
ByteHouse, a part of @BytedanceTalk, is a lightning-fast, fully managed #CloudDataWarehouse that enables efficient, cost-effective big data analytics.
Joined October 2021
- Tweets 337
- Following 58
- Followers 24
- Likes 46
Photos and videos
Pinned Tweet

12 Dec 2023
The Modern Data Stack - An essential guide
This blog post provides you with an essential guide to the modern data stack and how you can build one using ByteHouse - bytehouse.cloud/blog/modern-…
#DataEngineering #DataWarehousing

2
1
112
4 Jan 2024
The challenges of semi-structured data
In this insightful post, Daniel Beach talks about the challenges of semi-structured data.
open.substack.com/pub/dataen…
#dataengineering #xml #json
1
30
2 Jan 2024
This is such an elegant representation of data pipelines from @alexxubyte of @bytebytego
#dataengineering #datapipelines
27 Dec 2023

Data Pipelines Overview. The method to download the GIF is available at the end.
Data pipelines are a fundamental component of managing and processing data efficiently within modern systems. These pipelines typically encompass 5 predominant phases: Collect, Ingest, Store, Compute, and Consume.
1. Collect:
Data is acquired from data stores, data streams, and applications, sourced remotely from devices, applications, or business systems.
2. Ingest:
During the ingestion process, data is loaded into systems and organized within event queues.
3. Store:
Post ingestion, organized data is stored in data warehouses, data lakes, and data lakehouses, along with various systems like databases, ensuring post-ingestion storage.
4. Compute:
Data undergoes aggregation, cleansing, and manipulation to conform to company standards, including tasks such as format conversion, data compression, and partitioning. This phase employs both batch and stream processing techniques.
5. Consume:
Processed data is made available for consumption through analytics and visualization tools, operational data stores, decision engines, user-facing applications, dashboards, data science, machine learning services, business intelligence, and self-service analytics.
The efficiency and effectiveness of each phase contribute to the overall success of data-driven operations within an organization.
Over to you: What's your story with data-driven pipelines? How have they influenced your data management game?
–
Subscribe to our newsletter to 𝐝𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐭𝐡𝐞 𝐆𝐈𝐅. After signing up, find the download link on the success page: lnkd.in/eawsYGiA
1
104
29 Dec 2023
As this year comes to a close, ByteHouse wishes you and your loved ones more peace, love, good health, and success in 2024.
Wish you a Happy and Prosperous New Year!
#happynewyear #HappyNewYear2024
46
28 Dec 2023
How is data warehousing adapting to the needs of Web3
In this blog post, we discuss the evolution of data warehousing to accommodate the Web3 and Blockchain space, its use cases, challenges, and solutions.
bytehouse.cloud/blog/data-wa…
#dataengineering #datawarehousing #web3

27
27 Dec 2023
Measuring data quality at Airbnb through Data Quality Score
In this insightful article, Clark Wright shares how they developed the DQ Score, and how it will power the future of data quality at @AirbnbEng.
medium.com/airbnb-engineerin…
@Airbnb
#dataengineering #dataquality #airbnb

