
Product Design Lead @Tovira_sui
Joined May 2022
- Tweets 10,919
- Following 266
- Followers 591
- Likes 12,430
507 Photos and videos




Brown retweeted

May 13
New look. Better flow. Cleaner experience.
We just revamped our landing page to make everything smoother, faster, and way more intuitive.
From the visuals to the user journey, every detail was redesigned to feel better, work better, and connect better.
tovira.xyz
6
10
22
582

May 12
We just launched testnet V2 on @SuiNetwork
V2 introduces some of our biggest shifts yet in defining how users interact with our core product, had fun iterating ux
Try out V2, would appreciate feedback.
1
1
2
91
Brown retweeted
May 11
🚀 TESTNET V2 IS LIVE 🚀
The wait is over.
A faster, smoother, and stronger experience starts now.
testnet.tovira.xyz

9
17
76
5,275
Brown retweeted
Jan 27
Web3 is powerful, but let’s be honest ; the UX is still frustrating. 😅
We’re hosting an X AMA to have the real conversation:
📌Why is Web3 UX still so bad?
Are we building for projects, or for real users?
Designers, builders, founders, users — pull up.
This one will be raw, honest, and necessary. 🎙️🔥
📍 Venue: X (Twitter)
⏰ 7PM, Saturday 31st Jan
We are thrilled to have @InspectorPambs @notbypriest @Azariahsamuel6 @AngelBatubo @Brown_ux as our speakers.
Come share your experiences, frustrations, and ideas.
Let’s fix this together. 🚀

6
7
23
1,064
Jan 23
I'm really excited to share that I have joined @Tovira_sui as product lead to build user centered AI products on @SuiNetwork, new chapter here and I'm excited for it.
8
2
18
566
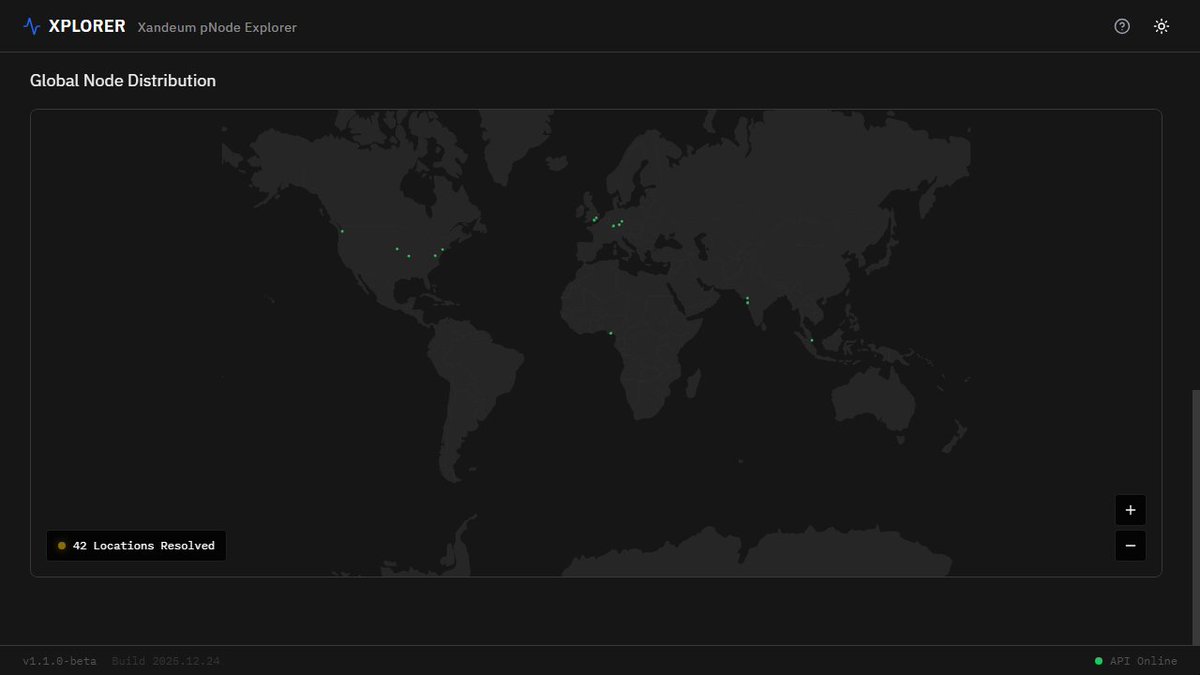
26 Dec 2025
41 more @xandeum pNodes have appeared on the map in the last 24 hours, this confirms the geo-location logic I used for this works well (huge relief)
and I'd guess some nodes opted out of privacy settings, Xplorer auto picks that up and runs routined checks on geo-location
The hackathon submission closed today, I was really hoping I would have time to add interactive functionalities to the network map, like being able to click on countries for details or calculate and visualize decentralisation density as heatmaps
But still, even the attempts I had at implementing the logic of this feature has all failed so far haha, it's on pause for now, but I will give it more thoughts after the hackathon results are out
I am also currently working on a data research and methodology for xandeum pnodes, I think there's still so much insights that can be derived from the current available data
translating that into product data positioning without cluttering UX and cognitive design is where the work really is
btw I updated the status tag on the right of the footer "API online" to actually check the real connection state of my API, so if you check in anytime and see something else like "Connection failed" please send a DM so I can fix it asap, thank you!
