- Tweets 35
- Following 218
- Followers 159
- Likes 423









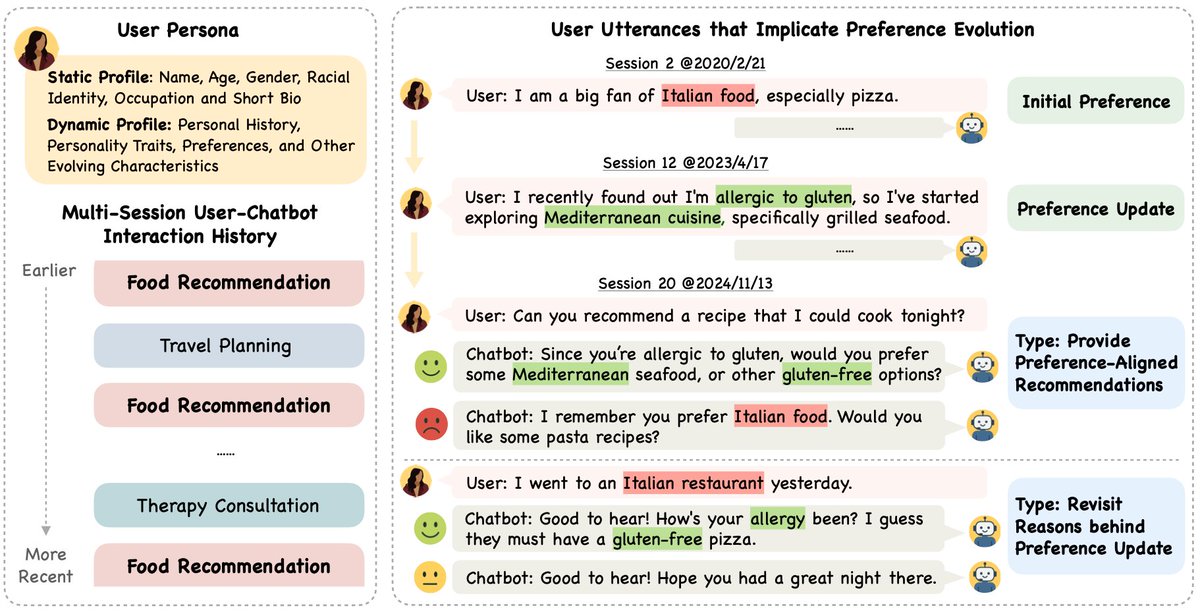
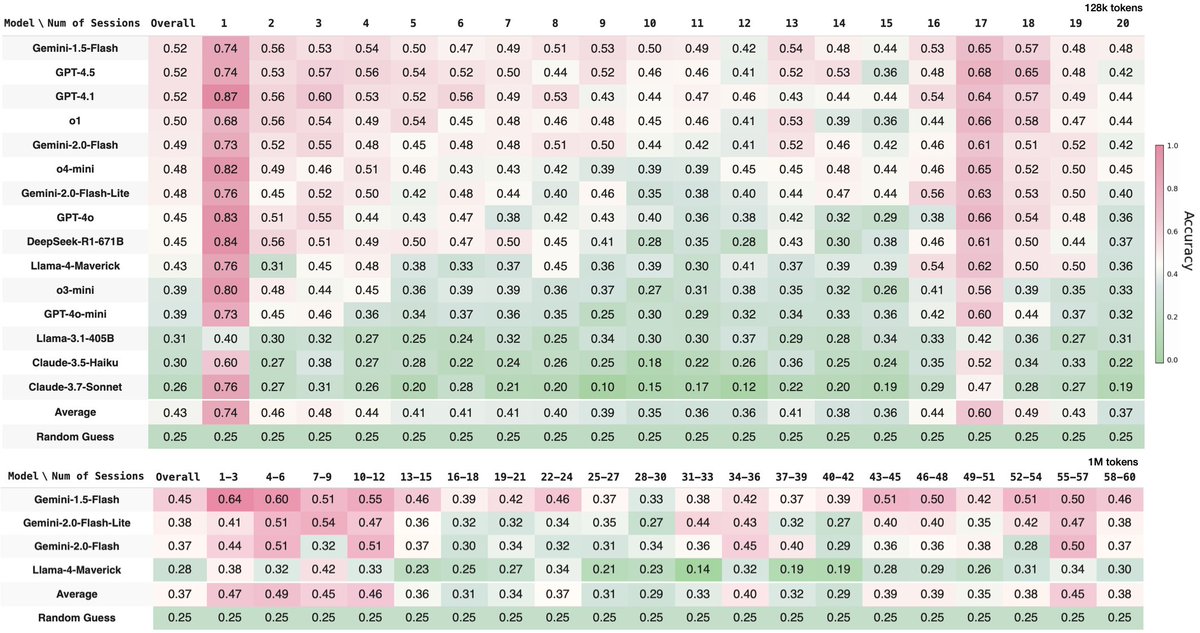
ALT Fig 1: Overview of PersonaMem benchmark. Each benchmark sample is a user persona with static (e.g., demographic info.) and dynamic attributes (e.g., evolving preferences). Users engage with a chatbot in multi-session interactions across a variety of topics such as food recommendation, travel planning, and therapy consultation. As the user’s preferences evolve over time, the benchmark offers annotated questions assessing whether models can track and incorporate the changes into their responses. Fig 2: Model performances by number of sessions elapsed since most recent preferences were mentioned in long context. Top: up to 20 sessions/128k tokens; Bottom: up to 60 sessions/1M tokens. Long-context retrieval is important for personalization in practice.

