
Founder @Onehousehq, Creator of @apachehudi, Built the World's first #DataLakehouse, Distributed/Data Systems, Linkedin, Uber, Confluent alum. (views are mine)
Joined April 2009
- Tweets 1,271
- Following 232
- Followers 1,807
- Likes 754
133 Photos and videos







Pinned Tweet

20 May 2025
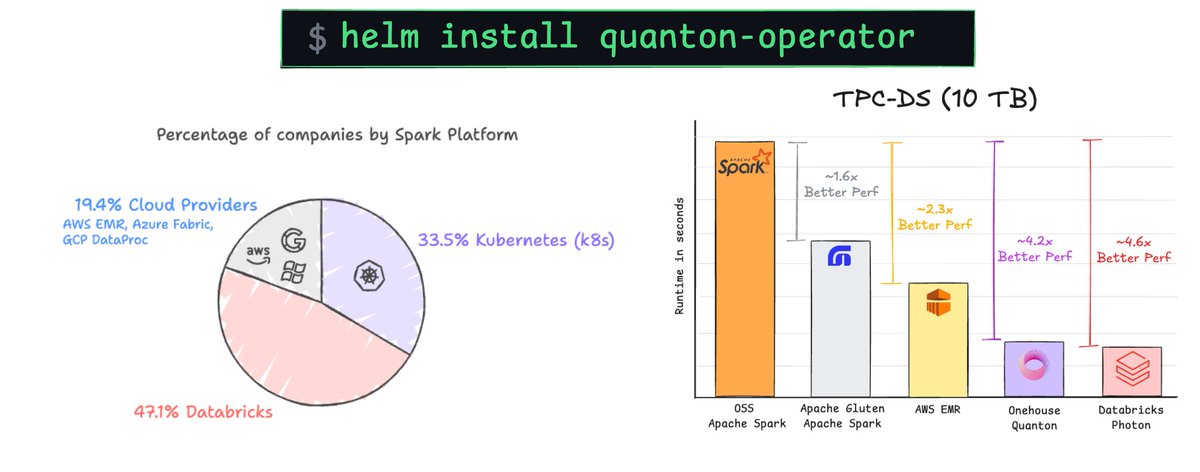
🔥 Meet Quanton — the new query execution engine from Onehouse.
👍 Same Spark & SQL.
📉 At least half the cost.
📈 1.6x-3.6x better ETL price-performance
📊 2.2x-6.5x better Ingest price-performance
👉 Read the full blog here:
onehouse.ai/blog/announcing-…
⬇️ Download our free Spark cost analyzer tool: onehouse.ai/spark-analysis-t…
⁉️ How? Quanton processes only what’s actually needed. Most engines only try to go fast. Quanton goes smart.
✔️ Drop-in replacement for Hudi Spark jobs
✔️ Compatible with Iceberg, Delta, SQL, dbt
✔️ Benchmarked thoroughly against top cloud runtimes
✔️ No rewrites. No lock-in. Just plug in & save.
For Hudi users hitting support walls with your Spark provider or rising infra bills, it’s time to switch. We've got you even if you’re writing to Iceberg or Delta. Quanton boosts every open table format to its potential. Onehouse is now the most open, most cost-efficient platform for ETL.
Proudly built by a small, gritty team of Davids in a sea of Goliaths. Quanton is here. It’s open. It’s fast. It’s efficient.
We are actively building towards unlocking the next 30-80% efficiency gains by the end of the year.