Happy Holidays.
1
4
308
Brown retweeted
20 Dec 2025
I just released the first stable version (v1.0.0) of an explorer platform for @Xandeum's pNode storage network - XPlorer
Watch the video for my demo submission link to live platform and github repo (in comments)
3
1
5
614
20 Dec 2025
From research, architecture design, product and analysis, I built XPlorer user-first, cognitive, intuitive and optimized directly for data insights on
@Xandeum's pNode network
I use A LOT of analytics tools, building one was simply an elevative experience, encountered so much issues with the backend infrastructure and some data logic
I remember commiting my first backend repo as "Final Backend Infrastructure" because I had tested it so much locally and thought it was ready for production, haha (I was so wrong)
I later pushed about 6 different commits that same day haha
I spent a lot of time studying xandeum's pnode network to understand it's architecture and how to create valuable data insights from what was available (will share notes later)
The current version of XPlorer is officially v1.0.0
I iteratated on the user experience a lot and will continue to do so over time, so more versions incoming
btw I love the dark mode really, but some users prefer light mode, so I made sure to add it
I hope you like it, and find it useful Please feel free to send a DM for feedback, i'd reply immediately I am available
20 Dec 2025

I just released the first stable version (v1.0.0) of an explorer platform for @Xandeum's pNode storage network - XPlorer
Watch the video for my demo submission link to live platform and github repo (in comments)
1
1
4
223
20 Dec 2025
I just released the first stable version (v1.0.0) of an explorer platform for @Xandeum's pNode storage network - XPlorer
Watch the video for my demo submission link to live platform and github repo (in comments)
3
1
5
614
20 Dec 2025
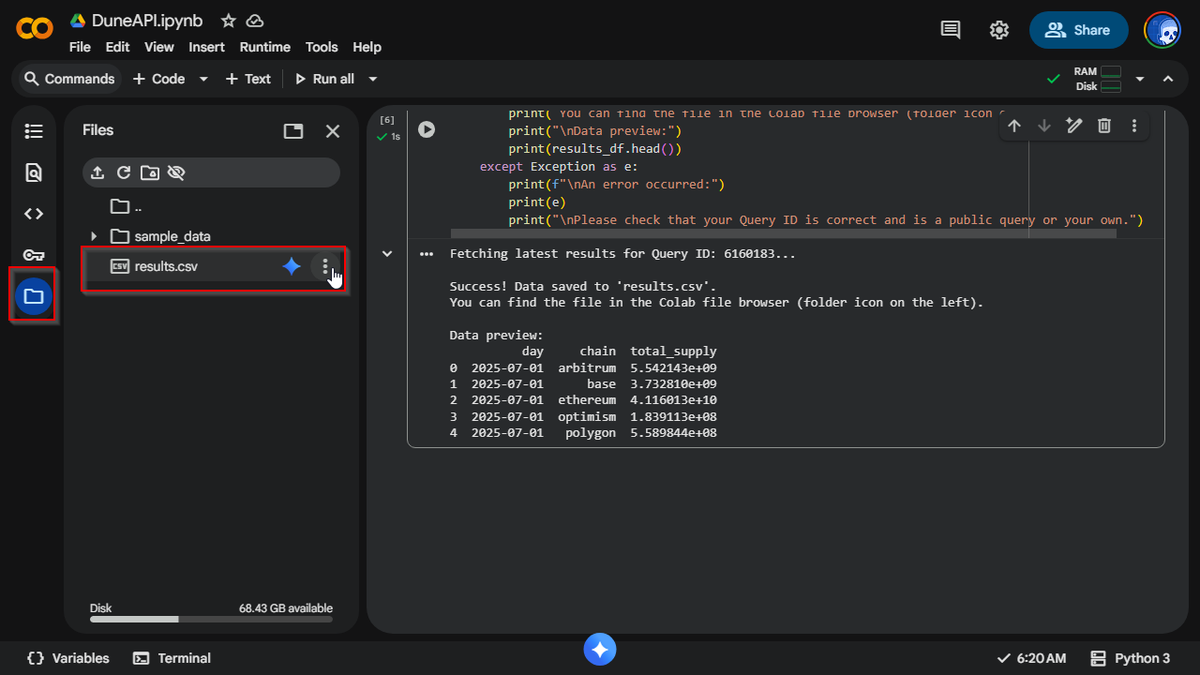
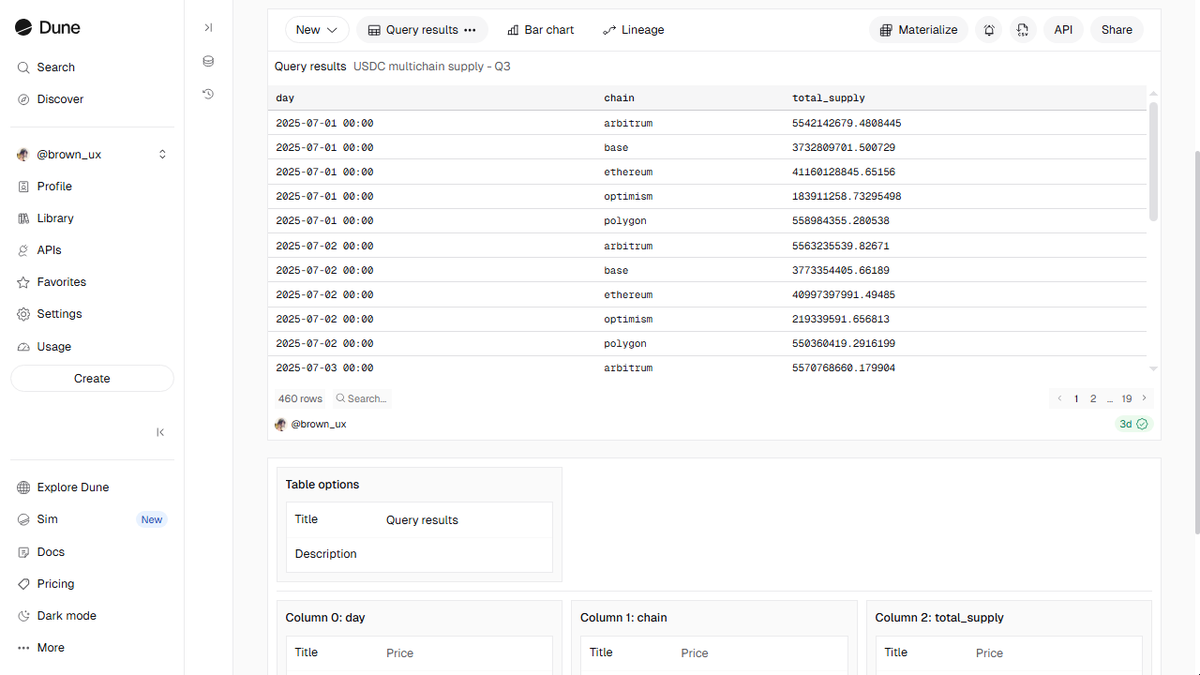
Try out XPlorer here - xplorer-ten.vercel.app
Feel free to reach out when you do, I'd appreciate any feedback
2
89
5 Dec 2025
It’s been about 10 days since @monad went live on mainnet, and I’m already seeing profiles say things like “Oh look, they said 10K TPS, but look what the data says.”
Let’s get this straight: when Monad says “10K TPS” (aka throughput capacity), they’re essentially saying:
“When we need to, our network can handle up to 10,000 transactions per second.”
