
NLP Researcher; Twitter lurker
Joined November 2009
- Tweets 136
- Following 187
- Followers 514
- Likes 422
Photos and videos
Colin Cherry retweeted

11 Mar 2025
Externally retrieving knowledge empowers LLMs for domain-adapted MT ⚖️🩺. But how is knowledge best represented, and how viable is generating it from an LLM itself? Our @GoogleAI paper investigates these questions through a careful experimental setup 📜. arxiv.org/abs/2503.05010
1
3
6
446
Colin Cherry retweeted

14 Mar 2025
<<Call for BoF/Affinity Group meeting>>
Applicants should fill out the application form before March 24
2025.naacl.org/calls/affinit…
#NAACL2025
1
2
1,520
Colin Cherry retweeted

19 Feb 2025
😼SMOL DATA ALERT! 😼Anouncing SMOL, a professionally-translated dataset for 115 very low-resource languages! Paper: arxiv.org/pdf/2502.12301
Huggingface: huggingface.co/datasets/goog…

3
12
35
4,187
Colin Cherry retweeted
12 Feb 2025
The call for Diversity and Inclusion Subsidies is out:
2025.naacl.org/calls/dei_sub…
7
10
2,143
Colin Cherry retweeted

26 Nov 2024
LLMs are typically evaluated w/ automatic metrics on standard test sets, but metrics test sets are developed independently. This raises a crucial question: Can we design automatic metrics specifically to excel on the test sets we prioritize? Answer: Yes!
arxiv.org/abs/2411.15387

4
11
49
11,766
Colin Cherry retweeted

12 Nov 2024
New application link! google.com/about/careers/app…
I am at EMNLP/WMT this week. Please come find me if you want to learn more about this role!
18 Oct 2024

Interested in doing research on Google Translate and Gemini? Good news! I’m hiring for full-time roles on the Google Translate Research Team! Apply here: google.com/about/careers/app…
10
35
5,536
Colin Cherry retweeted
29 Oct 2024
📢Don't miss the NAACL Student Research Workshop!
🖇️ CFP & Important dates: naacl2025-srw.github.io/cfp
#NLProc
2
4
3,003

Thank you to those who participated in our recent all-member vote regarding our name change. The change is happening!
We are: The Nations of the Americas Chapter of the Association for Computational Linguistics!
Announcement 👉 naacl.org/posts/2024-10-24-N…
1
13
64
3,271
Colin Cherry retweeted
21 Oct 2024
📢 NAACL needs Reviewers & Area Chairs! 📝
If you haven't received an invite for ARR Oct 2024 & want to contribute, sign up by Oct 22nd!
➡️AC form: forms.office.com/r/8j6jXLfAS…
➡️Reviewer form: forms.office.com/r/cjPNtL9gP…
Please RT 🔁 and help spread the word! 🗣️
#NLProc @ReviewAcl
1
27
41
9,806
Colin Cherry retweeted
18 Oct 2024
Interested in doing research on Google Translate and Gemini? Good news! I’m hiring for full-time roles on the Google Translate Research Team! Apply here: google.com/about/careers/app…
3
82
246
38,341
Colin Cherry retweeted

17 Oct 2024
Researchers from @Google reveal that verbose #LLMs, 🤖 which offer multiple translations 🔄 or refuse to translate, 🚫 pose significant challenges ⚠️ to traditional #MT evaluation frameworks.
#machinetranslation @ebriakou @ColinCherry @markuseful
slator.com/google-finds-refu…
4
6
475
Colin Cherry retweeted
17 Oct 2024
📢 Call for demos is out!!
#NAACL2025 #NLProc
Check the website for submission guidelines and a chance to win the Best Demo Award! 🏆
🖇️ 2025.naacl.org/calls/demo/
6
11
6,366
Colin Cherry retweeted

7 Oct 2024
📢📢🌟@jhuclsp Have an Idea? Let’s Hear It!
JSALT 2025 Call for proposal is out.
Deadline: October 15th, 2024
For more information:
clsp.jhu.edu/the-11th-freder…
5
14
4,486
Colin Cherry retweeted

2 Oct 2024
[1/5] Are verbose #LLM translations skewing evaluation results?
TLDR: Yes!
Our recent work dives into the prevalence and impact of LLM verbosity in automatic and human evaluations.
📎 Paper: arxiv.org/pdf/2410.00863