1
33
26 Dec 2023
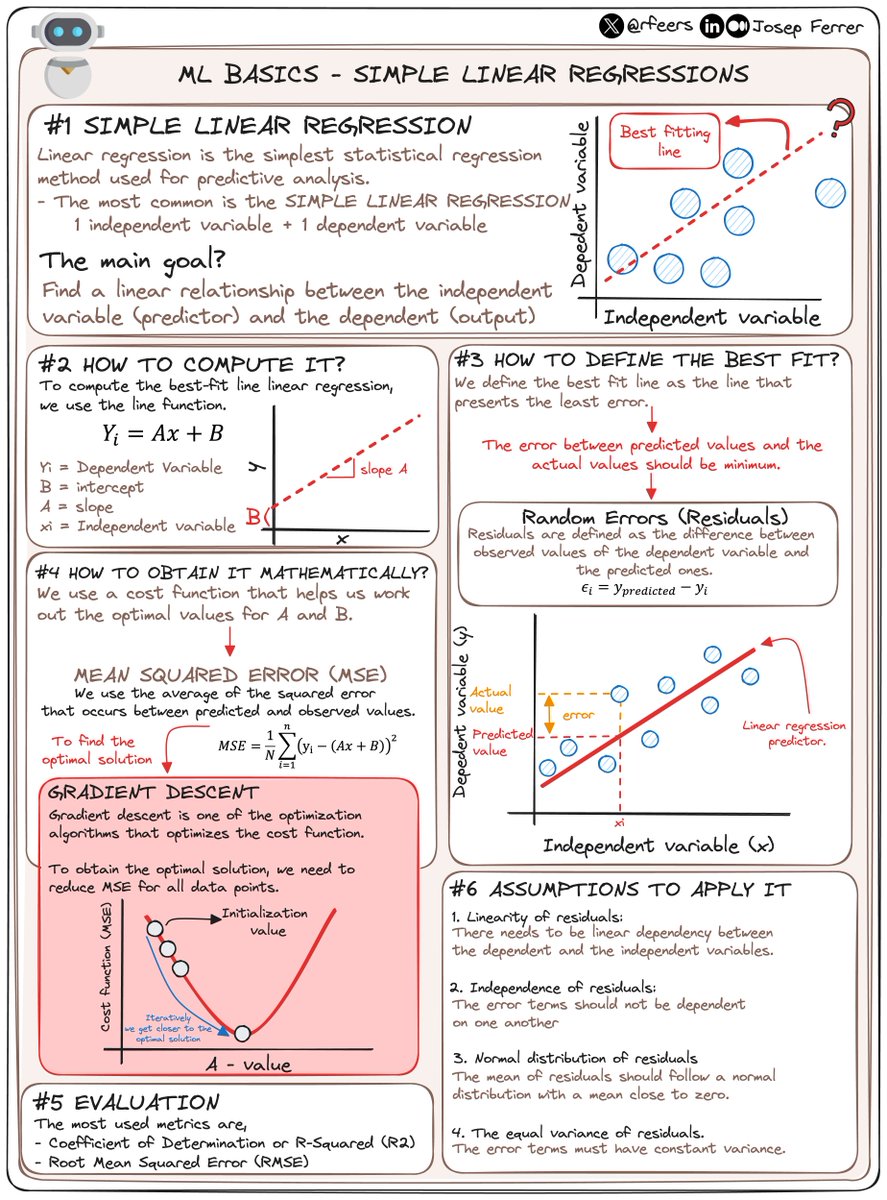
A refresher on Linear Regression is always useful
24 Dec 2023

Struggling with Machine Learning algorithms? 🤖
Then you better stay with me! 🤓
Today I am starting a new series of threads to simplify ML algorithms.
...and Linear Regression is the first one! 👇🏻
44
26 Dec 2023
ClickHouse for large-scale data ingestion and application
This article explores the application of large-scale data ingestion and use with Go and ClickHouse.
Read it here - medium.com/@kn2414e/utilizin…
#dataengineering #clickhouse #golang

51
22 Dec 2023
Season's greetings from ByteHouse. May this time bring joy to everyone ❤️
#merrychristmas #bytehouse

1
40
21 Dec 2023
Data ingestion deep dive - Part 1
Sharing part 1 of the 2 part series by Jan Meskens -
medium.com/@meskensjan/the-a…
#dataengineering #dataingestion
1
32
20 Dec 2023
Open Source Tools powered by AI/OpenAI for Kubernetes
AI-powered tools can help you master Kubernetes by automating tasks, improving reliability, and providing insights.
Read about it here: itnext.io/ai-and-kubernetes-…
#dataengineering #kubernetes

21
19 Dec 2023
10 use cases of a data lakehouse for modern businesses
Read our latest blog post exploring the use cases for a data lakehouse in modern businesses and how to build one with ByteHouse.
bytehouse.cloud/blog/use-cas…
#dataengineering #datalakehouse #datalake

1
27
15 Dec 2023
Advanced SQL for data engineers
SQL is an essential tool to master in the field of data engineering. As the complexity of work increases, it is important to advance one's expertise.
Here's a useful playlist by @Alex_TheAnalyst - youtube.com/playlist?list=PL…
#dataengineering #sql