#ApacheHudi #Spark #SQL #Lakehouse #ETL #OpenData #DataEngineering #Onehouse #Quanton #DataPlatform #Infra #DataOps #CloudData #Efficiency #ApacheIceberg #DataWarehouse #DeltaLake
1
6
22
3,319
Jun 11
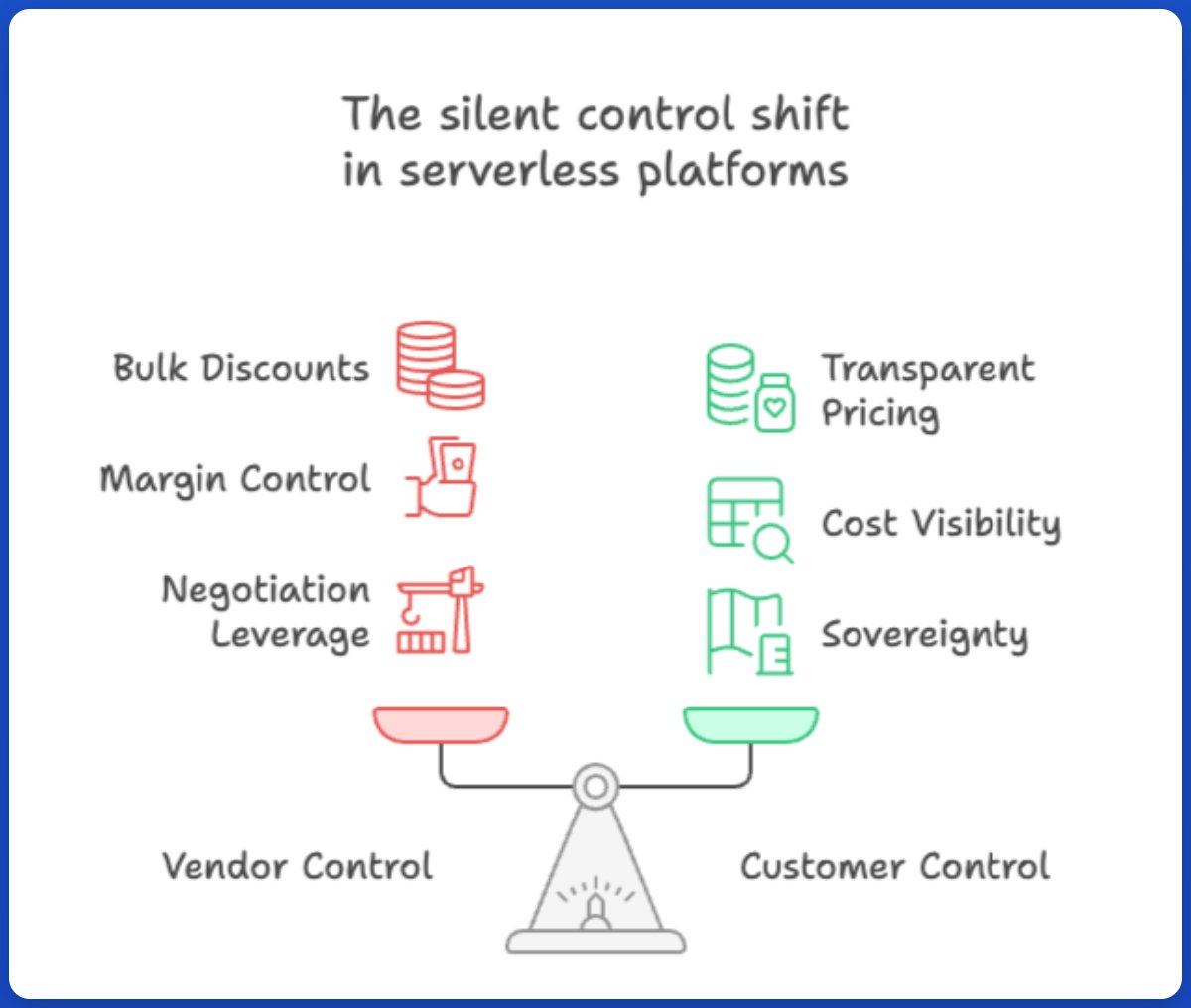
24 months in, one thing is obvious: this was never just a fight over open table formats. It’s about who controls the metadata, the catalog, and the center of gravity for where your data gets computed.
By summer 2024, three communities had spent 6–8 years building the open lakehouse. We were finally on the doorstep of real interoperability. With Apache XTable (incubating), major vendors—Google, Microsoft, and others—lined up to build open bridges across formats. Maybe for the first time ever.