1
11
48
4,492
Colin Cherry retweeted
2 Oct 2024

1
10
46
9,543
Colin Cherry retweeted
12 Sep 2024
Translation is a complex task involving pre-translation research and post-translation stages. Can #LLMs handle this process step-by-step, relying solely on their internal knowledge?
✨We show that decomposing the translation process significantly improves #Gemini translation quality of long-form texts across all #WMT24 languages!
📜arxiv.org/pdf/2409.06790

2
14
69
6,564
Colin Cherry retweeted
12 Sep 2024
📢 Calling all #NLProc enthusiasts! Submit your tutorial and workshop proposals to 2025 *ACL conferences (NAACL, ACL, EMNLP) through one joint call!
Tutorials: 2025.naacl.org/calls/tutoria… Workshops:2025.naacl.org/calls/worksho…
12
23
3,760
Colin Cherry retweeted
27 Aug 2024
🥳 LLMs are changing the game, even for datasets! NewsPaLM, a publicly released LLM-generated dataset, outperforms larger web-crawled corpora for MT. It includes sentence & paragraph-level, MBR-decoded data. See paper for more, incl. LLM self-distillation. arxiv.org/abs/2408.06537
1
8
36
3,523
Colin Cherry retweeted
22 Aug 2024
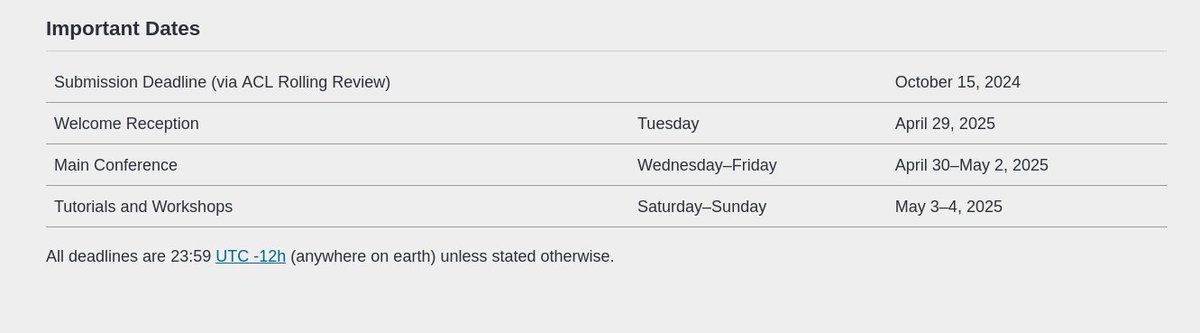
First call for papers is out!
#NAACL2025
🔴2025.naacl.org/calls/papers/
1
22
73
7,917
Colin Cherry retweeted

17 Jul 2024
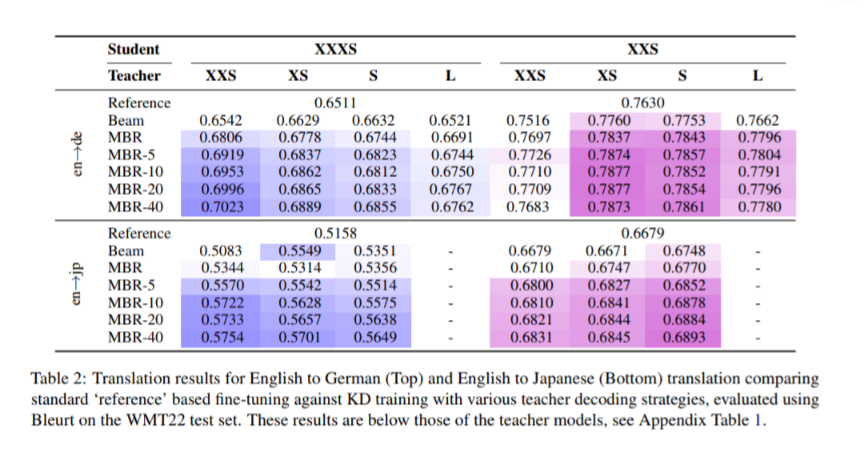
[New paper] If you are sampling multiple outputs from a teacher LLM (e.g., Gemini 1.5 GPT), ranking them, and fine-tuning the student on the best output, you can do better.
Simple idea: Fine-tune / Distill on the top-k outputs instead. Consistent gains on machine translation.
4
26
184
20,723