
PhD student @berkeley_ai 👋
Joined November 2009
- Tweets 179
- Following 342
- Followers 1,747
- Likes 1,426
16 Photos and videos













Brent Yi retweeted

Apr 7
Our new work, STITCH 2.0, can perform consecutive running sutures to close a sample wound with the daVinci robot.
8
15
59
26,514
Brent Yi retweeted

World models are heavy. They don't need to be.
Each frame is encoded as 1024 spatial tokens. What if it were just 1?
In our #CVPR2026 Highlight from Amazon FAR, we compress frames into "delta" tokens for efficient generative world modeling.
Paper, code & models below ↓
(1/7)
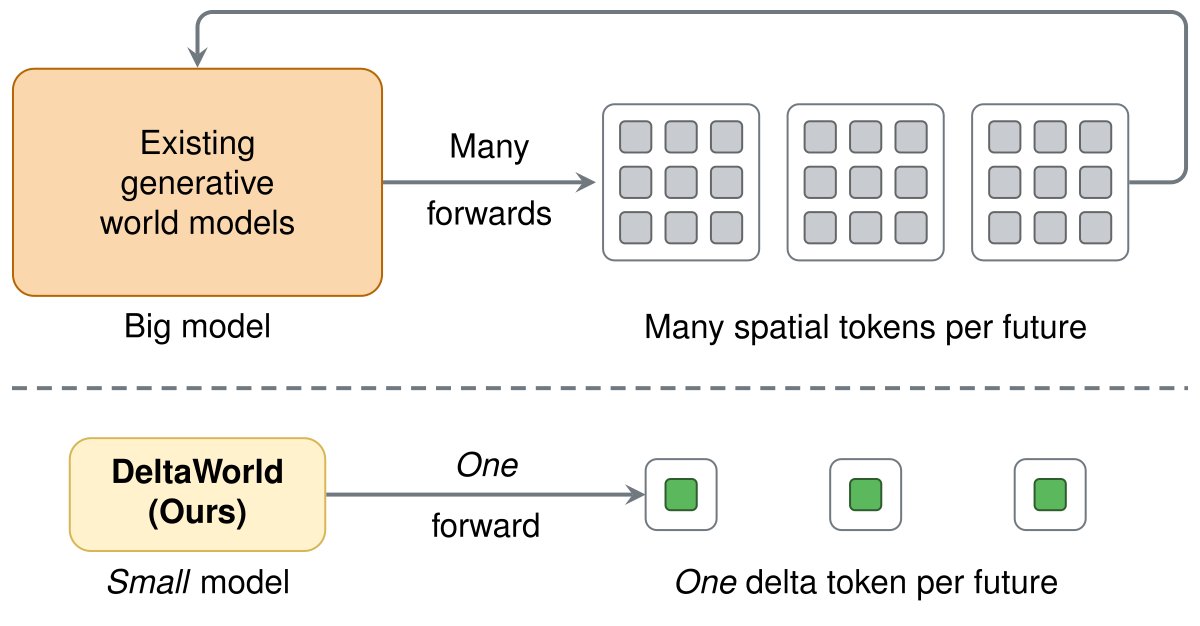
ALT Outline of DeltaWorld. Unlike large existing generative world models that require many forward passes and represent each frame with many spatial tokens, our small DeltaWorld generates multiple futures in a single forward pass by using a single delta token to encode the difference between consecutive frames.
12
74
596
55,529
Brent Yi retweeted

Apr 2
What’s the right representation for a world model? 3D, pixels, or something else?
Excited to release our new paper “Forecasting Motion in the Wild” where we propose point tracks as tokens for generating complex non-rigid motion and behavior
From @GoogleDeepmind @Berkeley_AI @TTIC_Connect
7
74
469
80,698
Brent Yi retweeted

Apr 1
Robotics: coding agents’ next frontier.
So how good are they?
We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability.
From @NVIDIA @Berkeley_AI @CMU_Robotics @StanfordAILab
capgym.github.io
🧵
20
126
632
168,843
Brent Yi retweeted

Mar 27
Excited to share our latest work on motion generation! We tackled multi-agent generation across diverse tasks using Diffusion Forcing.
Check out the project page for more! 🚀
Mar 27

When people share a space, their movements become intertwined. Embodied agents need to understand these social dynamics to interact effectively.
Introducing MAGNet 🧲, a unified autoregressive diffusion forcing model for multi-agent motion generation that captures these interactions.
MAGNet is flexible: predict the future, fill in missing motion, or have people react to each other, all while naturally scaling to N>2 people and generating ultra-long motion sequences.
1
1
9
1,067
Brent Yi retweeted

