
Browser automation for real web data workflows. Scraping templates, APIs, retries, dedupe, and delivery beyond the first run.
Joined May 2025
- Tweets 189
- Following 6
- Followers 268
- Likes 54
79 Photos and videos












Jun 11
🚨 Headless browser automation breaks at login, CAPTCHA, 2FA.
The pattern:
→ Define task boundaries
→ Keep state compact
→ Human handoff for hard edges
→ Convert to reusable Skills
Explore once. Automate the rest.
browseract.com/blog/headless…
#BrowserAutomation #AIAgents
1
1
18
Jun 11
Multi-account social automation fails at the account boundary, not the scheduler.
Durable model:
1 account = 1 browser identity
1 workflow = 1 session
Publishing / DMs / 2FA = human approval
browseract.com/blog/automate…
16
Jun 10
AI agents need more than search results.
A useful web stack needs search, fetch, extract, browser actions, login, and workflows.
Tool map: BrowserAct, Browserbase, Firecrawl, Apify, Playwright, MCP tools.
browseract.com/blog/tools-fo…
50
Jun 10
Best browser automation for AI agents?
Scripts, data fetches, cloud browsers, and logged-in actions are different jobs.
I compared BrowserAct, Playwright, Browser Use, Browserbase, Firecrawl, and Selenium.
browseract.com/blog/best-bro…
2
63
Jun 9
BrowserAct vs Browserbase is really workflow vs infrastructure. Browserbase is strong cloud browser infrastructure. BrowserAct is built for logged-in workflows, account identity, human approval, and multi-account browser operations. browseract.com/blog/browsera…
1
24
Jun 9
AI agents can search the web. The harder question: can they safely use logged-in websites? New guide: login state, 2FA handoff, approval gates, browser sessions, and account isolation. browseract.com/blog/ai-agent…
27
Jun 8
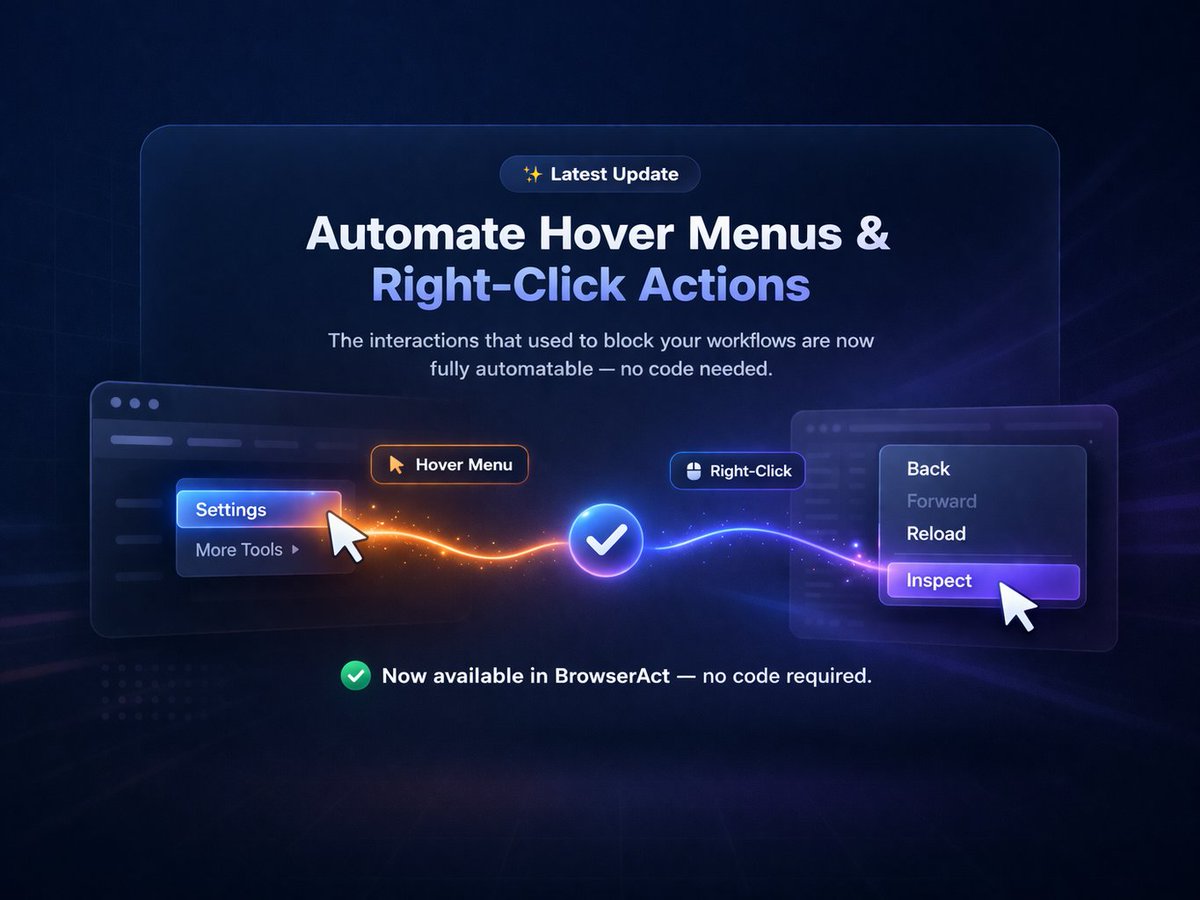
🚀 BrowserAct Static Proxy is live.
Built for more stable social media automation.
One managed account.
One browser profile.
One static IP.
Read the docs:
docs.browseract.com/workflow…
Upgrade BrowserAct and try it now:
github.com/browser-act/skill…
1
112
Jun 8
🤖 AI agents look solid in demos — real sites expose the browser as the bottleneck.
Cloudflare, CAPTCHA, session drops, automation flags trip up most agents.
BrowserAct covers it: stealth browsing, session persistence, workflow recovery.
Worth a read 👇
medium.com/towards-artificia…
51
May 29
🚀 New feature is live: BrowserAct Multi-Session.
🧩 One browser profile. Multiple independent session windows.
⚡ Your agent can now run browser workflows across Facebook, LinkedIn, X, research sites, dashboards, or internal tools in parallel.
Try it 👇
github.com/browser-act/skill…
View videos👇
youtube.com/watch?v=RmhAqpaU…
💬 Questions or ideas? Drop them below.
#BrowserAct #AIAgents #BrowserAutomation #ClaudeCode #Automation
1
2
78
May 24
🚨 Twitter scraping in 2026:
API is $200/mo (Basic) or $5,000/mo (Pro).
snscrape/nitter are dead.
✅ Durable path: real-browser takeover (logged-in Chrome).
browseract.com/blog/twitter-…
1
85
May 23
A Google Maps scraper that only exports a CSV is halfway done.
Production setup:
- search matrix, not one broad query
- scroll dedupe validation
- API/webhook delivery when teams depend on it
Guide:
browseract.com/blog/google-m…
1
95
May 23
Playwright spawns a fresh browser with no login. BrowserAct's browser-act Skill drives the Chrome you're already signed in to.
Tried in Claude Code:
→ Triage 6 logged-in GitHub Issues
→ Smoke-test a NVDA alert form
→ Forge a github-repo-research Skill
browseract.com/blog/agent-br…
116
May 22
🚨 Stop rebuilding broken web workflows.
BrowserAct Skill Forge turns any website into a reusable agent skill.
⚡ Install
🧠 Describe the workflow
▶️ Run the skill
📊 Get structured data
Works with Codex, Claude Code, Cursor, Gemini CLI, GitHub Copilot, Windsurf, and more.
Install:
npx skills add browser-act/skills --skill browser-act-skill-forge
👉 browseract.com/skill-forge
2
224
May 15
1/ 🚀 BrowserAct Skill Forge is here.
Turn real website workflows into reusable AI Agent Skills with one natural-language instruction.