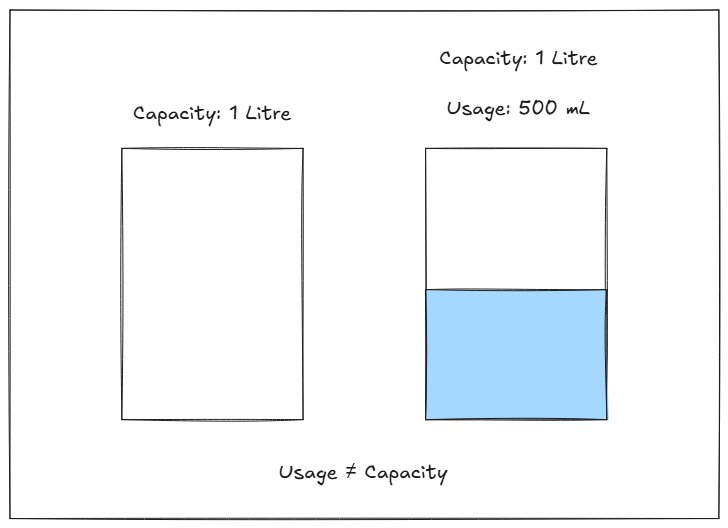
It’s like I tell you I have a jar that can take 1 litre of water when full, and then I show you the jar with only 500ml inside, and you say, “look, it’s not 1 litre.”
Well yeah… because it’s not full yet.
Capacity is a theoretical upper bound shaped by off-chain factors, design, hardware assumptions, propagation speed, execution model, and the physical limits of the network. It is not something you “read” from onchain data.
So when you query TPS onchain, the result you get is strictly about actual usage, meaning you’re answering the question:
“How many transactions did the network handle per second?” not how many it could handle.
Before digging into network efficiency and optimization, I spent time studying how the design of various L1s affects onchain TPS. What became obvious is this:
There are a lot of variables that influence onchain TPS, especially for high-performance L1s. A few important ones:
> demand (how many tx users submit)
> block structure (gas limits, block times, fee rules)
> transaction heterogeneity (simple transfers vs heavy/complex contracts)
> optimization differences (client performance, mempool behavior)
> execution model (sequential vs parallel execution)
> workload shape (parallelizable vs contention-heavy workloads)
That last part is especially true for Monad and other chains like @Aptos and @SuiNetwork, parallel runtimes scale differently based on workload type:
highly parallel workloads → huge TPS
contention-heavy workloads → lower TPS
mixed workloads → volatile TPS
This is the execution model reacting to the shape of the workload, not “real performance fluctuation.”
And it’s important to note that TPS doesn’t tell you when a network is under strain. If a chain is approaching its limits, you’d see fee pressure, mempool growth, latency creep, and blocks saturating.
None of that is happening on Monad today, which means the system is nowhere near its ceiling.
The fundamental logic of onchain data is simple: it answers questions. TPS by itself answers “How many transactions did the network handle?”
It doesn’t address all the other variables that affect the number you’re looking at.
So no, low early TPS on a brand-new chain doesn’t contradict its theoretical capacity. It just tells you the jar isn’t full yet.
1
5
200
29 Nov 2025
Ethereum’s Fusaka upgrade leans on PeerDAS and its erasure-coded design for blob data availability
by distributing RS–encoded shards across the network, validators can verify data availability even when only ~50% is sampled
Research on RS design → x.com/Brown_ux/status/199396…

1/ Fusaka is coming December 3rd.
Ethereum’s next major upgrade shows that the network can grow to meet global demand, without compromising on decentralization or permissionlessness.
Whether you’re a user, builder, institution, or operator, here’s how Fusaka will impact you.

1
2
214
27 Nov 2025
I have been thinking a lot about my growth path to impact and network in this industry
As long term as I think I am ready to stay, I am becoming anxious that I will burn time on things that may not add to my perceived value
By myself, I see growth, but when I think of where I want to be and how much impact I want to make in research, It seems like I am nowhere near that
That, in fact, is both thrilling and scary at the same time, especially because I might feel like I am on the right path and maybe absolutely not
Building, not just any network, but a network that sees value in what you do is really hard (or maybe it's becoming valuable at all that is hard)
I have never felt more inclined to look for someone who could be a guiding light to me in this industry
Of course, I never thought I could make it alone, but I also never thought I'd need to be held by the hand either
I'd say, "Just study how they do it," but honestly, that's been really hard
I spend 6-9 hours a day on data and research, most of which never make it to publishing
When I get exhausted and nearing sleep, I'd think to myself; maybe if I had spent this time on X, I'd have gained more followers
As skilled as I think I am, I fear that the reality of my skill level may be far from that
But I have never really gotten the opportunity of true feedback (from someone who is up there already)
And all this drags me back into the same loop, "spend more time getting better and you will," but when I look into the mirror that is you (my network), is there really value in me?
