or leading edge in AI. Today that figure is 64%. But adoption is not the same as impact. Half of leading edge companies report significant ROI. Among early stage organizations it is just 1 in 9.
We surveyed 1,640 IT decision makers across the US, UK, France, and Japan to find out.
1
2
14
678,683
Unfortunately, Claude Fable will no longer be available in the Box AI Studio. We hope this issue gets resolved and we can offer it again to customers soon.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
4
12
1,503
Most enterprise AI programs fail not because the models are weak. They fail because organizations invest in AI before they have the data, governance, content, and execution readiness to support it.
Our guide breaks down what a real enterprise AI strategy looks like, why most programs stall at the pilot stage, and the seven steps to build one that actually delivers at scale.
Read here.👇
blog.box.com/enterprise-ai-s…
2
3
438
Box retweeted

Jun 12
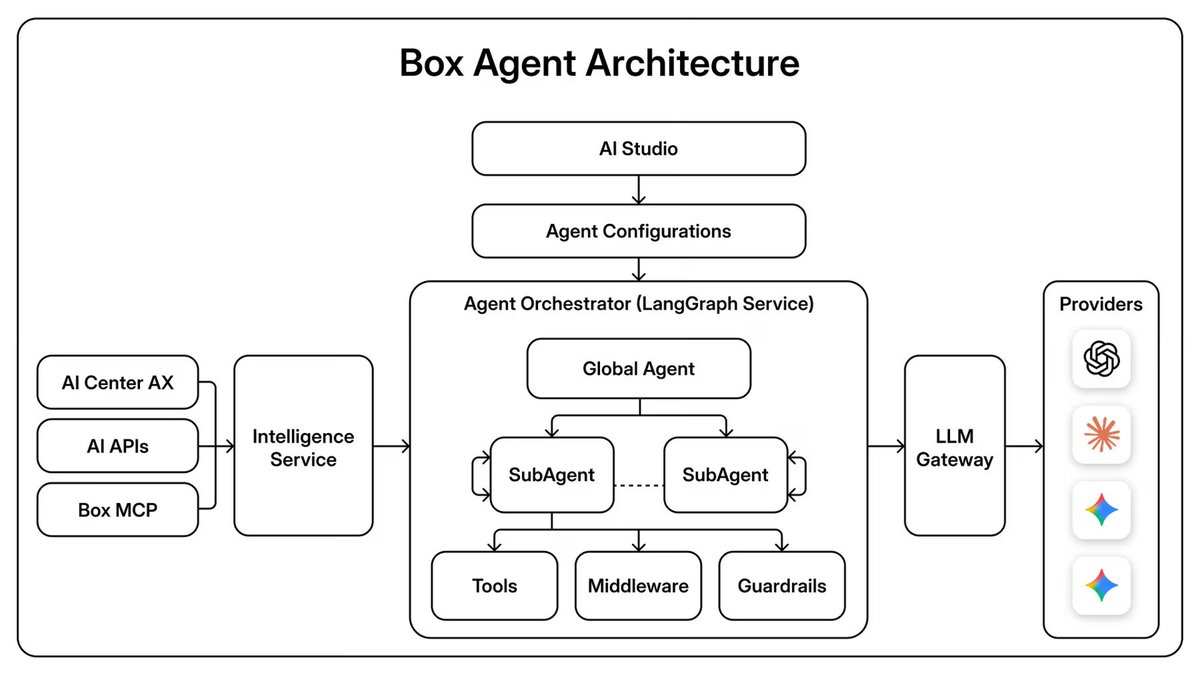
.@Box Agent is built on Deep Agents.
✅ Cross-library search
✅ Multi-doc synthesis
✅ Structured reports
✅ All within Box's existing security and permissions model
6
18
85
6,633
When Box transitioned Box AI into a multi-step agentic system, we chose @LangChain's LangGraph over building a custom execution engine from scratch.
Our full architectural breakdown covers how agents are defined and compiled at runtime, how the Global Agent spawns sub-agents dynamically, how LangGraph's checkpointing powers session resumability, and how Box enforces user-scoped security at the platform level, not the LLM level.
Read here.👇
blog.box.com/how-box-built-i…
5
15
3,045
Box retweeted

Jun 12
At Box, we just surveyed 1,640 IT leaders across the US, Japan, and Europe about agentic AI adoption. Many standout findings, but a big one was that the companies that adopted AI the most are planning to grow headcount the most.
Obviously lots of ways you can read that data and variables mixed in, but it’s actually quite intuitive that the companies that become most productive want to (and are able to) reinvest back into the business to keep getting the gains going.
The narrative of jobs being wiped out assumes that companies will take a fixed approach to what they want to be able for work on. What’s happening in practice is it’s causing companies to want to light up more engineering projects, sell to more customers, automate more processes to give time back, and more. That all leads to more work to be done by people.