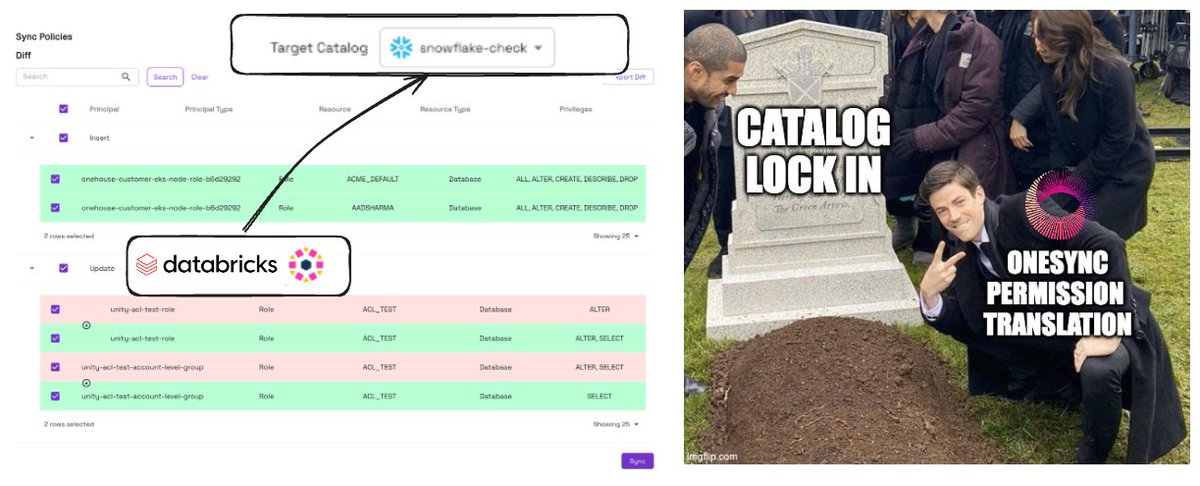
Except one vendor didn’t. Databricks chose to buy and merge 2 of the 3 projects—framing it as “unification,” but effectively bending Iceberg toward Delta Lake to regain control. It’s disappointing how far we still are from the promised land, even after 24 months.
Through it all, we’ve stayed open, collaborative, and patient.
Onehouse supports all formats equally, as we set out to do from day one. Apache Hudi supports Iceberg as a pluggable table format.
The future isn’t just open formats. It’s an open lakehouse stack. We’re building it in Apache Hudi—and doubling down on interoperability through the Apache XTable project.
1
2
10
394
Jun 11
3
113
Jun 8
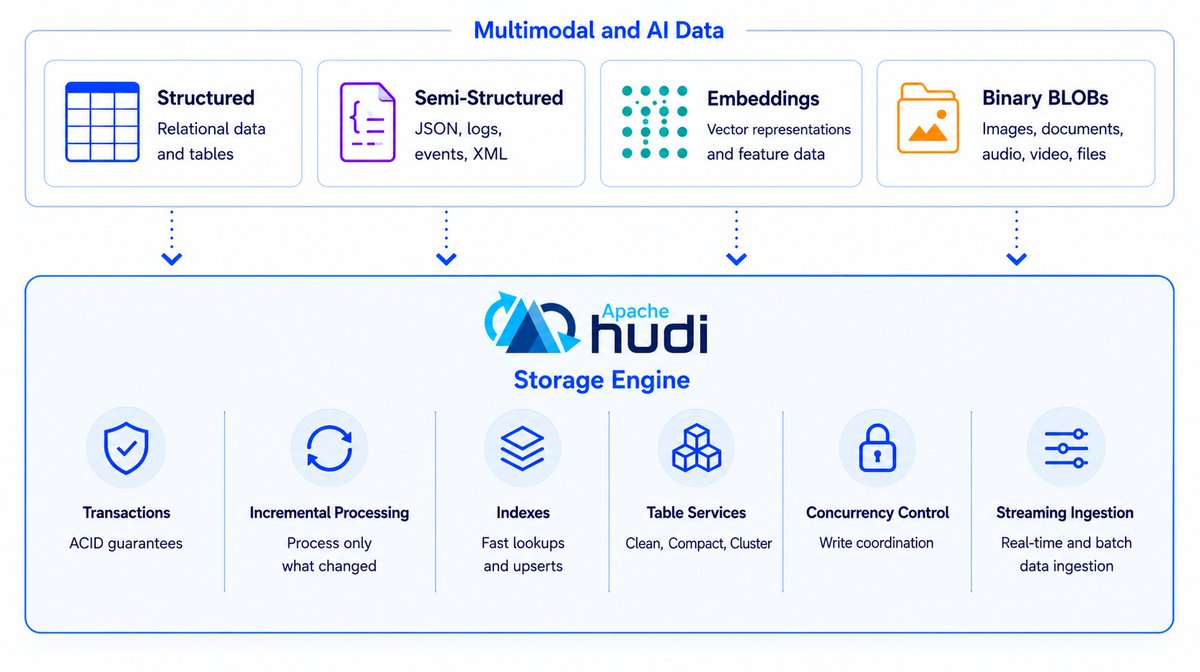
@apachehudi 1.2 dropped today. Multimodal data finally lands in the lakehouse. Embeddings, images, and video now sit in the same tables as your structured data—no new silos. 🚀
1
7
354
Jun 8
One foundation for structured, semi-structured, and multimodal data.