1
3
377
27 Nov 2025
Ethereum’s scaling roadmap effectively hit a bandwidth ceiling after Dencun
While blobs successfully lowered costs for Layer 2s by offering temporary storage lanes, the current requirement for validators to download this data in full restricts the network's ability to scale without hurting decentralization
[More on Blobs: x.com/Brown_ux/status/197447…]
PeerDAS resolves this bottleneck by fundamentally changing the verification model: shifting from "downloading everything" to "sampling specifically."
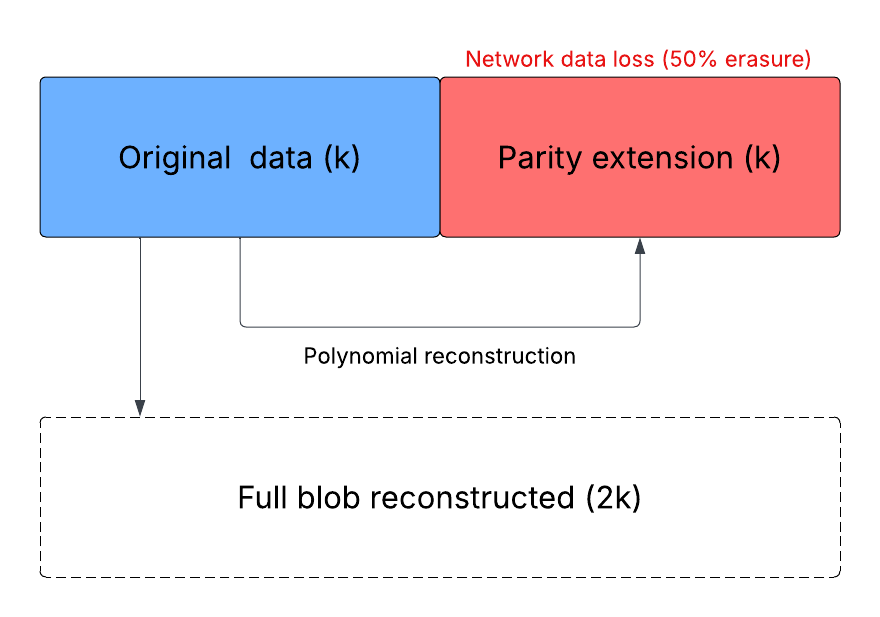
For this to work without compromising security, the protocol relies on a specific cryptographic transformation. When a proposer submits a block, the blob data is not just posted; it is mathematically extended using Reed-Solomon erasure coding.
This process generates redundant bridges to the original data, ensuring the information is mathematically dispersed across the network rather than existing as a fragile, single file
The implications of this structure are massive. Because of this redundancy, the network no longer needs to possess 100% of the shards to reconstruct the file
As long as the network collectively holds at least 50% of the extended dataset, the entire original blob can be perfectly recalculated regardless of which specific parts are missing.
This mathematical guarantee is what allows us to partition data across subnets, freeing nodes to focus on speed rather than raw storage. But does this hold up under stress?
My recent research aimed to verify this theoretical limit computationally. I modeled the reconstruction process in a simulated environment to observe the system's behavior at the margins of failure.
The results confirmed that while the system is robust at 50% availability, there is a stark "cliff edge" where the original blob becomes mathematically irreversible if even one byte more is lost.
This confirms that Ethereum’s security model relies on a precise, binary boundary.
Crucially, while this cliff edge exists theoretically, a scenario where 50% of data is simultaneously lost across a decentralized, global network is highly improbable outside of a coordinated, massive-scale attack.
The Reed-Solomon extension provides an immense probabilistic safety buffer for normal network operations.