1
3
134
May 15
4/ Most browser automation is fragile.
Selectors break.
Pages load dynamically.
Sessions expire.
Scripts become hard to maintain.
Skill Forge helps turn those workflows into agent-callable capabilities.
1
2
109
May 15
5/ Useful for:
Creator / KOL sourcing
Market research
Competitor monitoring
Lead generation
Internal web automation
AI agent workflows
GitHub: github.com/browser-act/skill…
What website task would you turn into a Skill?
2
110
May 14
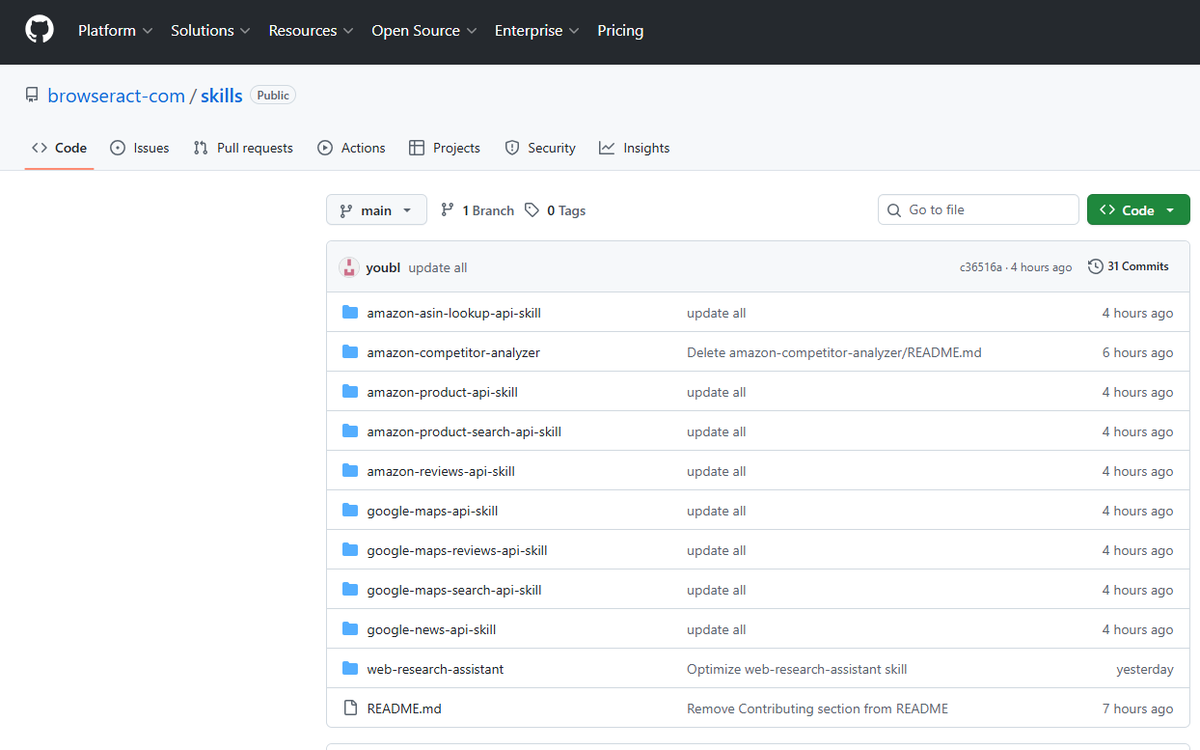
Most "agent browser" tools = Playwright stealth patches. Flagged in headless.
Open-sourced two Skills today:
- browser-act: stealth Chromium, remote-assist on 2FA
- skill-forge: agent explores any site, emits a reusable Skill
Free.
github.com/browser-act/skill…
1
4
230
Apr 24
Amazon's CAPTCHA isn't a puzzle — it's AWS WAF scoring your browser on 7 signals.
→ 2Captcha: $1/1K image only
→ Stealth residential: 85%, breaks weekly
→ Real-browser takeover: 98%, zero maintenance
browseract.com/blog/amazon-c…
2
204