If you’re building retrieval, recommendations, AI observability, or streaming pipelines, try Hudi 1.2 and help shape the next open lakehouse.
Huge thanks to the entire community that made this happen. 🙏
1
42
Jun 4
It’s snowing in the San Francisco summer..
Most companies offload their Snowflake ETLs to spark;
We launched Quanton on Snowflake. So, you can finally run real cutting-edge Apache Spark, inside Snowflake..
For the what, how, why: checkout Kyle Weller ‘s blog here 👉 onehouse.ai/blog/real-apache…
1
1
5
1,362
Jun 2
Onehouse isn’t at Snowflake Summit this year (let’s not go into reasons). But someone should be having the real Spark-on-Snowflake conversation — so we showed up anyway. On a truck 🚛
Here’s why:
- Real Apache Spark — inside Snowflake containers
- Iceberg writes up to 4× faster
- No lift-and-shift, no second platform — especially if your data already lives in parquet/iceberg/delta/hudi
- Sitting on unspent Snowflake credits? Use them for real Spark instead of paying yet another vendor
- And since Snowpark containers can be cheaper than Snowflake warehouses, you could spend up to 65% fewer credits
We didn’t build Quanton to win a benchmark slide. We built it so data teams don’t have to move their data, double their bill, or pick a side in someone else’s platform war just to run a workload.