Read the full research note:
27 Nov 2025
Modeling @ethereum's Fusaka PeerDAS: A computational analysis of reed-solomon erasure coding
hackmd.io/@brownresearch/HJC…
1
3
247
27 Nov 2025
Modeling @ethereum's Fusaka PeerDAS: A computational analysis of reed-solomon erasure coding
hackmd.io/@brownresearch/HJC…
2
451
25 Nov 2025
Drafted a 6 page methodology documentation for my data research on @AcrossProtocol around its V3 model
20 metrics evaluating its intent economy and decentralization depth of the protocol's relayer network
then decided to do a study on V4 before kicking off
V4 introduced a more advanced architectural design on verification (now universal via @SuccinctLabs's SP1Helios) and settlement of cross-chain intents
now I'm not even sure if I should stick with V3 for the research (esp given that most of its data is deprecated) or V4 since it's the flagship version (thesis remains the same tho)
also need to learn how to navigate data structures of upgradeable contracts better, updates = structural change and most times it's visible in data continuity
1
3
175
21 Nov 2025
had a draft on a research thesis covering "the privacy paradox of intents" to explore systemic risks of intents visibility in solver infrastructure
until I saw anoma's developments on "confidential intents" powered by fairblock (mind blown)
what a time to be alive
31 Jul 2025
Fairblock × Anoma unlocks confidential intents:
- Onchain amounts and triggers: Fairblock
- Solver privacy: Fairblock Anoma
- Confidential solver bids: Fairblock Anoma
- Address anonymity: Anoma
Simply Better pricing. Stronger security.

1
5
172
18 Nov 2025
something that's been on my mind a lot during my work these past few months is how often we mix up two key parts of data processes
> data collection
> data visualization
> data presentation*
> data analysis*
If you're just starting out your data journey I think it's important you know the difference between the last two. Let me explain:
data presentation shows you WHAT happened, it points to a number and says "look this happened"
example: user count went down by 20%
data analysis looks deeper to tell you 'WHAT EXACTLY', 'WHY', & 'WHAT TO DO'
this time looking deeper to tell you the full story
what exactly happened? what is the nature of that 20%? (were they new users or long-time power users?)