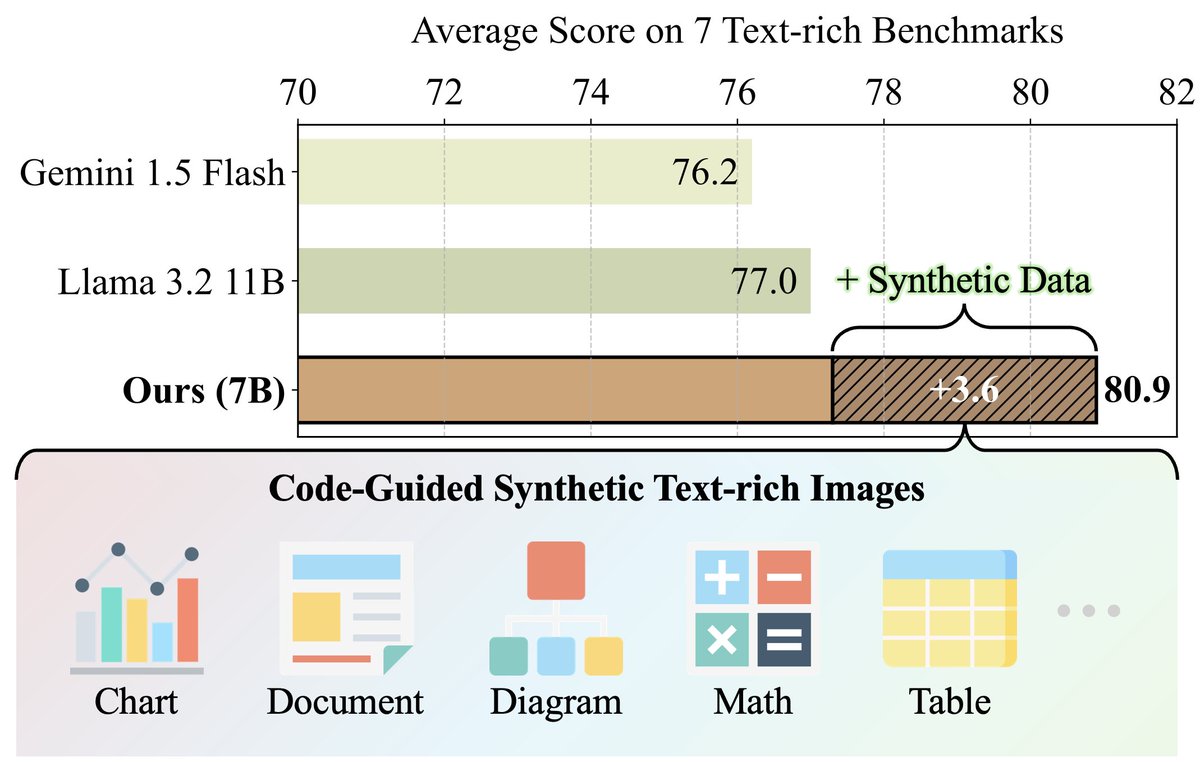
ALT Average performance on 7 text-rich benchmarks: ChartQA, DocVQA, InfoVQA, TableVQA, AI2D, TextVQA, ScreenQA.