At Summit? Wave at the truck. Not here? quanton.dev/docs/guides/snow….
5
18
121,973
May 28
More honesty is good. 👍🏻
Its very frustrating when AI (also) lies about work.

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
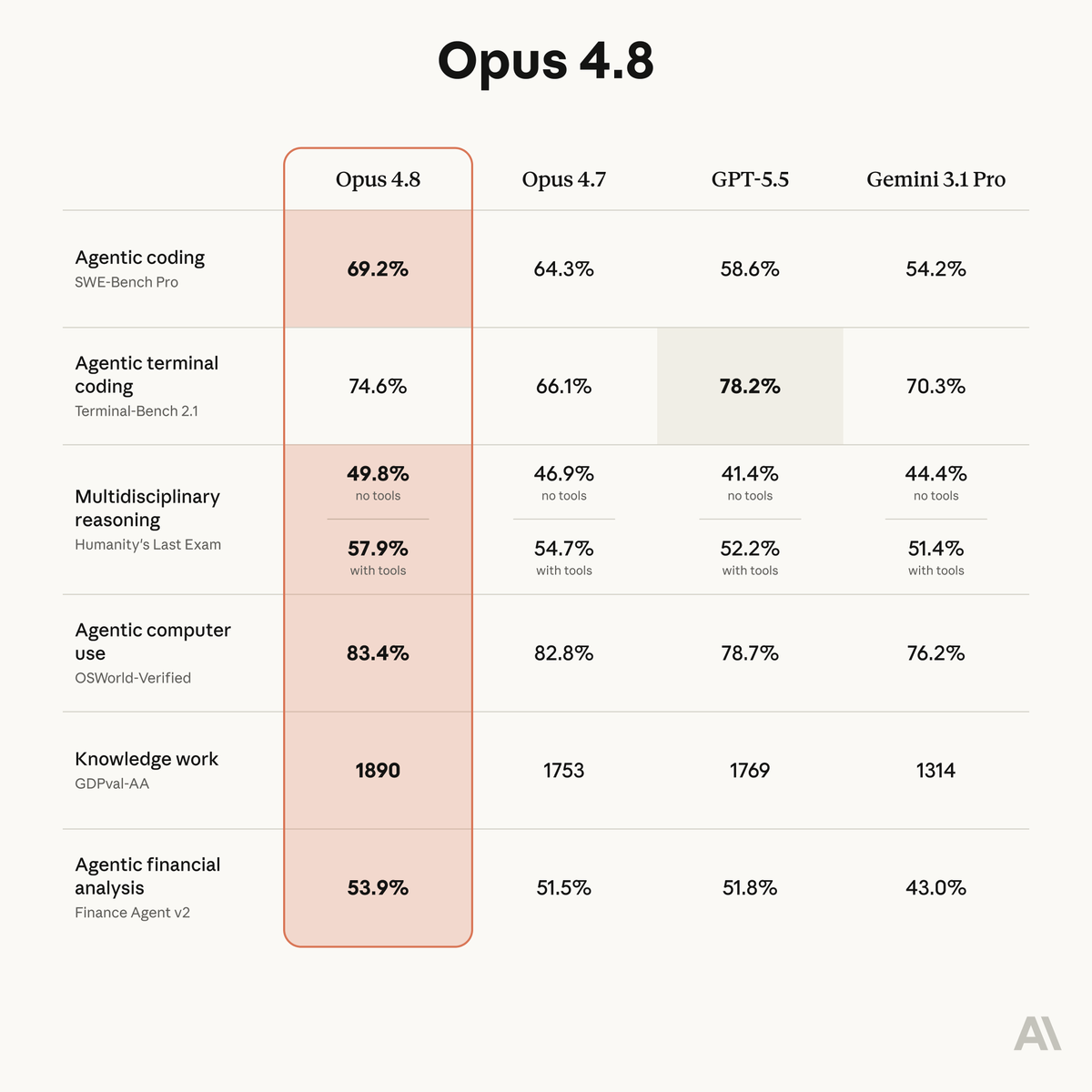
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
1
170
Vinoth Chandar retweeted

May 27
Picture your lakehouse bogged down by updates at 10TB scale 📊?
Core issue: Finding records without scanning full table.
Hudi's file groups route same-key records to one group with base/log files 🔑.
Updates are bound to that group 🚀—skip full searches.
Wins:
• Bounded write locality
• Limited scans for merge reads/compaction
At scale, this stabilizes ingestion vs. messy maintenance or sluggish MERGE INTO 🛠️.

1
2
7
650
Vinoth Chandar retweeted
May 26
Building indexes on a 100 TB Hudi table without blocking writes.
The naive approach: stop writes, build the index, resume. Hours of downtime.
Hudi async indexing: bootstrap index, then converge , high concurrency ↓

1
2
7
762
May 21
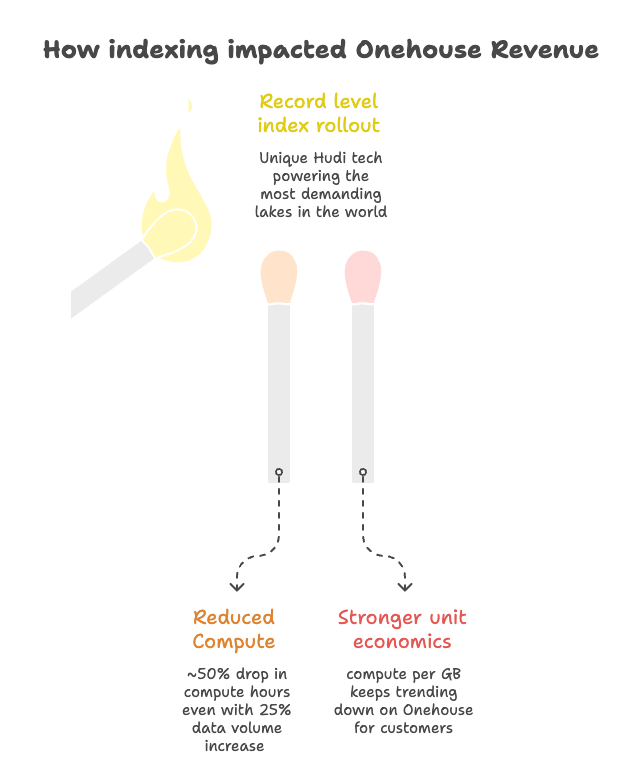
📉 In 2025, Onehouse's revenue growth was affected—not from churn or slower market, but because we rolled out Record-Level Indexing (RLI) across our biggest pipelines.