Mar 27
When people share a space, their movements become intertwined. Embodied agents need to understand these social dynamics to interact effectively.
Introducing MAGNet 🧲, a unified autoregressive diffusion forcing model for multi-agent motion generation that captures these interactions.
MAGNet is flexible: predict the future, fill in missing motion, or have people react to each other, all while naturally scaling to N>2 people and generating ultra-long motion sequences.
6
58
372
66,251

Brent Yi retweeted

Feb 27
The viser viewer in mjlab just got a huge QOL upgrade!
- Real-time factor control: go slower or faster than real-time and viewer paces physics to match
- Single step mode: advance one physics step at a time (super useful for debugging!)
- Overall faster and smoother
5
24
181
7,495
Brent Yi retweeted
Feb 12
New in mjlab from the amazing @ki_ki_ki1: 8 new terrains and a viser-based terrain visualizer 😎
3
16
158
16,777
Brent Yi retweeted

Feb 9
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
32
192
1,436
221,558
Brent Yi retweeted

Feb 6
One of my favorite robot clips (filmed Oct 2025).
You can train any crazy full-body motions like this with our open-source stack without changing any parameters.
whole_body_tracking: github.com/HybridRobotics/wh…
mjlab: github.com/mujocolab/mjlab/t…
17
68
413
37,085

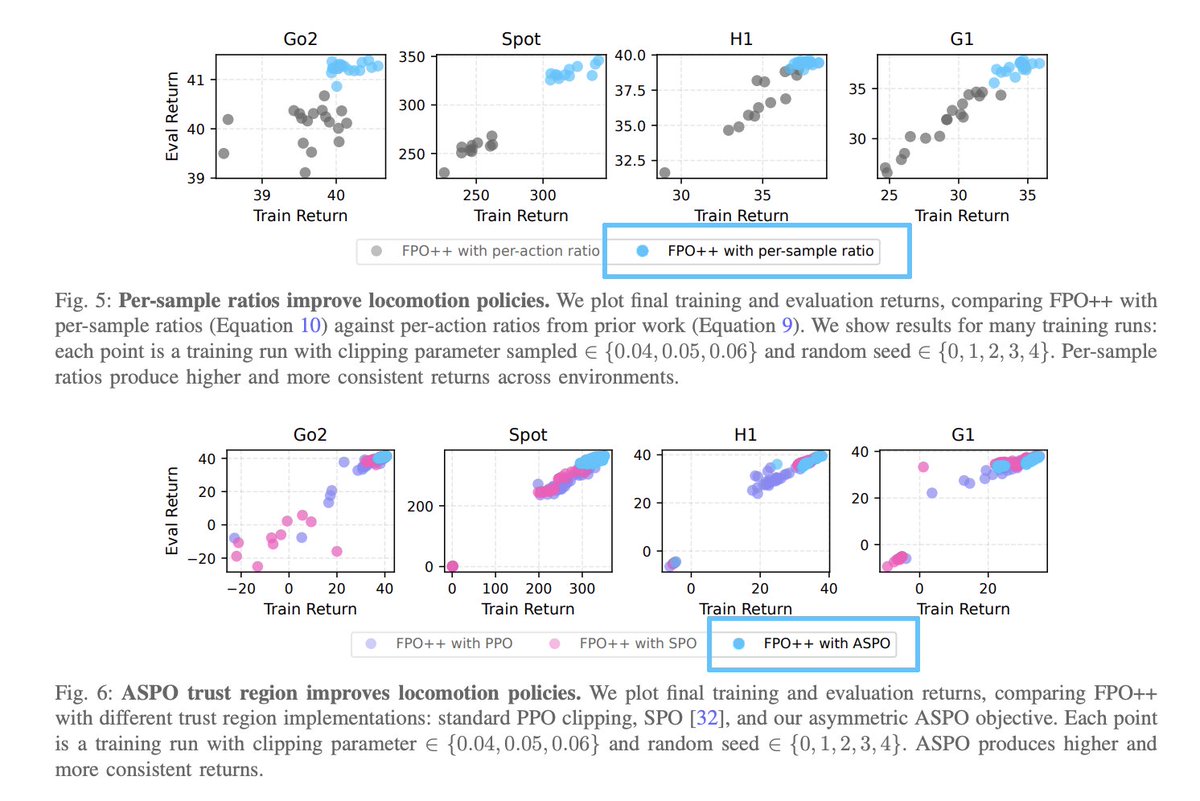
New project! Flow Policy Gradients for Robot Control
tldr; a simple online RL recipe for training and fine-tuning flow policies for robots
co-led w/ @redstone_hong: hongsukchoi.github.io/fpo-co…
16
100
603
73,891
and DexMimicGen:
x.com/SteveTod1998/status/18…
1 Nov 2024

How can we scale up humanoid data acquisition with minimal human effort?
Introducing DexMimicGen, a large-scale automated data generation system that synthesizes trajectories from a few human demonstrations for humanoid robots with dexterous hands. (1/n)
1
11
1,087