why did they leave? (new users from last month's campaign stopped using the app, Is it because the campaign ended or was the onboarding poor?)
what to do? what patterns do we see, and what's the recommendation? (now that we know why, here is what we recommend)
presentation shows you a number. analysis gives you a story and a recommended action
collection, visualization, and presentation are all critical (and tedious!) parts of the job, but I think knowing the difference is essential
this is especially important when you're working with teams to inform a product's growth, user experience, and market position
4
1
7
233
14 Nov 2025
after 3 weeks of working on my research project, I am not so excited to announce that I am discontinuing my research
my curiosity started from wanting to understand the true nature of the "omnichain" concept and what it really meant for money markets
from OFTs to OApps by @LayerZero_Core, the goal was to explore and evaluate the solution design of omnichain protocols (specifically lending markets)
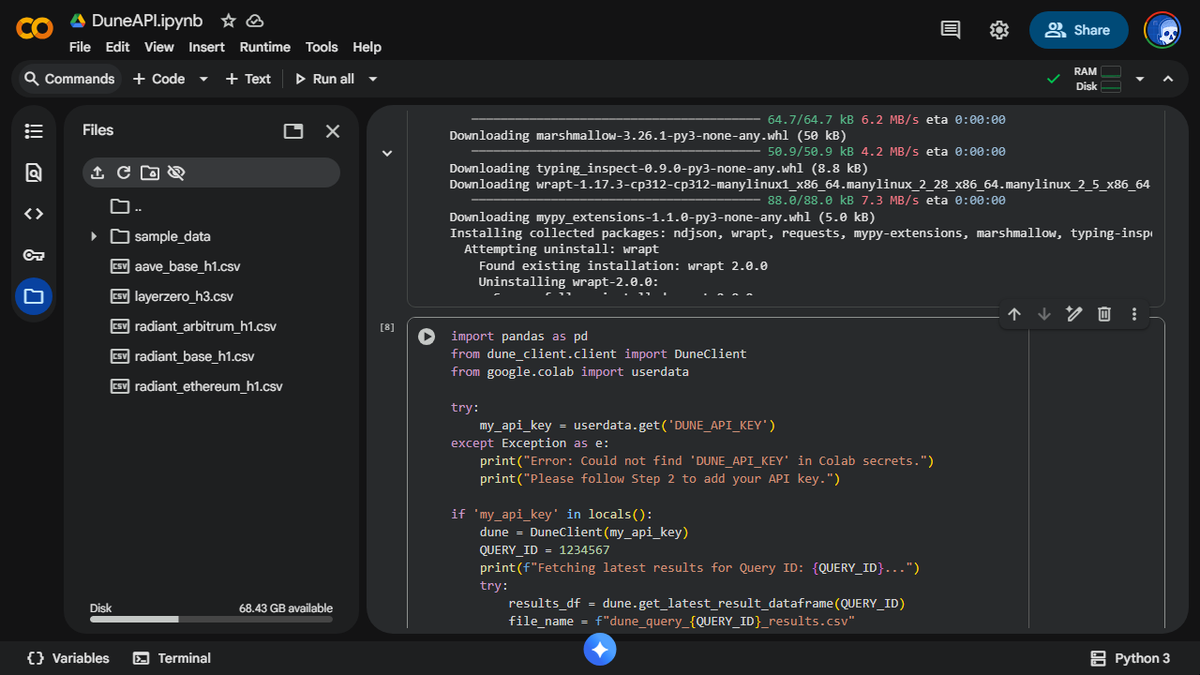
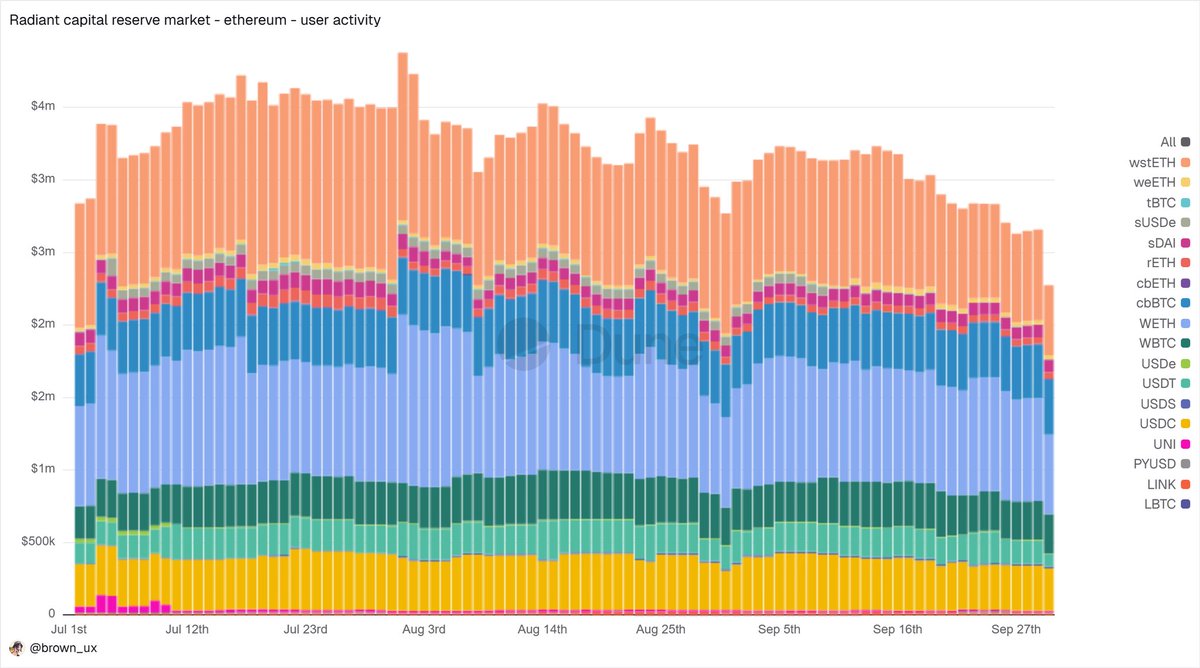
Based on the criteria I set to select the candidates of my research, I'd found only Radiant capital to be the prominent omnichain protocol in the lending market category
With the other candidate being aave, the advantage is anything but fair
Radiant experienced two major protocol hacks last year, that insta killed user trust making them "migrate liquidity"
The entire premise of capital efficiency and multi chain money movement is already running negative since users are leaving anyway
This is why I decided to wind down
It's a little painful, yes but I actually did learn A LOT during my research, from smart contract data structures to APIs, computations and analysis with python and building up hypotheses for empirical analysis, maths, logic and code
it has been nothing short of exiting, so I'm not exactly sad about this, I've actually never felt more ready for my next research
The biggest take away for me (and you) here is, when you want to research say the impact of a few concepts on a protocol, make sure to check the current landscape and state of the protocol
that way you'd ensure that your evaluation is fair and objective
gm
1
6
227