Jun 11

JUST IN: Jeff Bezos predicts AI will create a labor shortage rather than put humans out of work.
46
48
233
41,517
CIOs are no longer asking whether to adopt AI. They are asking whether their content is ready for it.
96% of organizations say agents need access to company-specific content to work effectively. But only 36% have actually connected agents to trusted content across multiple use cases. That gap is where most content strategies break down in practice.
1
2
5
30,608
Start our State of AI in the Enterprise report here.👇
blog.box.com/SAI26-agentic-a…
1
1
1,928
.@claudeai Fable 5 is now in Box AI. We ran it head-to-head against Opus 4.8 on enterprise tasks:
→ Report Drafting: 87% vs. 81% ( 6.8 pp)
→ Data Analysis: 80% vs. 76% ( 4.6 pp)
→ Due Diligence: 77% vs. 74% ( 3.4 pp)
→ Media and Entertainment: 78% vs. 61% ( 17 pp)
→ Financial Services: 89% vs. 83% ( 5.9 pp)
2
6
26
477,129
Read our full evaluation here. 👇
blog.box.com/anthropics-clau…
1
2
816
The latest State of AI in the Enterprise report from Box is out!
One year ago, 8% of organizations described themselves as advanced or leading edge in AI. Today that figure is 64%. But adoption is not the same as impact. Half of leading edge companies report significant ROI. Among early stage organizations it is just 1 in 9.
We surveyed 1,640 IT decision makers across the US, UK, France, and Japan to find out.
1
2
14
678,683
See the report here.👇
blog.box.com/SAI26-agentic-a…
1
2
678
Box retweeted
Jun 11
Lots of evidence of huge jumps in capability for Fable across coding (and related) tasks. It’s also a major jump in accuracy and success in complex knowledge work tasks.
In our Box AI Complex Work Eval, we tested the model against Opus 4.8 and saw huge boosts across almost every industry. For our eval we give the Box AI Agent, using Fable, a set of hard real world knowledge work problems that deal with enterprise documents. Then score how the agent performs the tasks.
The main differentiators for Fable vs Opus 4.8 is that it doesn't take shortcuts on complex reasoning, it gets multi-step calculations right, and it's significantly more consistent across runs. We saw the biggest leaps in Media & Entertainment (78% vs 61%), Technology (81% vs 73%), Financial Services (89% vs 83%), and Healthcare (66% vs 60%).
Here are some specific examples:
* Legal M&A due diligence: On a task reviewing NDA terms against a semiconductor company's contracting policy, Fable correctly identified that a joint-ownership clause violates exclusivity requirements while a liability cap is permitted under a Super Cap exception. Fable scored 100% vs Opus's 78%.
* Healthcare: On a clinical radiology error audit across 12 reports, Fable precisely categorized each error by severity grade and correctly concluded no Grade 3 errors existed. Opus prematurely escalated a case to "major error requiring immediate departmental review" when the evidence didn't support it — Fable 63% vs Opus 41%.
* Media & Entertainment: On a genre profitability projection task, Fable correctly recognized that a 20% Argentine tax deduction was already embedded in the source spreadsheet figures and didn't double-apply it. Opus applied it again on top — a compounding error across 4 genre calculations that took its score negative on the task vs Fable's 74%.
* Retail analytics: On a task analyzing high-growth product articles against an investment benchmark, Fable correctly computed each article's growth rate individually and identified that only 2 of 5 exceeded the threshold. Opus confused "high growth relative to average" with "above the benchmark" — scoring 61% vs Fable's 94%.
* Financial Services: On a 5-year debt facility projection, Fable correctly applied interest to opening balances and used the right capex figure. Opus applied interest to the total facility amount and computed tax from the wrong base — two compounding errors. Fable scored 83% vs Opus's 62%.
* Technology: On a SaaS feature valuation requiring computation of a Feature Value Index across multiple regions, Fable applied the formula correctly and got exact values for the markets. Opus got the arithmetic wrong on multiple criteria — Fable scored 100% vs Opus's 74%.
Overall, huge step change in complex analysis, work that requires analytical reasoning, and deep domain understanding. Fable will be available shortly in the Box AI Studio for customers to build agents with.