RLI (used at Uber-scale with Apache Hudi) is key reason Onehouse is the most efficient option for large-scale ingestion/ETL, often cutting Spark ingest/ETL compute 50% . As customers adopted it, metered compute hours dropped ~50% even as data grew.
This reveals a deep problem within the industry and also why platforms don't optimize harder with techniques like indexing. incentives!
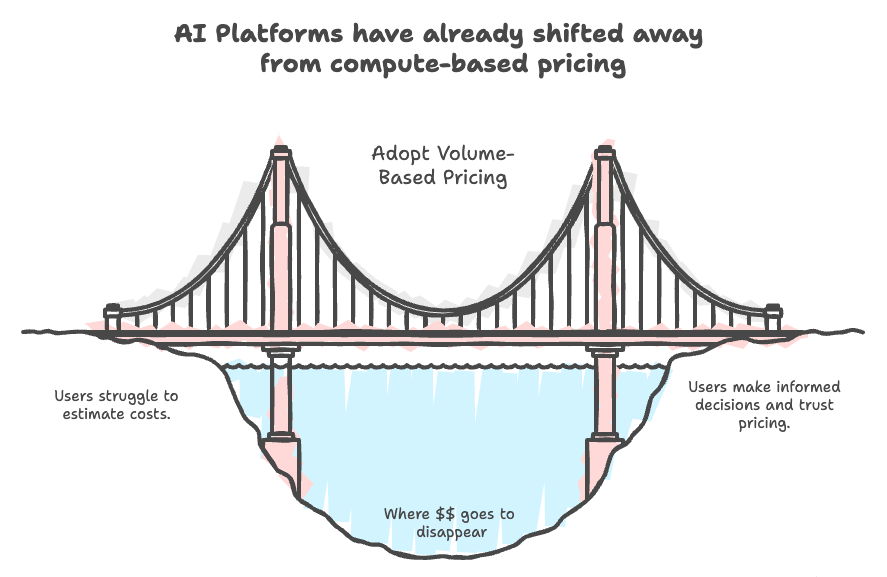
💰 For EMR/Databricks Classic: faster jobs → lowers revenue. Not good for vendor.
🏦 For Databricks serverless/Snowflake: faster jobs → better vendor margins. No direct benefits to user.
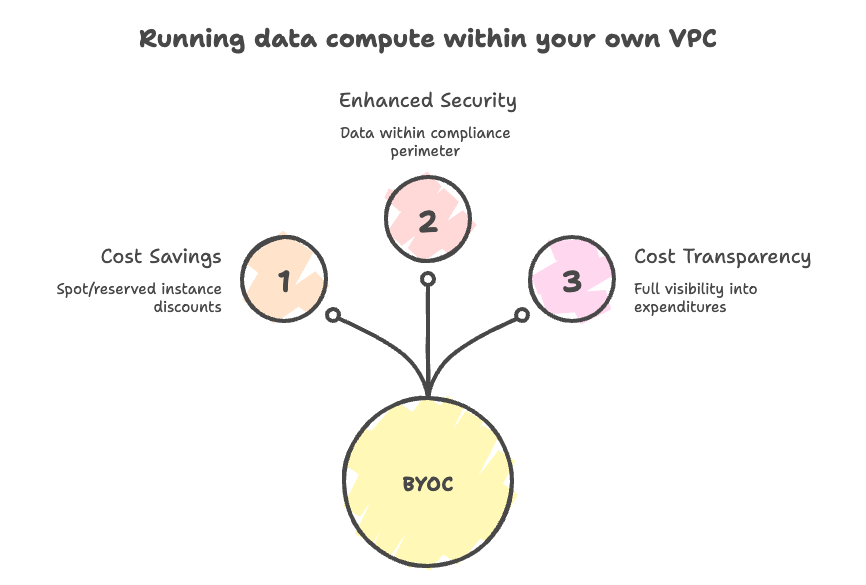
🔄 What did we do?: volume-based pricing for Spark SQL pipelines on Quanton.dev running in the user's cloud.