26
ByteHouse retweeted

14 Dec 2023
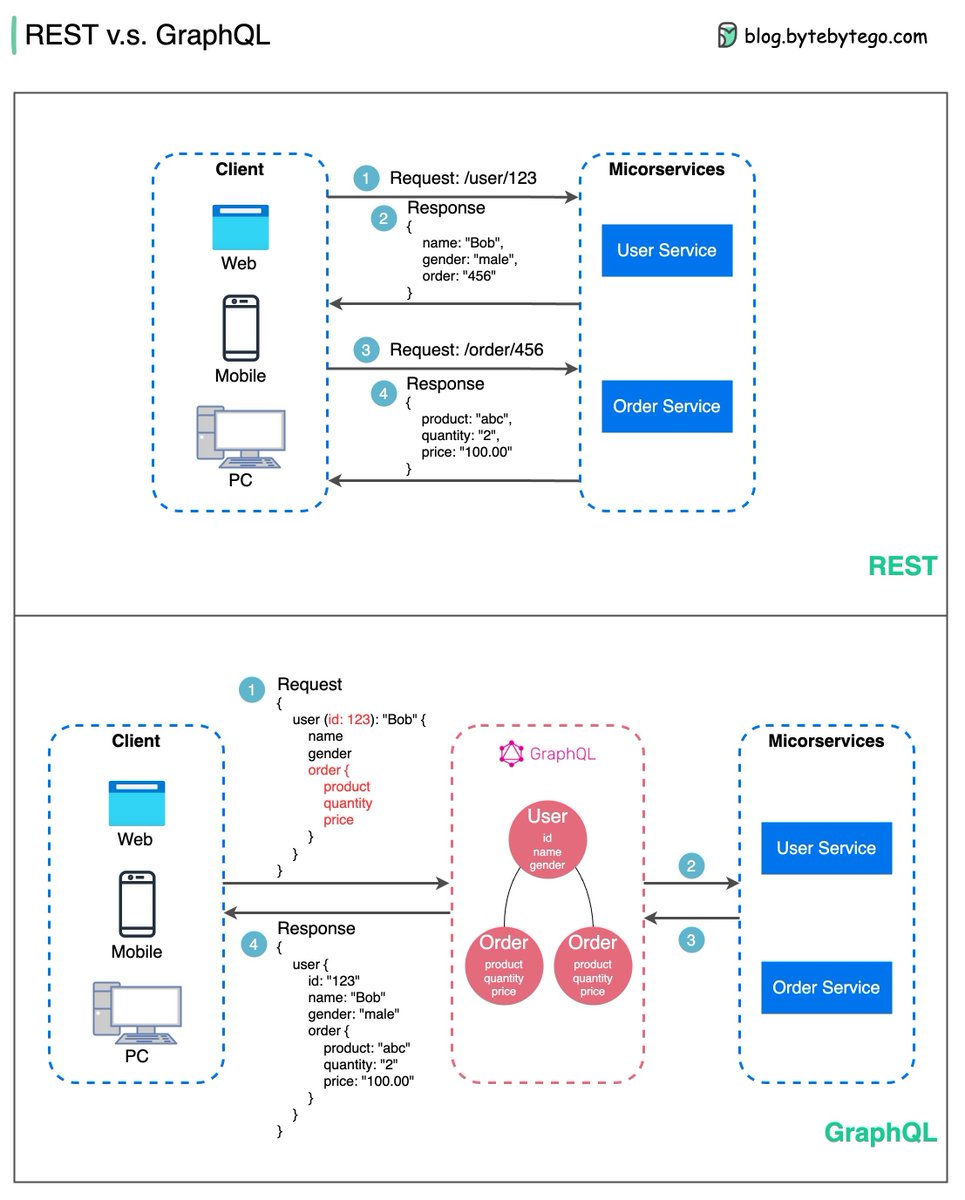
What is GraphQL? Is it a replacement for the REST API?
The diagram below shows a quick comparison between REST and GraphQL.
🔹GraphQL is a query language for APIs developed by Meta. It provides a complete description of the data in the API and gives clients the power to ask for exactly what they need.
🔹GraphQL servers sit in between the client and the backend services.
🔹GraphQL can aggregate multiple REST requests into one query. GraphQL server organizes the resources in a graph.
🔹GraphQL supports queries, mutations (applying data modifications to resources), and subscriptions (receiving notifications on schema modifications).
We talked about the REST API in last week’s video and will compare REST vs. GraphQL vs. gRPC in a separate post/video.
Over to you:
1). Is GraphQL a database technology?
2). Do you recommend GraphQL? Why/why not?
–
Subscribe to our weekly newsletter to get a Free System Design PDF (158 pages): bit.ly/3KCnWXq
12
112
521
45,472
14 Dec 2023
Europe's new comprehensive AI rules
Europe has always been the forerunner in implementing laws that safeguard the security of its netizens, and this time too, it is the world’s first to draft comprehensive AI rules - apnews.com/article/ai-act-eu…
#dataengineering #ai #generatieveai