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
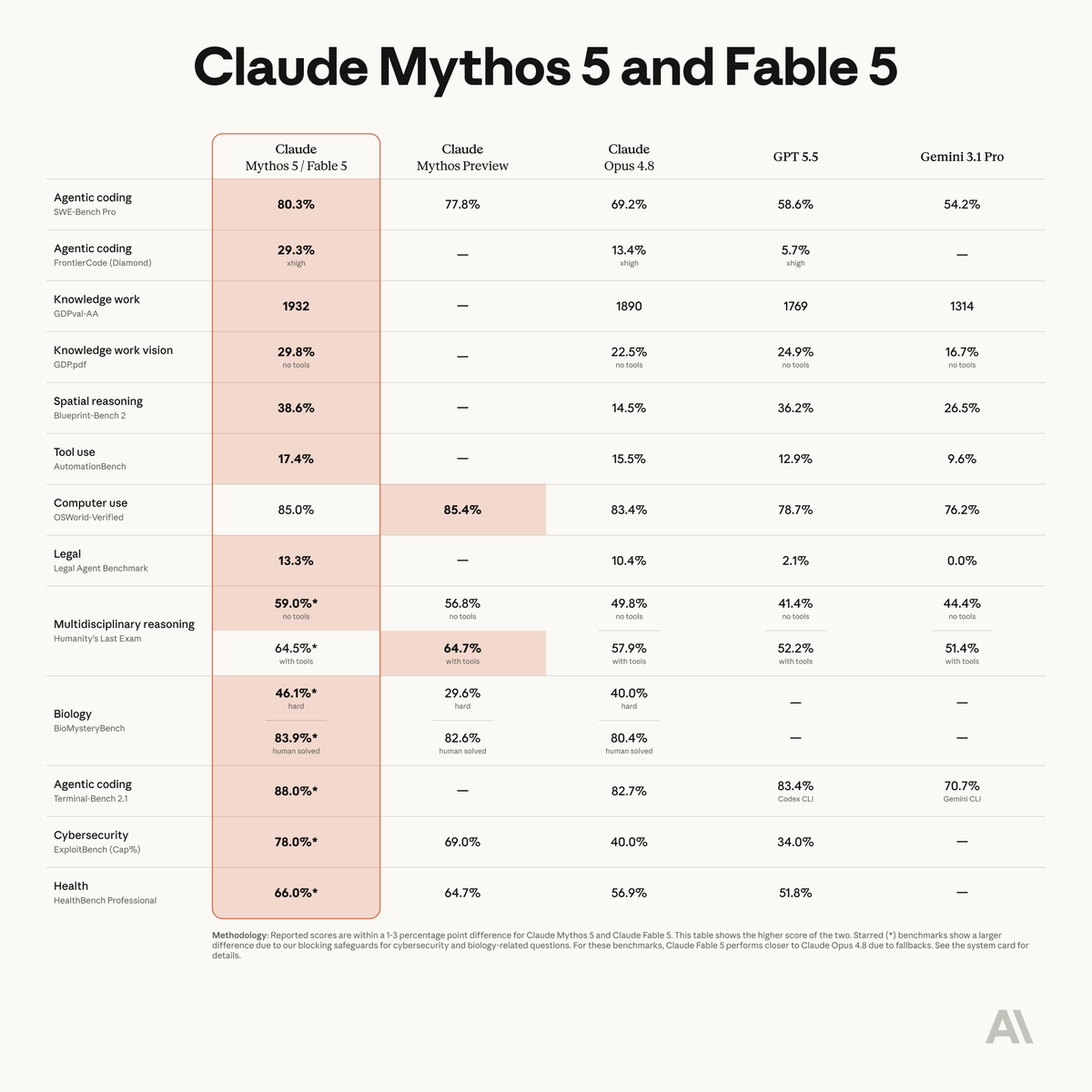
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
43
39
361
72,714
AI assistants are moving from "answer my question" to "do the work." But they are only as useful as the enterprise content they have access to.
Our demo shows what it looks like when @Copilot Cowork is grounded in Box. Your governed content powering multi-step agentic workflows, without ever leaving Microsoft 365.
2
1
9
25,831
Enterprises have tolerated unstructured data governance failures for years. The blast radius was manageable because humans were the ones accessing it.
Agents are a potentially bigger challenge. Our CISO Heather Ceylan shared why AI agents make your unstructured data problem impossible to ignore, and why you have to build the governed content layer before you deploy the agents—not after.
1
3
5
35,908
"The more that you let them think about things, the better the results will be."
The newest AI agents are more capable because they are designed to take time, reason through problems, and make a plan. Our latest AI Explainer breaks down why giving agents more time produces proportionally better results.
1
3
6
71,741
Watch the full episode: youtube.com/watch?v=0SLeegZG…
1
1
1,484
Sales approvals should not require manual document generation, email routing, and CRM updates by hand.
We show how to chain Box Doc Gen and Box Automate via API to go from @salesforce opportunity data to a generated approval packet, routed for review, with the outcome written back to Salesforce automatically.
2
1
6
1,007
Read the full walkthrough here. 👇
blog.box.com/how-automate-sa…
1
1
718