⚡ We make Quanton faster
→ directly lowers user's compute spend
→ Onehouse earns based on different metric: GB processed/month.
#ApacheHudi #ApacheIceberg #DeltaLake #Lakehouse #CloudOptimization #DataEngineering
1
1
4
323
May 21
Quanton matches Databricks Photon on reads and is much faster on writes—up to 4x faster/cheaper Spark at this price.
DM or leave comments - for feedback!
1
115
May 20
Google just stepped on the gas and left the keyword search era in the rearview mirror.
May 19

Today we are starting to roll out the biggest upgrade to the Google Search box in over 25 years — now completely reimagined with AI, along with Gemini 3.5 Flash as the new default model for AI mode users globally!
1
290
May 20
⚡ Speed is Iceberg’s biggest Achilles’ heel.
Most teams chase Velox or Gluten for Spark speed. Yet the real wins sit in fast I/O and layers untouched.
We’ve spent years making lakehouse pipelines fast—but this isn’t a table-format debate.
It’s slow I/O, shuffles, and reprocessing driving costs up.
Speed is a stack:
⚡ SIMD
📊 Columnar processing
🔍 Query plans
💾 Fast I/O
🗄️ Metadata
📐 Storage layout
🔗 Indexes
🔄 Merging
Full-stack engine: 3–4× faster than OSS Spark on Iceberg, better price/perf than Photon, no lock-in.
1
2
19
1,915
Vinoth Chandar retweeted
May 19
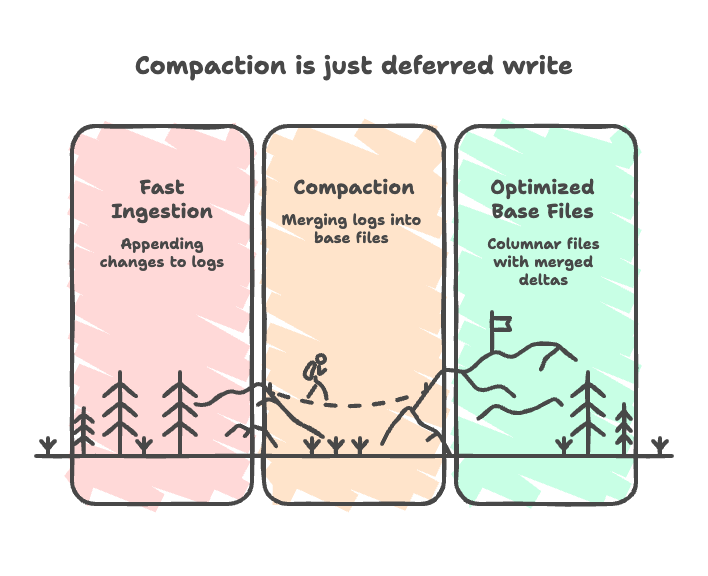
Compaction isn't just housekeeping 🧹—it's deferred write work in Merge-on-Read systems 📝.
Append changes to logs for fast ingestion 🚀, then compaction folds deltas into optimized base files 🔄.
Real question: When to pay back that deferred cost? ⏳
It affects:
- Ingest latency ⏱️
- Read performance 📈
- Storage efficiency 💾
- Background resource usage ⚙️
Hudi makes this tradeoff explicit, treating compaction as a first-class table service.
1
1
4
449