ALT https://apnews.com/article/ai-act-europe-regulation-59466a4d8fd3597b04542ef25831322c
18
13 Dec 2023
Why is peter missing?
12 Dec 2023

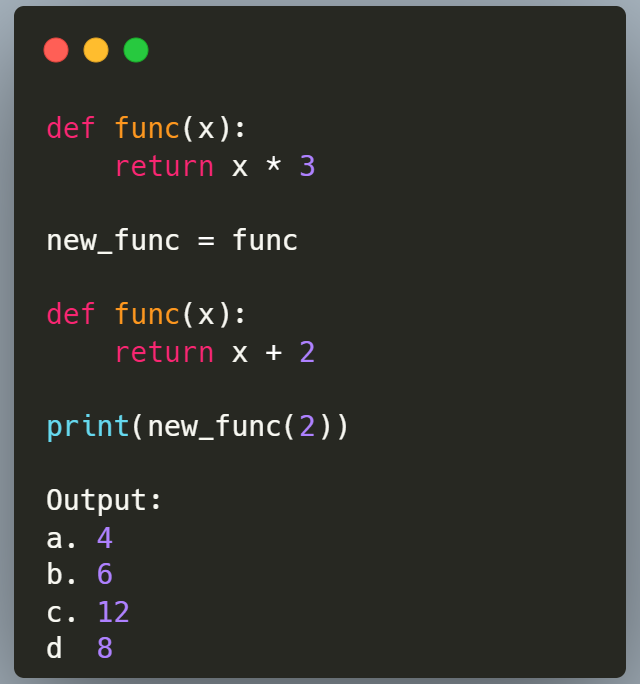
Python Question;
Happy Tuesday
What is the output of this code, and why?🤔🤔

40
13 Dec 2023
10 Advanced Data Pipeline Strategies
In the real world, it is common for data engineers to inherit a data pipeline mess, or work under tremendous constraints.
In this guide, @Databand_ai share advanced strategies for managing data pipelines.
#dataengineering #datapipeline

1
59
8 Dec 2023
Try doing a dry run
7 Dec 2023
Python Question;
Another function. Can you figure this one out?
What is the output of this code and why?🤔🤔
32
8 Dec 2023
Explain it like I’m 5 (ELI5) - Apache Kafka
Ever wondered how to explain Apache Kafka to non-data folks?
Gently Down the Stream by Mitch Seymour is a gentle (and super cute) introduction to Apache Kafka - gentlydownthe.stream/
@_round_robin
#dataengineering #kafka

42
ByteHouse retweeted

6 Dec 2023
The best tech for each task:
- batch pipeline: Apache Spark
- data visualization: Apache Superset
- web api: NextJS (spring boot close second)
- SQL database: Postgres
- NoSQL database: DynamoDB
- Graph database: Neo4j
- front end web: React
- front end mobile: React Native (Flutter close second)
- CI/CD system: GitHub Actions
- data quality checks: Great Expectations (Deequ close second)
- data lake file management: Apache Iceberg (Delta Lake a close second)
- job orchestration: Apache Airflow (Mage and/or Prefect close second)
- machine learning model: XGBoost (linear regression close second)
- LLM: GPT-4.5 Turbo
- programming language: Python (Rust close second)
- message queue: Kafka (RabbitMQ close second)
- cache: Redis (Memcached close second)
#softwareengineering
41
235
1,381
196,381